
本文主要整理了网易云容器编排技术负责人娄超的演讲“网易云基于Kubernetes的深度定制化实践”,其他讲师的演讲内容还在整理中,敬请期待!

娄超,网易云容器编排技术负责人。曾经参与淘宝分布式文件系统TFS和阿里云缓存服务研发,2015年加入网易参与网易云容器服务研发,经历网易云基础服务(蜂巢)v1.0,v2.0的容器编排相关的设计和研发工作,并推动网易云内部Kubernetes版本不断升级。
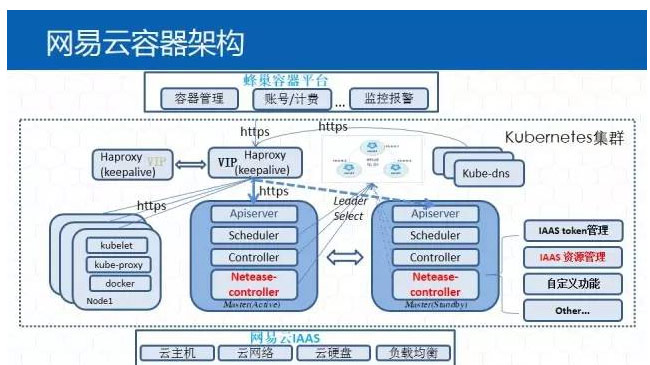
网易云的容器服务基于网易云的IaaS。为了简化用户的操作,Kubernetes并不是直接暴露给用户的,而是通过上层的业务层为用户提供容器服务,增加独立的Netease-Controller, 对接网易IaaS及公共平台,资源管理和复杂的业务需求。
Kubernetes公有云实践
Kubernetes的社区版本主要面向私有云市场,没有租户的概念,只有namespace的逻辑隔离,Node/pv等资源都是集群全局共享的,服务发现和负载均衡也都是全局的,Node须在集群内预备足够,不用担心资源调度出现失败,也无需关心Docker隔离安全性问题。而对于公有云来说,云中有着海量用户,用户的技术背景多样,需要很高的安全隔离性。网易云在基于Kubernetes实现公有云的过程中,做了很多工作。
1. 首先,在多租户的安全隔离方面,有专门的IaaS团队提供主机、硬盘和网络的隔离;
2. 对于每个租户来说,都可以自定义创建namespace;
3. 原生的Kubernetes认证很简单,而且Node是全局共享的,每个Node上都可访问Kubernetes的所有资源,所以为了实现公有云,网易云做了租户级别的安全隔离,包括认证、授权和API分类统计和流控报警;
4. 在网易云中计算、存储、网络资源均按需实时分配、回收,保证资源的利用率尽可能高;因为资源是实时分配的,所以创建起来一般比较慢,所以网易云对创建流程做了一些全局的优化,比如加快Node注册的进程,根据镜像选择主机等;
5. 原生的Kubernetes中没有网络IP的概念,网易云增加了Network资源类型表示网络IP。
网易云容器pod网络
容器的网络主要有以下几种方案:
入门级:Docker 基础网络模型 host(共享),bridge(NAT)。
进阶级:自建网桥(IP-per-Pod),可跨主机通讯,如Flannel, Weave。
专业级: 多租户,ACL,高性能可扩展 ,如Calico,GCE高级网络模式。
网易云容器网络实现
网易云的容器服务的网络实现与GCE类似,基于底层的IaaS网络,通过Kubernetes与网易云网络对接,网易云容器与主机在网络上完全对等,租户内全互通。
Kubernetes中没有定义IP的管理,可能一个容器或节点重启一下,IP就变了。网易云通过IP的管理实现了IP的保持功能,同时Pod支持私有网、公网双重网络。
此外,网易云还实现了Pod的私有网、公网IP映射关系管理,在Kubelet上实现Netease CNI插件管理网卡挂卸载、路由配置。
网易云有状态容器
提到容器的状态,人们常用Cattle和Pet来做比喻。Cattle是指无状态的容器,随时可以被替换,Pet则是有标记的,它的数据、状态和配置可能都需要持久化。社区从1.3版本就开始用PetSet实现有状态的容器,最新的1.6版本中,是叫StatefulSet。
网易云在社区版本的有状态容器诞生之前(1.0版本),就自研了StatefulPod的实现方式:
- 和StatefulSet不同的是,它可以支持容器系统卷、数据卷的保持(PV、PVC)。StatefulSet只能支持外挂的数据卷,但是网易云的StatefulPod能够保证只要不删除用户,用户系统盘的数据也能够保持下来;
- StatefulPod还能保证容器私有网、公网IP保持(Network);
- 在原生的Docker中,一个Node启动的所有容器目录都是统一的,网易云扩展Docker支持容器rootfs目录自定义;
- 网易云的有状态容器还支持故障的迁移,比如硬盘和IP等资源都能在Node间漂移。
网易云Kubernetes性能优化
一般在实现公有云时,尽量会保证同一个机房内,只有一个Kubernetes集群,但随着用户的增多,集群的规模也越来越大,会出现很多性能问题。网易云随着社区的发展一路走来,也遇到了社区在设计之初可能没有预料到的一些问题,比如:
1. Kube-scheduler对所有Pod顺序串行调度;
2. Kube-controller的deltaQueue是无优先级的FIFO队列;
3. Serviceaccounts控制器里没有Secret本地缓存;
4. 所有Node重复配置集群所有Service的iptables规则;
5. Kubelet的SyncLoop每次检查都重复GET imagePullSecrets;
6. 大量Node的心跳汇报严重影响了Node的监听;
7. Kube-apiserver 没有查询索引。
master端的调度器
针对这些问题,网易云做了很多性能优化,首先是master端的调度器:
- 公有云的场景和私有云不一样,容器分布在不同的租户中,每个租户的资源都是独立的,本身就可以通过租户来沟通并调度;
- 通常在调度的时候需要一个个去遍历Node,实际上很多无闲置资源的Node可以不参与调度的检查,网易云会在遍历前过滤掉无闲置资源的Node;
- 优化predicate调度算法过滤顺序,提高调度效率;
- 网易云中,调度都是基于事件的,比如调度失败如果是因为Node资源不足,就会发一个事件去申请资源,资源回来后会又会返回一个事件驱动Pod重调度,没有任何时间等待。
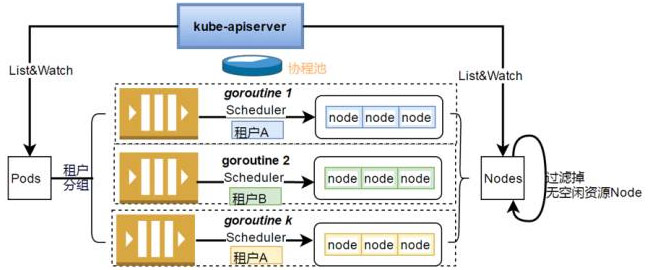
上图就是在网易云中并行调度的过程。
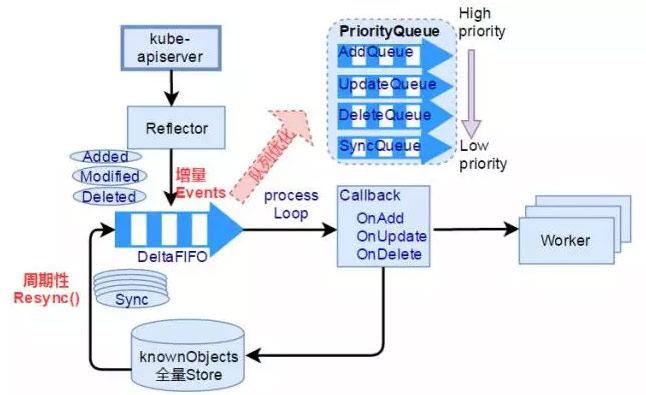
mater端控制器的优化
Kubernetes中有很多控制器,比如Node控制器、Namespace控制器,其中Replication Controller是一个核心的控制器,能确保任何时候Kubernetes集群中有指定数量的Pod副本在运行。网易云创建了事件优先级机制,根据事件类型进入优先级队列workqueue。
Node端的优化
网易云的用户很多,用户之间都是完全隔离的,网易云kube-proxy按租户对Node分组:
- 租户之间容器网络完全隔离,不配多余转发规则;
- 只监听本租户的Service,再生成iptable 规则。
Kubelet降低master请求负载:
- imagePullSecret推迟都要拉镜像才GET或增加Secret local cache;
- 只监听本租户相关资源变化(依赖apiserver新加的tenant索引);
- 精简kubelet watch 低master连接数,包括Node。
单集群扩展的优化
根据官方的数据,Kubernetes 1.0最多支持100个Node,3000个Pod;在1.3版本中这个数字上升到2000个Node,6万个Pod,今年最新发布的1.6版本已经支持5K个Node,15W个Pod。
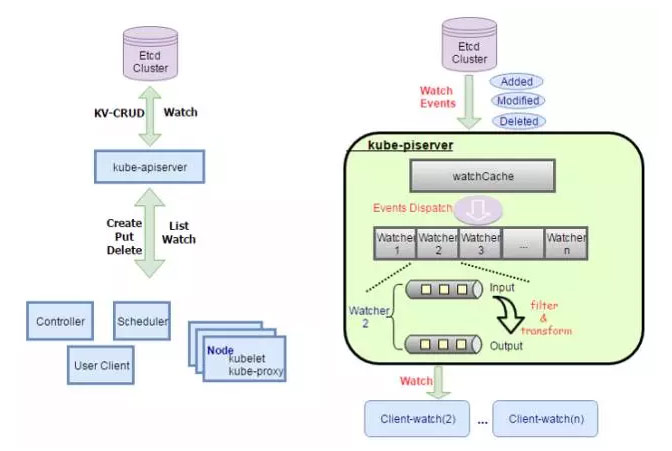
通过上图可以知道APIserver是整个集群的通信网关,只是一个proxy代理,而且goroutine对web服务完美支持,最终性能瓶颈在对 etcd的访问上。
为了解决这个问题,首先想到的是分库,按Node/RS/Pod/Event分库存入多个etcd集群。因为Etcd本身容量和性能均不能水平扩展,而且没有性能诊断工具:
- Etcd2 调优,比如针对snapshot的优化,采用SSD硬盘等;
- 升级Etcd3,在之前的版本中,每次更改都会发送一个请求,一个请求又对应一个回复,在Etcd3中是批量请求的方式,可能一次请求就把1000个变化推送过来了,所以效率提高很多;
- 更换Kubernetes后端的存储,换其他性能更优的KV存储。
Node心跳汇报模式修改:
- Node心跳间隔延长;
- Node心跳不持久化;
- 心跳从Node分离出来,Node心跳只需list不必watch;
- NodeController被动改主动探测。
其它优化
镜像、容器的GC完善:目前的GC只考虑了磁盘的空间使用量,没考虑inode的问题,很多用户的小文件很多,所以网易云新增了磁盘inode使用率检查。
容器监控统计:Cadvisor新增网络流量、TCP连接、磁盘相关统计。
NodeController安全模式,自定义Protected,Normal,Advanced 3种模式:
- Protected: 底层IaaS主动临时运维时,为了避免大规模迁移波动, Node离线只报警不迁移;
- Normal:有状态的不迁移,无状态的及时离线删除重建。(仅仅底层云盘、网络故障);
- Advanced:有状态无状态都自动迁移恢复。
还需要注意的一些问题:
- Pod的graceful delete要容器能正常传递SIGTERM信号;
- StatefulSet在kubelet挂掉时可能出现两个同时运行的Pod。

登录后评论
立即登录 注册