
分享嘉宾:崔东
本次,我分享的主题是《东方国信基于Kubernetes构建容器云平台的实践和思考》。
先讲一下背景,国信之前的软件部署方式是找台机器,把war包或者jar包往机器上一扔,启动就可以了,所有功能都在一个包里面,模块之间相互耦合,导致新功能开发上线周期很长,客户的需求得不到及时满足。
所以我们把我们的应用微服务化改造,微服务化以后,原来一个应用现在变成了十几个,每个应用功能相对独立,开发人员需要了解的东西变少,开发新功能也比以前简单了;
但是软件部署运维变得困难了,原来一个软件包,现在成了十几个。了解过DevOps的同学一定知道,开发和运维之间有一道墙,现在这道墙更高了。
所以我们希望有一款产品能解决我们这些痛点,最后我们把目标锁定在docker和kubernetes上,我们希望基于这个平台来实现DevOps的部分流程,来减轻部署运维的负担,同时能提高我们的资源利用率。
最后我们制定了下面这样一个架构:
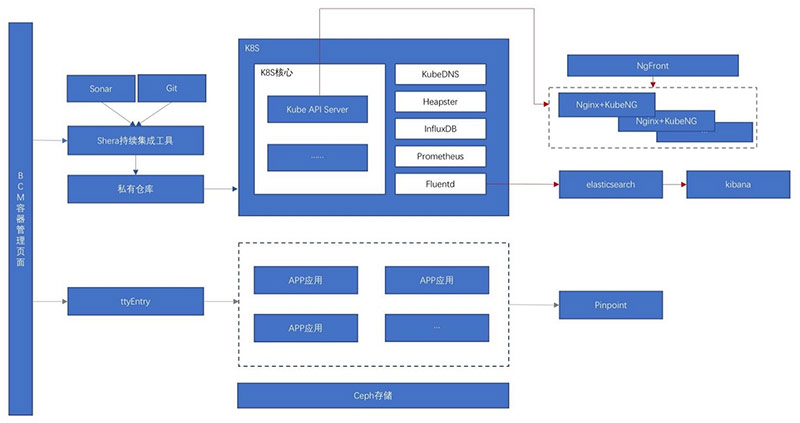
这张图的最左边是我们控制台,叫BCM,用户所有的操作都在BCM的界面上面完成,包括镜像的构建,服务的发布、升级等,这种界面的东西各公司根据业务和服务对象不同会有所不同,但是主要功能都差不多,所以不展开说了,后面会贴几张界面。
我们先说最核心的k8s部分,因为所有工作都是围绕着k8s展开的。
云平台的主体基于K8S+Docker构建;通过KubeDNS来为集群内的应用程序提供域名解析;
通过heapster收集性能信息,写入influxDB,然后是BCM读取influxDB信息进行展示,我们没有使用grafana,主要是考虑到我们的平台是多租户的,不同的租户只能看到自己系统的性能指标;
而且我们通过对kubelet和heapster的修改,增加了对容器内应用的线程数和socket连接数的监控,为什么要增加?
因为我们在使用过程中发现有些应用代码质量不高,乱用线程,有的文件句柄打开后忘记关闭,导致运行一段时间后连接数据库失败,所以我们增加了这两项监控,当然严格执行代码质量检查和review才是更重要的。
大家也看到我们使用了prometheus,我们主要使用了prometheus对cpu和内存使用率进行告警,同时对prometheus和alertmanager增加了配置接口,在应用部署时,把阈值配置下去,同时重载prometheus的配置,完成监控功能。
我们使用fluent来收集容器的日志,写入elasticsearch,通过kibana进行检索。
同时bcm的web界面上可以查看实时日志,这本来是个小功能,但是开发过程也是一波三折,开始我们使用了k8s的api进行日志获取,当日志文件很大的时候,发现读取很慢,接着我们又修改成通过docker的api获取,但是还是很慢。有时候我们只想查看一个特定时间段的日志,这个日志量应该不会太大,应该很快才对。
于是我们查看了docker源码,发现有两点需要优化,第一是读取缓冲区,太小了,只有1KB;
第二就是每次都从第一条日志进行读取,反序列后进行时间比较,看看是否在时间段内,其实docker不支持结束时间,我们自己加的。
针对第一点,修改方法很简单,增大一下读取缓冲区就可以了;
第二点,修改策略是把日志分成多个文件,并且记录每个文件的开始日志时间和结束日志时间,通过查询记录信息,定位到第一个需要读取的日志文件和最后一个需要读取的文件,减少不必要的io。
下面我们再说一下我们的服务发现:
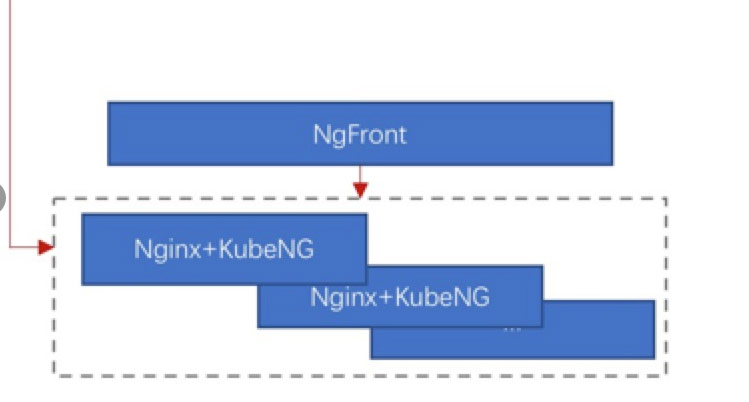
我们使用了Nginx来做反向代理,同时我们开发了KubeNg这样一个后台程序,为每个Nginx服务器配置一个KubeNg,KubeNg通过kube-ApiServer实时监控服务的变化,更新nginx的配置文件,reload nginx配置。
kubeNg是一个后台程序,没有界面,生成的nginx配置都是固定格式的,有些用户对自己应用程序的nginx配置有特殊的要求,需要修改,我们又没有界面来修改,这不行啊,所以我们又开发了一个NgFront前端程序,NgFront满足下面几点要求:
通过NgFront可以管理多套Nginx集群,因为有些租户公用一套nginx,有些租户单独使用一套nginx。
2、可以修改抓取到的配置,解决租户对配置有特殊的要求。
3、可以增加没有使用容器进行部署的服务的反向代理,因为不是所有服务都会使用容器进行部署,起码刚开始不会,但是这些服务还想共用容器的nginx,当然运维人员可以登录到每台nginx机器上进行配置,但是这样很容易出错,直接在界面上面编辑完成,下发到所有机器就可以了。
4、Reload之前进行配置文件语法检查。
5、可以下载配置文件,有时候会有运维人员绕过NgFront进行操作,导致Nginx集群内各节点的配置不一致,有些用户可以正常访问,有些不能正常访问,取决于LVS把用户的请求负载均衡到哪台nginx上面了,所以出现这种情况的时候,我们点击下载,用文本对比工具对比一下,很快就能发现问题。
下面我们再说说ttyEntry:
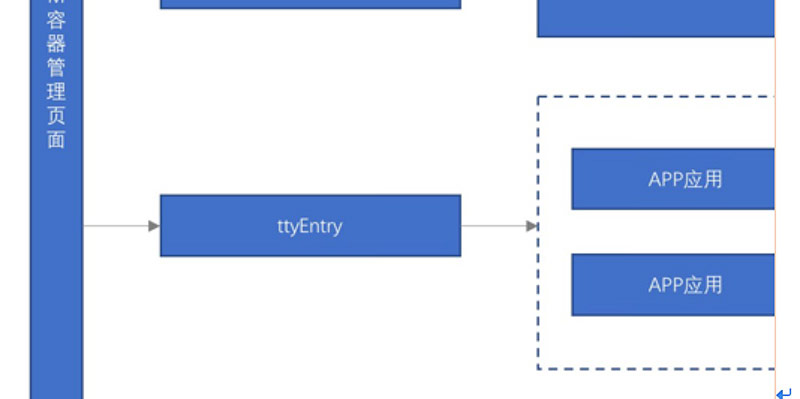
这个主要是解决用户调试方便的需求。用户在刚开始使用容器的时候,碰到最多的问题就是配置文件忘记修改了,导致系统启动失败。用户需要重新上传个jar包到BCM平台,进行镜像构建,所以他们需要有一个环境像使用虚拟机一样,可以使用vi进行编辑,修改完成后,执行java –jar进行测试,如果正常,直接打包成镜像,推送到仓库。
BCM使用了xterm来做了一个web版的终端,TtyEntry主要功能就是把xterm发过来的请求转发到容器内部。
下面再说说pinpoint功能:

这个是一个很赞的工具,在不需要修改代码的情况下,可以给出应用之间的调用关系和花费的时间,而且性能损失很小。
下面是pinpoint的架构图,我们把红色框中的Pinpoint Agent做到了容器内,通过BCM界面上的开关控制是否开启监控。
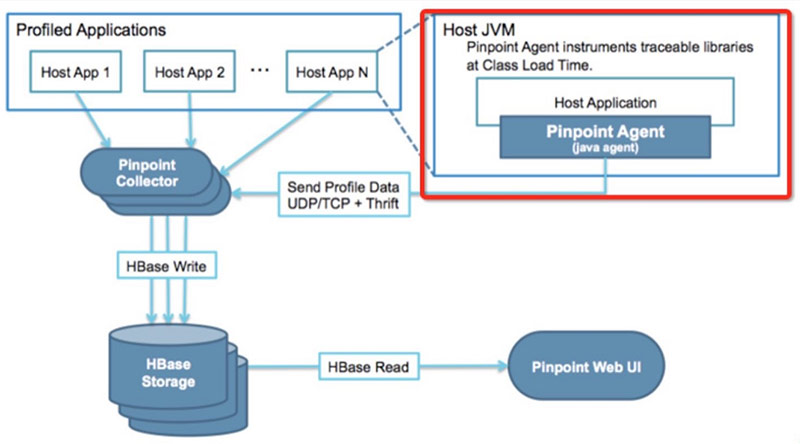
精华也在Pinpoint Agent,Agent会在我们应用程序的class加载的时候,进行jvm虚拟机代码的注入,在class执行的时候采集执行时间发送给Collector,后面的HBase就是存储,WebUi就是展示。
深入的原理还是要看google的论文,Pinpoint是根据google的Dapper论文研发的。
再回到我们刚开始的整体框架图,里面有个Ceph,Ceph用来提供高性能的网络存储。我们的应用程序不全是无状态的,有很多应用程序需要用户上传脚本、说明文档等,这些东西显然不能存储在容器内部的存储上。
大家知道docker容器重启后,里面存储的数据就会丢失,所以我们就把ceph挂载到容器内部,把这些需要持久化的东西存储到ceph,即使pod被重新调度到其他节点,存储在ceph里面的文件也不会丢失。另外Ceph的块存储也可以为我们的mysql、redis等的容器化提供存储。
我们还有一部分没有介绍,就是下面这块:
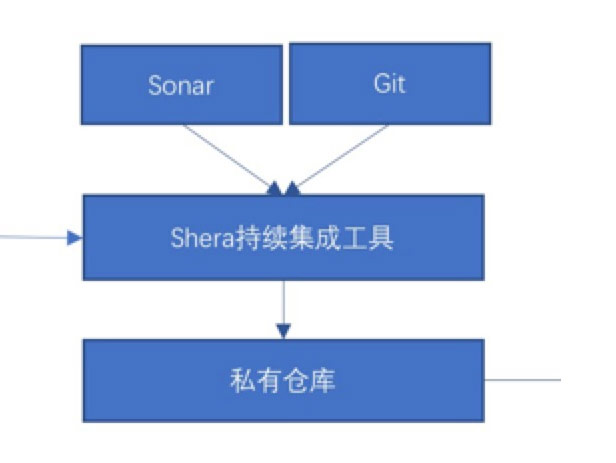
这其实就是个简配的DevOps,之所以做一个简配版,主要是考虑到两方面:一、实现简单;二、推广简单。一个工具一旦复杂了,就很难推广落地,所以我们前期先做一最简单的,先让大家上船,后面才好往下走。
我们开发了一个持续集成工具SheRa,就是动画片里面的“希瑞请赐予我力量吧”的希瑞。SheRa只是一个后台服务,提供restful的接口,BCM实现配置页面。下面是界面:
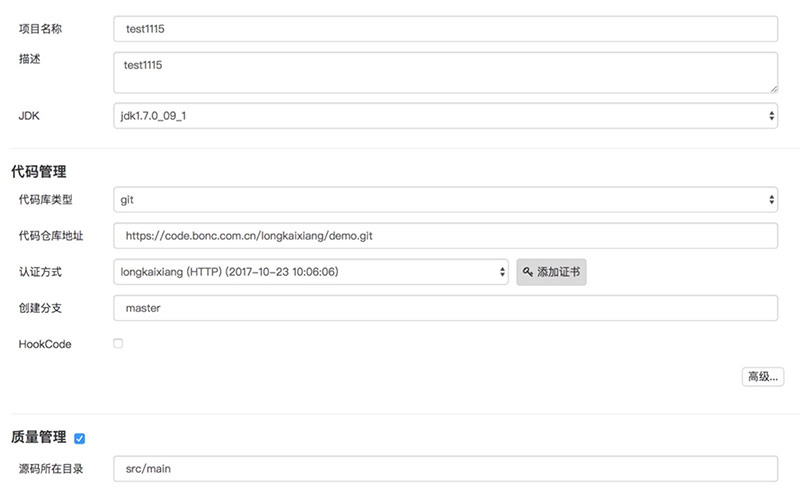
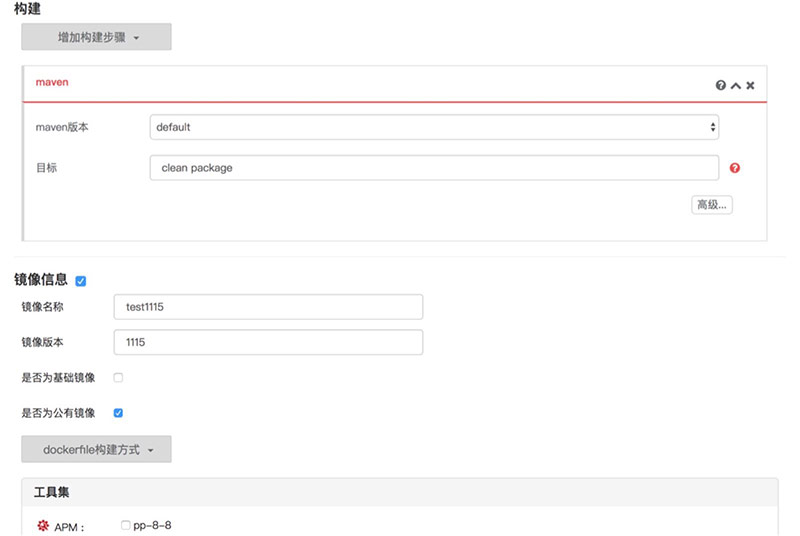
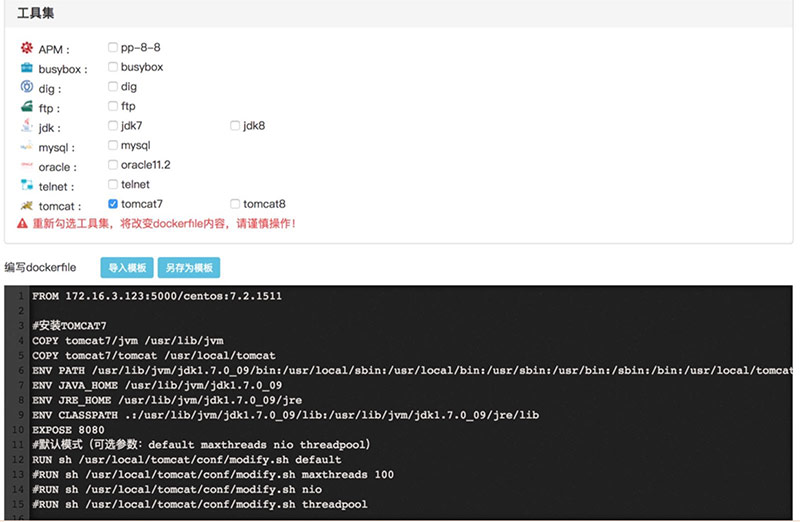
界面配置Git的地址、maven编译命令,sonar代码质量检查是可选的配置,如果选择了,最后生成的镜像就有一个相应的质量标签,最后是dockerfile,我们的shera自带了几个工具,如果最后生成的镜像有问题,可以把shera自带的工具打包进去,协助进行调试。
比如,连接mysql不成功,可以把mysql客户端打包到镜像内,通过ssh进入镜像,进行连接测试。因为刚开始使用容器,研发很容易把屎盆子扣在容器头上,我们可以通过这些工具有理有据的告诉他们,数据库连接没有问题,你们是不是打包配置错了jdbc。
下面是配置完成,编译后的界面:

点击项目名称,进入详情

点击快速部署按钮,进行部署。

这样一个服务也就配置完成了。
好了,我的分享也就这么多了,谢谢大家阅读。
作者:东方国信 崔东
来源:DockOne

东方国信就别在上面丢人了