
原标题:瓜子云的任务调度系统; 本文标题:基于Kubernetes的瓜子云的任务调度系统
【编者的话】瓜子云的任务调度系统结合了Kubernetes的Job和Airflow。并在Airflow基础上加了很多改动。本次分享跟大家交流瓜子云的调度系统的架构设计和解决方案。
瓜子云的任务调度系统结合了Kubernetes的Job和Airflow。
Airflow是Airbnb出品的任务调度系统,支持DAG调度,这一点完美的弥补了Kubernetes Job的不足。借助Kubernetes的自动扩展,集群资源统一管理,Airflow将更具灵活性,更稳定。但是,把Airflow部署在Kubernetes上是一个很大的挑战。
接下来我讲详细介绍一下瓜子云的任务调度系统搭建所遇到的问题和解决方案。
需求
瓜子最早的时候,任务调度用的是Crontab,后来由于数据仓库的复杂调度需求,我们引入了Airflow。Airflow支持DAG依赖,失败重试,历史状态记录,log收集等多种非常使用的功能。
Airflow有很多问题:
- Airflow的Worker需要手动搭建,可扩展性不好。
- Job代码更新之后,需要手动部署到Worker上,非常繁琐。
- Airflow Worker的环境太多,由各个团队自行维护,维护成本太高。
- 瓜子云平台搭建之后,所有机器都会被回收,各业务线拥有的机器将会很少,Worker将会没有地方部署。
此外,我们还希望调度系统有如下的功能:
- DAG之间的依赖
因为数据仓库的ETL非常复杂,没有任何人能够完全掌控整个流程,我们需要把整个ETL切成很多小的DAG,这些DAG之间是有互相依赖的。 - 自动扩容缩容
瓜子这样的特点,晚上有大量批量任务需要跑,白天每个小时,每一分钟都会有增量任务需要跑。 - 环境隔离
瓜子的语言多种多样,每个团队都有很多不同的Job在不同的环境上跑着,管理很混乱,还有可能互相影响。
介于这样的问题,我们准备把调度系统部署到Kubernetes上,利用Kubernetes的环境隔离,自动扩容缩容的特性。
Airflow的原始架构
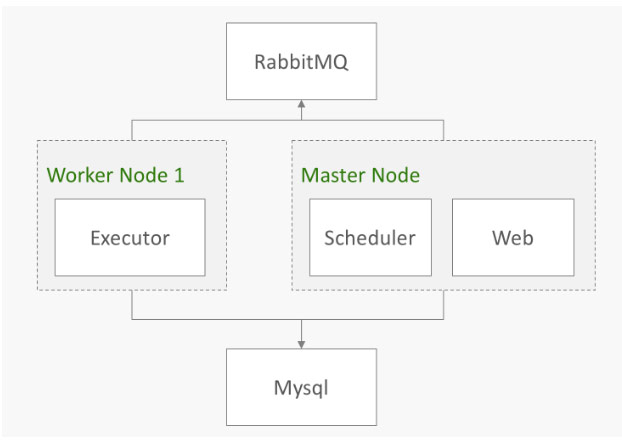
Airflow分为Master节点和Worker节点两种。Master节点有Scheduler和Web两种服务,Worker上有Executor一种服务。
我们从任务的调度过程来看看他们是怎么工作的:
- Scheduler读取DAG配置文件,将需要执行的Job信息发给RabbitMQ,并且在MySQL里面注册Job信息。
- RabbitMQ里面按照环境有很多channel,Scheduler的Job会根据需要执行的环境发到相应的channel里面。
- Executor消费RabbitMQ相应的channel,进行执行,执行结果更新到MySQL中,并将log暴露到Executor的某个http端口上调用,并存入MySQL中。
- Web读取MySQL里面的Job信息,展示Job的执行结果,并从MySQL中获取log的url,展示log。
- Web上发现执行错误的Job可以点击重试,直接发送Job给RabbitMQ里,并改变MySQL里面Job的状态。
Airflow上云的问题
Airflow上云有很多问题,我们这里只列举一些比较麻烦的问题来说一下。
1. Scheduler HA
Airflow不支持多个Scheduler,多个Scheduler一起启动时会报错,所有Scheduler都会挂掉。当我们在Kubernetes上滚动更新时,需要先启动一个新的Scheduler,然后再干掉旧的Scheduler。这样就不可避免会出现多个Scheduler并行的情况。
2. 配置更新
Job配置更新后,所有组件自动更新最新配置的问题。Airflow中所有组件都需要拿到DAG配置才能正常工作。其实原理上大可不必,可能是Airflow设计的时候没考虑到分别部署的情况吧。
3. Web访问Worker
Web需要通过Worker的HOSTNAME来访问Worker上的log,但是Kubernetes中不支持通过HOSTNAME来访问。
4. Worker不同环境
Job需要在不同环境中执行,不可能在Kubernetes中为所有环境单独搭建长期运行的Pod。
问题的解决
1. Scheduler HA
我们引入了ZooKeeper,在Airflow Scheduler启动时去监听ZooKeeper下的/airflow/scheduler。
如果发现下面有个running的key,就说明已经有Scheduler在运行了,然后一直监听,直到running timeout。
如果发现没有,就可以启动Scheduler,然后在/airflow/scheduler下注册running,把自己的信息,作为value。每隔5s注册一下,该running timeout时间设为30s。
这样就解决了HA的问题。
2. 配置更新的问题
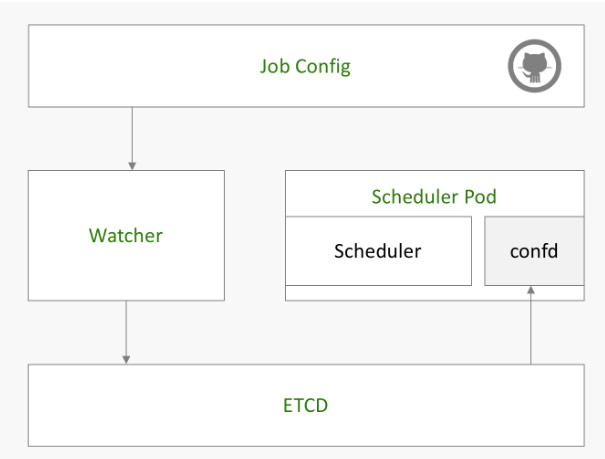
配置更新的配置流程为:
- 我们自己写了一个Watcher的组件,通过连接Git的Webhooker,监听git merge信息,一旦收到merge的信息,就会把Git的commit hash值存入etcd的/medusa/airflow/config 里面。
- 我们在Scheduler旁边放一个sidecar —— Confd,两个容器作为一个Pod,共享一个文件夹作为airflow的DAG配置文件夹。
- Confd监听etcd的/medusa/airflow/config key,发现更新就触发git pull操作。
这样子,我们就拿到了最新的配置文件。通过相同的方式部署Web和Worker即可。
3. Web访问Worker的问题
这个问题,我们在Airflow源码里面改了一点东西,用IP地址代替HOSTNAME解决了问题。
只需要修改models.py 里面的这行代码就好。

4. Worker不同环境
我们的解决方案是,不在Worker里面放任何环境,只负责由给定的image和script来生成Kubernetes job xml,并启动Job和监控。我们将在下面重点介绍。
Airflow云上架构
经过上述改动后,云上Airflow的架构就改成了下图这样
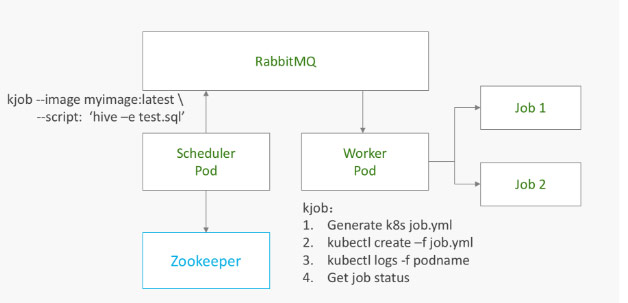
整个任务调度流程为:
- Scheduler读取任务配置文件夹信息,发现有个任务需要执行。所有的执行命令都是:
kjob --image myjob:latest --script 'hive -e test.sql'
这个样子的,也就是所有任务都通过KJob来执行。
- Worker里面我们用Golang写了一个KJob的脚本,内部做了如下几件事
- 通过传入的两个参数image和script,生成job.yml
- 通过job.yml 启动Kubernetes Job
- 一旦Job开始正常运行,监听log
- Job完成,获取job的状态并返回成功与否
这个样子,我们就把环境依赖的事丢给开发者自行维护了。
这时的任务更新流程如下图:

我们写了一个med-sdk,其功能是把代码打成Docker镜像,并且push到Docker Registry里面。这里我就不详细展开了,有兴趣的可以看我的之前的分享。
详细流程为:
- 如图右侧,任务代码改动后,会自动触发med-sdk构建Docker镜像,并发布到Docker Registry里面,镜像以latest作为version,确保每次都拉取最新版的镜像。
- 如图左侧,Airflow配置改动后,Watcher会收到Git的merge信息,并更新ETCD。Scheduler,Worker会更新相应的配置文件。
- Worker收到最新Job之后会拉取最新的镜像部署服务。
整个Airflow上Kubernetes的难点算是处理完了。
感谢大家的倾听。
Q&A
Q:请问下自动触发med-sdk构建Docker镜像,med-sdk是什么开源项目,能介绍下么?
A:med-sdk是瓜子自行开发的一个工具,用于把代码打成Docker镜像包。每个Git里面只需要添加一个med.yml就可以实现。
Q:请问为什么要集成Kubernetes?
A:Airflow的Worker需要手动搭建,可扩展性不好;Job代码更新之后,需要手动部署到Worker上,非常繁琐;Airflow Worker的环境太多,由各个团队自行维护,维护成本太高;云平台搭建之后,所有机器都会被回收,各业务线拥有的机器将会很少,Worker将会没有地方部署。
Q:Airflow处理的调度量是什么规模,也就是批量任务会不会阻塞,一次并发有多少Pod,多少容器实例,一套Kubernetes Master能否扛得住,方便给个数据量进行参考吗?
A:目前瓜子每天有2000个任务。任务的执行地点都是在Kubernetes上的,不会阻塞。并发的Pod个数是由同时处理的Job数定的,Airflow的Worker有设置一个Worker可以同时跑几个Job。我们并发Pod有20个。一套Kubernetes可以抗住我们的规模。数据量不好给,因为任务的计算量不好估算,有的大有的小。
Q:为什么不考虑Celery之类的任务队列?
A:首先是我们之前选用的是Airflow,用Python写的DAG,非常符合我们的需求,我们的DAG需求很大,比如数据仓库,所以选择了Airflow。
Q: 有做过类似软件的对比么,差异在哪?
A:Kubernetes目前被Docker官方支持。Mesos用C写的,不好运维。Rancher社区不够大。其实功能大家都支持,主要是社区。
Q:并发的容器数量是多少,实际的Docker实例个数量级,20个Pod可大可小。方便给个参考吗?谢谢!
A:我们测过每台机的上限在100个,我们的机器是128G,24cores。我们Airflow的Worker有20个Pod。
以上内容根据2017年10月31日晚微DockOne信群分享内容整理。 分享人彭超,瓜子云平台架构师,大数据架构师,浙大毕业后,先后工作于EverString,宜信大数据,瓜子二手车。专注于云平台系统架构的设计与研究,大数据与云平台的结合。DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiesa,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。

登录后评论
立即登录 注册