
前言
容器推出以来,给软件开发带来了极具传染性的振奋和创新,并获得了来自各个行业、各个领域的巨大的支持——从大企业到初创公司,从研发到各类IT人员等等。跨境知名电商小红书随着业务的铺开,线上部署单元的数量急剧增加,以 Jenkins 调用脚本进行文件推送的部署模式已经不能适应需求。这一期实践日,小红书运维团队负责人孙国清将为大家带来小红书如何以最小的投入,最低的开发量快速的实现容器化镜像部署,以及由此带来的收益。以下是此次演讲的整理。
作者介绍

孙国清
小红书运维团队负责人
浙大计算机系毕业,曾在传统企业 IT 部门工作多年, 最近几年开始在互联网行业从事技术及技术管理工作,曾就职于携程基础架构,负责 Linux 系统标准化及分布式存储的研究和落地,目前在小红书带领运维团队,负责业务应用,基础架构以及IT支持。个人接触的技术比较杂,从开发到运维的一些领域都有兴趣,是 Scala 语言的爱好者,曾翻译了”The Neophyte’s Guide to Scala”,有上千 Scala 开发者从中受益,到小红书后开始负责系统化落地 DevOps 和提高运维效率。
小红书

图 1
小红书本身是一个社区做起来的。一开始是大家在平台上发帖子,分享一些生活中的好东西,健身什么的。目前我们已经有有 5 千万的用户,1 千万的图文,每日 有1 亿次笔记曝光,涉及彩妆、护肤,健身,旅游等等各种领域。
现在小红书是最国内早践行社区电商这个商业模式并获得市场认可的一家电商,我们从社区把流量引入电商,现在在电商平台的 SKU 已经上到了十万级。我们从社区里的用户创建的笔记生成相关的标签,关联相关商品, 同时在商品页面也展示社区内的用户相关笔记。
小红目前还处在创业阶段,我们的技术团队规模还不大, 当然运维本身也是一个小团队,现在整个运维是八个同学。小公司资源有限,一个是人力资源有限,二是我们很多业务往前赶,在如何做好 CI/CD,怎么务实的落地方面, 我们的策略就是开源优先,优先选择开源的产品,在开源的基础上,发现不足的地方做补缺。
小红书应用上线流程
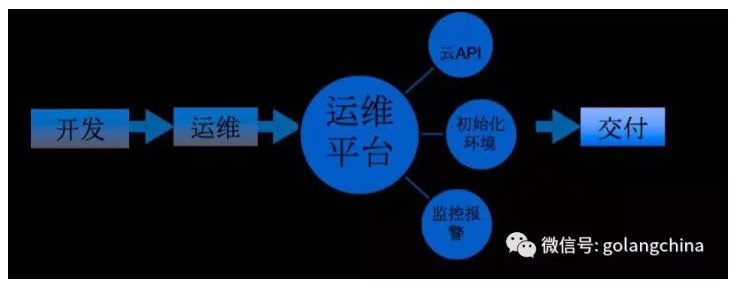
图 2
如图 2 是现在应用上线的过程,开发向运维提需求,需要多少台服务器, 运维依据需求去做初始化并交付给开发。小红书现在有一个运维平台,所有服务器的部署都是有这个平台来完成,平台调用腾讯云API生成服务器,做环境初始化,配置监控和报警,交付给开发的是一个服务器。

图 3
线上发布是用 Jenkins 脚本的方式:用 Jenkins 的脚本做测试,执行代码推送. 当有新加一台服务器或者下线一台服务器,要去修改这个发布脚本。 发布流程大概是这样的: jenkins脚本先往beta环境发,开发者在 beta 环境里做自测,自测环境没有问题就全量发。
我们遇到不少的情况都是在开发者自测的时候没有问题,然后在线上发,线上都是全量发,结果就挂了。然后回退的时候,怎么做呢?我们只能整个流程跑一遍,开发者回退老代码,再跑一次 Jenkins 脚本,整个过程最长需要10来分钟, 这段过程线上故障一直存在,所以这个效率挺低, 再加上现在小红书的整个技术在做一些更迭,环境的复杂度越来越高, 如果还是维持现有的代码上线模式, 显然会有失控的风险.
问题&需求
首先,我们整个技术的团队,团队人数在增加,再加上技术栈在变。以前都是纯 Python 的技术环境,现在不同的团队在尝试 JAVA、Go、Node。还有就是我们在做微服务的改造,以前的单体应用正在加速拆分成各个微服务,所以应用的数量也增加很多。拆分微服务后, 团队也变得更细分了; 同时我们还在做前后端的拆分,原来很多的 API 就是在前端展现,现在在做前后端的拆分,后端程序是 API,前端是展示页面,各种应用的依赖关系也变得越来越多。以现在的模式基本上已经不太可行了,很难持续下去。
所以团队就在两三个月以前就思考怎么解决这些问题,怎么把线上环境和代码发布做得更加好一点。基本上我们需要它做到这几点:
- 重构“从代码到上线”的流程;
- 要支持Canary发布的策略,就是所谓的灰度策略;
- 要能快速回退;
- 实践自动化测试,要有一个环境让自动化测试可以跑;
- 要求服务器等资源管理透明化,不要让开发者关心应用跑在哪个服务器上,这对开发者没有意义,他只要关心开发就可以了。
方法
 图 4
图 4
两个月以前我们思考怎么实现这样的东西。其实一开始就考虑到容器化,一开始就是用Kubernetes 的框架做容器化的管理。为什么是用 Kubernetes,这和运行环境和部署环境有关系。我们是腾讯云的重度用户, 腾讯云原生支持 Kubernetes。所谓原生支持就是说它有几个方面的实现: 第一个是网络层面,我们知道 Kubernetes 在裸金属的环境下,要实现Overlay网络 ,或者有SDN网络的环境,而在腾讯云的环境里,它本身就是软件定义网络,所以它在网络上的实现可以做到在容器环境里和原生的网络一样的快,没有任何的性能牺牲。第二在腾讯云的环境里,负载均衡器和 Kubernetes 里的 service 可以捆绑,可以通过 Kubernetes 的接口,创建 Kubernetes 的 service 去生成云服务的负载均衡器。第三就是腾讯云的网盘可以被 Kubernetes 管理。这些都是我们为什么选择 Kubernetes 的原因。
刚刚说了我们作为创业公司都是是以开源为主,在新的环境里应用了这样的技术(图 4),Jenkins、Gitlab 和 Spinnaker。Jenkins 和 Gitlab 应该都听说,用得很多了,普罗米修斯、Docker 也都是很主流的。
第一个 Traefik,在我们的环境里是用来取代Nginx反向代理. Traefik 是用 Go 写的一个反向代理服务软件。第二是 Spinnaker,这是一个我个人认为非常优秀的开源的发布系统,它是由 Netflix在去年开源的,整个社区非常活跃,它对 Kubernetes 的环境支持非常好。接下来我会重点介绍这两块东西。
Spinnaker
- Netflix 开源项目
- 开放性和集成能力
- 较强的 pipeline 表达能力
- 强大的表达式
- 界面友好
- 支持多种云平台
刚才介绍了 Spinnaker,它本身是一个开源项目,是 Netflix 的开源项目。Netflix 的开源项目在社区一直有着不错的口碑。它有开放式的集成能力,它的整个设计里对于集成能力有非常好的实现。它原生就可以支持 Jenkins、Gitlab 所有东西的整合,本身它还支持 webhook ,就是说在某一个环境里,如果后面的某个资源的控制组件,本身是个 API,很容易就可以整合到 Spinnaker 里。
再者它有比较强的 Pipeline 的能力,它的 Pipeline 可以复杂到无以复加,它还有很强的表达式功能,可以在任何的环节里用表达式来做替代静态参数和值。在整个Pipeline开始的时候,Pipeline 生成的过程变量都可以被 Pipeline 每个 stage 调用。比如说这个 Pipeline 是 cash 的时候,整个过程是怎么样,都可以访问这个参数。它有很友好的界面,重点的是支持多种云平台。目前支持 Kubernetes,支持 open stack,支持亚马逊的云平台。

图 5
图 5 是发布系统的架构,是一个微服务的架构。里面有很多组件,有面向用户界面的 Deck,然后有面向调用,可以完全不用它的界面开发一个封装,由后台它帮我们执行发布等等任务。Gate 是它的一个 API 的网关,Rosco 是它做 beta 镜像构建的组件,Orca 是它的核心,所谓的流程引擎。Echo 是通知系统, igor是用来集成Jenkins等CI系统的一个组件。Front52 是存储管理,Cloud driver 是它用来适配不同的云平台的,比如Kubernetes 就有专门的Cloud driver,也有亚马逊的 Cloud driver。Fiat 是它一个鉴权的组件。
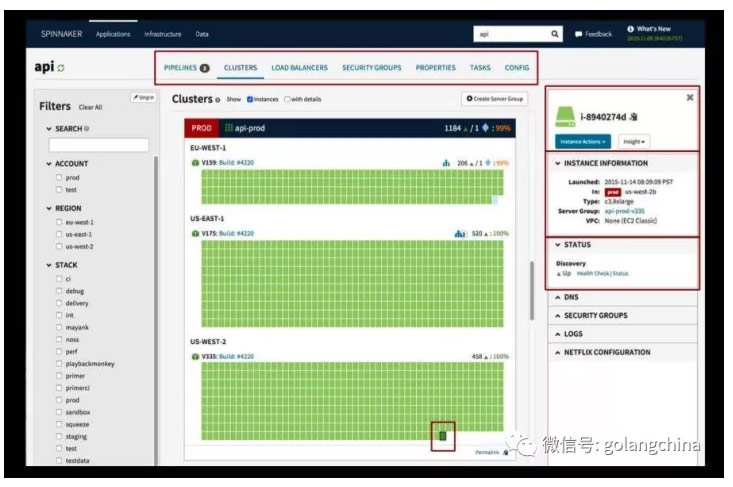
图 6
图 6 是它的界面。界面一眼看上去很乱,实际上它还是有很好的逻辑性。这里每一个块,每一个难点,或者是红点或者是灰色的点,代表的是在 Kubernetes 的环境里的某个实例。蓝色是代表是活着的,右边是实例的信息。实例怎么起来的,在哪个环节里,是在哪个 group,右中是状态,是活着还是死了等等界面介绍。
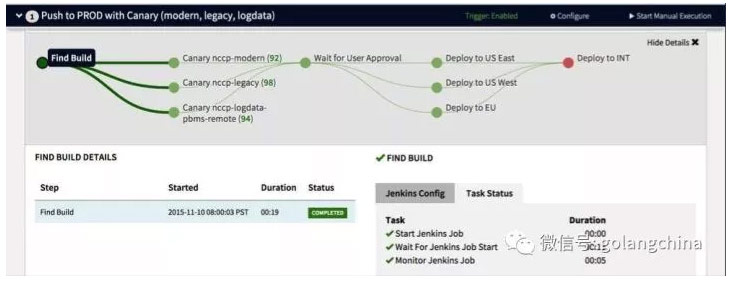
图 7
图 7是 Pipeline 的界面。首先,我觉得这个界面很好看。二是 Pipeline 可以做得非常灵活,可以说执行了前几个步骤之后,等所有的步骤执行完了再执行某个步骤。这个步骤是某个用户做某个审批,再分别执行三个步骤其中的一个步骤,然后再执行某个环节。也可以说要发布还是回退,发布是走发布的流程,回退就是回退的流程。总之在这个 Pipeline 里,你所期待的 Pipeline 的功能都可以提供。
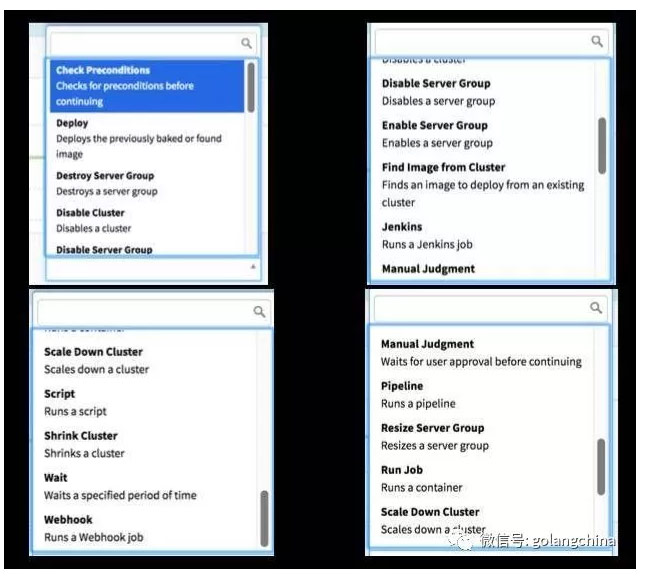
图 8
图 8 是 Pipeline Stages 的类型。左上 Check Precondltions 前置条件满足的时候才执行某个步骤。例如当前面的第一次发布里所有的实例都存活的时候,才执行某个步骤。或者当前面的步骤达到了某个状态,再执行下一个步骤。deploy是在kubernetes环境里生成replicationSet, 可以在deploy里消灭一个服务器组、禁用一个集群、把集群的容量往下降、往上升等等。也可以跑某一个脚本,这个脚本是在某一个容器里,有时候可能有这样的需求,比如说 JAVA 来说,, 这个 JAVA 跑起来之后并不是马上能够接入流量,可能要到 JAVA 里跑一个 job,加载初始数据并做些初始化工作后,才可以开始承接流量。
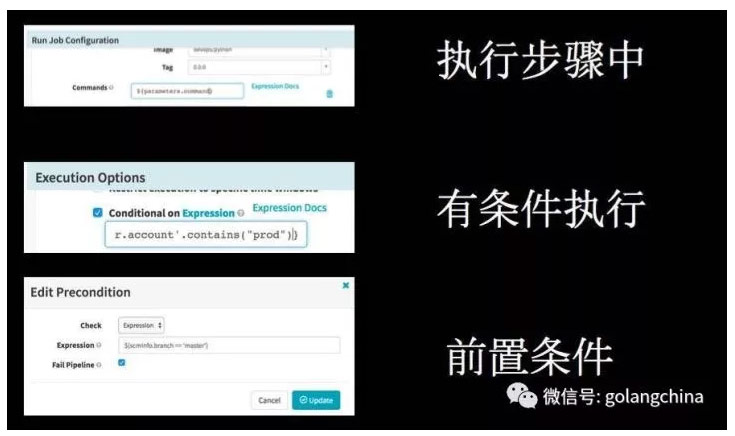
图 9
Pipeline 表达式很厉害,它的表达式是用 Grovvy 来做,大家知道 Grovvy 是一个动态语言。凡是 Grovvy 能用的语法,在字符串的地方都可以用。所以,这些步骤中,可以说这个步骤参数是来自表达式。也可以说有条件的执行,生成环境的时候才做这样的东西。也可以有前置条件,当满足这个条件的时候,这个流程和 stage 可以继续走下去。
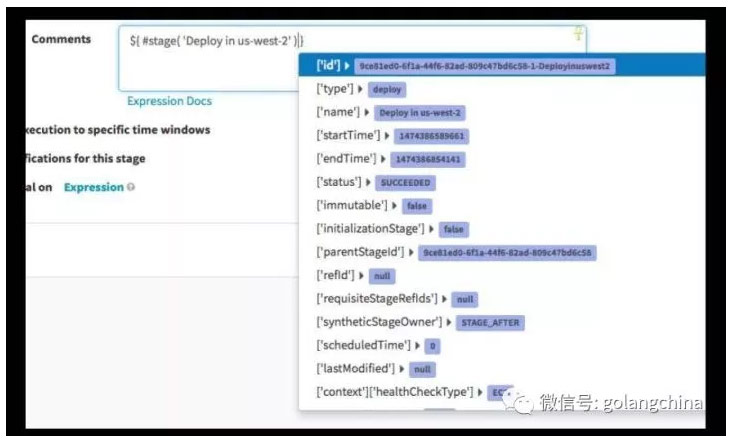
图 10
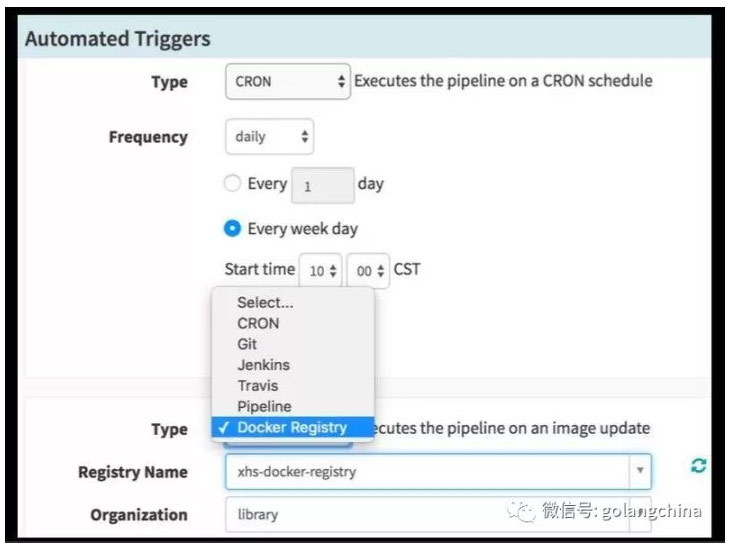
图 11
如图 10 是各种类型的表达式,从现在看起来,基本上各种要求都能满足了。Pipeline 可以自动触发(图 11),可以说每天、每周、每年、每月,某一天的时候要执行 Pipeline,做一个自动发布等等,也可以用今天新生成一个镜像的时候,Pipeline 去做发布。
Spinnaker 和 Kubernetes 的关系

图 12
Spinnaker 和 Kubernetes 有什么关系?它有很多概念是一对一的,Spinnaker 有一个叫Account,Account 对应到 Kubernetes 是 Kubernetes Cluster,现在在我们的生产环境,我们的环境里有三组 Kubernetes 的 Cluster,分别对应到开发、测试和生产,它也是对应到Spinnaker 的 Account、Instance,在 Spinnaker 里 Instance 对应到 Kubernetes 里 Pod,一个 Pod 就是一个运行的单元,它有 Server Group,这个 Server Group 对应的是 Replica Set 或者是 Deepionment。然后 Load Balance,在 Spinnaker 里称之为 Load Balance 的东西在 Kubernetes 里就是 Service。
Traefik

图 13
Traefik亮点:
- 配置热加载,无需重启
- 自带熔断功能
-traefik.backend.circuitbreaker:NetworkErrorRatio() > 0.5
- 动态权重的轮询策略
-traefik.backend.loadbalancer.method:drr
为什么我们用 Traefik 不用 Nginx 做反向代理呢?首先 Traefik 是一个配置热加载,用Nginx时更新路由规则者是做后端服务器的上线、下线都需要重载,但 Traefik 不需要。还有它自带熔断功能,可以定义后端服务错误率超过比如 50% 的时候,主动熔断它,请求再也不发给它了。还有动态的权重允许策略。一般的轮询策略是均摊,第一个请求发给 A,第二个请求发给 B,第三个请求发给 C,第四个请求发给 D,但在 Traefik 里的动态权重策略,它会记录 5 秒钟之内发给 A 的请求,是不是比发给 B 的请求更快,如果 A 处理请求的速度快过B,那接下来的 5 秒钟有更多的请求发给 A ,有更少数的请求发给B。这个过程在不断的调整,这是我们需要的功能。因为上了容器之后,整个基础的硬件环境,很难去保证所有的节点性能都是一致的。
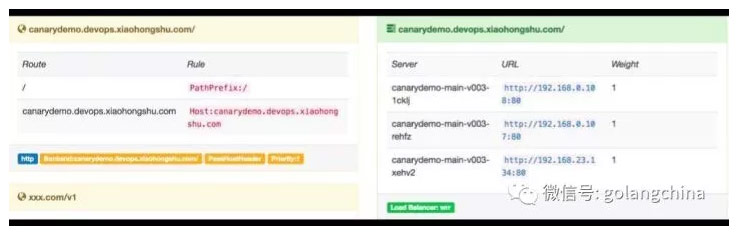
图 14
图 14 是它界面,它本身带界面。这个我们定义的规则,是pass。这个规则是本身后端的应用就是 Kubernetes 的 pod,直接打到后端应用里。
为什么在 Kubernetes 环境里选择了 Traefik?
- K8s 集群中的 Ingress Controller
- 动态加载 ingress 更新路由规则
- 根据 service 的定义动态更新后端 pod
- 根据 pod 的 liveness 检查结果动态调整可用 pod
- 请求直接发送到 pod
Traefik 和 Kubernetes 有什么关系呢?为什么在 Kubernetes 环境里选择了 Traefik?因为在 Kubernetes 是以 Ingress Controller 存在,大家知道 Kubernetes 到 1.4 之后就引进了 Ingress 的概念。Kubernetes 原来只有一个叫 service,service 是四层的负载均衡,Ingress是在 Kubernetes 里七层的实现,Kubernetes 本身不去做七层的负载均衡,它是通过 Ingress Controller 实现的,就是在Kubernetes 里就是 Ingress Controller。它可以动态加载一个 Ingress 的路由规则。刚刚说的,它根据 service 的定义,在 Kubernetes 里定义了很多 service 定义动态更显后端的 Pod,这个 service 比如说关联了这个 Pod,在 Traefik 就会把要访问的这个 service 的流量直接请求到后端的十个 Pod。
根据 Pod 的 Liveness,Kubernetes 有一个 Liveness 的概念,去检查结果,检查这个 Pod 是不是活着,是不是已经准备好能够接受请求了,然后做动态的调整。最后今天如果严肃的考虑 Kubernetes 的生产环境的使用,一定要考虑请求直接发送到 pod 这个问题,因为Kubernetes,比如说刚才说的七层请求,是 http 的请求打过来,有很多的实例跑在后面。正常一般来说,Kubernetes 原生的实现是根据 service,定义一个 service。这个叫 service 叫serviceA,service 后端的 Pod 有这么十个,在最外层用户请求进来的时候,是进入任何容器的节点都可以,这个节点访问的 service IP 和端口转发到 Pod,多一个转发的过程。Traefik 就不是这样,Traefik 可以直接把打到 Traefik,它马上就发到后端的 Pod,因为它和 Pod 直接关联起来的。
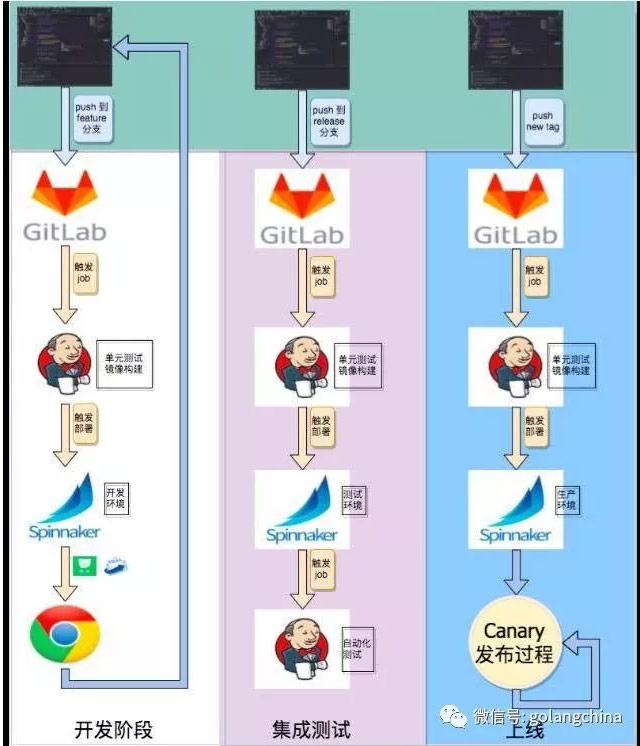
图 15
图 15 是新发布的一个流程或者是开发的流程。我们有三个环节:一个是开发阶段,一个是集成测试,一个是上线。
开发阶段,开发者在 UI 里 push,把东西推到 feature分支,这次开发迭代的时候领到一个任务,这个任务可以推到 feature 分支 。推到 feature 分支 之后,配置了一个 web hook,触发一个Jenkins job,这个 job 做单元测试和镜像构建,构建成一个 feature 分支 的镜像。生成之后这个新的镜像之后,触发 Spinnaker 的部署,这个部署只在开发环境里。
开发者怎么访问这个东西呢?比说 web 应用,如果这个程序叫做 APP1,就通过 APP1-A.dev.xiaohongshu.com 就可以访问到 Feature A 的代码。整个过程在整个周期里可以不断的迭代,最后觉得可以了,就进行推送到 release。一旦把代码推往 release 就触发构建,基本上差不多。最后会有一个自动化的测试,基本上是由测试团队提供的自动化测试的工具,用 Spinnaker 调用它,看结果是什么样。
如果今天很有信心了,决定往生产发了,可以生成一个 tag,比如这个 tag 是 0.1.1,今天要发0.1.1版了,同样可以触发一个镜像的构建。这三个不同的阶段构建的镜像 tag 不一样,每生成一个 新tag, Spinnaker 会根据tag的命名规则触发不同的 pipeline, 做不同环境的部署。
Canary
最重要的是我们有一个叫 Canary 的发布过程,我们在 Spinnaker 的基础上,开发了一套 Canary 的机制。Canary 和 Beta 差不多,但 Canary 是真实引入流量,它把线上用户分为几类:一是比较稳定的流量用户;二是这些用户稍微可以牺牲一点,帮我测试某一个新版本,我们的实现就是先给公司、先给办公室的人来用,等办公室的人用得大家的反馈都 OK,没有什么问题,看看监控数据也觉得没有问题,才开始在线上做发布了。
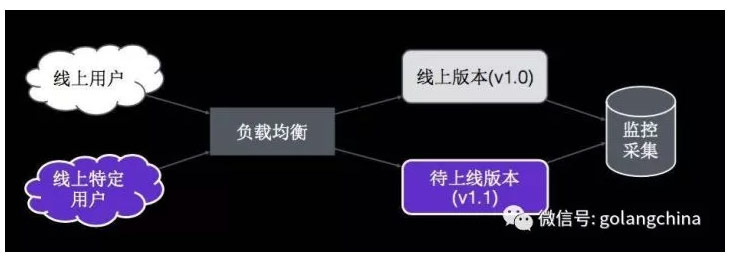
图 16
这个是 Canary 的意思,线上用户还是线上特定用户分成两组,线上用户访问老版本,特定用户通过负载均衡转发到特定的版本里,在后面有监控及和比较两个版本之间的差异。
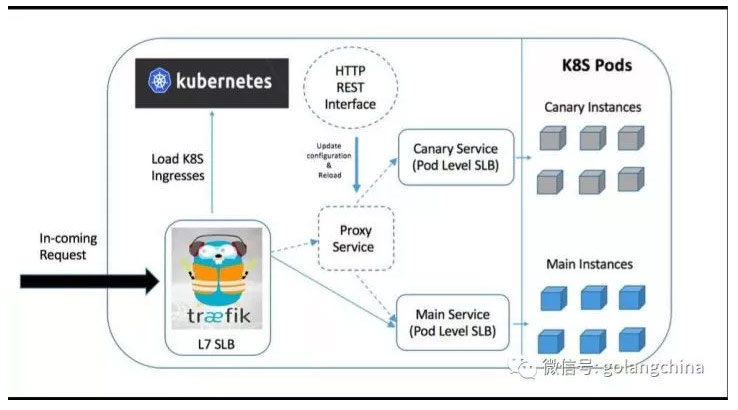
图 17
这是在容器环境里实现的 Canary 的机制(图 17),用户请求从前面进来,首先打到 Traefik,如果没有做 Canary 的过程,Traefik 是直接把请求打到组实例。如果要发布一个新的版本,有一个 http 的 API 控制 project service,决定把什么样的流量可以打到这个里面版本。我们的策略可能是把办公室用户,可以通过 IP 看到 IP,或者把线上的安卓用户,或者线上 1% 的安卓用户打给它,这些都是可以定义的。
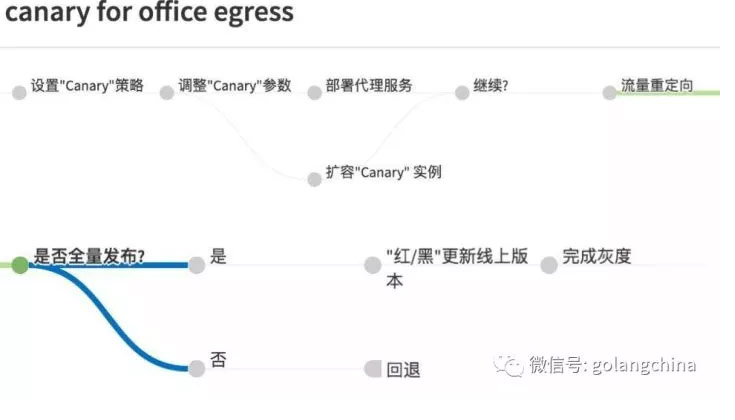
图 18
如图 18 所示是线上真实的部署流程。首先是要设置一个 Canary 策略,这个策略是完全随机还是根据用户的特定来源。比如说是一个办公室用户,还是上海的用户,还是北京的用户等等,然后去调整参数,是 1% 的北京用户,还是所有的北京用户。然后开始,我们是部署在服务器。然后把这个 Canary 实例做扩展,在流量进来之前,实例的容量一定要跟着上线。进来之后把流量做重新定向,把流量原来直接打给后端的 Pod,打到代理服务器。整个过程不断的迭代,有 1% 的线上用户,最后 2%,10%、50%、100%,最后就是全量用户。在全量过程中是采用红黑版本,先把所有的新版本老版本的实例数生成出来,等所有的新版本通过健康检测,都在线了,旧的版本再下线,这样完成一个灰度。如果不行的话,马上就可以回退,所谓的回退就是把 Canary 下线,把流量打到线上版本去。

图 19
图上(图 19)是我们的 Canary 策略。这是我们自己实现的一套东西。就是说我们把这个网段一半的 IPhone 用户,首先它是 IPhone 用户,它的在这个网段,这个 1000 和这个 1000 有各自的权重,最终实现的结果在这个网段里一半的 IPhone 用户进行灰度,整个灰度的维度可以有很多。现在我们支持的是完全随机,要线上的 1%、2%,不管是谁,反正是随机的,可以支持从 IP 来的,可以支持是什么设备,是 IPhone 还是安卓,维度可以组合起来。
我们实现的灰度是业务要求,如果是灰度,这个用户必须从头到尾,即使是随机,比如说 1%线上的随机。1% 的用户灰度的话,永远需要灰度,不会是说 1%的全局请求会去到灰度,而是 1%的用户,这个用户是固定的。
下一步打算
- ACA – 自动灰度分析
- 自动容量管理
下一步我们打算做几件事情:第一,我们想做自动灰度分析,叫 ACA, 现在很流行所谓的 AIOps,自动灰度分析可以说是一个最具体的 AIOps 落地了。在灰度的过程中,现在是人肉判断新版本是否正常,其实如果日志采集够完整的话,这个判断可以由机器来做。比如说今天发布新版本,响应时间比旧版本增加了 100%,显然这个灰度会失败,就可以终止这个灰度,不用人去判断。第二,再往下可以做自动的容量管理,当然是基于 Kubernetes 的基础上,做自动容量管理。
最后总结一下: 我们倾向于采用开源的方法解决问题,如果开源不够的话,我们再开发一些适配的功能。谢谢大家!以上就是我的讲解。
来源:Go中国

Traefik 还不如用Kong 或者fabio,完全抛弃掉service