
黄惠波,腾讯互娱高级工程师
目前主要负责游戏计算资源容器化平台的研发工作,包括kubernetes/docker研究以及定制化开发,主导腾讯游戏万级容器资源调度平台的建设工作。
大家好!今天我分享的主题与游戏行业相关,为大家介绍的是kubernetes在腾讯游戏中的应用实践。
腾讯在线游戏的容器化应用场景
2014年,我们开启了容器化探索之路,先回顾一下之前遇到的一些问题。
在物理机时代,资源的交付时间较长,资源的利用率较低,也不能做到隔离。到了xen\kvm虚拟机时代,问题得到了初步的解决,但在弹性伸缩方面仍有不足。随着Docker技术的兴起,我们开始调研Docker在游戏容器化方面的应用。我们的目标有两个,一是提高资源利用率,二是通过Docker镜像来标准化部署流程。
选择Docker技术之后,我们开始了容器调度平台的选型。我们当时也调研了其它的一些组件,比如Shipyard、Fig等,但这些组件无法支撑海量游戏容器调度。而自建调度平台的话,时间成本非常的高。就在那时,Google开源了kubernetes(当时的版本是kubernetes v0.4),我们基于这个版本进行了定制和开发,使其成为我们游戏容器的调度管理平台。
在2015年初的时候,TDocker平台上线。之后,我们开始逐步接入业务。一开始的模式非常简单,就是把Docker当成虚拟机来使用,但这不意味着游戏全容器化的实现。
大家知道,对于一项新技术来说,大家都很谨慎,会通过不断的灰度上线,由点到面的策略推动。截至目前,在全国各地以及加拿大等地区,都有我们的部署点;接入容器数超过两万,接入的业务也有两百多款,包括手游、端游、页游。在这么多的业务中,主要分为两种场景,第一种场景是轻量级虚拟机模式,这类容器承载多个服务进程,需要一个具体的内网IP,可以通稿SSH登录。另一种是微服务化模式,这种模式会拆分得非常细,每一个容器对应一个服务进程,不需要对外可见的内网IP,可以使用虚拟IP。
接下来会对每一个场景做一些分享。首先来看一下传统游戏下的架构。这是非常典型的三层服务架构,包括了接入层、逻辑层、数据库层。同时,游戏又分为:全区全服、分区分服两种类型。对于分区分服类游戏,滚服对资源的调度非常频繁,所以我们需要一个高效的调度平台。
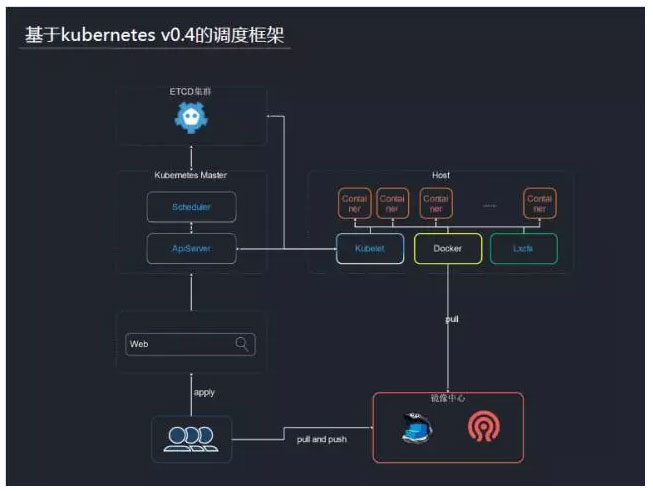
容器资源的调度管理基于kubernetes v0.4版本,上图是一个简化后的调度框架。在Master端包括ApiServer和Scheduler,接收Web请求,然后做资源调度。在每个node节点上,包括agent进程、Docker进程,还有Lxcfs进程。在镜像存储方面,当时用的是Registry V1版,后端用的是ceph存储。现在,我们自己维护了一个分支,功能上已满足当前的游戏需求,并保证运行的稳定。所以在虚拟机模式下,我们不会升级kubernetes,而是把一些好用的功能合并进来。
基于kubernetes的功能定制与优化
首先讲调度器,调度器为数以万计的容器提供了一个灵活、稳定、可靠的底层资源计算调度引擎。资源的合理分配像是一场博弈,里面有很多矛盾的地方,需要我们根据游戏的特点做取舍。
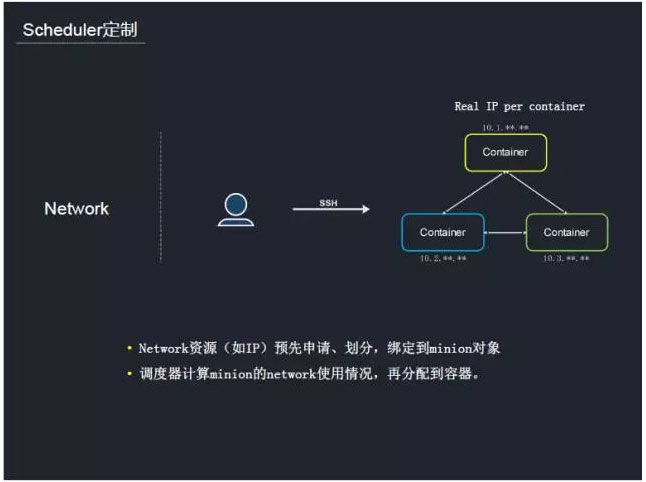
我们在原有的调度策略上根据游戏特点做了一些定制。比如在网络方面,传统游戏的每个容器都需要一个对外可见的实体IP,用户可以通过SSH登录到容器里面,因此对网络资源进行调度。部署容器的时候,会申请network的资源(比如IP)然后进行划分,绑定到minions对象。这样调度器调度的时候,就可以通过这些配置信息给容器分配好网络资源。
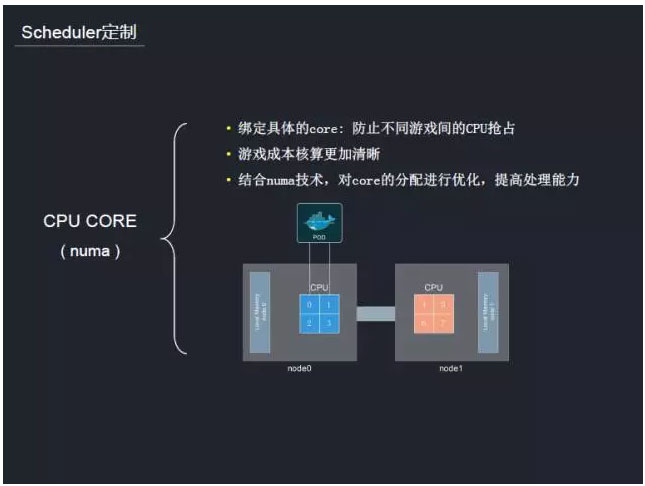
在社区中,CPU的分配用的是共享CPU的方式,游戏采用的是一种混部的模式。也就是说,将不同游戏业务部署到同一台母机,采用绑定核的方式。这样做一方面可以防止不同游戏之间的CPU抢占,另一方面对游戏成本的核算也会更加精细。例如,某个游戏用了多少CPU这些指标都是可以量化的。在容器分配CPU时,结全numa技术,对于CPU CORE的分配会尽量地分配到同一个numa node上,这样可以提升性能,因为同个numa node的CPU访问只需通过自身的local memory,无需通过系统总线。

在磁盘容量分配方面,由于游戏业务是有状态的服务,需要存储,所以我们把磁盘也作为一个可调度的资源分配给容器。还有非亲和性的调度。我们知道,在容器的可靠性与碎片优化之间需要一个权衡,让用户根据这些策略去选择、部署自己的容器。例如在非亲和性的策略中,用户希望把容器是分散到各个母机上的,在母机宕机时,可以减少对游戏的影响。
在IDC Module分配方面,游戏容器的部署会按地区划分,比如按照上海、深圳或天津地区的IDC来划分,所以我们提供了IDC部署策略。由于游戏需要考虑IDC的穿越流量问题,还有网络延时的问题,所以同一个游戏的的不同模块一般会部署到同一个IDC Module下面。
海量应用过程中遇到的问题与解决方案
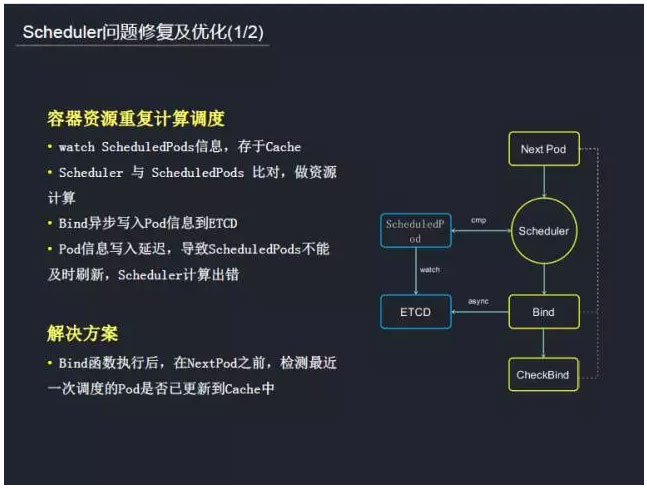
以上是基于游戏行业特点定制的调度规划。在资源调度过程中,也遇到过一些问题,例如容器资源的重复调度。首先在调度过程中它会跟ScheduledPod(已完全调度的容器)进行比较,判断现在是不是有足够的资源分配给待调度容器,最后通过Bind(异步)把Pod信息写入到ETCD。这里就会出现一个问题,那就是异步写入慢了或者ScheduledPod同步慢了导致ScheduledPods不能及时刷新,Scheduler计算出错,从而造成资源重复计算。针对这个问题,我们的解决方案是在资源调度完成后,做一个检测的逻辑,检测调度的容器信息是否已在ScheduledPod Cache这里,然后再进入下一个容器的调度。当然这会带来一定的性能损耗。
解决了这个问题,又产生了另外一些问题,那就是性能的问题。在0.4版本的pod接口是非常低效的,在查每一个pod状态的时候,会通过实时查所有的Host来确定,设计不太合理。社区也做了一些方案,当时我们也是参考了社区的一些方案做了一些改造,把pod状态放在Cache里面,定时更新,从而提高查询效率。
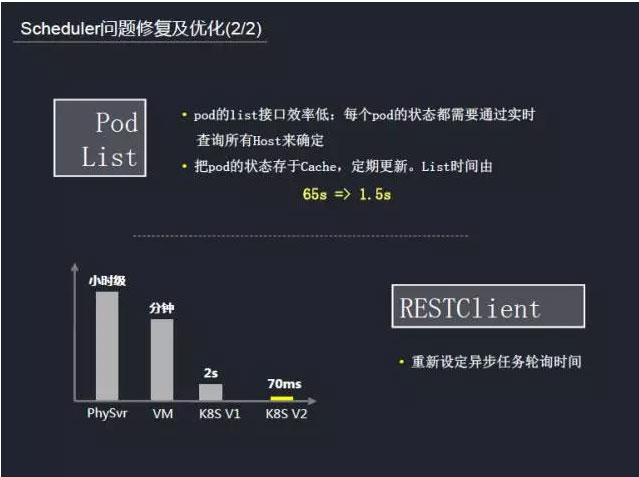
还有一点就是RESTClient。在kubernetes中,rest API大部分是异步进行,对于这些异步的接口的请求,并不会立刻返回结果。这里有一个轮询检测状态的逻辑,在检测轮询的时候有几秒的休眠,然后进再行下一个轮询。默认的休眠时间是2秒,这个时间对大部分场景来说有点过长,我们通过一些功能点的调整,从物理机的小时级到虚拟机分钟级的调度,再到还未调整之前的秒级调度,到现在达到的毫秒级调度,现在的调度能力已能满足游戏的需求。
讲完调度,再看一下网络方面。网络是非常关键、也是最为复杂的一环。在虚拟机模式下,结合公司网络环境为游戏提供高性能、稳定的网络环境,包括Bridge+VLAN\SR-IOV两种方案。
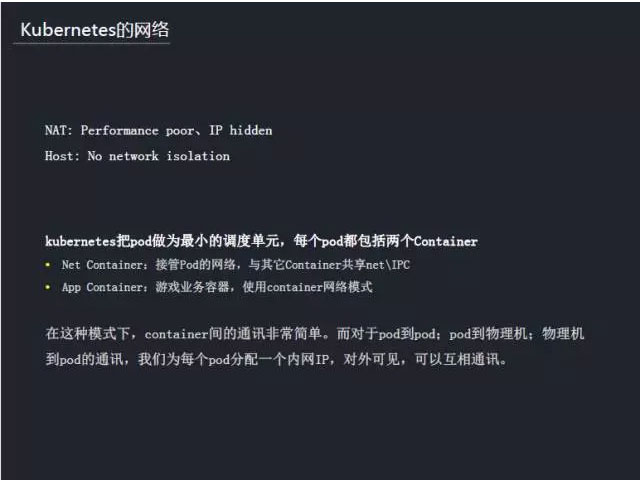
先来说,Docker的网络还有kubernetes的网络。对于Docker的NAT网络来说,性能是最大的瓶颈,同时它与物理机或虚拟机的通信路径不一致也会对业务带来一些未知的影响。比如,外界不能看到容器真实的IP(必须要使用主机IP+port方式,端口本身就是稀缺资源,并且ip+port的方式,无疑增加了复杂度),TGW仍然可以为业务程序服务。Host模式没有隔离,也不符合需求。在kubernetes中,pod作为最小调度单元,每个pod有两个容器,一个就是网络容器,接管pod的网络,提供网络服务,并与其它容器共享net\IPC。另一个是App Container,也就是业务容器,使用第一个网络容器的网络。在这种模式下,容器之间的通讯是非常简单的。对于pod到pod、pod到物理机、物理机到pod的通讯,我们为每个pod分配一个内网IP,对外可见,也可以互相通讯。
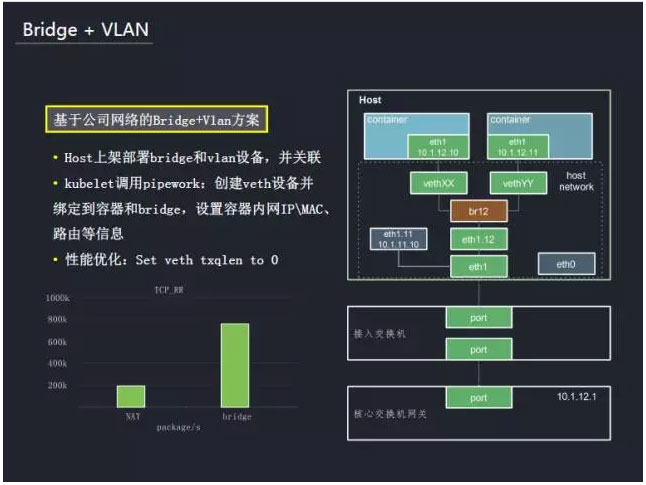
接下来,通过两个方案给大家分析。首先是Bridge+Vlan的方案,母机都是部署在虚拟化区上,通过Vlan做网络的隔离。在母机上架部署时,创建Bridge设备和VLAN设备并将它们进行关联。创建容器的时候,使用pipework脚本创建容器所需要的虚拟网卡设备,并把它们绑定到容器和Bridge上,同时会设置容器内的IP、MAC地址以及路由等信息。从而打通容器到外界的网络通信。这里也做了一些优化以提高性能,这里可以看到一个性能的对比,其中Bridge相对NAT网络有相当大的提升。这种方式可以满足一部分游戏的需求,而有一些业务,像FPS、Moba游戏等大流量,对网络要求非常高的业务,还有类似MySQL-Proxy这种组件,在Bridge场景下是无法满足需求的。
所以我们探索了另一种网络方式,就是SR-IOV模式,这种模式在zen\kvm虚拟化上用的比较多,游戏也需要这种网络方案,因此我们把这种网络方案也结合到Docker容器里面。
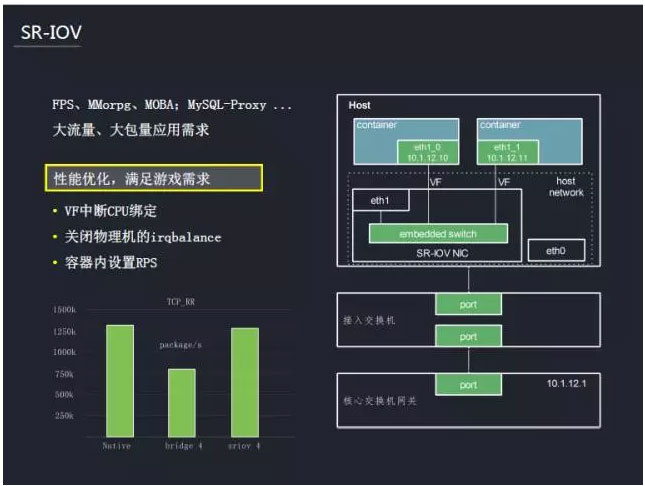
这里需要硬件的支持,结合SR-IOV技术的网卡,在Docker容器内就可以直接通过驱动来加载虚拟的网卡并使用。使用的方式就如同在一台物理机上使用一个真实的物理网卡一样,这个虚拟网卡也拥有驱动程序,也拥有PCI BUSID,因此所有的虚拟机网络操作都如同操作普通网卡一般,从而在性能上得到提升。为了进一步发挥SR-IOV的网络性能,还需要对容器的相关网络参数进行配置,主要包括以下几个方面:VF中断CPU绑定;关闭物理机的irqbalance;容器内设置RPS(软中断均衡)网卡不能中断均衡,对高性能的网络形成了阻碍。为了解决这个问题,需要设置容器内的软中断均衡。通过上述的调整,性能得到了大幅度提升。
这是我们测试的一个结果,这边是物理机的,这是Bridge,这是SR-IOV,SR-IOV在网络性能方面基本上已经接近了物理机,所以这个对于游戏大包量、大流量的应用是非常适合的,现在我们把SR-IOV网络作为传统游戏里默认的网络模式。
在游戏容器化过程中,我们希望资源的使用是明确的、合理的、可量化的。所以我们会为每个容器分配固定的资源,比如多少CPU、多少内存,还有需要多大磁盘、IO带宽。在启动容器的时候,比如CPU/Memory,通过Cgroup去做一个限制,disk通过xfs quota去做配额的限制。还有Buffered-IO带宽的限制。
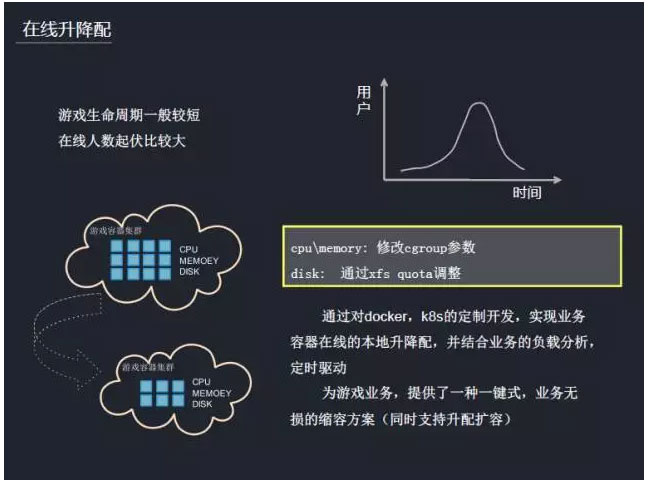
在资源分配方面,我们开始做的是限定的CPU、内存的分配。在容器的整个生命周期,这个配置并非一沉不变,比如在业务运行过程中都会有一些起伏和动态调整,这是游戏的一张生命周期图像,生命周期比较短,可能是一年半载的时间,而且这里在线人数起伏也会比较大,需要动态调整。而动态调整就会涉及两个方面,一是横向的水平扩展,二是垂直伸缩。
每个游戏都会有一个IP,因此横向拓展比较困难,因而更倾向于稳定的垂直扩缩。在虚拟化时代,扩缩容是有损的,需要重启机器来实现,而Docker可以做到无损的扩缩容。我们对这个需求做了一些定制开发,比如CPU或者内存,通过修改Cgroup的配额去把它提升上去或是削减下来。
当在线人数上来的时候,我们可以给业务做到无损扩容,不影响业务服务。过了一段时间,当人数降下来时,资源会闲置,我们会对空闲的资源做一些重复利用,将其回收。这个时候做一些缩容,针对缩容我们做一个常态的动作,检测这些容器的CPU、内存,结合业务的负载、活动、定时驱动。
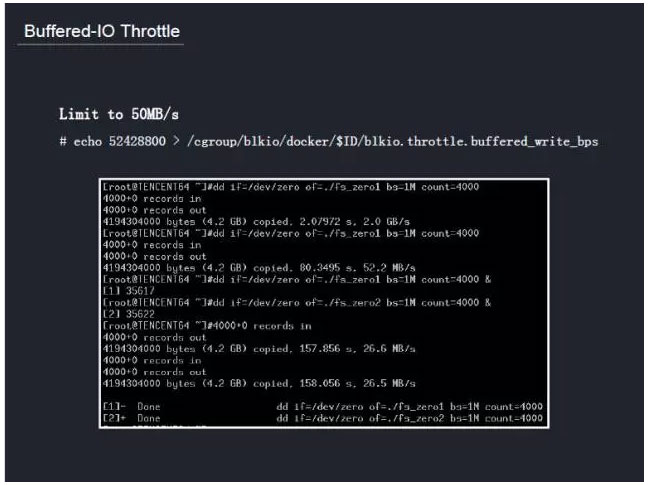
Buffered IO Throttle需要内核支持,我们与内核团队进地了紧密的合作,提供了支持 Buffered IO Throttle功能的内核版本。根据容器在母机资源的占比分配一定比例的IO带宽。这在某种程序上解决了游戏之间互相影响的问题。
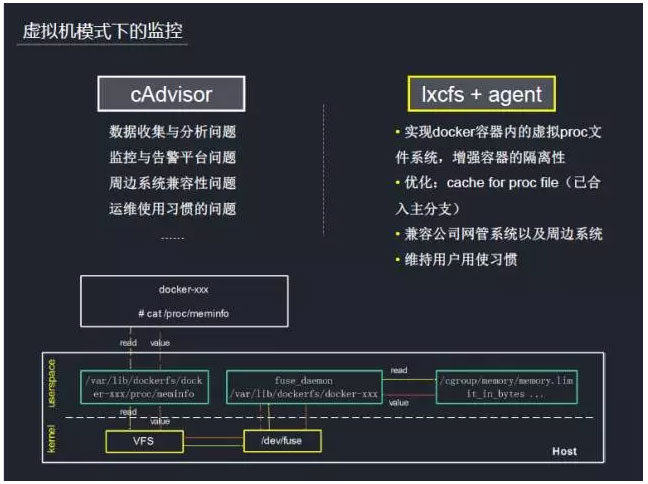
监控、告警是整个游戏运营过程中最为核心的功能之一。容器上的监控有别于物理机,cAdvisor和kubenetes结合得比较紧密,是个不错的方案。但它也会带来问题,那就是需要自建监控平台,而且它与周边各系统的兼容性也有待考验,同时改变运维的使用习惯也需要时间。综合考虑各种因素后,我们放弃了cAdvisor,重新调研其它方案,希望可以沿用公司成熟的监控平台,而且兼容周边系统。最终我们选用的是lxcfs + 公司agent的方案,通过lxcfs去实现Docker容器内的虚拟proc文件系统,增强容器的隔离性。
我们这里以meminfo内存统计信息为例,为大家讲解如何通过lxcfs用户态文件系统实现Docker容器内的虚拟proc文件系。挂载虚拟proc文件系统到Docker容器,通过Docker的volume功能,将母机上的/var/lib/dockerfs/docker-xxx/proc挂载到Docker容器内部的虚拟proc文件系统目录下/proc/。此时在容器内部/proc/目录下可以看到一些列proc文件,其中包括meminfo。用户在容器内读取/proc/meminfo时,实际上是读取宿主机上的/var/lib/dockerfs/docker-xxx/proc/meminfo挂载到容器内部的meminfo文件。内核VFS将用户请求转发到具体文件系统——fuse,fuse文件系统封装VFS请求,将请求转发给Fuse设备(/dev/fuse)。如果设备上有已经处理完成的请求(例如Cache),文件系统获取处理结果并返回给VFS,VFS再反馈给用户。用户库(fuse daemon)直接访问Fuse设备,读取文件系统转发到设备上的请求,分析请求类型,调用用户接口处理请求,处理完成后将处理结果返回给设备,再由设备返回给VFS,VFS再反馈给用户,从而实现容器内的隔离。公司agent可以通过读取memory等信息,上报到监控平台做分析与报警。同时运维通过SSH登录到这个容器,通过free、top等命令查看性能,维持了运维原来的使用习惯。

在传统游戏里,更多的是有状态的服务会涉及到数据的存储,我们通过Docker的volume提供持久化存储。最开始我们采用HostPath方式,把host上的目录挂载到容器里(例如/data)作为数据存储。这种做法非常方便、简单,无需额外的支持,但数据的安全性、可靠性方面比较差。所以我们采用了另外一种方案,即Ceph。改造kubenetes支持ceph,通过volume挂载,提供更安全、更可靠的数据存储方案。解决在host故障时,数据丢失的问题,应用场景也变得更加广泛,包括数据库存储,镜像存储,容器迁移等。

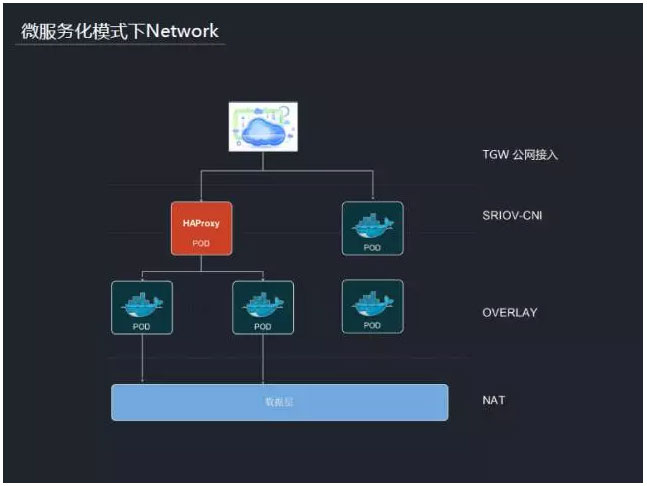
今年,我们开始支撑第一款微服务化游戏(极品飞车online),源于之前对kubernetes的使用经验。在微服化容器的调度中我们沿用了kubernetes,但在版本上重新做了选择,跟随着社区的发展,选用了v1.2版。在微服务化模式下,游戏的架构产生了很大的变化。按功能细分到各个小模块,通过镜像交付、分发,最后以容器来部署服务。每个模块相对独立,之间信息流交互通过消息组件(例如RabbitMQ)来实现。同时每个容器无须配置内网IP,可以通过域名来访问。所以在网络方面也有所调整,我们也评估了docker overlay、flannel、vxlan、maxvlan、SR-IOV等,结合其中的优缺点,最后我们选定的方案如下:
1、集群内pod与pod的之间的通信,由于不需要内网IP(可以用虚拟IP)所以采用overlay网络,由flannel组件实现。
2、公司内网到集群内pod通信,例如HAProxy,游戏某些模块,采用SR-IOV网络,由自己定制的sriov-cni组件实现。这类pod具备双重网络,eth0对应overlay网络,eth1对应SR-IOV网络。
3、pod到公司内网之间的通信。在微服务场景下,游戏的数据存储,周边系统等,部署在物理机或者虚拟机上,因此pod到这些模块、系统的访问,走的是NAT网络。
4、公网(Internet)接入,采用公司的TGW方案。
在整个微服化平台上,涉及到的关健技术点会更多:
1、网络方案:即上述讲到了overlay + SR-IOV + TGW + NAT方案
2、日志,监控:对于微服务化架构的游戏,版本的交付都是通过镜像,不会把公司的agent打到镜像,所以原来的lxcfs + agent监控就不适应了,所以这里我们重新打造了一个新的日志、监控平台,与蓝鲸团队合作,实现了游戏业务日志采集;容器健康状态、性能的监控
3、高可用方案:在资源的部署方面,我们采用了replication controller方式,通过kubernetes的controller manager模块来监测pod的状态,在发生故障的时候,实现快速的迁移、恢复服务。另一方面,在load balance场景下,我们采用了HAProxy来实现
4、安全方面:kubernetes集群承载着整个游戏容器资源的调度、管理。不管是人为误操作,还是黑客入侵,造成的影响将是非常之大。所以安全是我们需要考虑的重点,结合kubernetes,我们目前做了以几方面,后面会有更加的安全策略提供。
4.1 Authentication 和 Authorization。使用https来加密流量,同时在用户权限验证上,提供了token验证方式、ABAC权限认证方式
4.2 Admission Controllers:配置具体的准入规则
4.3 ServiceAccount:主要解决运行在pod里的进程需要调用kubernetes API以及非kubernetes API的其它服务问题
5、配置管理:通过configmap\secret为游戏提供简易的配置管理
6、服务发现:kubernetes会为每个pod分配一个虚拟的IP,但这个IP是非固定的,例如pod发生故障迁移后,那么IP就会发生变化。所以在微服务化游戏架构下,业务pod之间的访问更多地采用域名方式进行访问。在kubernetes生态链中,提供了skydns作为DNS服务器,结合kubernetes的server可以很好的解决域名访问问题

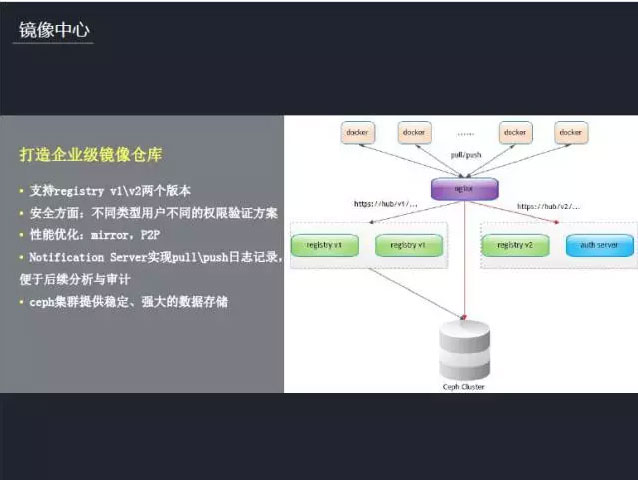
开始讲游戏容器化的时候谈到用镜像来标准化部署,所以我们花了很多时间打造企业级的镜像仓库。目前支持registry v1\v2两个版本,如右图所示,在client端(docker)与registry之间采用nginx作为代理,实现v1\v2不同请求的转发,这样一来,用户无需关心到底请求的是v1还是v2。在安全方面,不同类型用户不同的权限验证方案。公司内部用户接入OA认证,与公司平台打通。外部用户需要申请访问权限,由管理员分配帐号,然后通过分配的帐号来请求。在大批量拉取镜像的时候,镜像中心的性能、效率是我们需要考虑的问题。前期我们通过mirror方案来实现,在主要城市部署mirror registry,通过就近原则来拉取镜像,解决性能瓶颈。后续我们还会采用P2P方案来提升镜像拉取性能。同时我们定制了Notification Server,用于镜像pull\push日志记录,便于后续分析与审计。在镜像后端存储方面,采用ceph集群方案,从而提供稳定、强大的数据存储。
微服务化之路我们刚刚起航,在面临挑战的同时也带来了机遇。不仅仅是在线业务的探索,我们也会探索离线计算、深度学习等系统的支持。

来源于社区,回馈于社区。后续我们还会更多地参与社区互动,为社区做贡献。这也是我们想去做的一点。目前有个开源的项目,sriov kubernetes的网络插件(https://github.com/hustcat/sriov-cni),集中了腾讯游戏两种模式下容器的高性能网络经验,大家感兴趣的可以关注下。

登录后评论
立即登录 注册