
一个有效的Kubernetes容灾解决方案需要具备:
- 容器粒度的控制
- 能够备份数据和配置
- Kubernetes命名空间感知
- 针对多云和混合云架构的优化
- 保持应用的一致性
容灾解决方案必须满足以上五个标准,才能确保Kubernetes上运行的含大量数据的应用程序在容灾恢复的时候,满足服务水平协议(SLA)或相关法律要求。
让我们分析一下为什么这五个标准都很重要。
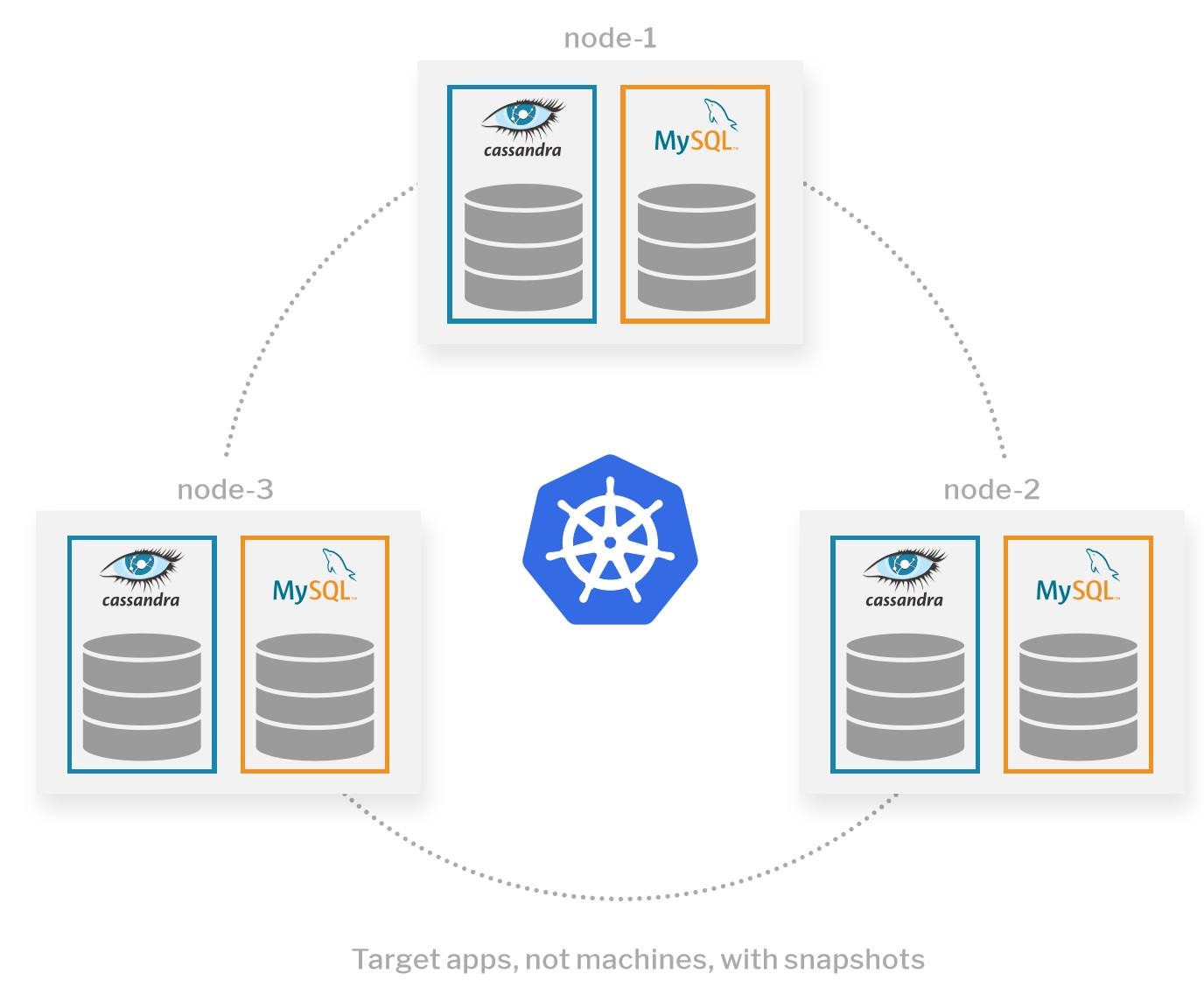
使用容器粒度的方式,可以在三个VM上仅备份一个PostgreSQL数据库或三节点Cassandra环,而无需其他任何备份。
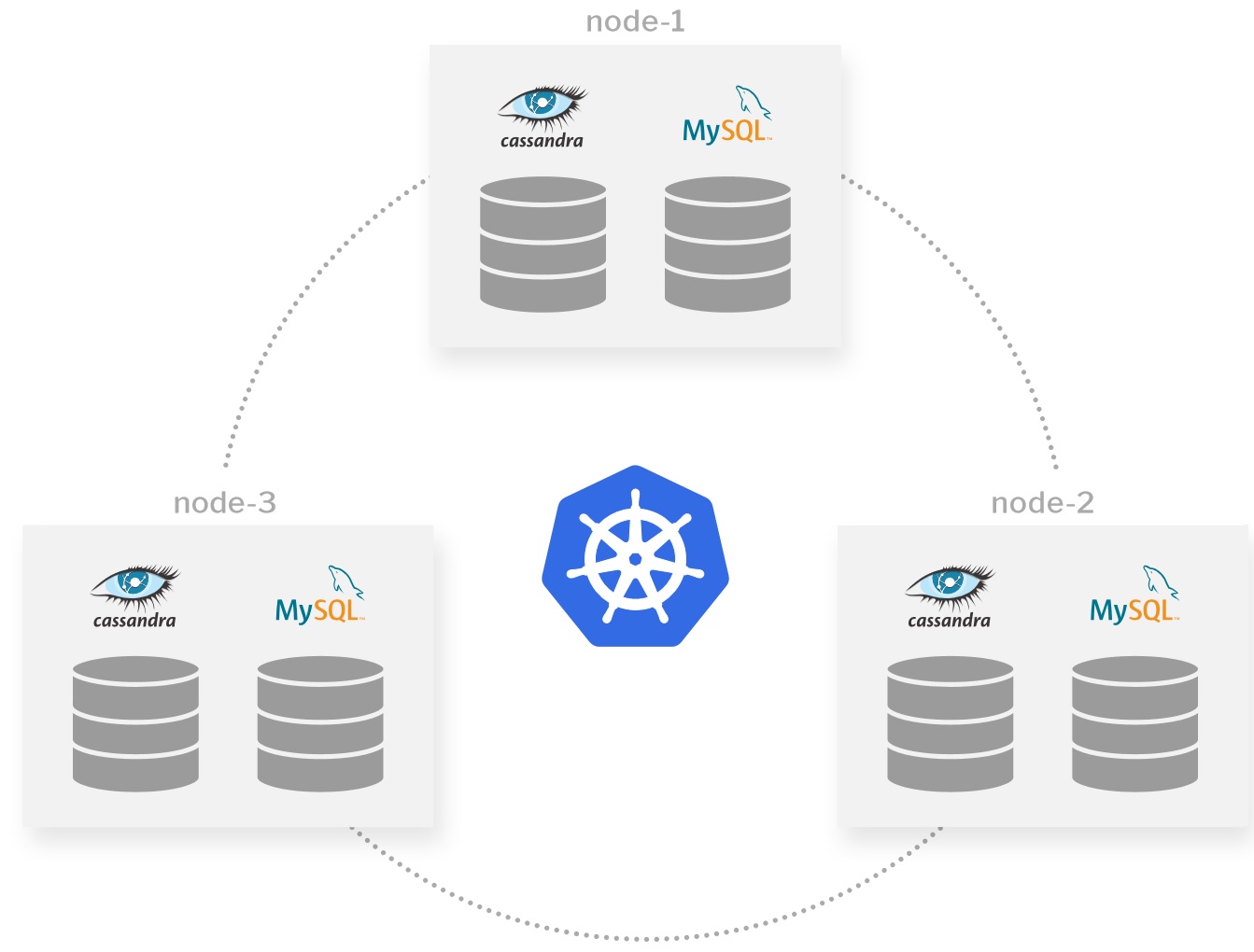
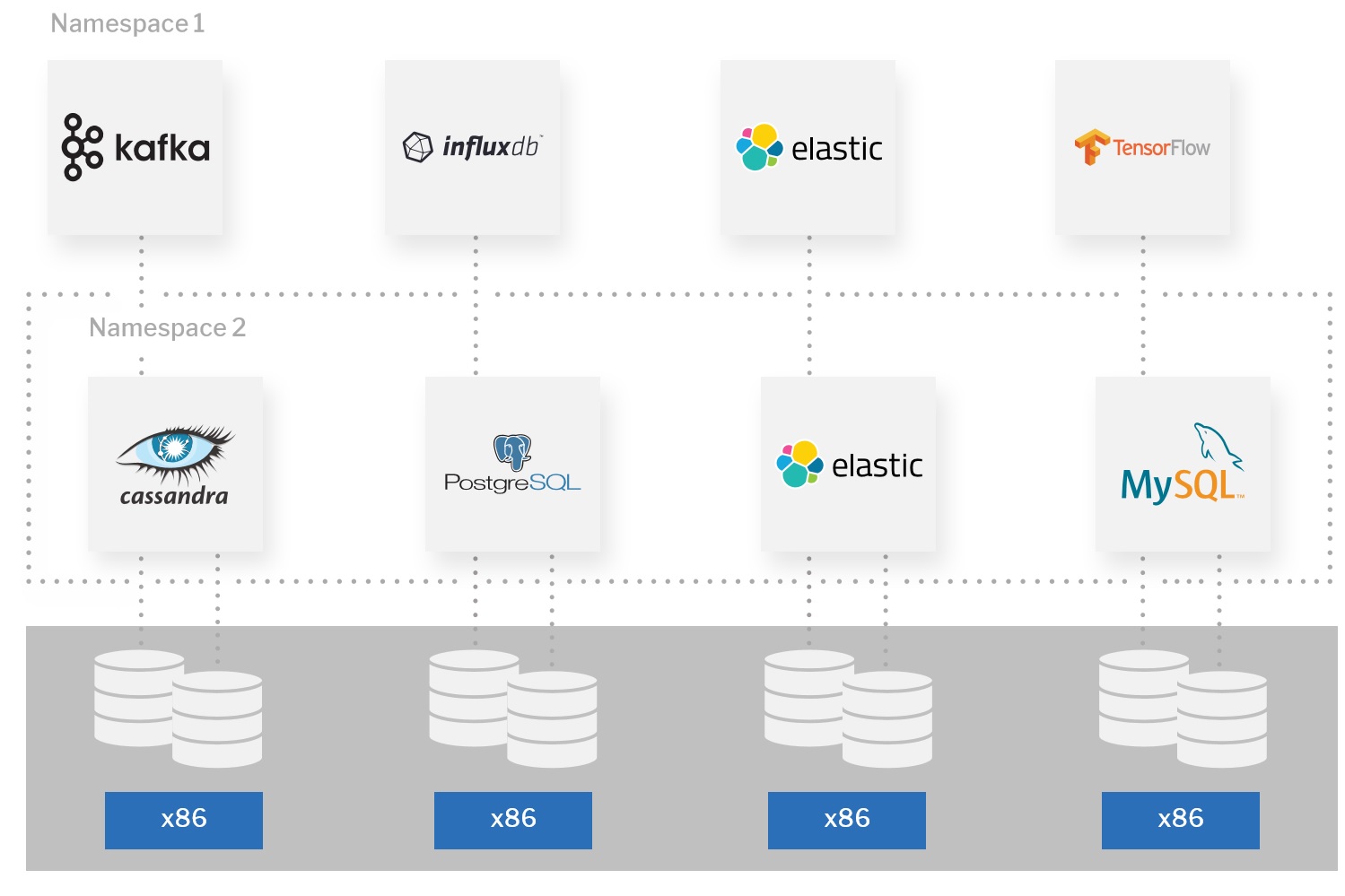
Kubernetes中的命名空间通常运行多个相关的应用程序。例如,企业Kubernetes部署中的一种常见模式是使公司/部门所有的应用都运行在同一个命名空间内。在这种情况下,通常有必要一起备份Kubernetes命名空间中的所有应用程序。
成功的快照,要使数据损坏风险最小化,并必须保持分布式架构的应用的一致性。这意味着在锁定属于应用程序的所有Pods的同时,来执行快照。

数据和配置备份
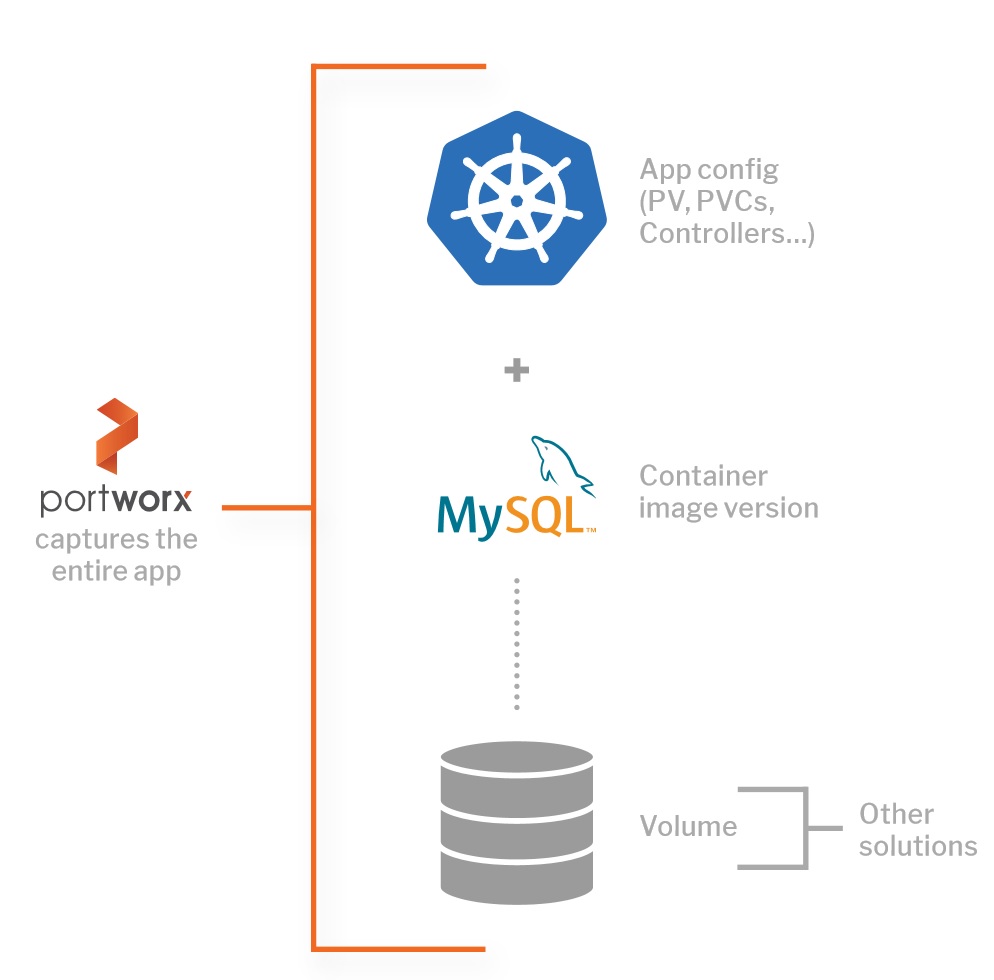
这需要备份应用数据和配置信息。如果备份中不包含配置信息,则必须就地重建应用程序,这是一个缓慢,手动且可能容易出错的过程。但是,如果仅保存配置,则可能会丢失所有数据。
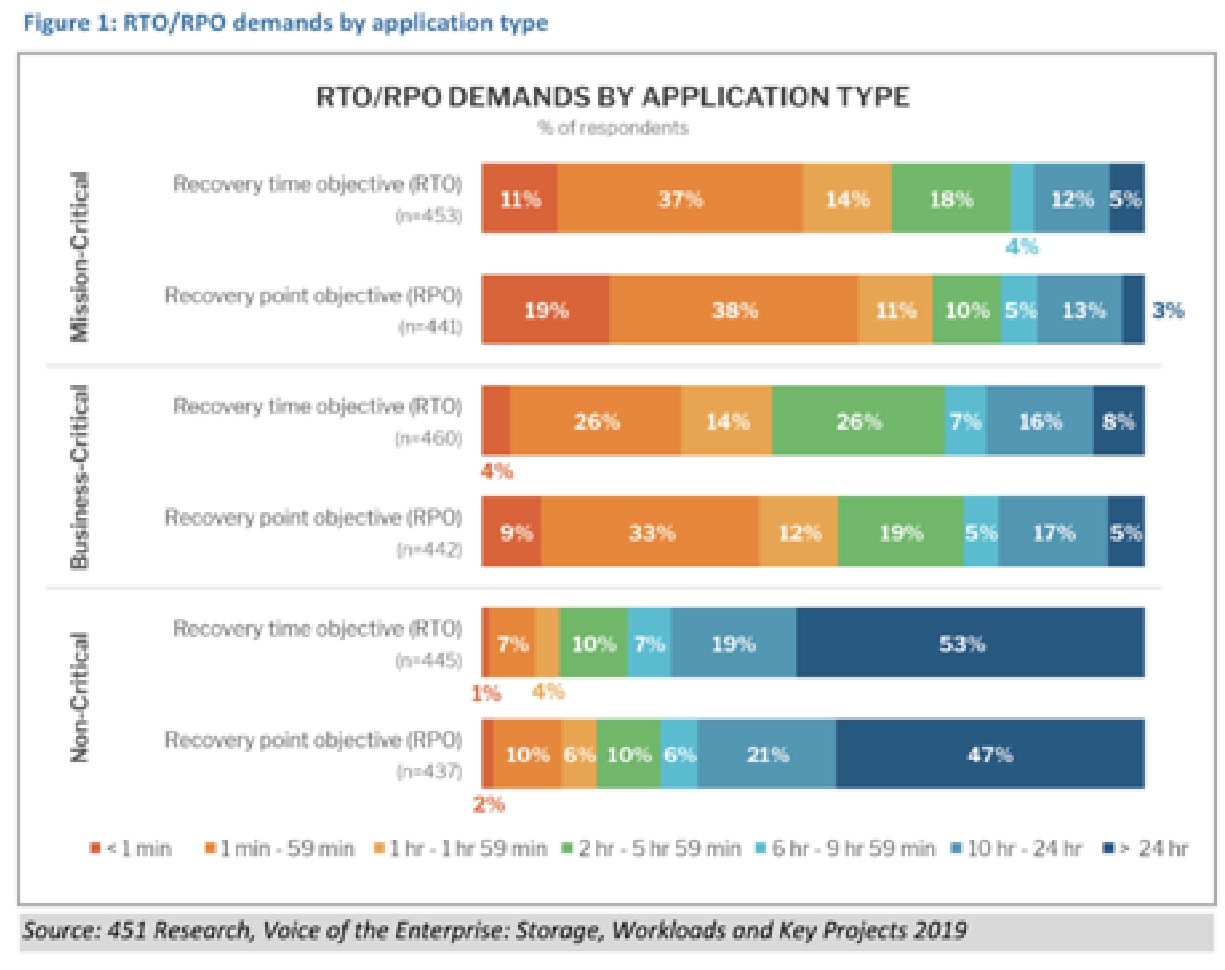

在某些情况下,企业希望主站点和备份站点之间的地理距离远一些。在这种情况下,RTO仍可以为零或接近零。但是延迟的增加,同步复制数据会产生比较大的性能问题。如果应用能够接受15分钟或1小时的RPO,则也是可接受的容灾方案。
Kubernetes的企业级容灾恢复方案,应为用户提供适用于多云或混合云架构的,同步复制或异步复制的选择。这样可以使用户能够基于自己的数据中心架构和业务需求情况,来选择不同的容灾恢复方案。
但它需要采用专为Kubernetes设计的容灾方法,与Kubernetes的工作方式深入结合。传统的基于VM的容灾解决方案无法做到这一点。
Portworx Enterprise 存储平台是专门为容器和Kubernetes构建的。它可为Kubernetes上运行的应用实现零RPO和接近零的RTO容灾恢复。并具有容器粒度控制的,命名空间感知的,应用一致性的容灾恢复。故障恢复可以完全自动化,从尽可能降低RTO。

登录后评论
立即登录 注册