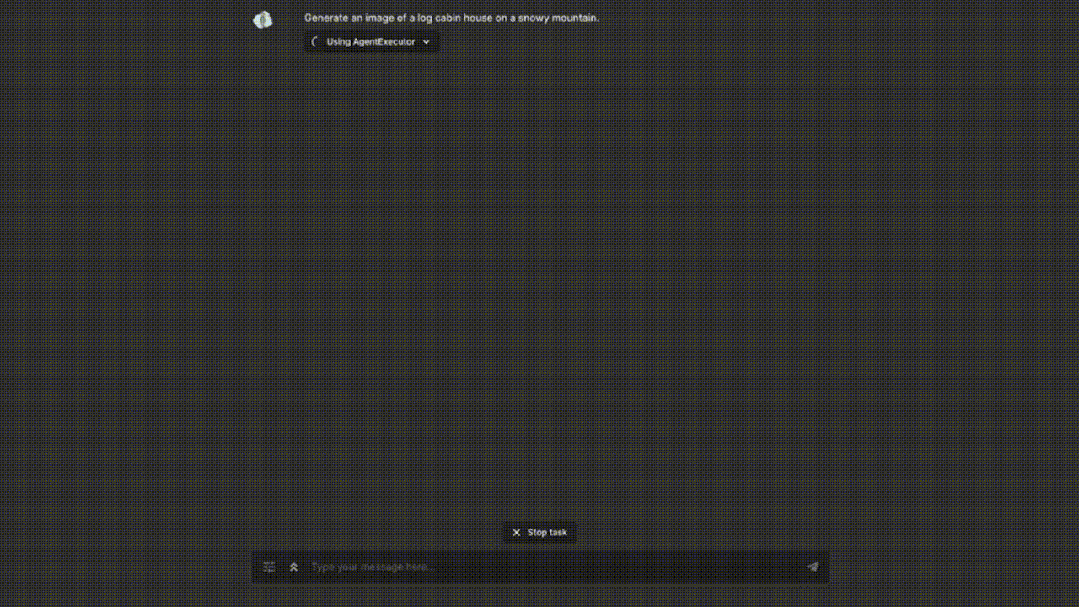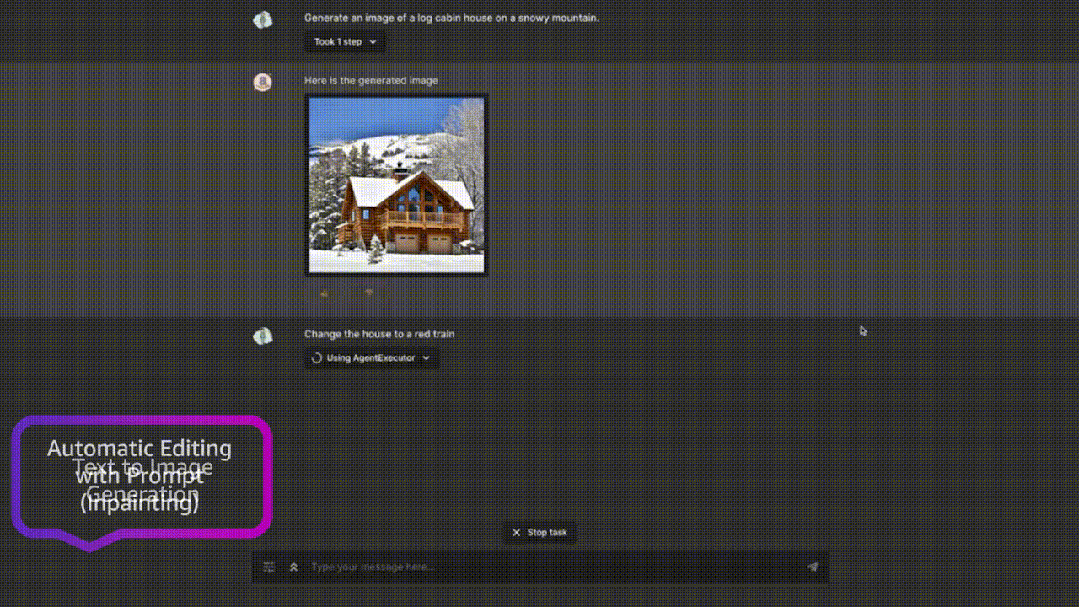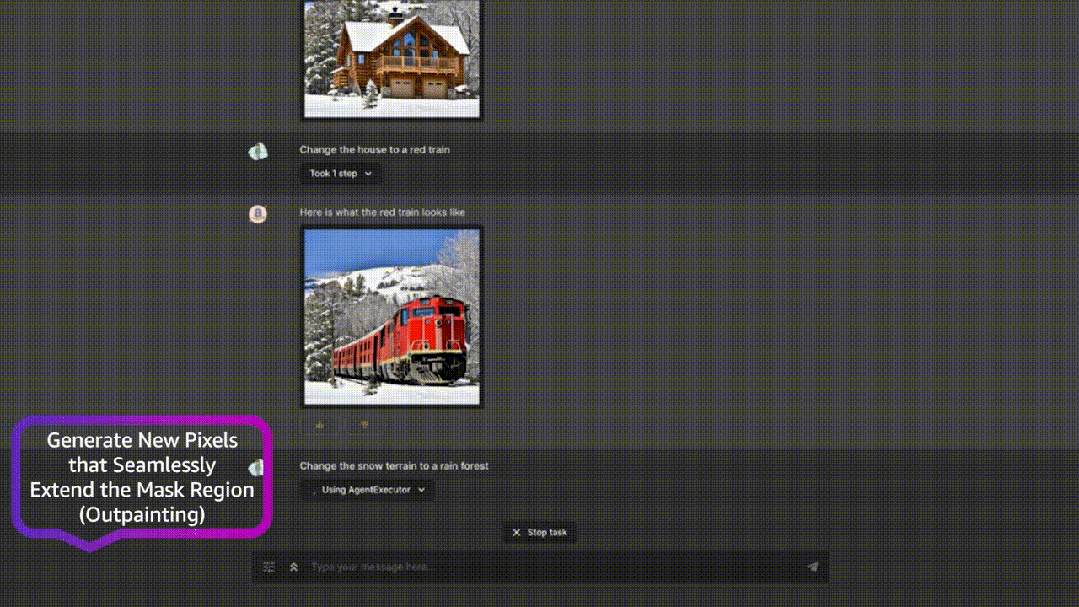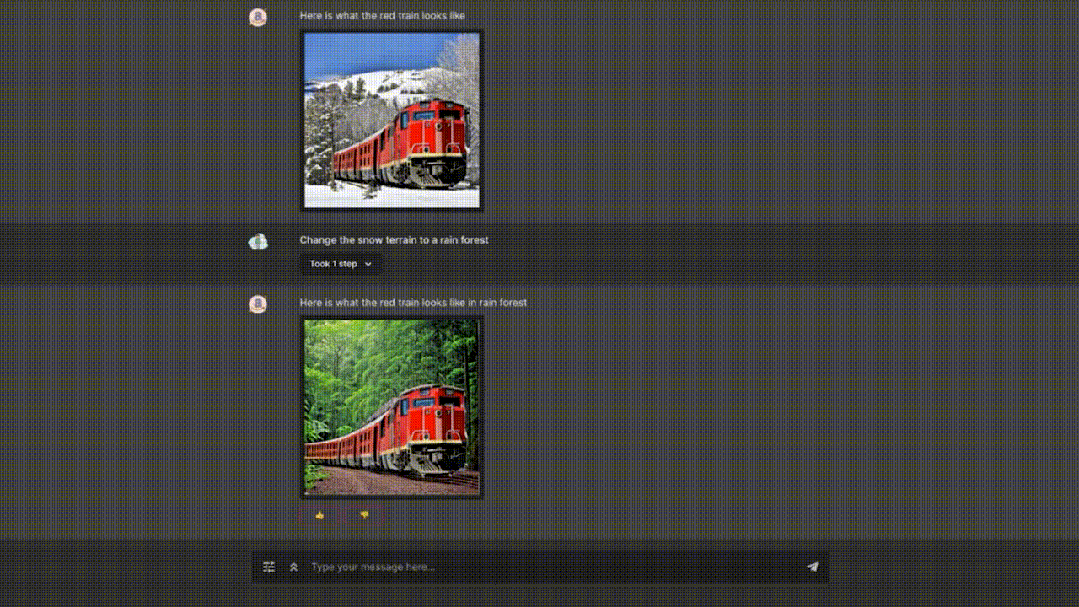
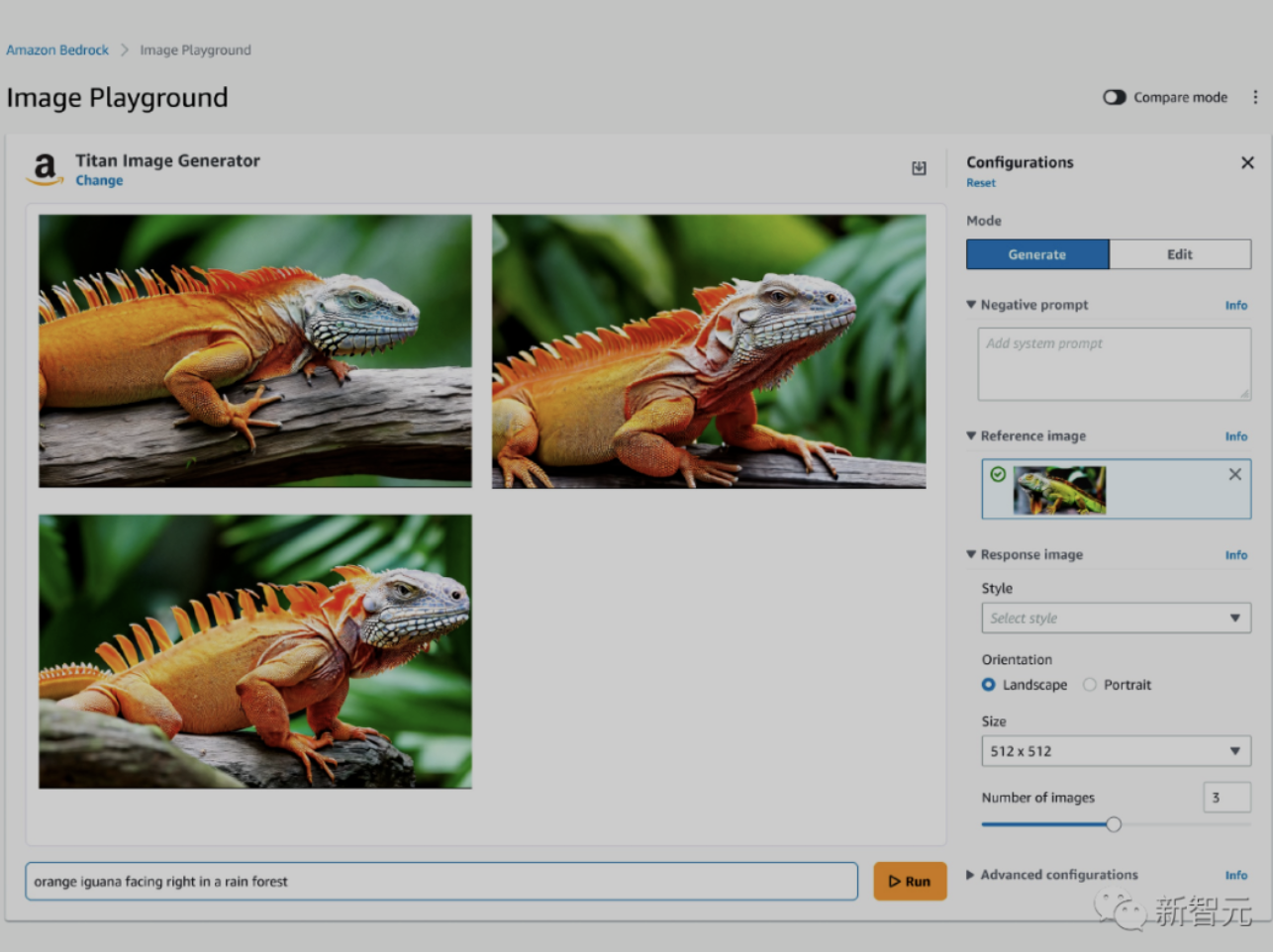
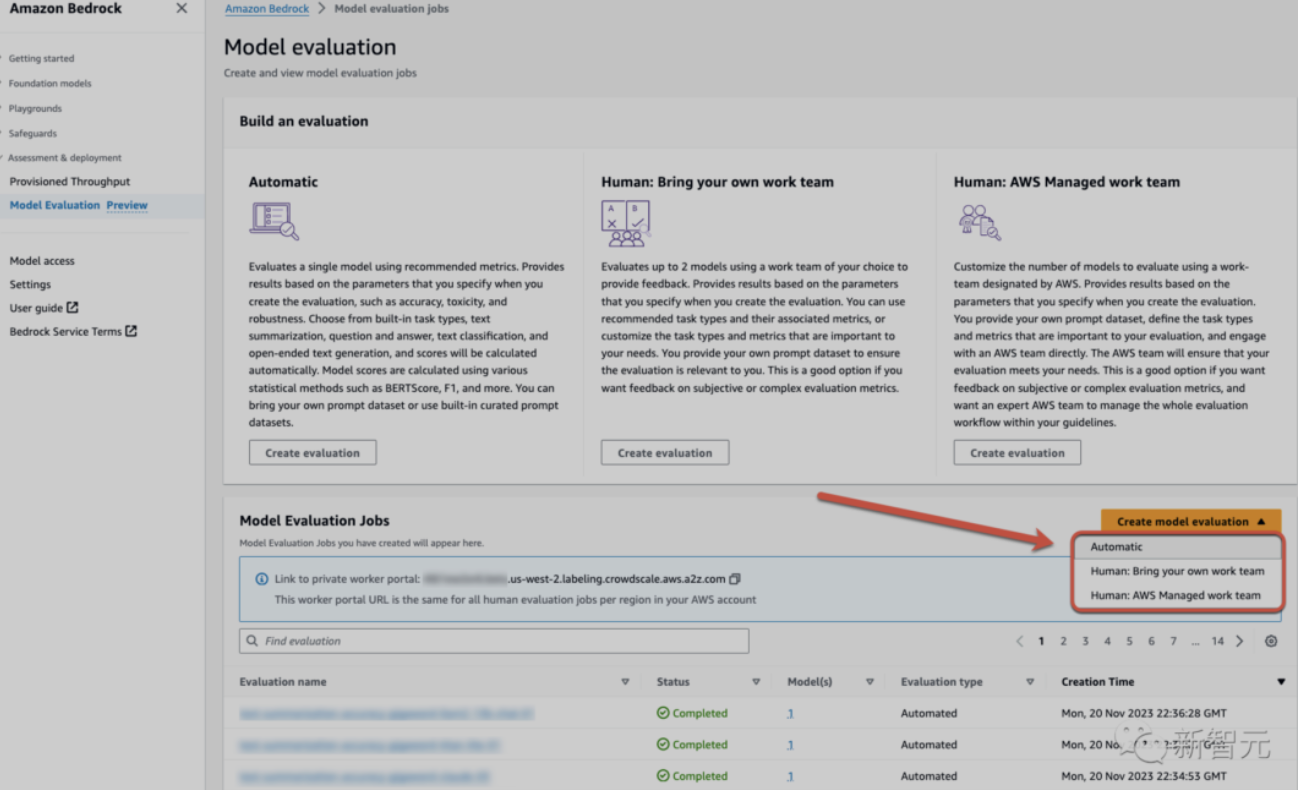
除了Amazon Titan Image Generator,大会上,亚马逊云科技还更新了两个文本生成的模型。一个是Amazon Titan Text Lite,用于文案写作等基本任务,结构紧凑非常适合微调。另一个是用于对话聊天的应用程序Amazon Titan Text Express,专为较大的任务而设计,并且同时兼顾了价格和性能。
Red Hat在2021年底将丢弃CentOS 8,用户们纷纷考虑面前的选择。
作者:Matt Asay 编译:沈建苗
在前不久的AWS re:Invent大会上,大型机现代化、数据库更新版和基于ARM的 Graviton3等新品赚足了眼球,诸位看官可能因此疏忽了一点:Amazon Linux 2022。AWS首席执行官Adam Selipsky在主题演讲中并没有提及它,但AWS计算服务副总裁Deepak Singh确实为此发了推文。但Amazon Linux 2022可能名至实归,因为它是那种了不起的产品,旨在提供稳定性、安全性和性能,又不显山露水。
这也是一个值得关注的版本。Amazon Linux 2022首次不基于Red Hat Enterprise Linux(RHEL)代码,而且从未基于CentOS。CentOS这个长期的RHEL克隆版在2020年底掀起了不小的动静,当时Red Hat宣布不使用定点(fixed-point)发布模式,改而使用“基于流”的滚动发布模式。相反,Amazon Linux 2022而是基于Fedora社区上游项目。
Red Hat出面稳定CentOS社区的办法是雇用主要的贡献者。就Red Hat而言,它希望为OpenStack和OpenShift等更高级的社区项目提供稳定的代码基础。Fedora无法提供这个基础,因为它的迭代步伐太快了。当然,Red Hat也想让吃白食的企业明白,不存在真正意义上的“免费软件”。为了避免被开发人员和小公司讨厌,Red Hat对RHEL开发者版本进行了重大更改,使其极易访问或使用(即免费!),同时让RHEL可供最多16台服务器免费使用,从而为学校及其他小组织提供了一种经济高效的方法,以运行经过测试、认证和支持的Linux。
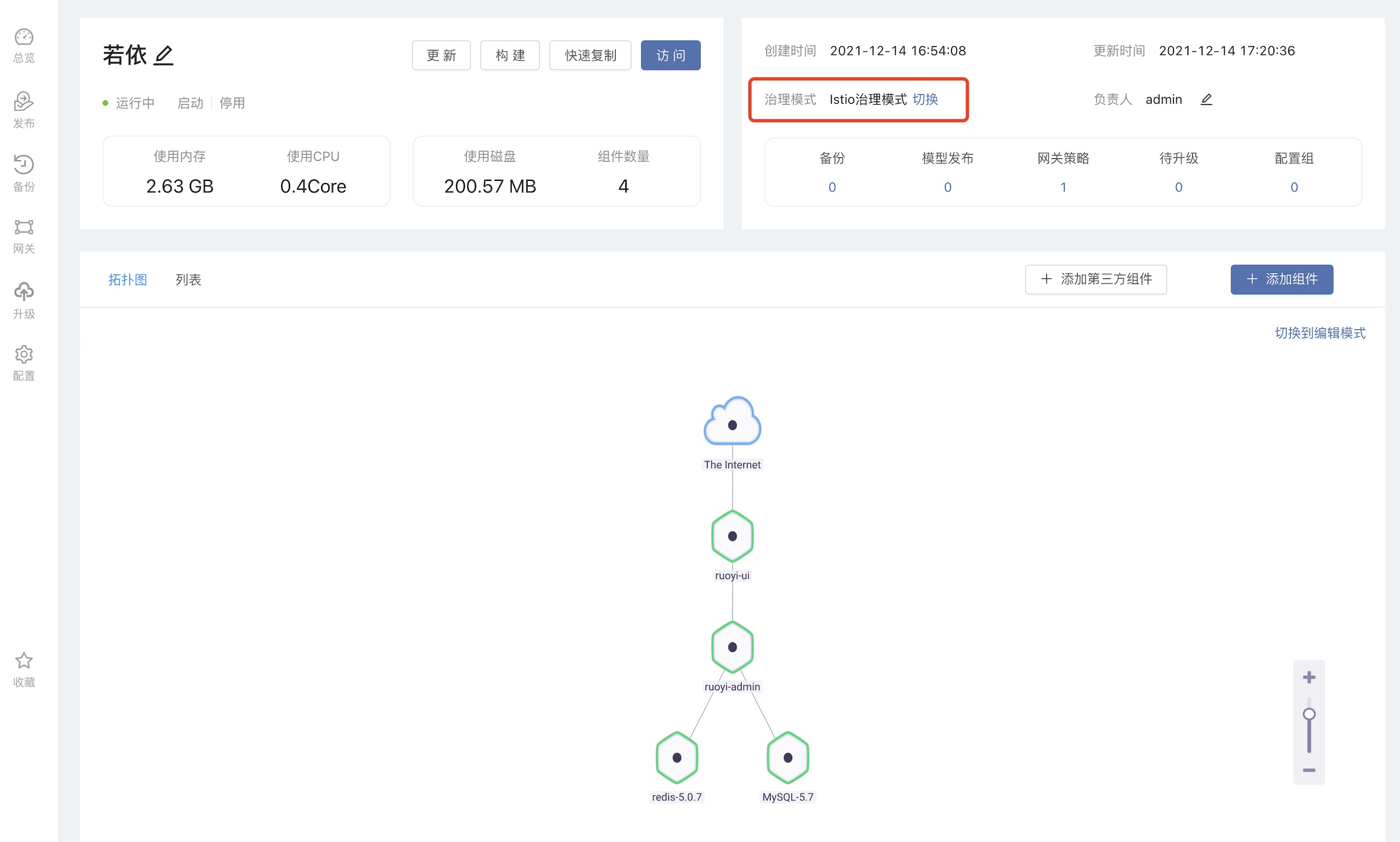
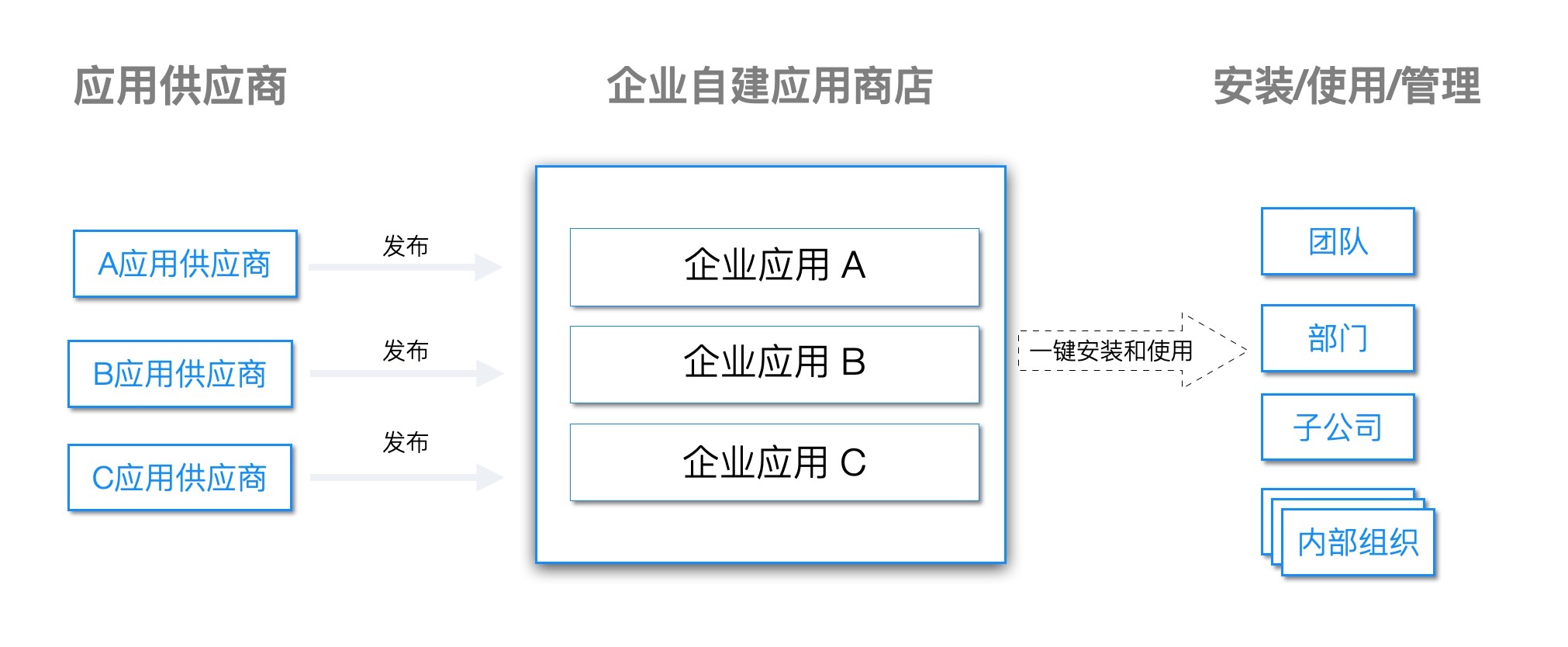
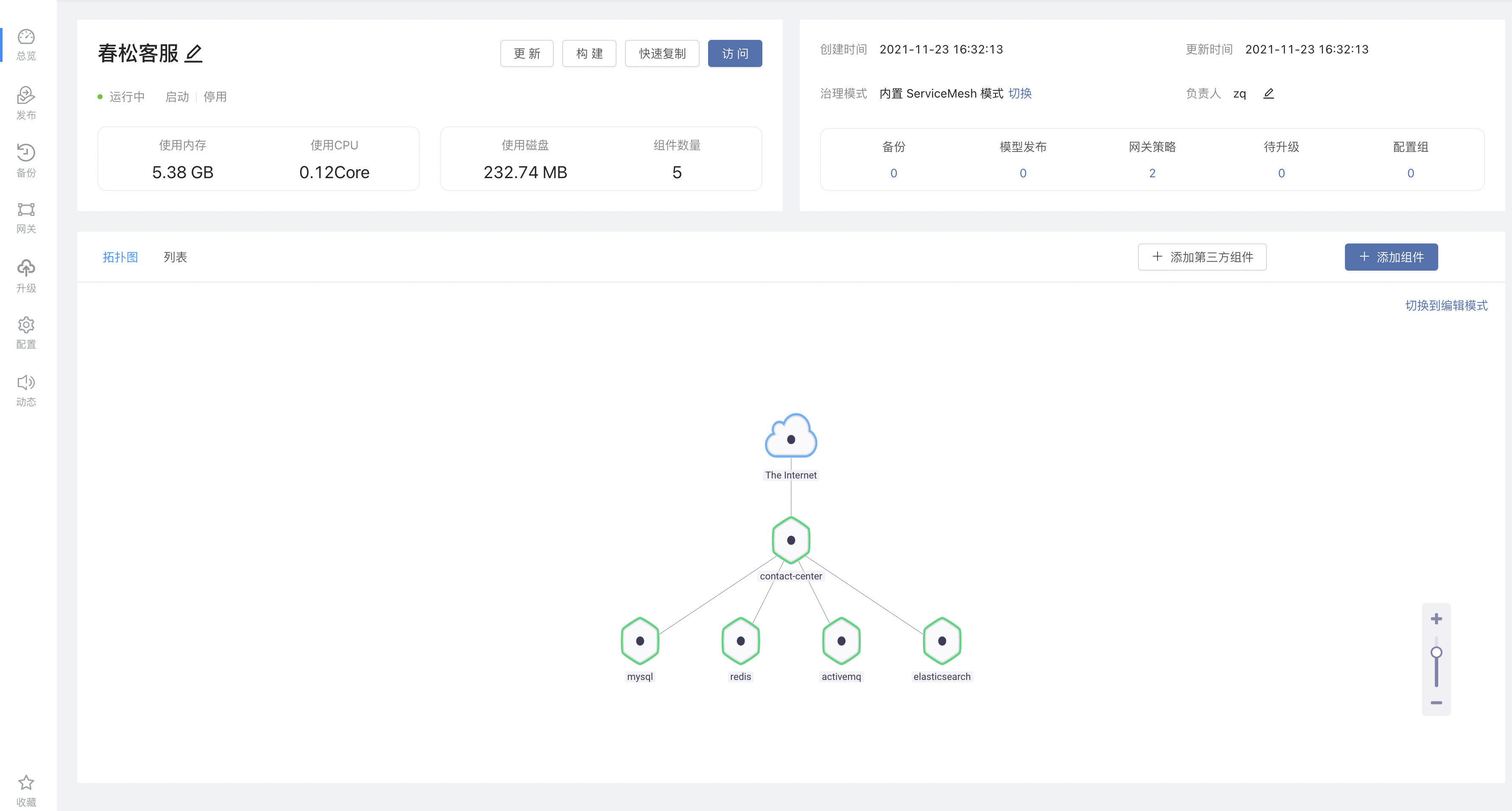
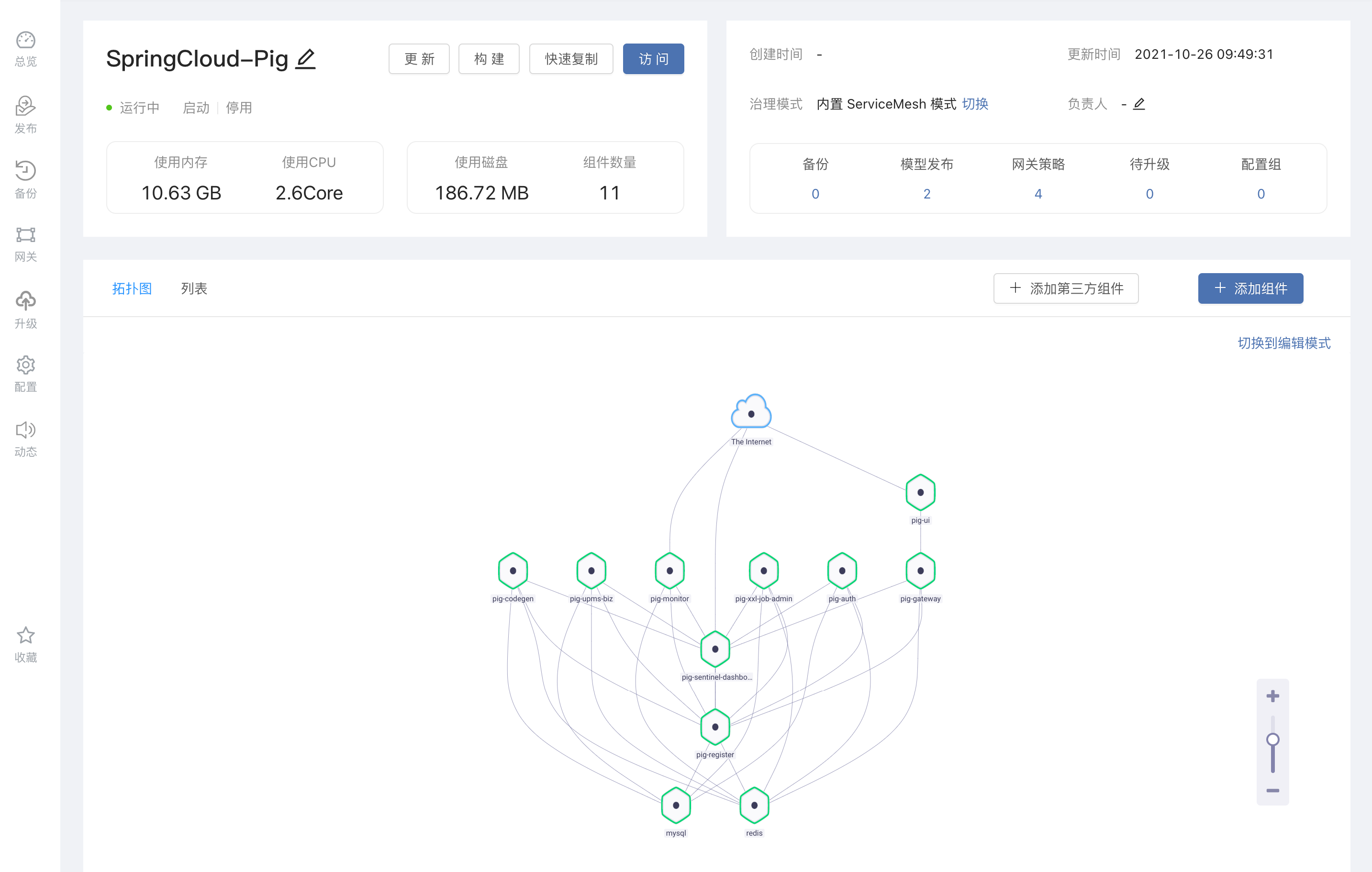
自动伸缩能力如果企业应用的最终用户是人,那么它的访问压力情况,都会有潮汐特征。好比一款供企业内部人员使用的OA系统,工作日的流量远比休息日高,工作时间的流量远比下班时间高。那么可否让这款 OA 系统根据流量的大小,自动调整实例的数量。令其忙时启动足够数量的实例抵御访问压力,闲时自动降低实例数量,将资源留给其他企业应用。Rainbond 平台可以赋予企业应用自动伸缩的能力。