
0x00 文章楔子
本文停止后续维护,请转至:
kubeadm HA master(v1.14.0)离线包 + 自动化脚本 + 常用插件 For Centos/Fedora
本文旨在通过最简易的方式指导读者搭建HA kubernetes 1.11集群
通过部署脚本驱动kubeadm工具进行自动化部署,自动启动keepalived负载均衡,calico网络插件,并且开启kube-proxy的IPVS模式。
本文中的自动化部署脚本可以在Lentil1016/kubeadm-ha找到,欢迎Star/Fork/提issue和PR。
在我的环境上进行示例自动化部署的录像可以在该链接查看
0x01 Kubernetes集群搭建
集群结构摘要
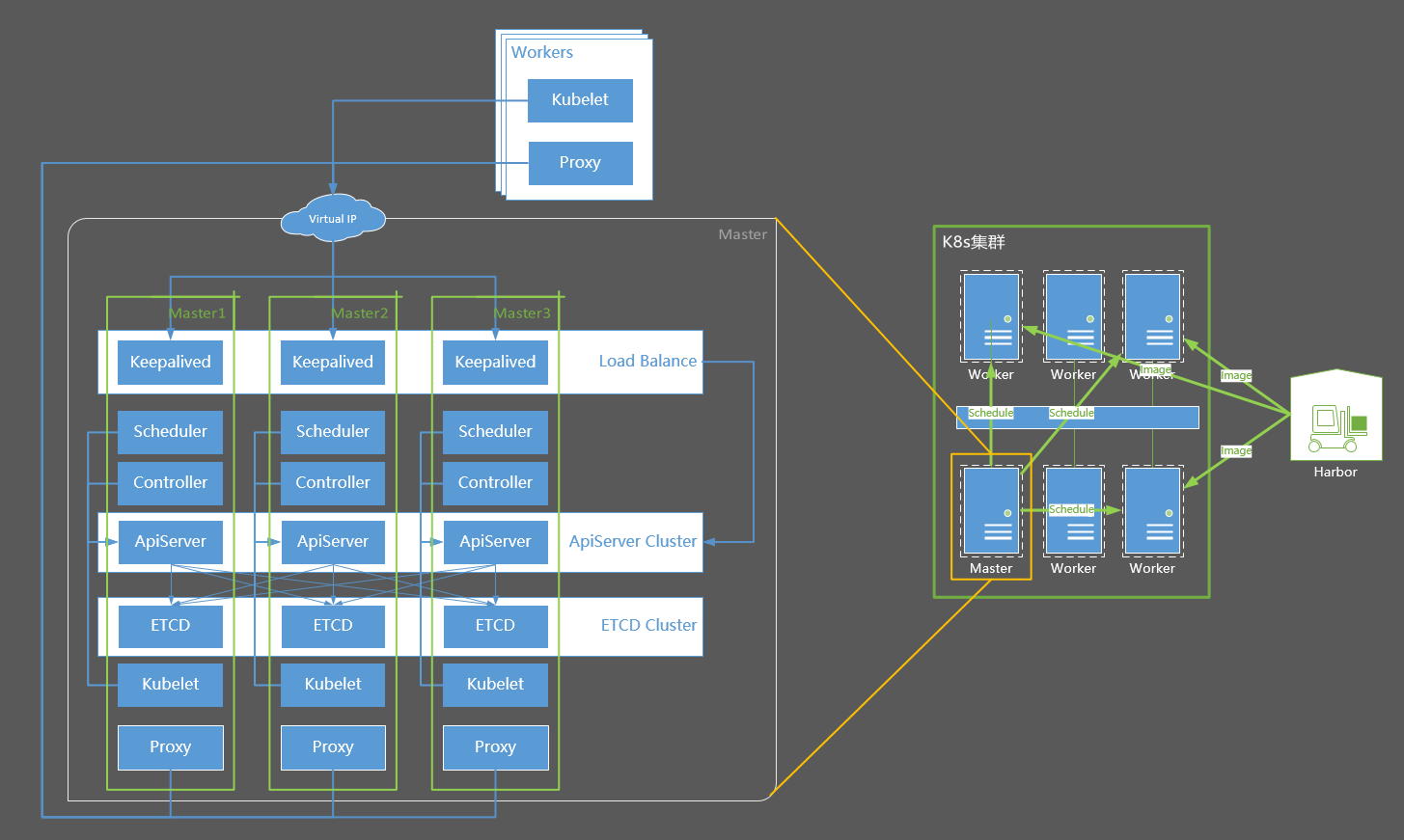
集群结构摘要
Master是集群的管理者,负责监控应用运行状态,维护应用运行,如发布工作任务、重启应用、部署升级应用等
Worker(节点),也被称为Minion,即从属主机,是Kubernetes集群中的一台工作机器。每一个节点都包含了Pod运行所需的必要服务,例如docker/kubelet/kube-proxy。
Kubernetes集群的基本部署步骤:
- 所有节点安装docker
- harbor节点安装harbor
- 所有master和minion节点安装kubelet kubeadm kubectl
- 初始化master节点,并启动Calico容器
- 将worker节点join到集群中
各个机器的主机信息以及IP分布如下:
- Distribute: CentOS 7
- Docker: 17.03.2-ce
- Kernel: 4.4.152-1.el7.elrepo.x86_64
- Kubernetes: 1.11.0
- NetPlugin: Calico
- Proxy-Mode: IPVS
- Master-Mode: HA Master
- DNS: CoreDNS
| Host Name | Role | IP |
|---|---|---|
| harbor | image registry | 10.130.38.80 |
| centos-7-x86-64-29-80 | master-1 | 10.130.29.80 |
| centos-7-x86-64-29-81 | master-2 | 10.130.29.81 |
| centos-7-x86-64-29-82 | master-3 | 10.130.29.82 |
| – | Virtual IP | 10.130.29.83 |
| node1 | worker | 10.130.38.105 |
| node2 | worker | 10.130.38.106 |
| node3 | worker | 10.130.38.107 |
进行系统配置
在所有机器上执行下面的脚本,配置注记:
- 关闭防火墙、selinux
- 关闭系统的Swap,Kubernetes 1.8开始要求。
- 关闭linux swap空间的swappiness
- 配置L2网桥在转发包时会被iptables的FORWARD规则所过滤,该配置被CNI插件需要,更多信息请参考Network Plugin Requirements
- 开启IPVS
# 所有主机:基本系统配置
# 关闭Selinux/firewalld
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
# 关闭交换分区
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak |grep -v swap > /etc/fstab
# 设置网桥包经IPTables,core文件生成路径
echo """
vm.swappiness = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
""" > /etc/sysctl.conf
sysctl -p
# 同步时间
yum install -y ntpdate
ntpdate -u ntp.api.bz
# 安装4.18版本内核
# 由于最新稳定版4.19内核将nf_conntrack_ipv4更名为nf_conntrack,目前的kube-proxy不支持在4.19版本内核下开启ipvs
# 详情可以查看:https://github.com/kubernetes/kubernetes/issues/70304
# 对于该问题的修复10月30日刚刚合并到代码主干,所以目前还没有包含此修复的kubernetes版本发出
# 读者可以选择安装我提供的4.18版本内核,或者不开启IPVS
# 4.18版本内核RPM下载链接:https://pan.baidu.com/s/1dCeozuMRQ96MBBjGpf0cjA 提取码:3nqg
cd /path/to/kernel-ml.tgz/
tar -xzvf kernel-ml.tgz
rpm -Uvh kernel-ml/*
# 检查默认内核版本为4.18,否则请调整默认启动参数
grub2-editenv list
#重启以更换内核
reboot
# 确认内核版本
uname -a
# 确认内核为4.18后,开启IPVS
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack_ipv4"
for kernel_module in \${ipvs_modules}; do
/sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
执行sysctl -p报错请参考centos7添加bridge-nf-call-ip6tables出现No such file or directory
Kubernetes要求集群中所有机器具有不同的Mac地址、产品uuid、Hostname。可以使用如下命令查看Mac和uuid
# 所有主机:检查UUID和Mac cat /sys/class/dmi/id/product_uuid ip link
安装配置Docker
Docker从1.13版本开始调整了默认的防火墙规则,禁用了iptables filter表中FOWARD链,这样会引起Kubernetes集群中跨Node的Pod无法通信,因此docker安装完成后,还需要手动修改iptables规则。
# 所有主机:安装配置docker # 安装docker yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo yum makecache fast yum install -y docker-ce # 编辑systemctl的Docker启动文件 sed -i "13i ExecStartPost=/usr/sbin/iptables -P FORWARD ACCEPT" /usr/lib/systemd/system/docker.service # 启动docker systemctl daemon-reload systemctl enable docker systemctl start docker
安装私有镜像库
如果不能翻墙,需要使用本文提供的私有镜像源,则还需要为docker做如下配置,将K8s官方镜像库的几个域名设置为insecure-registry,然后设置hosts使它们指向私有源。
# 所有主机:http私有源配置
# 为Docker配置一下私有源
mkdir -p /etc/docker
echo -e '{\n"insecure-registries":["k8s.gcr.io", "gcr.io", "quay.io"]\n}' > /etc/docker/daemon.json
systemctl restart docker
# 此处应当修改为harbor所在机器的IP
HARBOR_HOST="10.130.38.80"
# 设置Hosts
yes | cp /etc/hosts /etc/hosts_bak
cat /etc/hosts_bak|grep -vE '(gcr.io|harbor.io|quay.io)' > /etc/hosts
echo """
$HARBOR_HOST gcr.io harbor.io k8s.gcr.io quay.io """ >> /etc/hosts
下载链接:https://pan.baidu.com/s/17PV_VRYIbfmPz1qiiR_yGg 密码:newp,随后将该文件放置到harbor机器上,并在harbor主机上加载、启动该镜像
# harbor:启动私有镜像库 docker load -i /path/to/k8s-repo-1.11.0 docker run --restart=always -d -p 80:5000 --name repo harbor.io:1180/system/k8s-repo:v1.11.0
该镜像库中包含如下镜像,全部来源于官方镜像站。

镜像列表
安装配置kubernetes
基本安装
首先下载链接:https://pan.baidu.com/s/1tOIFgnexs25XWHxitLmmVQ 密码:lqth,并放置在k8s各个master和worker主机上
# master & worker:安装kubernetes yum install -y socat keepalived ipvsadm cd /path/to/downloaded/file tar -xzvf k8s-v1.11.0-rpms.tgz cd k8s-v1.11.0 rpm -ivh * systemctl enable kubelet kubeadm version -o short
配置免密码登陆
# master-1:生成ssh密钥对 ssh-keygen # 三次回车后,密钥生成完成 cat ~/.ssh/id_rsa.pub # 得到该机器的公钥如下图

将该公钥复制,并分别登陆到master-1 master-2 master-3的root用户,将它令起一行粘贴到 ~/.ssh/authorized_keys 文件中,包括master-1自己
复制完成后,从master-1上分别登陆master-1 master-2 master-3测试是否可以免密码登陆(请不要跳过这一步),可以的话便可以继续执行下一步
部署HA Master
HA Master的部署过程已经自动化,请在master-1上执行如下命令,并注意修改IP和Hostname
# 部署HA master cd ~/ # 创建集群信息文件 echo """ CP0_IP=10.130.29.80 CP0_HOSTNAME=centos-7-x86-64-29-80 CP1_IP=10.130.29.81 CP1_HOSTNAME=centos-7-x86-64-29-81 CP2_IP=10.130.29.82 CP2_HOSTNAME=centos-7-x86-64-29-82 VIP=10.130.29.83 NET_IF=eth0 CIDR=172.168.0.0/16 """ > ./cluster-info bash -c "$(curl -fsSL https://raw.githubusercontent.com/Lentil1016/kubeadm-ha/1.11.0/kubeha-gen.sh)" # 该步骤将可能持续2到10分钟,在该脚本进行安装部署前,将有一次对安装信息进行检查确认的机会
可以在该链接查看我在自己的环境上安装全过程的录像,安装结束后会打印出如下的信息,最后一行为加入集群的命令,其中加入集群的IP已经被更换为了高可用的VIP。
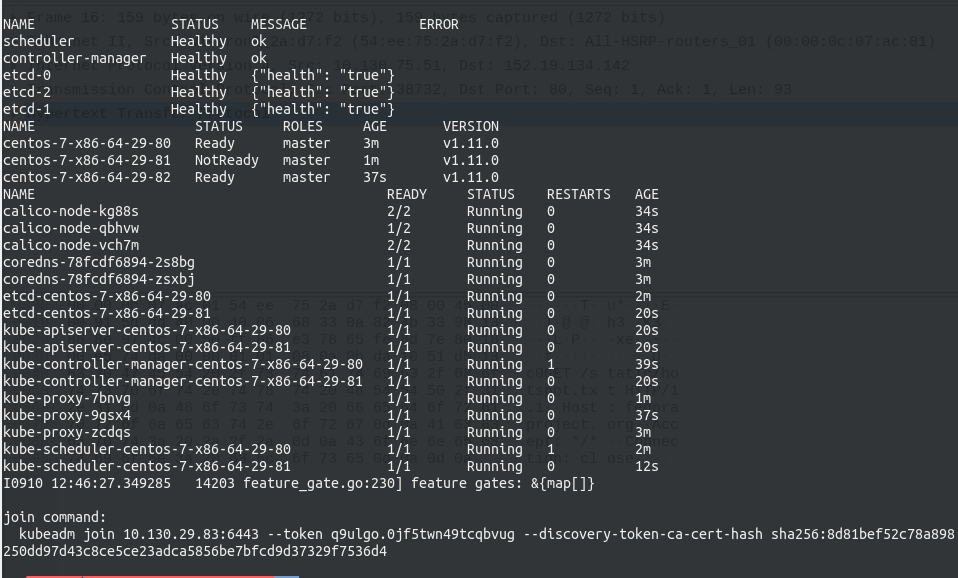
加入work node
现在可以将各节点入编到集群中。join command是由kubeadm动态生成的,其基本形式如下
# worker:将worker编入集群 kubeadm join --token fae76b.88ae6b2ad052b67f 10.130.29.83:6443 --discovery-token-ca-cert-hash sha256:9ed673962fd437dc556ccab07d02d718da01cf5db1b6eeaf443ecadd891a73e8
其中包含了节点入编集群所需要携带的验证token,以防止外部恶意的节点进入集群。每个token自生成起24小时后过期。届时如果需要加入新的节点,则需要重新生成新的join token,请使用下面的命令生成,注意改写IP:
# master-1:生成指向VIP的Join Command kubeadm token create --print-join-command|sed 's/${LOCAL_IP}/${VIP}/g'

随后到worker节点执行刚刚生成的join command即可将该节点编入集群。
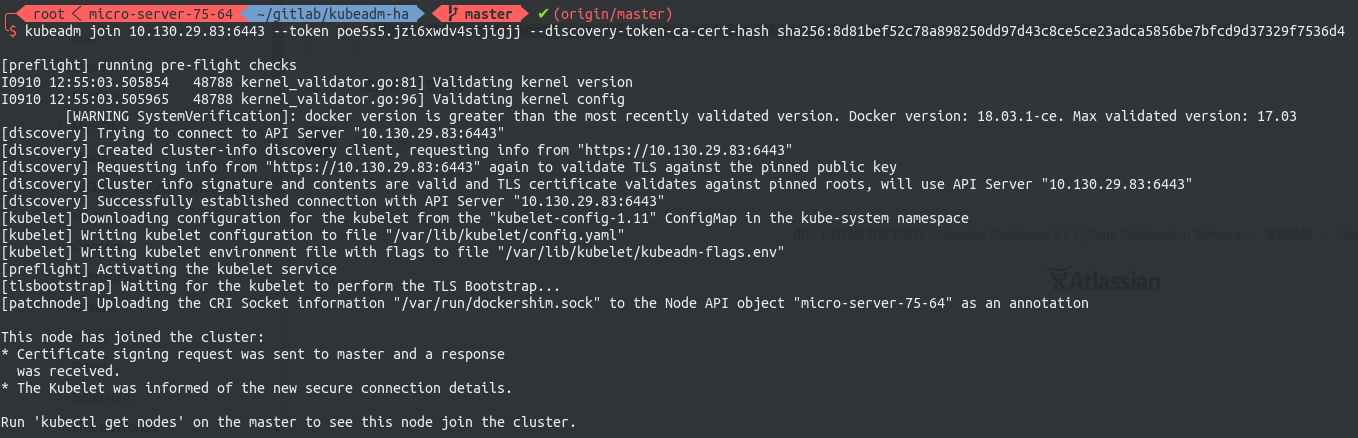
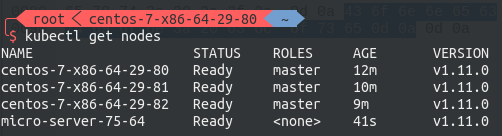
至此,HA master Kubernetes 集群搭建完毕

楼主能出个基于 ubuntu 18.04 的版本就造福大众了
你好,楼主没有Debian系的系统,所以没(lan)办(de)法(qu)维护k8s的deb私有源,如果你能想办法装好kubeadm/docker的话,本文中”安装私有镜像库”章节,以及从“配置免密码登陆”开始的后续章节理应可以在ubuntu上通用,感谢阅读。
楼主,能提供基于这个 k8s HA 方案的 Harbor 搭建方案吗?(如何搭建,拉取官方镜像)
harbor建议使用https://github.com/goharbor/harbor中提供的离线包安装,下载到一台有docker和docker-compose的主机之后解压直接运行install.sh就可以运行了,至于harbor的端口修改在百度上都搜得到。由于harbor只支持{hostname}/{project}/{image}:{tag},所以k8s.gcr.io/pause:3.1一类的镜像放不进去。我们内网里出于无奈只能用docker的registry:2镜像占80端口存放k8s组件的镜像,把harbor规划到了1180端口存其他的镜像,不太优雅,所以没有写。
楼主,您百度网盘中的 k8s 这个包如何从 docker registry:2 生成导出?
楼主网盘里的 包文件 ,如果组件升级了,如何更新并重新部署到本地 的 Harbor
这些内容够再开一篇博客了,所以我没法在这里说,可以给你说下大概的思路。docker hub上的registry:2是固定会把存储镜像的目录挂为docker volume的,那样修改是没办法commit的。所以我是用registry的二进制定制了一个镜像,然后直接把镜像存进去之后commit成仓库镜像,以后这个仓库镜像就是一个版本快照,跟着集群的yaml版本一起走,至于更新是每次大版本更新整体迭代一次,当然我是这个做法,但其实并不一定要这样做,看你的应用规模多大了。
学习中,去到 Harbor 这里停住了,不会搭建和拉取,有详细方案说明?
我看了脚本,第188行:
cp -f /etc/kubernetes/admin.conf ${HOME}/.kube/config
这个admin.conf 是从哪里来的 ?脚本里并没有生成啊
糊涂了。adm init 产生的。
是否有人测试过,把文中的1.11.0改成1.11.1 版本 ?api 起了一下,然后又死了,重启了Pod , 但是宿主机却没有了6443 端口。 etcd 也是起不来端口 。 容器没啥日志。。。
你好,如果你是连代理直接去取墙外的镜像是没问题的,如果用的是我的镜像,我只打包了1.11.0的包,不可以改。“安装私有镜像库”一节最后有列出我提供的镜像的列表
楼主, 一直不明白这段的后半段内容: 『docker run –restart=always -d -p 80:5000 –name repo harbor.io:1180/system/k8s-repo:v1.11.0』 尤其是 :『–name repo harbor.io:1180/system/k8s-repo:v1.11.0』 这里是何意义 /system/k8s-repo:v1.11.0 是什么? 我执行这句报错:
“docker run” requires at least 1 argument.
See ‘docker run –help’.
那个one argument的错误通常是因为少了最后面的镜像名造成的,比如执行
docker run --restart=always -d -p 80:5000 --name repo就会报那个错误。但是你粘贴的命令我原样执行,并没有报错误,你可以再检查一下。。。至于harbor.io:1180/system/k8s-repo:v1.11.0是我按自己仓库的分类起的镜像名字,对别人来说就只是个镜像名字而已,没什么别的意义。
初始化进程停在: ” ingress.extensions/dashboard created “, 过去一个多小时了,有什么初始化日志可以查看吗?
走到这一步集群已经建完了,脚本里在等待所有的容器进入Running状态,然后打印最后的日志。你可以
Ctrl + c结束脚本,然后kubectl get pods -n kube-system和kubectl get nodes看看是哪个容器有问题没启动起来感谢,是heapster-v1.5, 报错 imagepullbackoff.
好的,我检查了一下我的heapster.yaml,是我传错了编排文件的版本,刚刚更新了一下,现在再执行初始化应该不会有这个问题了。
是的,看pod日志发现了,我直接改了YAML重新apply就行了。谢谢。
你也可以执行
kubectl apply -f https://raw.githubusercontent.com/Lentil1016/kubeadm-ha/1.11.0/plugin/heapster.yaml覆盖掉我之前错误的yaml产生的安装谢谢
我也是走到这一步,等了一个多小时,出现情况如下:
# kubectl get pod –all-namespaces
The connection to the server localhost:8080 was refused – did you specify the right host or port?
# kubectl get node
The connection to the server localhost:8080 was refused – did you specify the right host or port?
该如何解决?
你不可能到了这一步,你的KubeConfig文件都还没有,可能集群都没建起来,更不可能到打出ingress.extensions/dashboard created日至的那一行。我都已经把正常的日志输出的演示给你了,你需要找第一处出现异常的地方,不然没人能帮你的。
dashboard监控页面如何登陆呢?
配置hosts dashboard.multi.io指向traefik所在机器,然后访问,脚本里是按使用traefik作为ingress controller透出集群中的https后端(如kubernetes dashboard)中的https方案配置的。
当然,dashboard官方提供的proxy链接访问的方法也是可以用的
试一试先 tks very much!
谢谢楼主,我按照安装文档,跑到 harbor的时候出问题了,docker load -i 提示这个:invalid diffID for layer 4: expected “sha256:3e67ca49ae8048983b2aacab1ac36342cd92a7ba2a2cd2c7f08c482d3dacef2a”, got “sha256:f3c05eb6ce11636abbf4d1a143d65b57354ac52fc33f68238e102a7fbd79516a” 能帮忙解答一下么?
提示的意思是镜像的第四层layer的sha256校验值和预期的不一样,恐怕是文件没有下载完整,或者是文件损坏了,建议重新下载
error while getting containers from Kubelet: failed to get all container stats from Kubelet URL
heapsper 无法获取kubelet信息
这个只是搭建k8s,没有包含服务发现和对外的负载均衡吗?
服务发现具体是指什么?如果是指DNS的话,coreDNS是默认安装的。负载均衡对外负载均衡L7是traefik,k8s master是L4负载均衡用的keepalived。另外这个是1.11.0版本的,我还写了一篇1.12.1版本的,建议使用新版本。
楼主,咨询个问题,执行脚本到下面位置卡住了,什么原因,如何解决?
Waiting for etcd bootup…
ca.crt 100% 1025 20.9KB/s 00:00
ca.key 100% 1679 20.0KB/s 00:00
sa.key 100% 1679 8.0KB/s 00:00
sa.pub 100% 451 157.5KB/s 00:00
front-proxy-ca.crt 100% 1025 505.1KB/s 00:00
front-proxy-ca.key 100% 1675 851.3KB/s 00:00
ca.crt 100% 1025 723.9KB/s 00:00
ca.key 100% 1679 19.9KB/s 00:00
admin.conf 100% 5450 781.6KB/s 00:00
admin.conf 100% 5450 2.6MB/s 00:00
Added member named k8s-master-2 with ID dc5f22231c65b178 to cluster
ETCD_NAME=”k8s-master-2″
ETCD_INITIAL_CLUSTER=”k8s-master-1=https://192.168.1.135:2380,k8s-master-136=https://192.168.1.136:2380″
ETCD_INITIAL_CLUSTER_STATE=”existing”
楼主,咨询个问题,执行脚本到下面位置卡住了,什么原因,如何解决?(上一个问题显示不全)
Added member named k8s-master-136 with ID dc5f22231c65b178 to cluster
ETCD_NAME=”k8s-master-136″
ETCD_INITIAL_CLUSTER=”k8s-master-135=https://192.168.30.135:2380,k8s-master-136=https://192.168.30.136:2380″
ETCD_INITIAL_CLUSTER_STATE=”existing”