
0x00 文章楔子
工作原因,本系列不再更新后续版本,抱歉
关于kubernetes v1.14.0:
- kubeadm开始建议使用systemd作为节点的cgroup控制器,因此建议读者参考本文流程配置docker为使用systemd,而非默认的Cgroupfs。
- kubelet额外的引入了对conntrack的依赖。
- Linux 5.0.x版内核已被支持。
关于其他plugins:
- 本次release集成的是calico3.5.3版本,使用host-local模式ipam。最新版的calico(3.6.0)中,calico-ipam功能已经成熟并在官方manifest中默认启用,然而3.6.0存在一些问题因而没能通过我的部署测试。
- 本次release集成的traefik是最新的稳定版本1.7.9,traefik:2.0已经发布,但尚处于alpha2测试阶段。
- 我在项目的feature-prom-rook分支添加了Rook和Prometheus的测试yaml,读者有兴趣的话可以试用一下。
理论上升级内核并不是必要的,为私有仓库单独准备一台机器也并不是必要的,但本指导为了简化步骤,将假设读者会按照本文步骤升级内核,并为私有仓库准备了一台单独的机器。如果读者跳过这些步骤后出现问题,本文不会提供解决这些问题所需要进行的额外配置。
本文中出现的全部下载连接见下表:
| 文件名 | 下载链接 | 提取码 | MD5 |
|---|---|---|---|
| helm-v2.13.1-linux-amd64.tar.gz | 百度盘 | crv5 | ffbe37fe328d99156d14a950bbd8107c |
| k8s-v1.14.0-rpms.tgz | 百度盘 | okdg | 7cccc6b10e17a6c640baced768aab274 |
| k8s-repo-v1.14.0 | 百度盘 | 88ua | 96af3a2da51460f8e51321e15094fdd2 |
| kernel-ml-5.0.4.tgz | 百度盘 | twl3 | 8e546a243f6fd5ca3ebe1d30079d2bac |
本文中的自动化部署脚本可以在Lentil1016/kubeadm-ha找到,欢迎Star/Fork/提issue和PR。
升级过程的录像可以在本链接查看
集群方案:
- 发行版:CentOS 7 & Fedora 29
- 容器运行时:Docker-18.09.3-ce
- 内核: 5.0.3-200.fc29.x86_64
- 版本:Kubernetes: 1.14.0
- 网络方案: Calico v3.5.3
- kube-proxy mode: IPVS
- master高可用方案:keepalived LVS
- DNS插件: CoreDNS 1.3.1
- metrics插件:metrics-server v0.3.1
- dashboard:kubernetes-dashboard v1.10.1
- ingress控制器:traefik 1.7.9
- helm & tiller:v2.13.1
0x01 Kubernetes集群搭建
集群结构摘要
此处为举列说明,假定各个机器的主机信息以及IP分布如下,需要额外说明的是,由于私有仓库需要占用80端口,与ingress controller冲突,因此为私有仓库单独准备一台机器是必要的:
| Host Name | Role | IP |
|---|---|---|
| registry | image registry | 10.130.38.80 |
| centos-7-x86-64-29-80 | master-1 | 10.130.29.80 |
| centos-7-x86-64-29-81 | master-2 | 10.130.29.81 |
| centos-7-x86-64-29-82 | master-3 | 10.130.29.82 |
| – | Virtual IP | 10.130.29.83 |
| node1 | worker | 10.130.38.105 |
| node2 | worker | 10.130.38.106 |
| node3 | worker | 10.130.38.107 |
进行系统配置
在所有机器上下载内核rpm包,并且执行下面的脚本,配置注记:
- 关闭防火墙、selinux
- 关闭系统的Swap,Kubernetes 1.8开始要求。
- 关闭linux swap空间的swappiness
- 配置L2网桥在转发包时会被iptables的FORWARD规则所过滤,该配置被CNI插件需要,更多信息请参考Network Plugin Requirements
- 升级内核到最新,原因见issue#19
- 开启IPVS
如果发现elrepo-kernel源中的内核版本过高或过低,无法满足要求,可以使用下面测试过的5.0.4版本rpm包:
| kernel-ml-5.0.4.tgz | 百度盘 | twl3 | 8e546a243f6fd5ca3ebe1d30079d2bac |
# 所有主机:基本系统配置
# 关闭Selinux/firewalld
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
# 关闭交换分区
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak |grep -v swap > /etc/fstab
# 设置网桥包经IPTables,core文件生成路径
echo """
vm.swappiness = 0
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.conf.all.rp_filter = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
""" > /etc/sysctl.conf
sysctl -p
# 同步时间
yum install -y ntpdate
ntpdate -u ntp.api.bz
# 升级内核
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm ;yum --enablerepo=elrepo-kernel install kernel-ml-devel kernel-ml -y
# 检查默认内核版本是否大于4.14,否则请调整默认启动参数
grub2-editenv list
#重启以更换内核
reboot
# 确认内核版本后,开启IPVS
uname -a
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in \${ipvs_modules}; do
/sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
执行sysctl -p报错请参考centos7添加bridge-nf-call-ip6tables出现No such file or directory
Kubernetes要求集群中所有机器具有不同的Mac地址、产品uuid、Hostname。可以使用如下命令查看Mac和uuid
# 所有主机:检查UUID和Mac cat /sys/class/dmi/id/product_uuid ip link
安装配置Docker
Docker从1.13版本开始调整了默认的防火墙规则,禁用了iptables filter表中FOWARD链,这样会引起Kubernetes集群中跨Node的Pod无法通信,因此docker安装完成后,还需要手动修改iptables规则。
# 所有主机:安装配置docker
# 安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
yum makecache fast
yum install -y docker-ce
# 编辑systemctl的Docker启动文件和配置文件
sed -i "13i ExecStartPost=/usr/sbin/iptables -P FORWARD ACCEPT" /usr/lib/systemd/system/docker.service
mkdir -p /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
# 启动docker
systemctl daemon-reload
systemctl enable docker
systemctl start docker
安装私有镜像库
如果不能翻墙,需要使用本文提供的私有镜像源,则还需要为docker做如下配置,将K8s官方镜像库的几个域名设置为insecure-registry,然后设置hosts使它们指向私有源。
# 所有主机:http私有源配置
# 额外为Docker配置私有源
cat > /etc/docker/daemon.json <<EOF
{
"insecure-registries":["harbor.io", "k8s.gcr.io", "gcr.io", "quay.io"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
systemctl restart docker
# 此处应当修改为registry所在机器的IP
REGISTRY_HOST="10.130.38.80"
# 设置Hosts
yes | cp /etc/hosts /etc/hosts_bak
cat /etc/hosts_bak|grep -vE '(gcr.io|harbor.io|quay.io)' > /etc/hosts
echo """
$REGISTRY_HOST gcr.io harbor.io k8s.gcr.io quay.io """ >> /etc/hosts
下载地址:
| k8s-repo-v1.14.0 | 百度盘 | 88ua | 96af3a2da51460f8e51321e15094fdd2 |
随后将该文件放置到registry机器上,并在registry主机上加载、启动该镜像
# registry:启动私有镜像库 docker load -i /path/to/k8s-repo-1.14.0 docker run --restart=always -d -p 80:5000 --name repo harbor.io:1180/system/k8s-repo:v1.14.0
该镜像库中包含如下镜像,全部来源于官方镜像站。
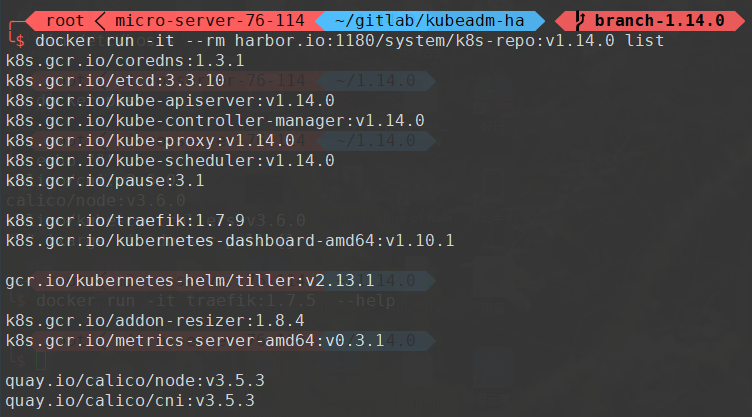
镜像列表
安装配置kubernetes
基本安装
下载文件:
| k8s-v1.14.0-rpms.tgz | 百度盘 | okdg | 7cccc6b10e17a6c640baced768aab274 |
并放置在k8s各个master和worker主机上
# master & worker:安装kubernetes yum install -y socat keepalived ipvsadm conntrack cd /path/to/downloaded/file tar -xzvf k8s-v1.14.0-rpms.tgz cd k8s-v1.14.0 rpm -Uvh * --force systemctl enable kubelet kubeadm version -o short
配置免密码登陆
# master-1:生成ssh密钥对 ssh-keygen # 三次回车后,密钥生成完成 cat ~/.ssh/id_rsa.pub # 得到该机器的公钥如下图

将该公钥复制,并分别登陆到master-1 master-2 master-3的root用户,将它令起一行粘贴到 ~/.ssh/authorized_keys 文件中,包括master-1自己
复制完成后,从master-1上分别登陆master-1 master-2 master-3测试是否可以免密码登陆(请不要跳过这一步),可以的话便可以继续执行下一步
部署HA Master
HA Master的部署过程已经自动化,请在master-1上执行如下命令,并注意修改IP
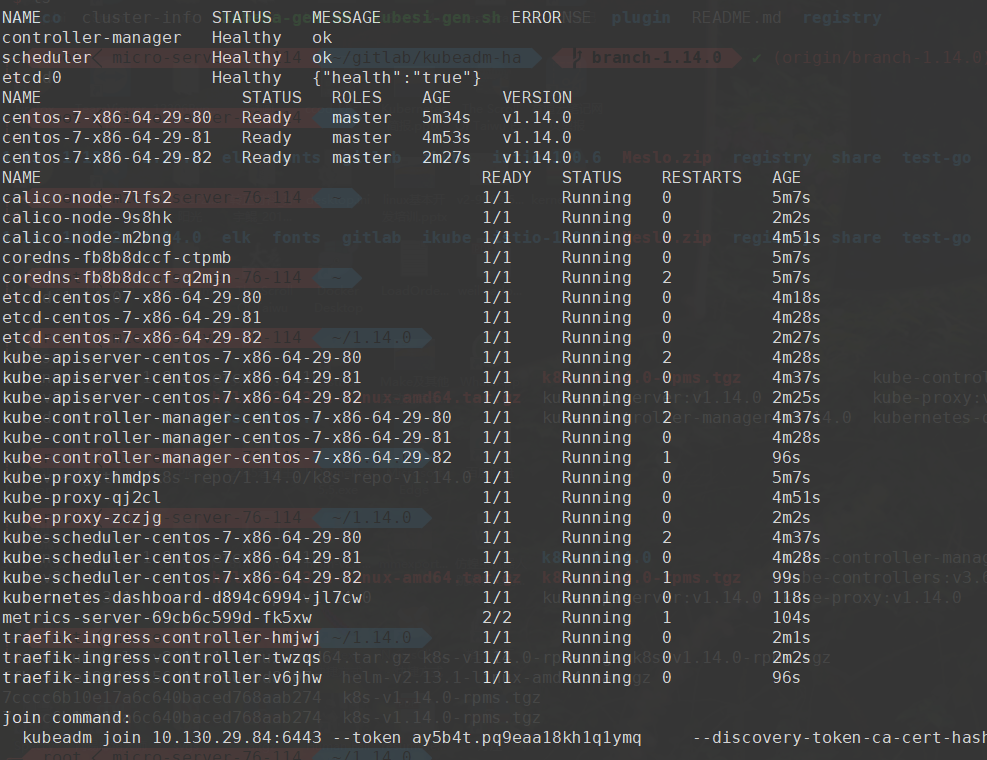
# 部署HA master cd ~/ # 创建集群信息文件 echo """ CP0_IP=10.130.29.80 CP1_IP=10.130.29.81 CP2_IP=10.130.29.82 VIP=10.130.29.83 NET_IF=eth0 CIDR=10.244.0.0/16 """ > ./cluster-info bash -c "$(curl -fsSL https://raw.githubusercontent.com/Lentil1016/kubeadm-ha/1.14.0/kubeha-gen.sh)" # 该步骤将可能持续2到10分钟,在该脚本进行安装部署前,将有一次对安装信息进行检查确认的机会
可以在本链接查看我在自己的环境上安装全过程的录像,安装结束后会打印出如下的信息,最后一行为加入集群的命令。
访问dashboard
如果需要访问kubernetes dashboard或traefik dashboard,只需要在浏览器所在机器上配置到任意master的hosts解析,然后访问对应域名即可。
echo """ 10.130.29.80 dashboard.multi.io ingress.multi.io""" >> /etc/hosts
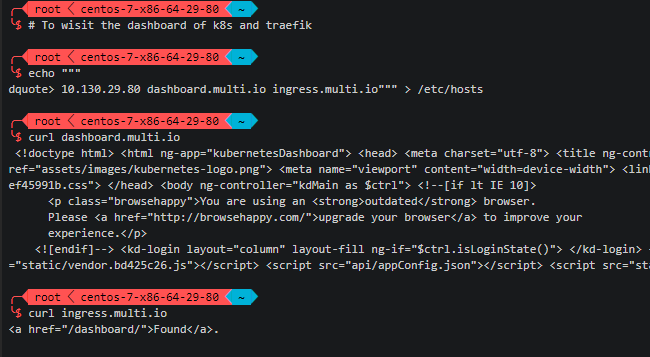
测试发现有时kubernetes dashboard容器会不响应请求,如果出现该情况请尝试删除dashboard的pod以重新启动该pod,即可解决该问题。
安装helm
如果需要安装helm,请先下载离线包:
| helm-v2.13.1-linux-amd64.tar.gz | 百度盘 | crv5 | ffbe37fe328d99156d14a950bbd8107c |
cd /path/to/helm-v2.13.1-linux-amd64.tar.gz/ tar -xzvf helm-v2.13.1-linux-amd64.tar.gz cd linux-amd64 cp helm /usr/local/bin helm init --service-account=kubernetes-dashboard-admin --skip-refresh --upgrade helm version
加入work node
现在可以将各节点入编到集群中。join command是由kubeadm动态生成的,其基本形式如下
# worker:将worker编入集群
kubeadm join 10.130.29.83:6443 --token 4n3hvt.sb8qjmno6l47tsww --discovery-token-ca-cert-hash sha256:a7f1de577bd8677a5d7fe4d765993645ae25d8b52a63a1133b74a595a7bb2e0f
其中包含了节点入编集群所需要携带的验证token,以防止外部恶意的节点进入集群。每个token自生成起24小时后过期。届时如果需要加入新的节点,则需要重新生成新的join token,请使用下面的命令生成,注意改写IP:
# master-1:生成指向VIP的Join Command kubeadm token create --print-join-command

随后到worker节点执行刚刚生成的join command即可将该节点编入集群。
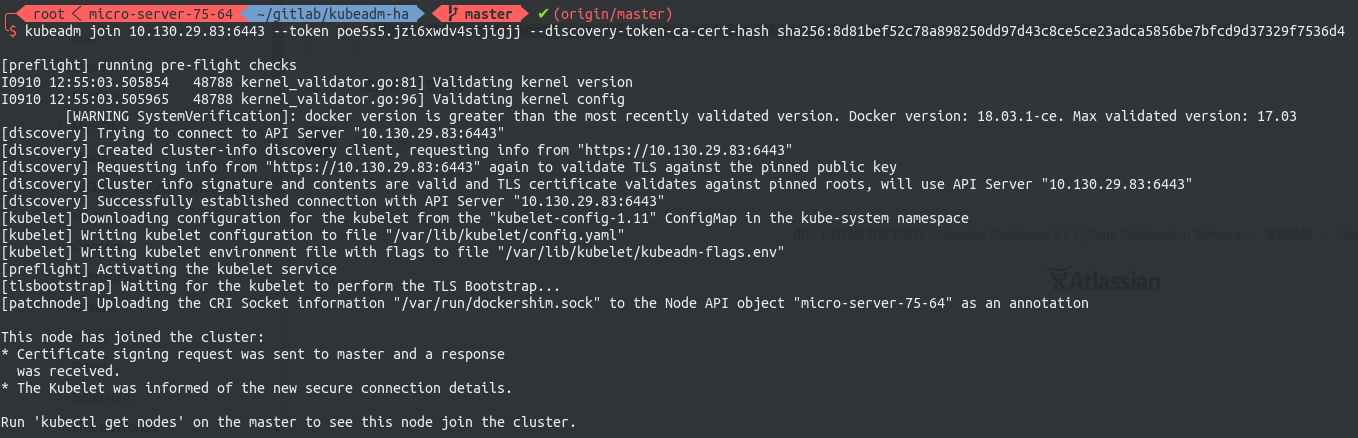
至此,HA master Kubernetes 集群搭建完毕

dashboard 用了80端口 是不是跟repo冲突了? 关了repo才能访问?
文章中已经多次强调要为repo单独准备一台机器。如果不想为repo单独准备机器,请自行使用ingress或其他转发方法将repo从其他端口映射到80
是我看错了 因为两个ip结尾都是80 所以用了同一台 抱歉
dashboard页面能打开,输入token死活没响应;
2019/04/04 07:44:58 MSG_LOGIN_UNAUTHORIZED_ERROR
2019/04/04 07:45:26 Metric client health check failed: the server could not find the requested resource (get services heapster). Retrying in 30 seconds.
2019/04/04 07:45:56 Metric client health check failed: the server could not find the requested resource (get services heapster). Retrying in 30 seconds.
请教楼主 有什么解决办法没
补充,试过几次删除 dashboard pod ,也是登录不上
我也碰到了,如何解决的呢?
同问,进不去
参考 https://stackoverflow.com/questions/53521962/kubernetes-dashboard-showing-unauthorized
使用 ssl -L 代理到本地后这个问题就解决了
CP0_IP=10.130.29.80
CP1_IP=10.130.29.81
CP2_IP=10.130.29.82
VIP=10.130.29.83
NET_IF=eth0
CIDR=10.244.0.0/16
这个IP要设置成路由器局域网IP怎么设置?
[root@w1 k8s-v1.14.0]# systemctl enable kubelet
Failed to execute operation: File exists
这个地方就报错了,不知道你是怎么成功的
报这个错误说明你这台机器已经enable过kubelet了。。。连百度都不查一下的
see this https://sealyun.com/post/sealos2.0/
为什么worker节点也装keepalived
可以不装
大神,能否在你的这个基础上 单独写一章calico各种模式的安装呢,网络部分感觉还有点难,多谢多谢了额
大神,我一直想不明白一个问题,我在你的1.12 1.13 .14的版本中发现calico calico-kube-controllers部分,你的calico.yaml中一直删除掉的,我这边如果直接用官网的 带calico-kube-controller 发现总有一个node有问题
kubectl get po –all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-etcd-5l764 1/1 Running 0 4d7h 192.168.200.29 master
kube-system calico-kube-controllers-5bc85548d5-ttgpv 1/1 Running 0 39m 192.168.200.27 node2
kube-system calico-node-4lj56 1/1 Running 0 39m 192.168.200.29 master
kube-system calico-node-9927l 1/1 Running 2 39m 192.168.200.28 node3
kube-system calico-node-9rb4f 1/1 Running 0 39m 192.168.200.27 node2
kube-system calico-node-dlhxz 0/1 Running 0 39m 192.168.200.26 node1
kube-system calicoctl 1/1 Running 0 4d3h 192.168.200.29 master
不知道你那边遇到过没
calico-kube-controllers是从3.6.0开始加入到calico的示例manifest中的,请检查是否使用了3.6.x版本的calico,3.6.x版本calico与3.5.x差别较大,可以尝试使用3.5.x版本看问题是否依然存在。
请教下:在执行
# registry:启动私有镜像库
docker load -i /path/to/k8s-repo-1.14.0
时报文件找不到,但是我检查了路径和文件都没问题权限也用的是root
下载的文件是这样的:k8s-repo-v1.14.0.baiduyun.p.downloading 、k8s-repo-v1.14.0 是不是文件有问题?有其他下载地址吗?
我也是一对文件找不到,正在排错中…
百度网上上传上去的私有镜像库文件没传完有问题,换了手机和网页版下载下来都不能用,有其他下载地址么?
我手动下载并且查验了一下,不存在你所描述的情况,请检查自身网络是否正常,并参考文件MD5校验值“96af3a2da51460f8e51321e15094fdd2”检查下载到的文件是否完整。
啊?下载下来是不是一个美欧后缀名的文件?k8s-repo-v1.14.0.baiduyun.p.downloading 、k8s-repo-v1.14.0 您用的百度网盘的版本号是多少?那就应该是百度网盘的问题,网上也有很多人下载下来是downloading这个文件
执行完脚本没有创建rc和pods,执行脚本过程中没报错
Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get config map: Get https://192.168.0.70:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config: dial tcp 192.168.0.70:6443:
安装过程中报这个,70机器是vip我就没装kube,但是不知道他为什么会从70访问kube
请教下楼主,我在添加work节点时卡在了check哪里,生成命令后 命令里面的节点IP是VIP,没理解添加work加入到vip为什么?谢谢
Waiting for all pods into ‘Running’ status. You can press ‘Ctrl + c’ to terminate this waiting any time you like.
一路顺风卡到这里一动不动一个小时了 kubectl get pods 查看no such file
那就不是一路顺风了,那是半路就出问题了
楼主你好,我实行完自动脚本后没有出现集群信息,一直停留在:Waiting for all pods into ‘Running’ status. You can press ‘Ctrl + c’ to terminate this waiting any time you like.
docker中的容器列表如下:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0c2319afaa7f 2c4adeb21b4f “etcd –advertise-cl…” 8 seconds ago Up 6 seconds k8s_etcd_etcd-iservice-master1_kube-system_23179374420bcee7bb403c052c430266_0
e24cb2487872 ecf910f40d6e “kube-apiserver –ad…” 8 seconds ago Up 6 seconds k8s_kube-apiserver_kube-apiserver-iservice-master1_kube-system_bf88ad7021deaf938b25c21a62aae8f9_0
54384ec791c0 5cd54e388aba “/usr/local/bin/kube…” 8 seconds ago Up 6 seconds k8s_kube-proxy_kube-proxy-lvrgb_kube-system_70cf20e0-65af-11e9-9945-000c29c4a2b5_0
5612a83d64ab 00638a24688b “kube-scheduler –bi…” 8 seconds ago Up 7 seconds k8s_kube-scheduler_kube-scheduler-iservice-master1_kube-system_58272442e226c838b193bbba4c44091e_0
24fd8e094b51 b95b1efa0436 “kube-controller-man…” 8 seconds ago Up 7 seconds k8s_kube-controller-manager_kube-controller-manager-iservice-master1_kube-system_0ff88c9b6e64cded3762e51ff18bce90_0
29ae077720ec k8s.gcr.io/pause:3.1 “/pause” 9 seconds ago Up 7 seconds k8s_POD_etcd-iservice-master1_kube-system_23179374420bcee7bb403c052c430266_0
e6340a06f5d2 k8s.gcr.io/pause:3.1 “/pause” 9 seconds ago Up 8 seconds k8s_POD_kube-scheduler-iservice-master1_kube-system_58272442e226c838b193bbba4c44091e_0
77246611fadd k8s.gcr.io/pause:3.1 “/pause” 9 seconds ago Up 7 seconds k8s_POD_kube-apiserver-iservice-master1_kube-system_bf88ad7021deaf938b25c21a62aae8f9_0
3d03395e6bc6 k8s.gcr.io/pause:3.1 “/pause” 9 seconds ago Up 7 seconds k8s_POD_kube-proxy-lvrgb_kube-system_70cf20e0-65af-11e9-9945-000c29c4a2b5_0
5db2599c89b7 k8s.gcr.io/pause:3.1 “/pause” 9 seconds ago Up 8 seconds k8s_POD_kube-controller-manager-iservice-master1_kube-system_0ff88c9b6e64cded3762e51ff18bce90_0
以上容器也无法删除,dashboard 也无法访问,麻烦帮忙分析下问题大概在哪里?谢谢
楼主你好,我按照安装步骤安装完毕后一切正常,但服务器重启之后,kubernetes自动启动失败(在之前已经设置了自动启动)使用kubectl get nodes 提示:The connection to the server 192.168.0.70:6443 was refused – did you specify the right host or port?
kubectl get cs 是不是应该显示三个etcd? etcd0 etcd1 etcd2
在apiserver里配置成三个,就会显示三个,kubeadm默认只配本地的一个
集群如何重启?重启服务器后集群启动不起来,dashboard无法访问
执行reboot命令重启。。。集群起不起来是不对的,你得查查
大佬,请教你的命令提示符怎么配置的
见楼下
大佬,你文档中用的终端工具叫什么,看着挺清晰的
oh-my-zsh + lent-dotfile
证书问题,一年以后过期,没看到解决
kubeadm alpha certs renew all+ 证书轮换具体方法呢?作者的部署方案里面能把证书时间改长吗?
参考https://www.kubernetes.org.cn/5777.html
楼主你好,看了你的帖子安装之后node节点在master上显示NotReady,查看报错为【6月 01 23:38:52 k8s-master kubelet[19475]: W0601 23:38:52.006800 19475 raw.go:87] Error while processing event (“/sys/fs/cgroup/devices/libcontainer_31517_systemd_test_default.slice”: 0x40000100 == IN_CREATE|IN_ISDIR): inotify_add_watch /sys/fs/cgroup/devices/libcontainer_31517_systemd_test_default.slice: no such file or directory】
请赐教。
not ready可能和这个报错没关系,先检查一下集群网络,看看calico有没有正常运行
有一个问题,主节点init起来之后通过kubeadm join添加从节点,但是Get https://172.16.233.250:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config: dial tcp 172.16.233.250:6443: connect: connection refused ,从节点好像没法获取到配置,因为无法telnet通vip。
我试了一下nginx+keepalived服务,master+backup节点,如果从节点80端口挂了,你在从节点上telnet vip 80
是没法请求通的。和上面一种情况,因为从节点还没有启动apiserver服务,但是有无法请求虚拟ip的apiserver服务。
所以想问下你们是怎么装成功的,有没有碰到这个问题
不应该出现这个问题,keepalived的工作原理是首先通过VIP跳转到当前的master机器(绑定了VIP的机器)上,然后如果有IPVS设置的话就IPVS负载均衡,没有的话就直接到本地的6443。我的方案里有负载均衡,但是keepalived的负载均衡会做健康检查,如果从机上的6443没有打开是不会转过去的。
这个问题应该和keepalived本身没关系,你需要检查VIP绑定到哪台机器上,最好nmap扫描一下哪些端口开着。先搞清楚包被送到了哪台机器,在哪里被阻挡的。
大神,那个registry里面的镜像是怎么导入的呢?能否教一下
你好,我想给registry里面加入镜像,那个怎么加?用了网上很多方法都不行。
楼主有没有升级到1.16的教程?