作者 | 邓学祥(祥翼)
来源 | Serverless 公众号
高德从 FY21 财年开始启动 Serverless 建设,至今一年了,高德 Serverless 业务的峰值超过十万 qps 量级,平台从 0 到 1,qps 从零到十万,成为阿里集团内 Serverless 应用落地规模最大的 BU,这中间的过程是怎么样的?遇到过哪些问题?高德为什么要搞 Serverless/Faas?是如何做 Serverless/Faas 的?技术方案是什么样的?目前进展怎么样?后续又有哪些计划?本文将和大家做一个简单的分享。
1. Why-高德为什么要搞 Serverless
高德为什么要搞 Serverless?背景原因是高德 FY21 财年启动了一个客户端上云项目。客户端上云项目的主要目的是为了提升客户端的开发迭代效率。
以前客户端业务逻辑都在端上,产品需求的变更需要走客户端发版才能发布,而客户端发版需要走各种测试流程、灰度流程,解决客户端崩溃等问题,目前的节奏是一个月一个版本。
客户端上云之后,某些易变的业务逻辑放到云上来。新的产品需求在云端来开发,不用走月度的版本发布,加快了需求的开发迭代效率,离产研同频的理想目标又近了一步(为什么要说“又”,是因为高德之前也做了一些优化往产研同频的方向努力,但是我们希望云端一体化开发可以是其中最有效的一个技术助力)。

1.1 目标:客户端开发模式–端云一体
虽然开发模式从以前的端开发转变为现在的云 + 端开发,开发同学应该还是原来负责相应业务的同学,但是大家知道,服务端开发和客户端开发显然是有差异的,客户端开发是面向单机模式的开发,服务端开发通常是集群模式,需要考虑分布式系统的协调、负载均衡、故障转移降级等各种复杂问题。如果使用传统的服务端模式来开发,这个过渡风险就会比较大。
Faas 很好地解决了这一问题。我们结合高德客户端现有的 xbus 框架(一套客户端上的本地服务注册、调用的框架),扩展了 xbus-cloud 组件,使得云上的开发就像端上开发一样,目标是一套代码、两地运行,一套业务代码既能在客户端上运行,也能在服务端上运行。
高德客户端主要有三个端:IOS、android、车机(类 Linux 操作系统)。主要有两种语言:C++ 和 Node.js。传统地图功能:如地图显示、导航路径显示、导航播报等等,由于需要跨三个端,采用的 C++ 语言来开发。地图导航基础之上的一些地图应用功能,如行前/行后卡片、推荐目的地等,主要用 Node.js 来开发。
FY20 财年淘系前端团队开发了 Node.js Faas runtime。高德客户端上云项目,Node.js 的部分就采用了现有的淘系的 Node.js runtime,来接入集团的 Faas 平台,完成 Node.js 这部分的一些业务上云。2020 年十一期间很好地支撑了高德的十一出行节业务。
C++ Faas 没有现有的解决方案,因此我们决定在集团的基础设施之上做加法,新建 C++ Faas 基础平台,来助力高德客户端上云。
1.1.1 端云一体的最佳实践关键:客户端和 Faas 之间的接口抽象
原本客户端的逻辑移到 Faas 服务端上来,或者新的需求一部分在 Faas 服务端上开发,这里的成败关键点在于:客户端和 Faas 的接口协议定义,也就是 Faas 的 API 定义,好的 API 定义除了对系统的可维护性有好处以外,对后续支撑业务的迭代开发也很重要,好的 API 定义请参考谷朴大神的文档:《API 设计最佳实践的思考》。
理想情况下:客户端做成一个解析 Faas 返回结果数据的一个浏览器。浏览器协议一旦定义好,就不会经常变换,你看 IE、Chrome 就很少更新。当然我们的这个浏览器会复杂一些,我们这个浏览器是地图浏览器。如何检验客户端和 Faas 之间的接口定义好不好,可以看后续的产品需求迭代,如果有些产品需求迭代只需要在 Faas 上完成,不需要客户端的任何修改,那么这个接口抽象就是成功的。
1.2 BFF 层开发提效
提到高德,大家首先想到的应该是其工具属性:高德是一个导航工具(这个说法现在已经不太准确了,因为高德这几年在做工具化往平台化的转型,我们要做万能的高德,高德的交易类业务正在兴起,高德打车、门票、酒店等业务发展很迅猛)。
针对高德导航来说,相比集团其他业务(如电商)来说,有大量的只读场景是高德业务的一大技术特点。这些只读场景里,大量的需求是 BFF(Backend For Frontend)类型的只读场景。为什么这么说?因为导航的最核心功能,例如 routing、traffic、eta 等都是相对稳定的,这部分的主要工作在持续不断地优化算法,使得高德的交通更准,算出的路径更优。这些核心功能在接口和功能上都是相对比较稳定的,而前端需求是多变的,例如增加个路径上的限宽墩提示等。

Faas 特别适合做 BFF 层开发,在 Faas 上调用后端相对稳定的各个 Baas 服务,Faas 服务来做数据和调用逻辑封装、快速开发、发布。在业界,Faas 用的最多的场景也正是 BFF 场景(另外一个叫法是 SFF 场景,service for frontend)。
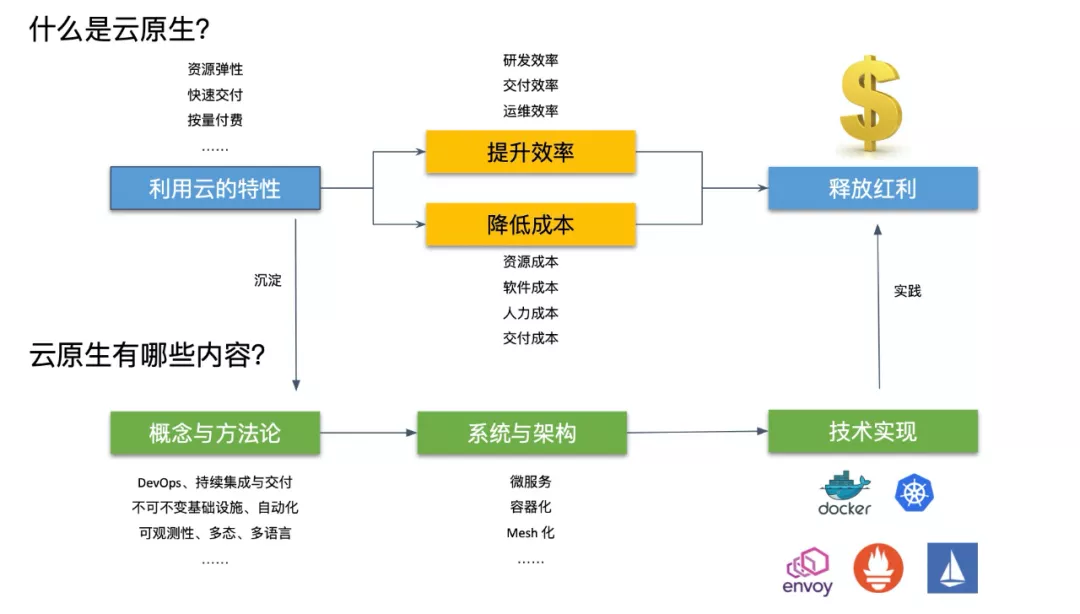
1.3 Serverless 是云时代的高级语言
FY21,高德是集团内第一个全面上云的 BU,虽然高德已经全面上云了,但是这还不是云时代的终局,目前主要是全面 pouch 化并上云,容器方面做了标准化,在规模化、资源利用率方面可以全面享受云的红利,但是业务开发模式上基本上还和以前一样,仍是一个大型的分布式系统的写法。对于研发模式来说还并没有享受云的红利,可以类比为我们现在是在用汇编语言的方式来写跑在云上的服务。而 Serverless、云原生可以理解为云时代的高级语言,真正做到了 Cloud as a computer,只需要关注于业务开发,不需要考虑大型分布式系统的各种复杂性。
1.4 Go-Faas 补充 Go 语言生态
前面讲到了因为客户端上云项目,我们在阿里云 FC(函数计算)团队之上做加法,开发了 C++ Faas Runtime。不仅如此,我们还开发了 Go-Faas,我们为什么会做 Go-Faas 呢?这里也简单介绍一下背景,高德服务端 Go 部分的 qps 峰值已超百万。高德已补齐了阿里各中间件的 Go 客户端,和集团中间件部门共建。可观测性、自动化测试体系也基本完善,目前 Go 生态已基本完善。补齐了 Go-Faas 之后,我们就既能用 Go 写 Baas 服务,又能用 Go 写 Faas 服务了,在不同的业务场景采用不同的服务实现方式,Go-Faas 主要应用于上文提到的 BFF 场景。
2. How-技术方案介绍:在集团现有基础设施之上做加法
2.1 整体技术架构
上文讲了我们为什么要做这个事情,接下来讲我们具体是怎么做这个事情的,是如何实现的,具体的技术方案是什么样的。
本着在集团现有的基础设施、现有的中间件基础之上做加法的思想,我们和 CSE、阿里云 FC 函数计算团队合作共建,开发了 C++ Faas Runtime 和 Go Faas Runtime。整体和集团拉通的技术架构如下图所示,主要分为研发态、运行态、运维态三个部分。

2.1.1 运行态
先说运行态,业务流量从我们网关进来,调用到 FC API Server,转发到 C++/Go Faas Runtime,runtime 来完成用户函数里的功能。runtime 的架构本文下一章节会具体介绍。
和 runtime container 一起部署的有监控、日志、Dapr 各种 side car,side car 来完成各种日志采集上报功能,dapr side car 来完成调用集团中间件的功能。
另外目前 dapr 还在试点的阶段,调用中间件主要是通过 Broker 和各个中间件 proxy 来完成,中间件调用的有HSF、Tair、metaq、diamond 等中间件 proxy。
最后 Autoscaling 模块来管理函数实例的扩缩容,达到函数自动伸缩的目的。这里的调度就有各种策略了,有根据请求并发量的调度、函数实例的 CPU 使用率的调度。也能提前设置预留实例数,避免缩容到 0 之后的冷启动问题。
底层调用的是集团 ASI 的能力,ASI 可以简单理解为集团的 K8S+ sigma(集团的调度系统),最终的部署是 FC 调用 ASI 来完成函数实例部署,弹性伸缩的,部署的最小单位是上图中的 pod,一个 pod 里包含 runtime container 和 sidecar set container。
2.1.2 研发态
再来看研发态,运行态决定函数是如何运行的,研发态关注函数的开发体验,如何方便地让开发者开发、调试、部署、测试一个函数。
C++ Faas 有个跨平台的难点问题,C++ Faas runtime 里有一些依赖库,这些依赖库没有 Java 依赖库管理那么方便。这样依赖库的安装比较麻烦,Faas 脚手架就是为了解决这个问题,调用脚手架,一键生成 C++ Faas 示例工程,安装好各种依赖包。为了本地能方便地 debug,开发了一个 C++ Faas Runtime Boot 模块,函数 runtime 启动入口在 boot 模块里,boot 模块里集成 runtime 和用户 Faas 函数,可以对 runtime 来做 debug 单步调试。
我们和集团 Aone 团队合作,函数的发布集成到 Aone 环境上了,可以很方便地在 Aone 上来发布 Go 或者 C++ Faas,Aone 上也集成了一键生成 example 代码库的功能。
C++ 和 Go Faas 的编译都依赖相应的编译环境,Aone 提供了自定义编译镜像的功能,我们上传了编译镜像到集团的公共镜像库,函数编译时,在函数的代码库里指定相应的编译镜像,编译镜像里安装了 Faas 的依赖库、SDK等。
2.1.3 运维态
最后来看函数的运维监控,runtime 内部集成了鹰眼、sunfire 采集日志的功能,runtime 里面会写这些日志,通过 sidecar 里的 agent 采集到鹰眼、或者 sunfire 监控平台上去(FC 是通过 SLS 来采集的)之后,就能使用集团现有的监控平台来做 Faas 的监控了,也能接入集团的 GOC 报警平台。
2.2 C++/Go Faas Runtime 架构
上面讲的是和 Aone、FC/CSE、ASI 集成的一个整体架构,Runtime 是这个整体架构的一部分,下面具体讲讲 Runtime 的架构是怎样的,Runtime 是如何设计和实现的。

最上面部分的用户 Faas 代码只需要依赖 Faas SDK 就可以了,用户只需要实现 Faas SDK 里的 Function 接口就能写自己的 Faas 了。然后如果需要调用外部系统,可以通过 SDK 里的 Http Client 来调用,如果要调用外部中间件,通过 SDK 里的 Diamond/Tair/HSF/metaq Client 来调用中间件就可以。SDK 里的这些接口屏蔽了底层实现的复杂性,用户不需要关心这些调用最后是如何实现,不需要关心 runtime 的具体实现。
SDK 层就是上面提到的 Function 定义和各种中间件调用的接口定义。SDK 代码是开发给 Faas 用户的。SDK 做的比较轻薄,主要是接口定义,不包含具体的实现。调用中间件的具体实现在 Runtime 里有两种实现方式。
往下是 Runtime 的一个整体架构。Starter 是 runtime 的启动模块,启动之后,runtime 自身是一个 Server,启动的时候根据 Function Config 模块的配置来启动 runtime,runtime 启动之后开启请求和管理监听模式。
再往下是 Service 层,实现 SDK 里定义的中间件调用的接口,包含 RSocket 和 dapr 两种实现方式,RSocket 是通过 RSocket broker 的模式来调用中间件的,runtime 里集成了 dapr(distributed application runtime),调用中间件也可以通过 dapr 来调用,在前期 dapr 试点阶段,如果通过 dapr 调用中间件失败了,会降级到 rsocket 的方式来调用中间件。
再往下就是 rsocket 的协议层,封装了调用 rsocket 的各种 metadata 协议。dapr 调用是通过 grpc 方式来调用的。
最下面一层就是集成了 rsocket 和 dapr 了。
rsocket 调用还涉及到 broker 选择的问题,upstream 模块来管理 broker cluster、broker 的注册反注册、keepalive 检查等等,LoadBalance 模块来实现 broker 的负载均衡选择以及事件管理、连接管理、重连等等。
最后 runtime 里的 metrics 模块负责鹰眼 trace 的接入,通过 filter 模式来拦截 Faas 链路的耗时,并输出鹰眼日志。打印 sunfire 日志,供 sidecar 去采集。下图是一个实际业务的 sunfire 监控界面:

2.2.1 Dapr
dapr 架构如下图所示,具体可以参考官方文档。

runtime 里以前调用中间件是通过 rsocket 方式来调用的,这里 rsocket broker 会有一个中心化问题,为了解决 outgoing 流量去中心化问题,和集团中间件团队合作引入了 dapr 架构。只是 runtime 层面集成了 dapr,对于用户 Faas 来说无感知,不需要关心具体调用中间件是通过 rsocket 调用的还是通过 dapr 调用的。后面 runtime 调用中间件切换到 dapr 之后,用户 Faas 也是不需要做任何修改的。
3. How-业务如何接入 Serverless
如前文所述,接入统一在 Aone 上接入。提供了 C++ Faas/Go Faas 的接入文档。提供了函数的 example 代码库,代码库有各种场景的示例,包括调用集团各种中间件的代码示例。C++ Faas/Go Faas 的接入对整个集团开发,目前已经有一些高德以外的 BU,在自己的业务中落地了 C++ /Go Faas。Node.js Faas 使用淘宝提供的 runtime 和模板来接入,Java Faas 使用阿里云 FC 提供的 runtime 和模板来接入就可以了。
3.1 接入规范-稳定性三板斧:可监控、可灰度、可回滚
针对落地新技术大家可能担心的稳定性问题,我们的应对法宝是阿里集团的稳定性三板斧:可监控、可灰度、可回滚。建立 Faas 链路保障群,拉通上下游各相关业务方、基础平台一起,按照集团的 1-5-10 要求,共同努力做到 1 分钟之内响应线上报警、快速排查;5 分钟之内处理;10 分钟之内恢复。
为了规范接入过程,避免犯错误引发线上故障,我们制定了 Faas 接入规范和 checkList,来帮助业务方快速使用 Faas。
可监控、可灰度、可回滚是硬性要求,除此之外,业务方如果能做到可降级就更好了。我们的 C++ 客户端上云业务,在开始试点阶段,就做好了可降级的准备,如果调用 Faas 端失败,本次调用将会自动降级到本地调用。基本对客户端功能无损,只是会增加一些响应延迟,另外客户端上该功能的版本,可能会比服务端稍微老一点,但是功能是向前兼容的,基本不影响客户端使用。
4. Now-我们目前的情况
4.1 基础平台建设情况
- Go/C++ Faas Runtime 开发完成,对接 FC-Ginkgo/CSE、Aone 完成,已发布稳定的 1.0 版本。
- 做了大量的稳定性建设、优雅下线、性能优化、C 编译器优化,使用了阿里云基础软件部编译器优化团队提供的编译方式来优化 C++ Faas 的编译,性能提升明显。
- C++/Go Faas 接入鹰眼、sunfire 监控完成,函数具备了可观测性。
- 池化功能完成,具备秒级弹性的能力。池化 runtime 镜像接入 CSE,扩一个新实例的时间由原来的分钟级变为秒级。
4.2 高德的 Serverless 业务落地情况
C++ Faas 和 Go Faas 以及 Node.js Faas 在高德内部已经有大量的应用落地。举几个例子:

上图中的前两个图是 C++ Faas 开发的业务:长途天气、沿途搜。后两个截图是 Go-Faas 开发的业务:导航 tips、足迹地图。
高德是阿里集团内 Serverless 应用落地规模最大 的BU,已落地的 Serverless 应用,日常峰值超过十万 qps 量级。
4.3 主要收益
高德落地了集团内规模最大的 Serverless 应用之后,都有哪些收益呢?
首先第一个最重要的收益是:开发提效。我们基于 Serverless 实现的端云一体组件,助力了客户端上云,解除了需要实时的客户端发版依赖问题,提升了客户端的开发迭代效率。基于 Serverless 开发的 BFF 层,提升了 BFF 类场景的开发迭代效率。
第二个收益是:运维提效。利用 Serverless 的自动弹性扩缩容技术,高德应对各种出行高峰就更从容了。例如每年的十一出行节、五一、清明、春节的出行高峰,不再需要运维或者业务开发同学在节前提前扩容,节后再缩容了。高德业务高峰的特点还不同于电商的秒杀场景。出行高峰的流量不是在 1 秒内突然涨起来的,我们目前利用池化技术实现的秒级弹性的能力,完全能满足高德的这个业务场景需求。
第三个收益是:降低成本。高德的业务特点,白天流量大、夜间流量低,高峰值和低谷值差异较大,时间段区分明显。利用 Serverless 在夜间流量低峰时自动缩容技术,极大地降低了服务器资源的成本。
5. Next-后续计划
- FC 弹内函数计算使用优化,和 FC 团队一起持续优化弹内函数计算的性能、稳定性、使用体验。用集团内丰富的大流量业务场景,来不断打磨好 C++/Go Faas Runtime,并最终输出到公有云,普惠数字化转型浪潮中的更多企业。
- Dapr 落地,解决 outcoming 流量去中心化问题,逐步上线一些 C++/Go Faas,使用 Dapr 的方式调用集团中间件。
- Faas 混沌工程,故障演练,逃生能力建设。Faas 在新财年也会参与我们 BU 的故障演练,逐一解决演练过程中发现的问题。
- 接入边缘计算。端云一体的场景下,Faas + 边缘计算,能提供更低的延时,更好的用户体验。
以上要做的事情任重道远,另外 FY22 财年我们部门还会做云原生的试点和落地。技术同学都知道,从技术选型、技术原型到实际业务落地,这之间还有很长的路要走。
欢迎对 Serverless、云原生、或者 Go 应用开发感兴趣,想一起做点事情的小伙伴来加入我们(不管之前是什么技术栈,英雄不问出处,投简历到 gdtech@alibaba-inc.com,邮件主题为:姓名-技术方向-来自 Serverless),这里有大规模的落地场景和简单开放的技术氛围,欢迎自荐或推荐!
本文整理自阿里巴巴高级技术专家–祥翼在【阿里云 Serverless Developer Meetup 上海站】上的分享
ppt 获取方式:关注 Serverless 公众号,后台对话框回复“ppt”即可
直播回放观看地址:https://developer.aliyun.com/live/246653