引言
如果说2019年是“云原生技术商业化元年”,那么2020年就是“云原生技术成为新常态”的一年。在这一年里,云原生技术正在快速开拓新的技术边界,支持新的应用范式,并更加关注全栈能力和生态建设。突如其来的疫情,更是给2020年的云原生应用落地速度与格局带来了深远的影响,云原生技术已经成为传统企业数字化转型的唯一解决方案。在这样的背景下,云原生技术实践联盟(CNBPA)联合灵雀云、云原生技术社区发起了“2020-2021年(第三期)传统行业云原生技术落地调研”。调研期间,总计收到了783份有效调研问卷,参与者分别来自金融、制造、能源、医药、电信、政企等不同领域、不同规模的传统企业。本次调研与前两期相比在多个维度上保持了统一和延续性,同时也对技术问题的颗粒度进行了更细致的拆解,不仅可以纵向对比前两年的调研数据,宏观了解云原生技术在传统行业的应用情况在三年内的变化,还可以深入了解企业在云原生基础设施、应用架构、开发流程、数据服务等各个板块的应用情况和落地成熟度,带您从全栈角度重新观察云原生。
核心观点
云原生技术(容器、DevOps、微服务)在生产环境中的应用相比去年已翻倍;
Kubernetes 已成为所有基础设施类软件的核心;
Service Mesh 使用率呈猛增势头,有望超过 Spring Cloud 成为市场最受欢迎的微服务框架;
服务网格、无服务及边缘计算成为企业最关注的三个云原生新兴方向;
01: 疫情之下,传统企业的IT规模逆势上扬
2020年,我国是全球唯一经济正增长的主要经济体,“新基建”与“增强产业链能力”等政策极大促进了传统企业数字化转型的发展。随着云计算在各行各业的落地不断深化,被技术赋能的传统企业早已将加速构建企业级云平台,作为创新发展的重要行动目标。
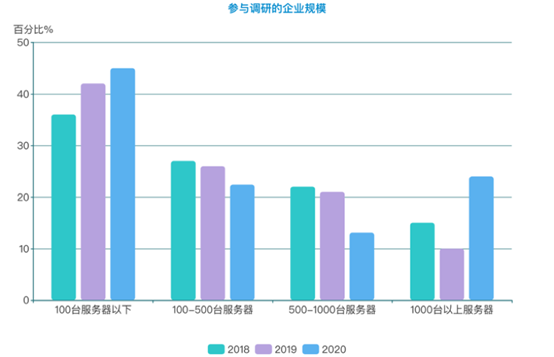
今年参与调研的企业中,100台服务器以下的企业占40.4%,100-500台服务器规模的占22.4%,500-1000台服务器的占13.1%,1000台以上服务器的企业则达到了24%,是2019年的2倍。
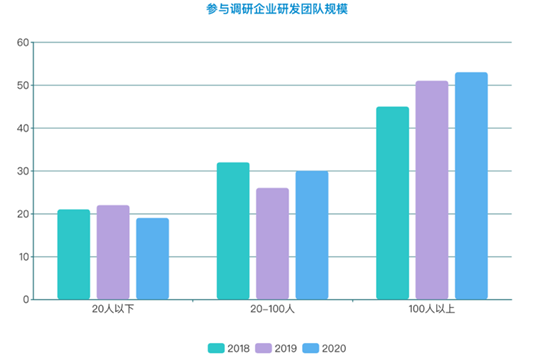
从团队规模来看,拥有100人以上研发团队的企业达到了52%,创三年调研的新高。

在问到企业IT预算投入的问题时, IT预算下降的企业占24.1%,增长保持在1%-5%的占38.4,增长5-10%的比例为22.1%,还有15.5%的企业IT预算有10%以上的增长。对比往年数据不难发现,2020年疫情像是为云时代的到来按下了加速键,传统企业的数字化转型步伐加快,IT投入上呈稳步增长态势。拥有较大IT规模企业,服务器用量与团队规模在2020年都有明显扩张,初创型及中型企业也基本维持了前两年的IT规模。
02: 云原生技术(包括容器、DevOps、微服务)在生产环境中的应用相比去年已翻倍
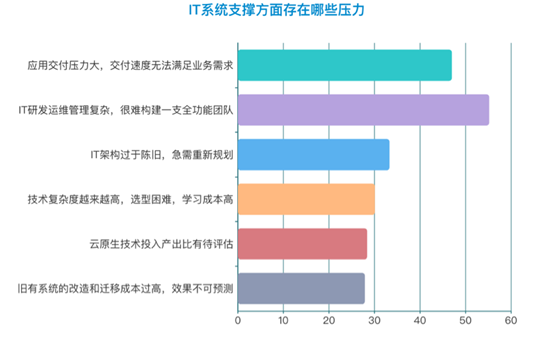
在云原生技术的支撑下,IT系统每周、每月更新升级的企业比例都有所升高,3-6个月更新以及半年更新的企业比例再次下降。相应地,系统维护压力和学习成本越来越高,给企业IT部门带来巨大挑战。
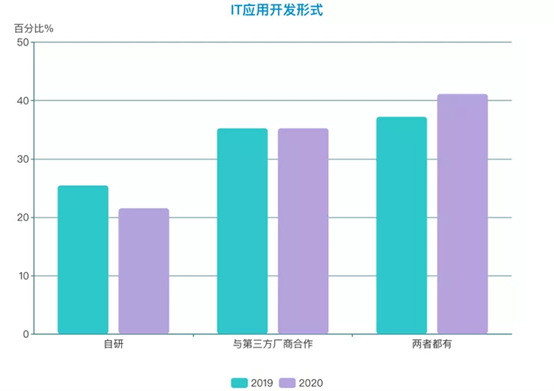
伴随着云原生技术的普及,企业面临着自研和外采的两难选择。自研不但人力成本和时间成本较高,也会遇到技术选型困难、陡峭的学习曲线、投入产出比预期复杂,效果难预测等情况。对比去年数据,在选用云原生技术时,依靠自研能力自建云原生平台的企业在逐年减少,同时企业呈现了与专业的云原生技术厂商合作的趋势,采购相对标准化的第三方云原生基础平台,自身聚焦于应用开发,已经成为用户实现云原生落地最稳健的选择。
对于云原生技术落地阶段,调研数据如预期——将包括容器、DevOps、微服务在内的云原生技术用于核心业务生产的企业已达到34.89%,相比往年数据有近1倍的提升。这也从侧面说明,云原生这一整套的技术体系和方法论,在几年的落地实践中已经为企业取得了显著的业务成果,在企业数字化转型中扮演了重要的角色。
03: 云原生基础设施:Kubernetes已成为所有基础设施类软件的核心
在过去几年,容器完全改变了云计算的基础设施架构。但云原生的基础设施到今天已经远远不限于容器管理,在大规模企业落地时,会看到一些更加现实的业务应对和趋势。
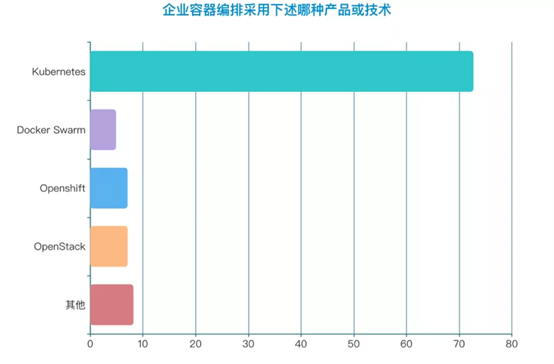
调查显示,受访企业中,72.7%的企业采用Kubernetes作为容器编排技术,保持了绝对的优势地位。这与最近CNCF发布的中国区云原生调查报告中的数据保持了相当高的一致性,同期全球调查报告的数字是78%。我们可以看到,在Kubernetes的使用率上,国内传统企业与全行业,甚至全球Kubernetes的使用率是持平的,Kubernetes已经完全进入主流市场,成为所有人都在使用的技术。多云部署的快速推进,与Kubernetes在企业生产环境中的运用不无关系。Kubernetes作为一个可移植层,它能够屏蔽基础设施的很多细节,可以很容易地做跨云迁移,对混合云和多云管理非常有好处。
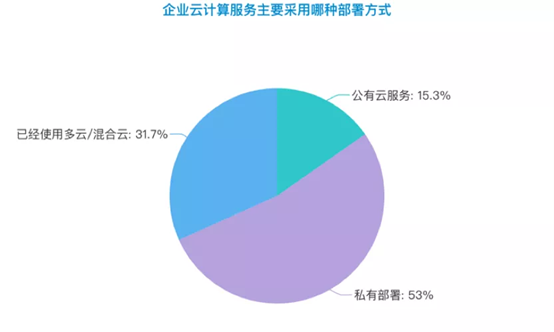
调查显示,有15.3%的被访问企业的云计算服务部署在公有云,53%部署在私有云,31.7%已经使用了多云/混合云的部署方式。另外,还有48.9%的受访人表示,所在的企业将要考虑多云/混合云部署云服务,也就是说,近8成未采用多云/混合云部署云服务的企业,打算在将来采用。由此可见,传统企业中多云/混合云部署已成明确的趋势。
04: 云原生应用架构:Service Mesh使用率呈猛增势头,有望超过Spring Cloud成为市场最普遍的微服务框架
企业一定要意识到微服务并不是免费的,它的本质是用运维的复杂度去换取敏捷性。因此在微服务改造大行其道的今天,企业采用微服务仍能遇到一些阻力和问题。
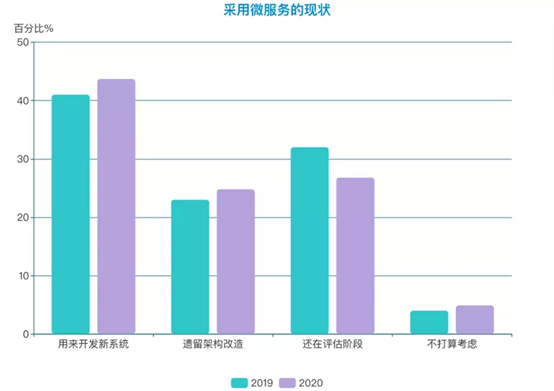
对比2019-2020两年数据,受调研的企业在微服务采用阶段上基本保持了相对稳定的比例。采用微服务开发新系统(41% / 43.7%)和对遗留应用进行改造(23% / 24.8%)的企业比例都有些许提升。同时,彻底不打算实施微服务架构的企业比去年同期有所增加,说明部分企业对于到底需不需要这样的敏捷性,有没有必要用过多的复杂度作为代价,也经历了深入的思考和判断。

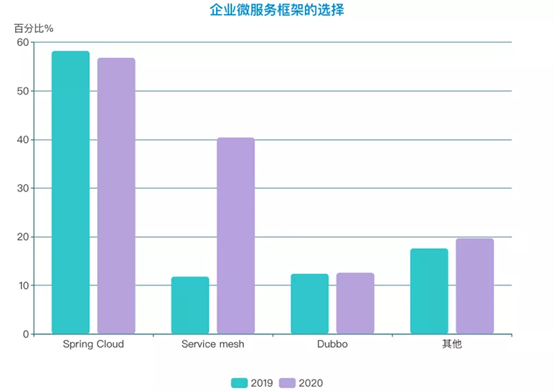
对于微服务框架的选择,今年的调研数据有比较大的突破。虽说市面上存在丰富的微服务框架,可是对稳定有极高要求的传统企业却常常陷入无型可选的尴尬境地,这也是为何Java系的Spring Cloud在前几年几乎一统天下的原因。以 Istio为代表的新一代微服务框架Service Mesh虽然还在演进过程中,但经过几年的实践深耕,以及在头部互联网企业宣传和能力平台化的推动下,已经被认定为微服务治理的最佳实践。在被调研的企业中,Service Mesh的使用率从2019年的11.8%提升到了今年的40.4%,涨幅达到三倍。Spring Could虽然仍占据选型第一的位置,但Service Mesh的势头不容小觑。
在用微服务架构开发新的应用系统的过程中,企业也不可避免地遇到了诸多难题。最大的挑战是“微服务拆分缺乏专业的人才,没有最佳实践指导”,占57.4%之多。微服务的演进成熟需要时间,企业熟悉掌握和应用新技术也需要时间。如果在没有明确业务需求、相应组织架构及技术关键细节的前提下,就强推微服务框架,反而有可能会达到反向作用。
05: 云原生开发流程:超6成DevOps基于容器建设
云原生技术的普及带来了诸多红利,其中之一就是DevOps产业的井喷式发展。在与容器化的新一代基础设施以及微服务架构搭配下,DevOps能够更加充分地利用云化资源、自动弹性伸缩等特性,在保证稳定的同时,更加快速交付高质量的软件及服务,灵活应对快速变化的业务需求和市场环境。

对比往年数据,DevOps已经实施或即将实施的比例越来越高,今年逼近9成。这其中,有62.3%的企业DevOps建立基于容器环境,25.7%的企业基于物理环境或VM。
DevOps的深入渗透,和云原生技术推动数字化转型的步伐基本保持了一致。我们认为,在云原生场景下,平台需要覆盖 DevOps完整的流程和场景,DevOps使用的整条工具链需要和Kubernetes平台对齐打通。不仅如此,Kubernetes可以编排一切,DevOps工具可以放在Kubernetes平台上去做管理。
这与Gartner于2020年9月发布的首份“Market Guide for DevOps Value Stream Delivery Platform(VSDP)”(DevOps价值流交付平台的市场指南报告)中的观点相一致。该报告指出,所有采用DevOps的企业都将从工具链方式向平台方式转型,到2023年,预计将有40%的企业和组织采用平台化方式的DevOps价值链交付平台。
06: 云原生数据服务:超5成受访企业考虑迁移至云原生数据库
在去年的调研中我们提到,企业在落地云原生的时候更关注完整、体系化的云原生解决方案。所以越来越多的数据库、存储、网络、中间件、安全等周边技术、组件正在跟云原生技术对齐。其中,容器化的数据服务目前成为为企业云原生的一个重要落脚点。
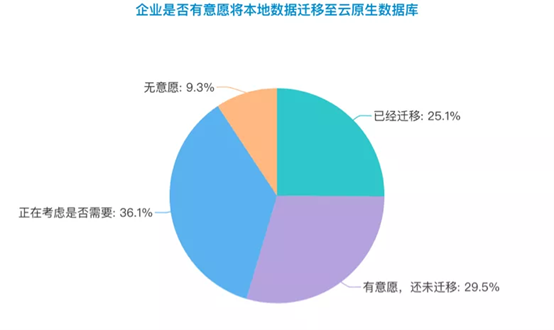
在问到企业是否愿意将本地数据迁移至云原生数据库时,调研数据显示,25.1%的受访企业已经做了迁移,而有29.5%的企业表示有意愿,还未迁移,另有36.1%的企业表示正在评估。
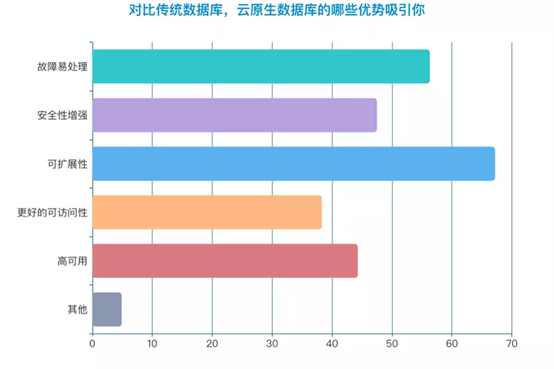
在对比云原生数据库与传统数据库时,“云原生数据库可扩展性”、“故障易处理”、“安全性增强”等优势成为传统行业企业最看中的优势。从调研结果可以看到,实施云原生过程中,越来越多的企业对于数据服务类的组件,已经不再满足于把数据服务留在虚拟机甚至物理机中“稳字当头“的应对思路了,提供兼容广泛的开源数据库、各类主流数据服务在Kubernetes Operator上实现自动化运维的一站式解决方案,将帮助企业降低开发测试人员的使用、管理成本,更专注于业务本身。
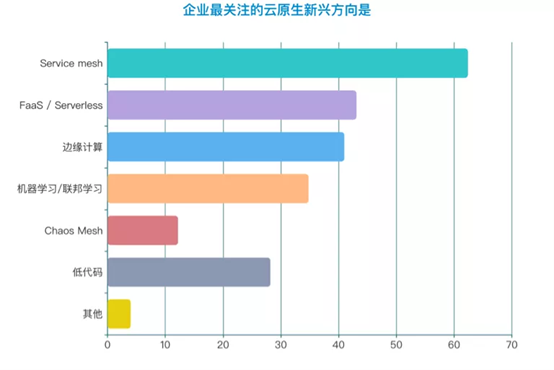
07: 展望未来:服务网格、无服务及边缘计算成企业最关注的三个云原生新兴方向
在已有工作重点的基础上,传统企业还将目光投向了云原生的新兴方向。最受企业关注的依然是服务网格(Service mesh),如前面调研数据显示,Service Mesh在企业中呈爆发性增长,有望成为市场上使用最普遍的微服务框架,但Service Mesh的成熟度还有待考察。
在新兴技术关注度上排名第二的是无服务器架构(FaaS/Serverless),Serverless是正在兴起的一种云原生工作负载,从 CNCF的调查报告来看,Serverless的普及率要高于service mesh。但是多数Serverless的使用都是在公有云上面,目前来说公有云上的 Serverless能力也会更加成熟,但长期来看,私有云环境也会慢慢有对Serverless编程范式和架构范式的需求。排名第三的是边缘计算,边缘计算是对云计算的一个补充和拓展。随着5G的发展,运营商、工业制造、智慧城市等传统行业都会涉及到海量、超低延时、多样性的数据处理,边缘计算就显得尤为重要了。数据表明,“新基建”时代80%的数据和计算将发生在边缘,并会有更多场景落地。此外,机器学习/联邦学习、低代码、Chaos mesh 也得到了企业相当多的关注。 综上,从整个报告的数据来看,传统行业企业开始全面拥抱云原生。基础设施、应用架构、开发流程、数据服务等方面的云原生化改造,让更多业务应用从诞生之初就生长在云端,从技术理念、核心架构等多个方面,帮助企业IT平滑、快速、渐进式落地上云之路。