
从单体到微服务,再到 Serverless,应用在逐渐地轻量化。有人可能会有疑问,微服务都还没有顺畅的搭建起来,现在又出了 Serverless,应该怎么办?
其实两者之间并不是一个相互替代的关系。我们可以看到,现在有单体应用在跑,也有微服务的应用在跑,那么以后 Serverless 这种应用也会有一定的用途。而微服务里也可以调用 Serverless 的函数(function)。
Serverless 定义
Serverless 类似于之前大数据的概念,大家都知道,但不是特别确切了解其中的含义。
CNCF 有一个 Serverless 工作组,在 Serverless 的白皮书中进行了定义。简单来讲就是,Serverless 等于 FaaS(Function-as-a-Service) 加上 BaaS(Backend-as-a-Service)。我们可以将应用程序以函数的形式打包,然后上传到 FaaS 平台。这样我们就不用关心底层服务器的运维,因为它能自动扩展,而且是按需收费。

Serverless 有一个很重要的特征,就是事件驱动模式,即依赖于外部事件去触发它运行。
至于 Backend-as-a-Service,你可以理解成支撑 Serverless 运行的一些 API 的服务,比如对象存储或者是数据库服务。
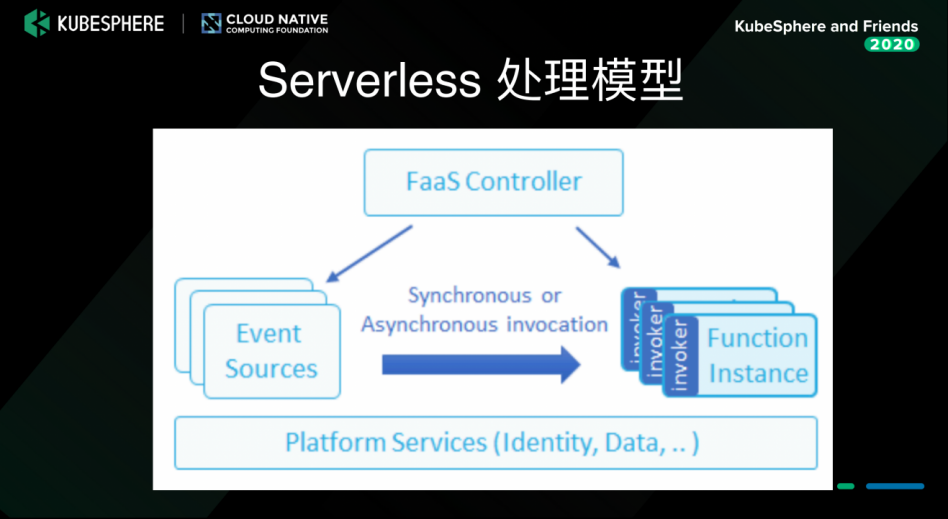
Serverless 处理模型
下图是 Serverless 的处理模型。上文讲到,它的模式是事件触发,所以它会有事件源产生事件,然后 FaaS 的 controller 是根据这些事件去启动 function 的 instance,而且能够实时的去扩展,能够 scale 到 0,这样动态的去给用户提供服务。
函数生命周期
函数(function)是有生命周期的,也就是函数部署流水线的流程。首先提供 function 的源码和 spec,然后把源码 build 成 docker image,再把 docker image 部署到 FaaS 平台上。
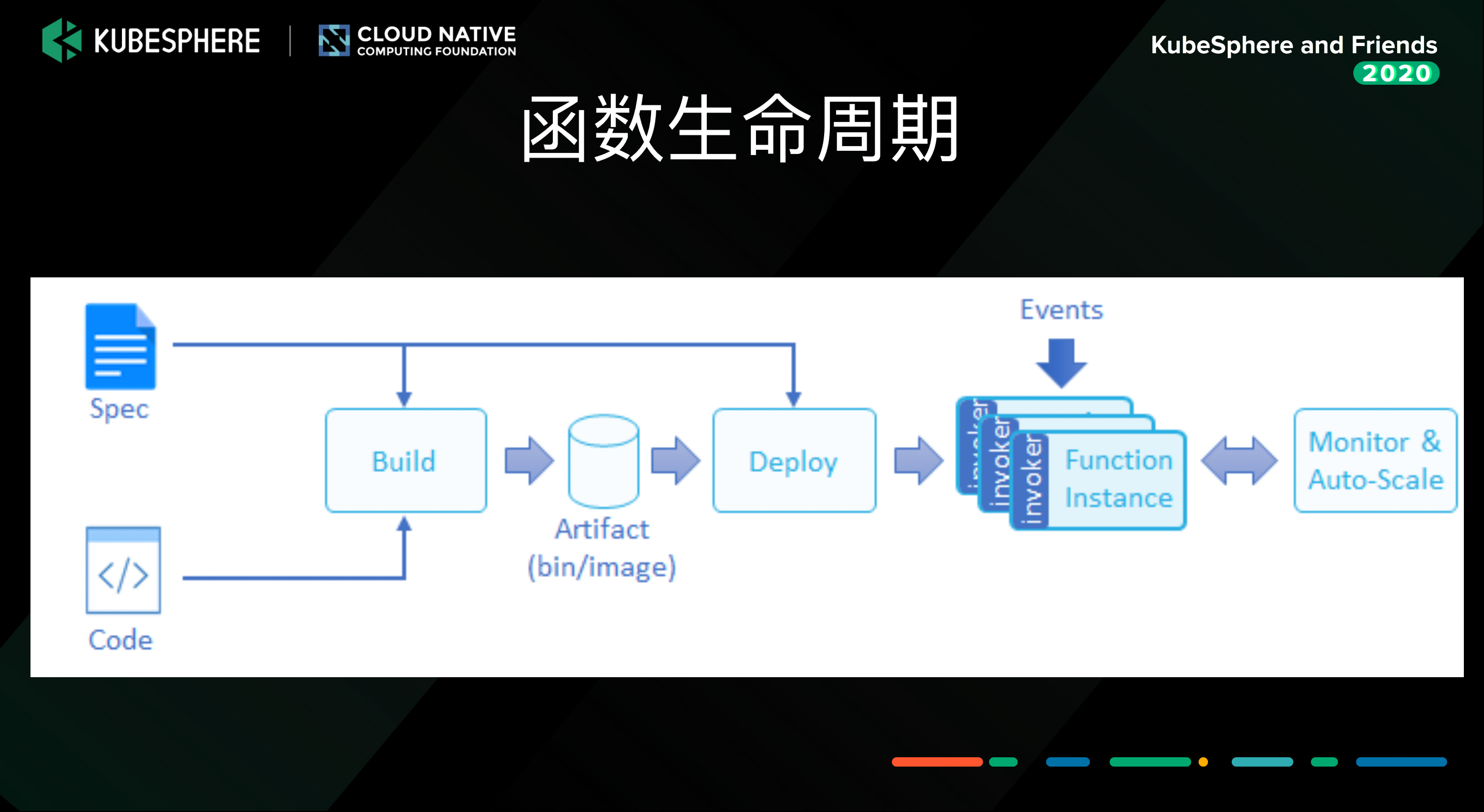
涉及到函数,肯定会有函数的创建、更新、发布等操作,因篇幅关系,这里就不再赘述了。

Serverless 应用场景
对 IoT 设备数据进行分析
目前边缘计算,还有 IoT 的应用都在逐渐地兴起。 比如 IoT 中的一个传感器,它会源源不断的产生一些数据(例如传感器温度超过了 60 度),我们可以调用一个云端的函数来处理这件事情(发个通知或者做一个应用)。所以 Serverless 和 IoT 这个场景可以很好地结合起来。

AI 模型服务
AI 也在逐渐兴起。边缘或者是云端提供模型的服务,因为很多模型的推理都要占用 GPU,所以如果一直占用 instance,非常耗费资源,而且还增加了成本。但是如果用 Serverless 这种方式去提供服务,比如利用 Kubeflow 项目下的 KFServing 提供推理服务,在空闲的时候可以 scale 到 0,有流量的时候会自动 scale up 起来,所以能很好地节省成本。
其他场景见上图,因为篇幅关系不再一一展开讲述。
Serverless 优势
- 降低成本
- 提高资源利用率
- 无需关系底层基础设施的运维及管理
- 灵活可拓展
- 提升开发效率
开源 Serverless 平台
我们针对开源的 Serverless 平台做了一个调研。下图中列出的都是开源的 Serverless 平台,可以分为两类,一类是 Knative,另一类就是非 Knative。
为什么这么分类呢?因为上文讲到,Serverless 主要就是有一个 FaaS 的功能,但 Knative 并不是一个严格意义上的 FaaS 平台,而其他开源的 Serverless 平台都属于 FaaS 平台。

下图是在 Google trend 上查询到的数据。在过去一年中, Knative 的热度基本是最高的,OpenFaaS 的热度在 FaaS 平台中是比较靠前的。而过去 5 年的数据也类似,可以说,Knative 自问世以来,热度一直居高不下。
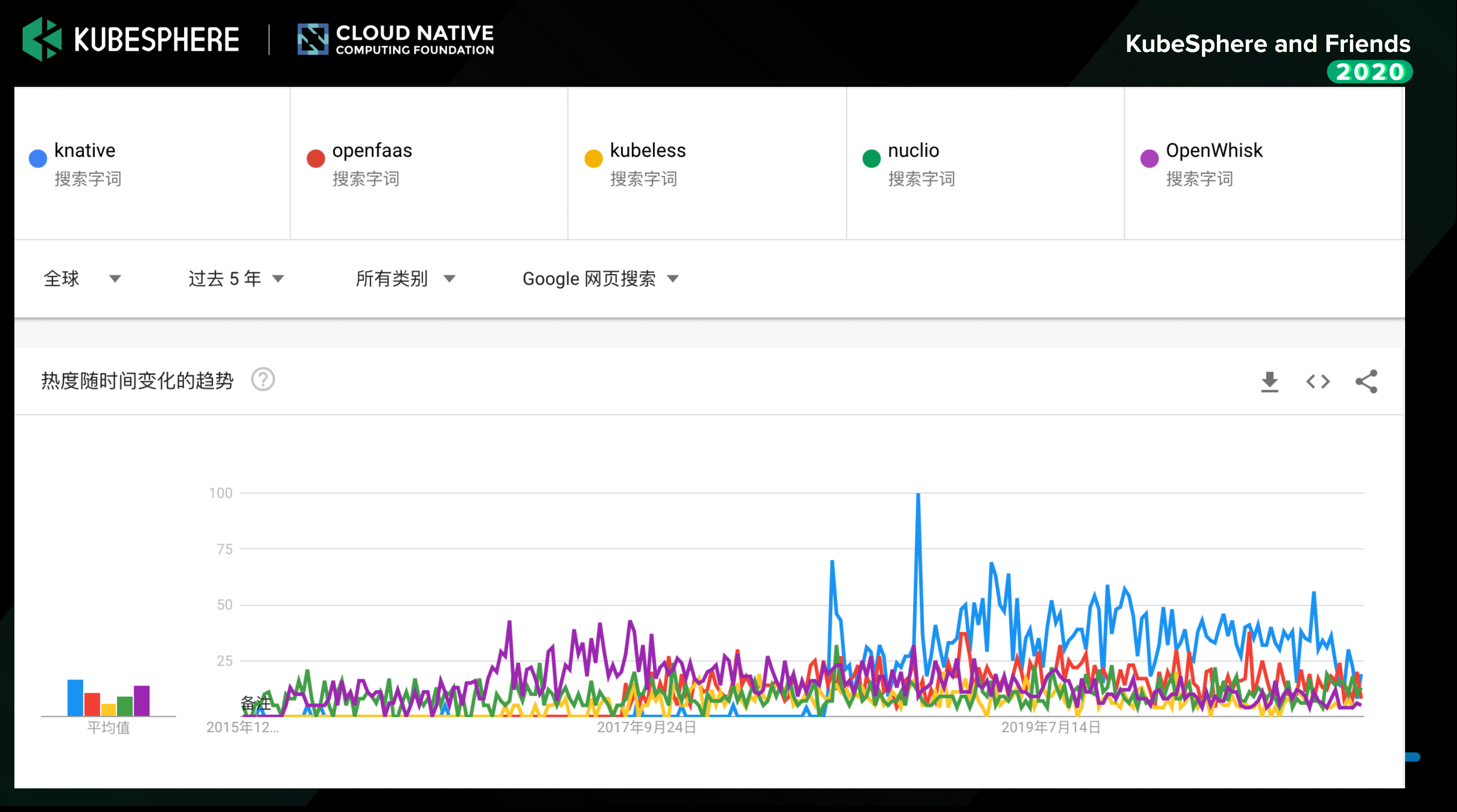
下图是 CNCF 去年做的一个调查,调查显示,在可安装的 Serverless 平台里,Knative 是比较领先的,然后 OpenFaaS 在 FaaS 平台里是比较领先的。

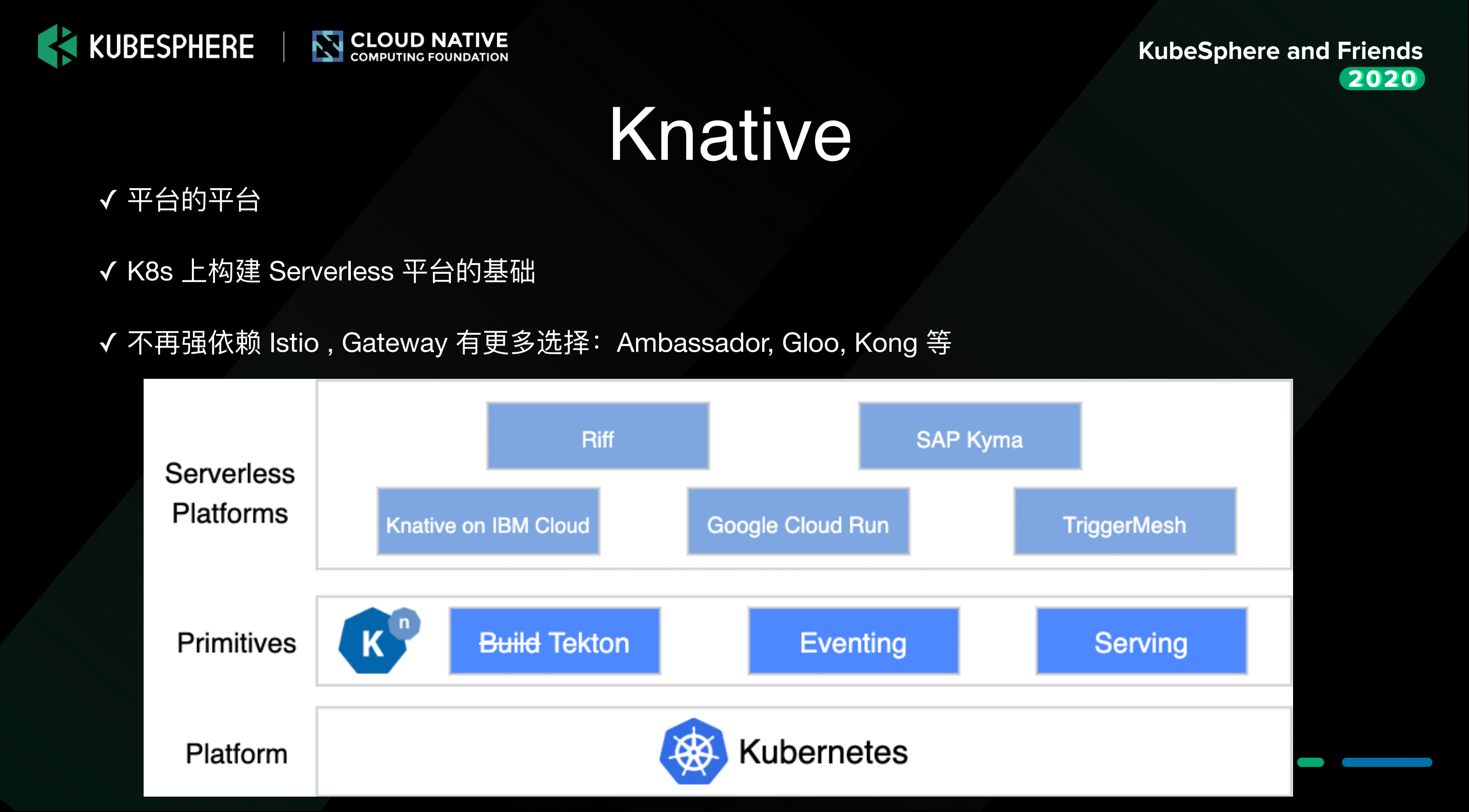
Knative 的优势
大家可能会有疑问,上文说到 Knative 并不是一个严格意义上的 FaaS 平台,那么它为什么在 Serverless 领域会这么受欢迎呢?
有以下几个原因:
- Serverless 有几个要素,首先它是事件驱动的,所以它要对事件有很好的支撑。通过 Knative Eventing,可以对事件的管理有很好的支持,也形成了一套 cloudevent 规范,用于 Serverless 负载的交互。
- 我们上文讲到了,它需要把函数的源码去 build 成一个 docker 镜像,所以它也要有 build 的能力。之前这个组件叫knative build,现在叫 Tekton。然后在函数发布的时候,可以利用 Knative serving,进行部署和版本管理。也就是说 Knative 是一个平台的平台。基于 Knative,你可以去构建更多的 Serverless 平台或者 FaaS 平台。
- 之前大家对 Knative 比较诟病的地方,就是它比较重,因为它依赖于Istio。Knative 自身的安装,可能也就几十兆,但是装上 Istio 之后,会占用几 g 内存。然而目前它已经不再强依赖于 Istio 了,Istio 只是其中一个选项。你也可以使用别的组件,比如 ambassador、Gloo、Kong 去替代它做 API Gateway。这意味着 Knative 也在逐渐的轻量化。
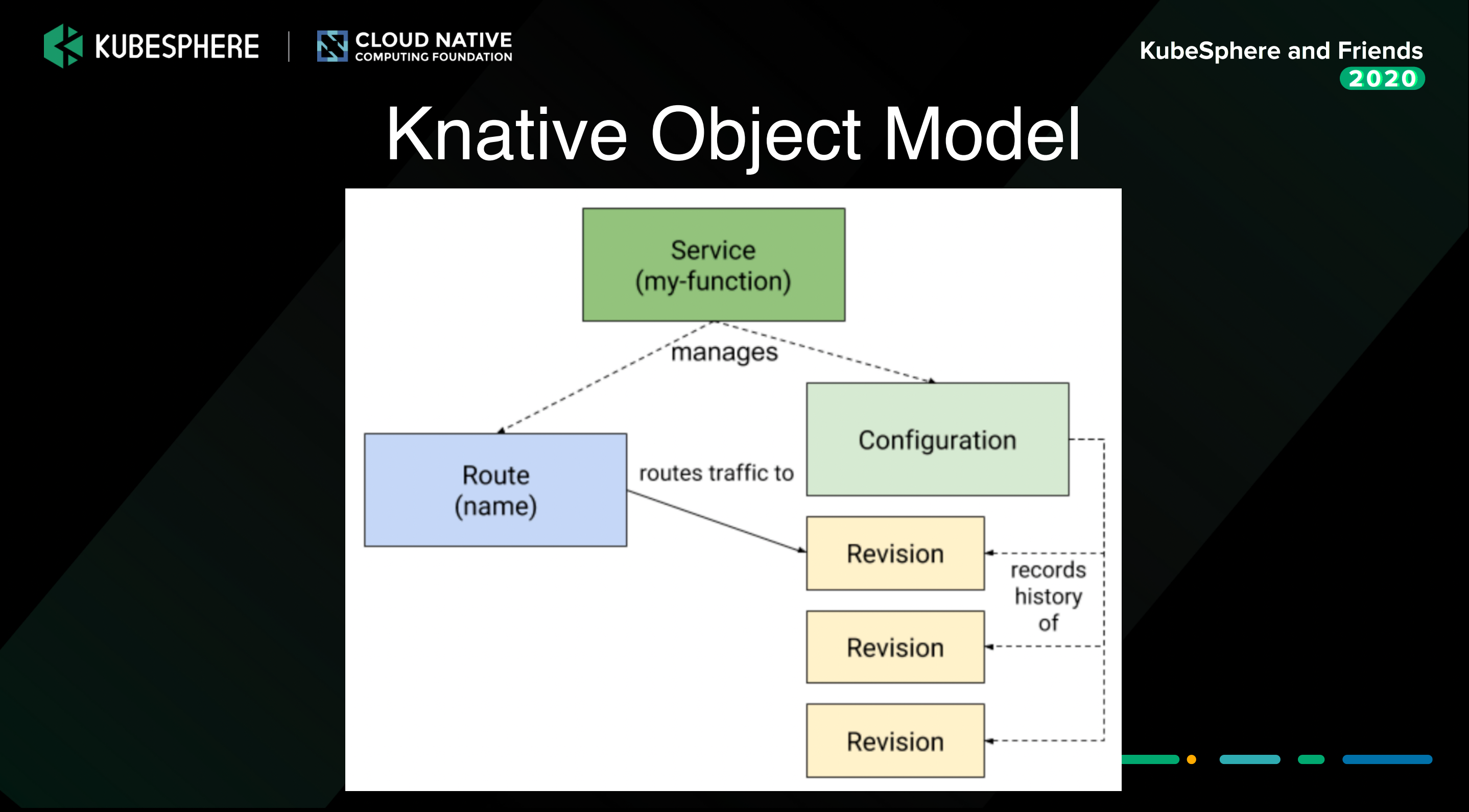
Serverless DevOps
函数要 build 成镜像会有一个 build 的过程,那么在 devops 里这个过程就是持续交付。然后把镜像部署到生产环境,在 devops 里面这个过程就是持续部署,所以 Serverless 和 DevOps 也有很多结合点。
Serverless CI
Serverless 的 CI 也是需要的,但是因为它是函数,不是一个完整的 source code,所以它有一些不一样的地方。但是肯定也需要代码的质量扫描、单元测试这样的工作。

Serverless CD
对于 Serverless CD,build 的过程也就是函数的创建过程,会自动的把这个函数打包成镜像,这是由 FaaS 平台去完成的工作。
如果要将函数镜像发布到生产环境,需要进行审核。

Serverless CI/CD 工具
build 的过程,我们可以依赖于 tekton 去管理流水线。但是从 kubernetes 1.20 开始,不再支持 docker 作为它默认的一个运行时了,也就是说以后 kubernetes 里可以不安装 docker daemon。

CNCF 官方的文档中,推荐了几个 build docker 镜像的工具,比如 Kaniko,img,buildah。他们各有各的优劣势,但是有一个共同点,就是不依赖于 docker daemon。你可以用 Kaniko 在 docker 里面 build 一个 docker 镜像,但是不需要连接 docker daemon。
另外一个比较新兴的工具是 Cloud Native Buildpacks,它更进一步,连 Dockerfile 都不需要了,根据源码就能检测出来,然后能够 build 出一个 docker 镜像。很多国外的公司,比如 Google、Pivotal,都在使用 Buildpacks。
Serverless/FaaS 痛点
目前有很多云厂商,而且几乎每个云厂商都有自己的函数平台。开源平台又有很多。所以大家会面临应该如何选择的问题,另外也会有厂商锁定的问题。
KubeSphere Serverless 路线图
我们做 Serverless 有一个想法,能不能做一个厂商中立的 FaaS 平台?它是一个平台的平台,你可以基于它去构建自己的 FaaS 平台。

通过 KubeSphere Serverless 平台,你可以在 kubernetes 里边去运行各个云厂商的云函数,运行开源 FaaS 平台的云函数。当然,运行云厂商的云函数有个前提,就是它的 runtime 必须是开源的。
KubeSphere Serverless 平台大概率也会开源,到时候希望社区的小伙伴能够积极的参与进来。
另外一个就是 Serverless 的应用,你可以把它想象成一个 deployment + service 的替代品。它有一个额外的能力,就是可以动态的扩展,然后它也能够 scale 到 0。简单来讲,你可以提供一个 docker 镜像,然后你就拥有了一个能够自动伸缩的 service。
多云及边缘可观察性
KubeSphere 在 3.0 版本中已经支持了多集群的管理,将会在 3.1 版本中支持边缘计算。所以这就产生了一个话题——多云及边缘计算的可观察性。
需求和挑战
- 多云及边缘集群的全局视图
很多用户使用 KubeSphere 管理多集群,希望能在一个统一的界面看到各个集群使用资源的情况。目前这个功能还在开发中。
也有社区用户反馈,KubeSphere 已经支持联邦的 federated 的这种调度,能不能在一个界面看到 federated 联邦的部署,各个集群里边,对运行的资源的占用情况,这也是一个需求。 - 跨集群监控指标
workspace 可能是跨了几个集群,那么能不能在一个界面里面看到 KubeSphere 在 workspace 中跨集群的资源的使用情况? - 多云及边缘集群的全局告警
因为边缘节点的资源是比较受限的,边缘集群的监控和告警怎么解决? - 网络状况各有不同
每个集群的特点都不一样。有的集群能够连接外网,也能够被外网连接。有的集群只能访问外网,不能够被 Host 集群主动连接。

架构
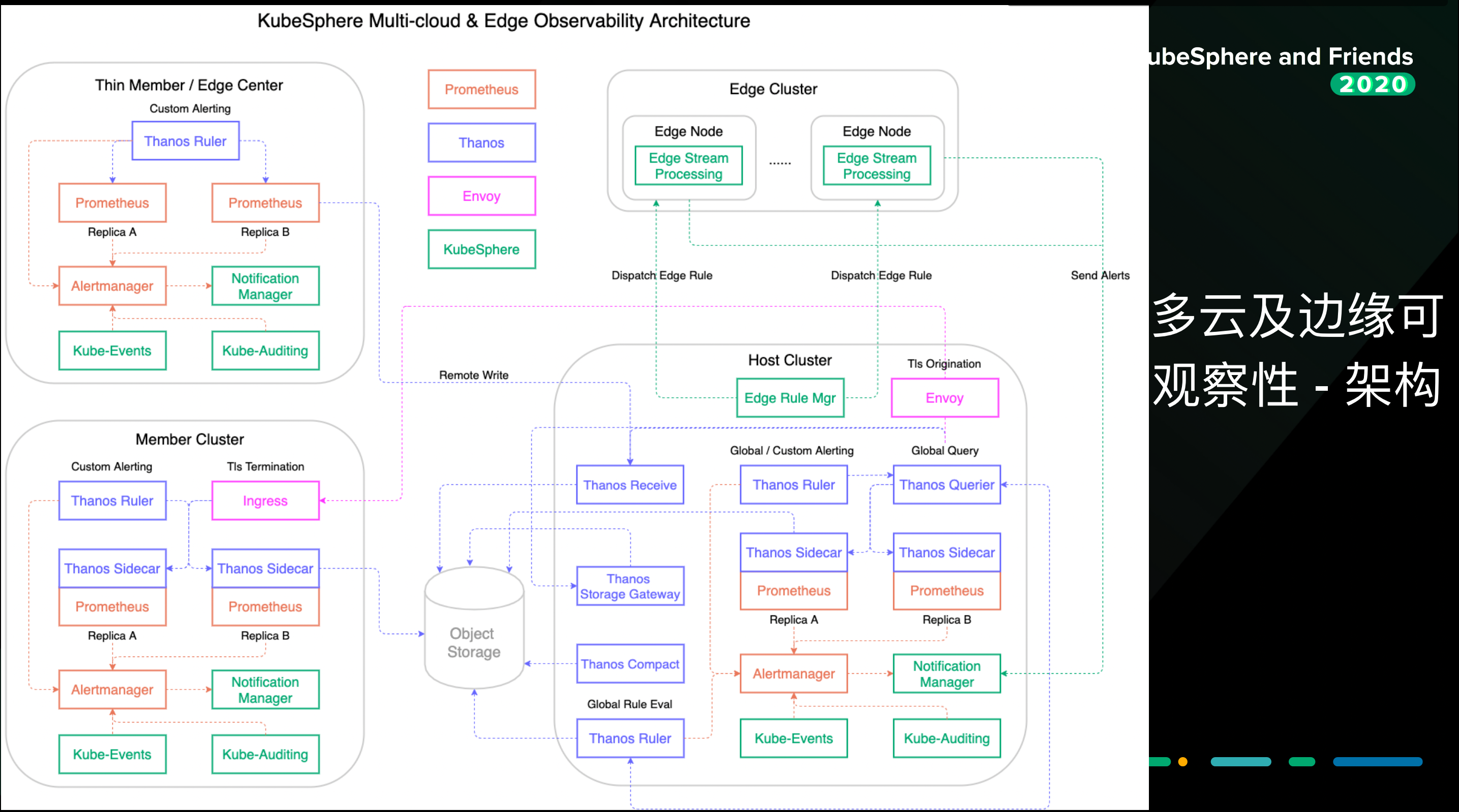
针对 Member 集群的连接方式,如果是像上图中左上角这样的集群,它只能连接外网,我们就可以用 prometheus 通过 remote write,把监控数据写到 Host 集群的存储上去。
对于上图中左下角的集群,可以双向访问,可以直接查询数据,然后到 Host 集群上做一个聚合,这样就能够把多集群监控的数据展现出来了。
有的用户尤其是企业用户,在单个集群上存储的数据可能不是很多,如果只想存一两年应该怎么办呢?
还有一个方案就是可以把它存储到对象存储中。Host 集群上也可以去查对象存储里时间比较久远的监控数据。
以上是监控的解决方案,那么告警是怎么解决的呢?
各个集群可以有自定义的告警,KubeSphere 3.1 会支持这个功能。对于 Host 集群,也可以做对于全局的监控指标的告警。KubeSphere 也有一些自己研发的组件,比如 Kube-Events、Kube-Auditing,这些组件也会发出一些告警,发到 Alertmanager 中,最后通过 Notification Manager 发到云端。
对于边缘集群,它的资源比较受限,它的配置通常是两核 4 g、一核 2 g,如果去使用 prometheus 往云端发送数据,资源占用会比较多。
对于边缘节点,它的带宽较小,如果源源不断的把监控数据传输到云端,会浪费带宽。
我们的想法是,可以利用一些边缘的流失处理组件,比如 EMQ 的 Kuiper 这样的组件,然后配合我们云端下发告警的规则,能够实时的把边缘的一些设备、节点的数据进行实时的过滤。当超过了阈值,就发到云端告警。这就是对边缘节点的支持。
关于 KubeSphere
KubeSphere (https://kubesphere.io)是在 Kubernetes 之上构建的开源容器混合云,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere 已被 Aqara 智能家居、本来生活、新浪、华夏银行、四川航空、国药集团、微众银行、紫金保险、中通、中国人保寿险、中国太平保险、中移金科、Radore、ZaloPay 等海内外数千家企业采用。KubeSphere 提供了开发者友好的向导式操作界面和丰富的企业级功能,包括多云与多集群管理、Kubernetes 资源管理、DevOps (CI/CD)、应用生命周期管理、微服务治理 (Service Mesh)、多租户管理、监控日志、告警通知、审计事件、存储与网络管理、GPU support 等功能,帮助企业快速构建一个强大和功能丰富的容器云平台。

登录后评论
立即登录 注册