
大家好!今天很高兴能有机会在这里跟各位分享灵雀云在云原生网络方面的实践和我们的思考。随着容器、Kubernetes、微服务等理念、技术的普及,云原生大幕开启。与此相应地,无论是平台的分布式化,还是业务的微服务化,都需要一个强大的网络来支撑虚拟节点和微服务之间的通信。
首先来看CNCF下面的这张图,CNCF对于网络架构的定义,可以看到Runtime这一层又可以分为资源管理、云原生网络、云原生存储。
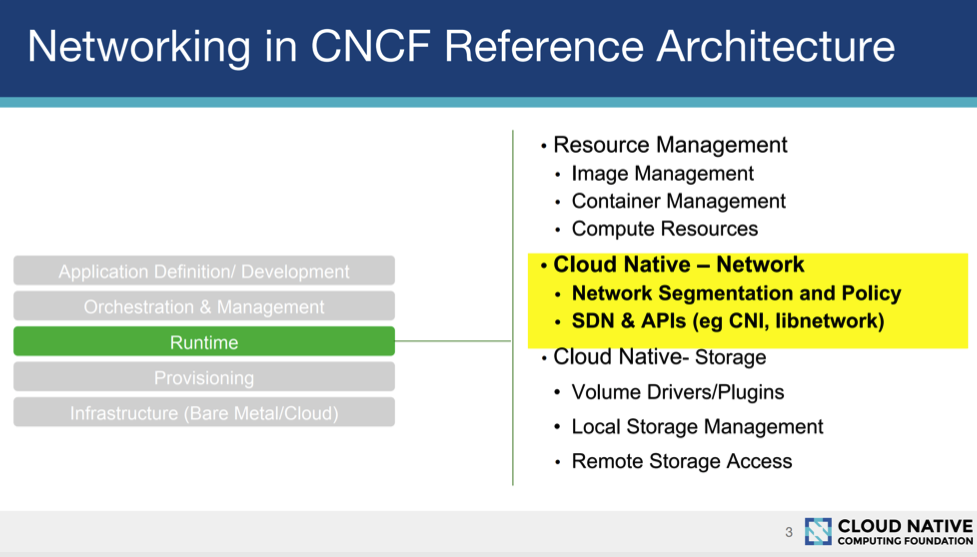
1什么是云原生网络

云原生网络和传统网络的区别,可以从容器网络和物理网络之间的对比来看。一个直观的感受就是,容器网络的变化频率非常高。对物理网络来说,当机器上架,交换机路由器接好,所有物理机接到交换机之后,整体的网络拓扑就不会变了,后面的增删改查不会很频繁。
对于容器网络来说,在整个集群node、pod、工作负载、节点的数量变化都很频繁,每个容器的生命周期很短暂,导致网络的整体变化比传统网络高很多。同时,网络策略的变化也很频繁,对网络自动化有很高的要求。想象一下,生成容器如果需要人工进行网络配置,就无法发挥出云原生的价值。
此外,容器网络对网络自愈能力也有很高的要求,在如此变化频繁的情况下,单一硬件很难解决,会有很多软件,包括软件的可靠性、应用可靠性都会对网络产生干扰。如果网络节点的上线、下线,任何容器的启停、节点的故障调整都需要人去参与、恢复,对整体网络产生很大的影响,对网络自愈能力要求特别高。
但是,容器网络并不完全等于云原生网络。我们可以想象云原生最初的思路,它是为了跨平台的,云原生的应用不应该依赖于底层的基础设施;网络最好是跨各种环境的,公有云、私有云、物理机,可以随时在不同的云上进行迁移。如果你的网络是跟底层的某些具体实现绑定的,比如某个公有云或私有云,在跨平台方面的能力就会弱很多。在我来看,一个云原生的网络,是跟平台无关的,可以方便地跨云进行迁移。
容器网络的基本要求,首先每个pod需要单独IP,其次所有pod之间的网络三层直接可达,不经过任何NAT设备。也就是说,从这个pod直接访问另一pod看到的目标IP应该是同一个IP。第三,网络还需要提供一系列的网络应用,比如Service、DNS、NetworkPolicy、Ingress等。这些网络应用加上之前的容器网络,以及跨平台的特性,才构成了完整的云原生网络。
2云原生网络的开源实现

关于开源实现,CNCF很早就定义了一个标准——CNI(container network interface),它实际是一个可插拔式的容器网络协议,Flannel、Clillium、Calico等都是基于CNI协议来做的。它规定了上层调度系统和底层容器网络之间的一个交互协议,交互协议定义了两个接口:ADD和DEL。
我们从控制平面和数据平面两个角度对网络插件实现进行分类。控制平面是指网络之间是如何相互发现的,容器网络相当于在物理机器的网络上面又加了一层网络,那么网络之间是如何相互学习了解的?一个节点的容器是如何发现另一节点的容器?其中的机制是怎样的?
这种实现机制大致可以分为四类:一种是所有控制信息用分布式kv进行存储,典型如Flannel、Cillium,把所有的控制信息存到etcd,然后下发到每个节点。灵雀云开源的Kube-OVN是把所有的控制信息存到OVS DB,也是一个raft协议的分布式存储。
第二种是不通过物理层面的存储,直接通过现有网络层面的路由器或者交换机上的自我发现能力,比如Calico, Kube-Router通过路由协议,有一个协议的Agent,把路由信息发布到外部路由器和交换机,外部硬件的信息就可以通过路由协议把整个控制平台的信息进行转发。
第三种是用底层物理设备,物理机的控制平面就是交换机,相当于每个机器把网络接到交换机上之后,交换机就学到了如何进行控制平面的转发。如果容器能够直接接入底层物理设备的话,可以试试这种做法,比较典型的是Macvlan,IPvlan。
还有一种比较少见但挺有意思的实现方式,Gossip协议Weave,也叫八卦协议或者流行病协议。就是一个人告诉另一个人,另外一个人再去不断告诉其他人。
从数据平面角度来看,主要分为两种:一种封装模式,比如Flannel Vxlan, Kube-OVN Geneve, CalicoIPIP, Cillium Vxlan,以及跟封装模式相对的Underlay 模式: Flannel hostGateway, Kube-OVNVlan, Calico BGP 。
3云原生网络面临的挑战

云原生网络在实际落地时,也面临着一些挑战,主要分为四个方面。
第一,功能层面来看,云原生网络功能方面的能力比较少,落地时会碰到很多客户要做的新功能。
比如固定IP,当用户提出要求,只能要么网络这边改,要么应用方面改。多租户的能力,有的用户有很大的集群,有很多项目组,希望有租户管理的功能。租户不仅指计算资源的隔离,也包括网络资源的隔离。比如地址空间相对独立,网络控制独立,一些银行或其他金融机构希望流量经过交换机时是加密的,还有一些客户并非所有业务都上了K8s,这些应用需要相互之间进行交互,集群内外的网络互通也是一个问题。
第二,监控和故障排查,这是比功能层面更让人头疼的问题,上了容器网络后会发现大部分时间都是在运维这个网络,检查各种各样的网络问题。这其中最典型的可能就是网络不通。而且,如果涉及开发环境,微服务也可能一块上了,就会导致网络结构和拓扑变得特别复杂。
还有一个网络容易出现的问题–与已有技术栈的兼容。有些客户还有传统的网络监控方式,传统的网络监控已经很成熟了,但在容器网络这块是空缺的,会导致整体监控是缺失的,整体的排查经验也是缺失的,网络一旦出现问题,就会是很难解决的问题。
第三,安全性。传统方式可能采用基于黑白名单,或者基于IP划分的网络策略,但是容器在K8s上面,如果是用Networkpolicy,很多方式和传统是不一致的,会带来很多兼容性的问题。传统的流量审计流量回放会收集经过集群的所有流量,这种形式如果没有好的底层基础设施,很多安全机制相当于被架空了,这些都是落地时会碰到的问题。
第四,性能,提到性能大多数人会关注数据平面的性能。但在我们来看,现阶段比较大的问题是,用户的网络究竟能撑多大规模的集群,什么时候控制平面的性能会出现明显的衰减,这是在选型时需着重考虑的。数据平面的性能到实际应用时,很多情况下没有那么突出。它需要根据应用所需要的性能进行评估,很多情况下最大的极端的性能反而不是最需要的性能。

登录后评论
立即登录 注册