
一、持续部署
1.现状
由于没有建立标准的持续部署流程,导致了版本管理混乱,制品管理混乱,上线持续时间长,上线测试覆盖不全面,业务流量上升后故障较多,排查复杂。运维、测试、开发人员每次版本迭代的时候,都要可能需要经历一次通宵的历练,并且这种在上线的第二天依然会出现很多线上故障。
2. 痛点
- 自动化发布体系覆盖率低。
- 无标准化发布的流程。
a.只注重敏捷、忽视质量问题;
b.变更频繁导致故障率增加;
c.开发语言种类多,发布制品管理混乱,发布方式复杂;
- 安全问题容易被忽视。
二、工具介绍
1.Saltstack
基于ZeroMQ的开源的配置管理工具。笔者之所以选型使用saltstack,而放弃了ansible,原因是由于ansible基于ssh通信,在管控主机超过五百台之后,基于消息队列的命令下发方式无论在稳定性还是速度上都优于ssh协议。笔直另外选在saltstack的原因是,在服务的开发团队中存在着不同的技术栈并行的状况,尤其是java和.net并存的情况下,saltstack对于windows的支持明显要优于ansible。更容易作为多平台的底层发布工具。
而基于SaltStack打造自动化部署平台主要是用grains、pillar、state三个特性,grains用于获取默认环境配置信息、pillar用于定义环境信息、state用于编排发布文件进行发布。
2. Artifactory
全语言制品仓库管理软件,有开源版及企业版两种。开源版支持maven制品管理;企业版支持全语言制品管理,支持元数据管理功能,提供高可用部署方式、匹配nvd及vulnDB数据库,提供漏洞扫描能力。
三、针对上述痛点解决方案
1. 自动化发布覆盖率低
通过搭建兼容多平台部署统一发布工具,替换掉传统的shell脚本拷贝的方式实现发布工具标准化。通过SaltStack的state特性,实现跨平台的基础服务发布、服务启停、文件发布、配置发布、远程主机管理等90%以上手动操作。使用SaltStack的state编排文件,执行远程命令,通过Artifactory获取制品及配置,将需要的版本发布到线上。
主要方案在部署平台中,通过json格式描述发布流程,通过yaml.dump(sls_json)将json文件转换成yaml各位的配置文件,最终通过平台调度saltstack执行编排好的任务。
转换后的yaml文件格式如下:
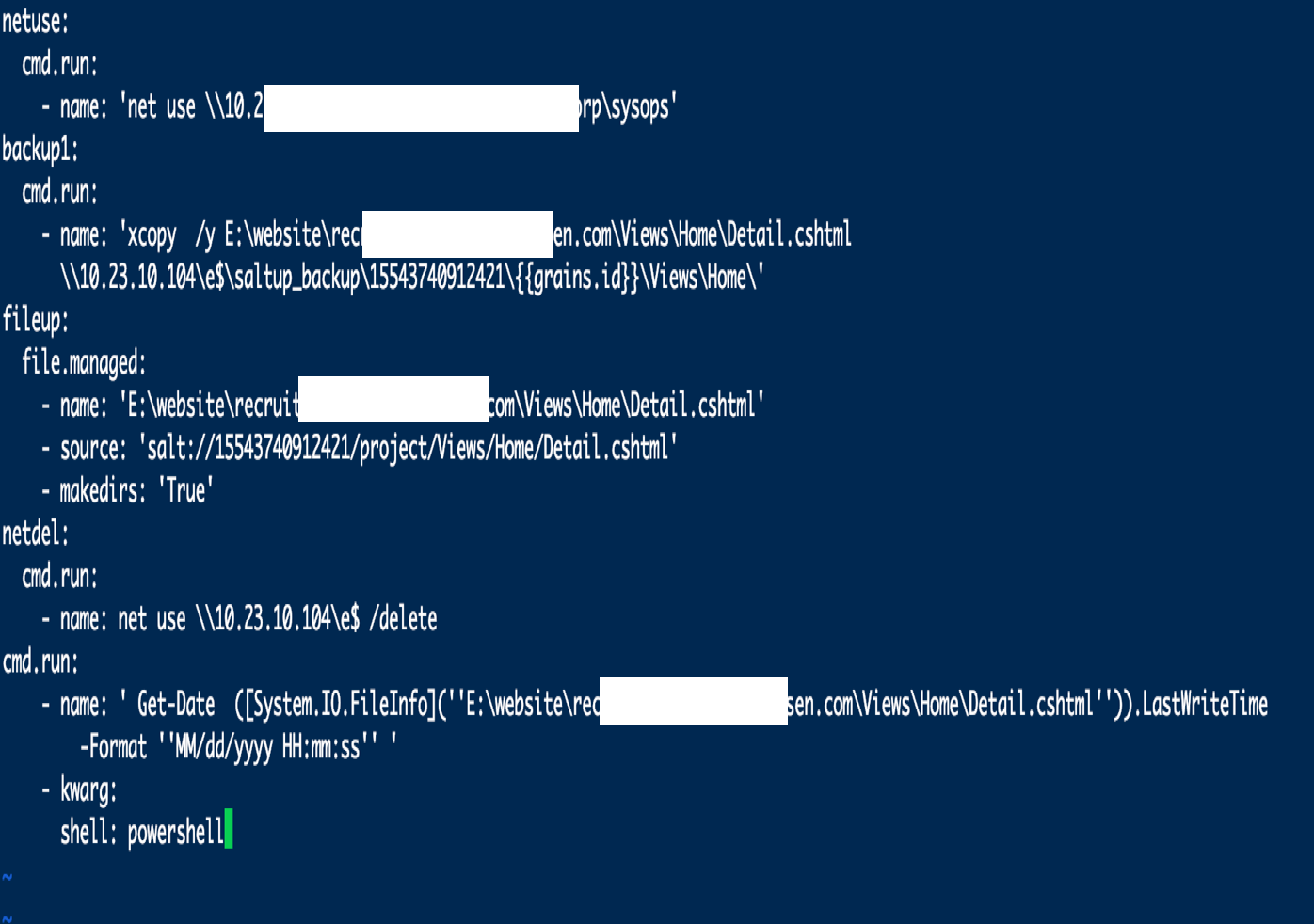
2. 标准化发布流程
- 备份
发布任务编排的第一步就是备份,备份需采用本地备份加异地备份两种机制,本地备份用于快速回滚,异地备份用于环境重建。
- 切流量(蓝绿部署)
对于服务,尤其是有状态的服务,需要在注册中心中进行节点下线,确保本节点所有处理结束后,再进行部署。
对于页面,需要在负载均衡上将节点注销,对没有流量的web页面进行部署操作。
- 部署
通过saltstack的sls特性,编排部署文件,对多个部署任务进行统一进行发布。
部署时我们希望可以在部署页面查看到类似下述信息,如:部署包对应的需求id、部署包对应代码的提交信息、部署包自动化测试的通过率、部署包的代码扫描结果、部署包的安全扫描结果、部署包人工测试的结果等等。运维人员需要在发布过程中看到此类信息,来明确包是否通过了所有质量关卡、具备了上线条件,从而判断此次上线是否可以继续进行。这里我们使用了Artifactory的元数据功能,用于记录软件包诞生的整个生命周期的信息,并通过api方式对接到发布平台。给运维人员一个完整的包的信息记录。
- 自动化测试
此处自动化测试主要可以理解为检测服务端口通信是否正常、回归线上功能是否可用、缺陷是否被修复、新特性是否部署完成等。同时此处需要预热服务及站点,通过自动化的测试打通业务流程。
- 流量回归(金丝雀)
部分真实流量切换到已经部署完成的应用上,通过全链路日志追踪或监控指标反馈来初步判断新上线应用是否健康运行,并将此结果作为后续发布或回退的依据。
- 部署补全(滚动发布)
在使用低谷时间将流量牵引到已部署完成的应用上,同时将其余应用升级。
- 变更管理通告。
上线成功后需要及时的通知大家线上版本已变更,产品经理需要及时更新文档,运营人员需要及时对用户进行告知。
- 回滚
任何发布都需要考虑回滚方案,对于单个应用需要回滚到一个指定版本;对于多个应用,需要明确一个回滚集,通过发布时的编排任务指定回滚的编排任务。对于数据库等更新,如果回顾复杂,则需要在升级方案制定前就明确回滚方案或在业务中做好版本兼容。
3. 建立统一的制品管理仓库
大多互联网公司已经对源码仓库有了统一的管理,但对于制品依然处于一个原始的管理状况,比如使用ftp以及每种语言开源的管理仓库。这里遇到的问题是,运维人员需要投入大量的精力维护不同的包管理平台(如ftp、maven、nuget、pypi、docker镜像中心等)。浪费掉大量运维团队的人力成本之外,也极度复杂了发布流程。发布人员需要在不同的平台获取上线的包,导致发布流程混乱,发布平台配置混乱。并且大多数开源组件均不提供高可用能力,一旦硬件或软件出现故障,都将严重的影响发布效率。
为了解决这种问题,我们采用Artifactory来管理所有语言的制品仓库。与统一gitlab一个道理,我们把整个公司的制品统一管理,成为对接发布平台的唯一包来源,从而规范了发布流程。

4. 漏洞扫描
目前安全团队扫描大多是在服务部署上线后进行,这种情况下和容易造成由于版本有安全漏洞导致的整个迭代废弃,所有包需要重新编译,重新经过测试流程以及上线过程,浪费掉大量的时间,降低迭代的速度。
解决办法是将漏洞扫描步骤前置,在制品包构造编译的时候,乃至开发人员code代码的时候就对外部引用、内部公共库进行漏洞扫描,一旦匹配到高危漏洞,直接把提交或构建终端。如果一定要继续构建,那么可以将扫描结果记录到制品的元数据中,供测试人员,运维人员查看。目前JFrog Xray等安全扫描故居提供此类能力。也可以使用开源软件,如cvechecker,在编译流水线中对包进行扫描,防止由于安全漏洞造成的整个迭代失败。
四、后期完善
1. 设置度量体系,提升发布质量
敏捷开发模式下,开发人员和测试人员往往是汇报给同一位管理人员,出于快速迭代线上功能,往往有些团队会投机取巧、将没有测试完整的包发布到线上进行测试。该种问题的直接表现是,为了解决一个bug,可能多时间多次对同一个应用或页面进行hotfix或发布新版本。这样做是十分危险的,置线上业务稳定于不顾。为了避免此类情况发生、我们可以采用一些措施或规范来约束开发团队。例如:
上线后触发新bug数量
短时间内对相同问题发布次数
由于上线原因造成的P5-P0级别故障的数量
上线后故障恢复时间
上线后回滚的次数
非上线时间内紧急上线数量
…
通过收集上述数据,每月或固定周期对各个团队进行考核。并对发布状态复盘,通过制定规约,评估团队的交付质量及交付能力,挖掘团队中的发布问题及痛点,从而提高发布质量,减少线上故障率。
2. 制定度量标准,进行发布质量考核
每团队初始分为100分,每月重置,每月用此分作为迭代质量的一项标准,分数不挂钩kpi考核,只用来驱动开发团队去提高效率。
评判为两个维度:项目组发布稳定性得分、服务(站点、app、微服务等)发布质量得分
- 非上线时间发布hotfix(项目组减1分,服务减1分)
- 代码类hotfix,同一项目每天发布超过3次(项目组减1分,服务减2分)
- hotfix发布失败或回滚(项目组减2分,服务减2分),发布是否失败,由运维团队认定。
- 数据库等脚本异常或执行失败(项目组减1分)
- 每月服务发布数量(取top5,服务按排序减5到1分)
- 由于hotfix原因造成P2级以上的线上事故,项目组减5分,相关服务减5分
- 项目组本月hotfix量如超过前3月平均值的30%,减10分
3. 变更管理
在google的SRE体系中,变更管理是DevOps体系中最为重要的一个部分。根据以往的经验,90%的线上故障是由于线上变更导致的,该变更原因包括软件、硬件、环境等所有因素。建设变更管理体系目的就是为了快速定位线上问题,止损由于变更造成的线上故障,及时通知相关人员做好故障预防工作。所以,变更管理体系也是需要我们重点去建设以及完善的。
落地方式包括但不限于下述几点:
- 运维人员、对应的开发及测试人员、产品经理等微信通知
- 大屏滚动播放最近的变更记录
- 变更记录同步到监控系统
五、总结
总结为一句话,虽然在敏捷开发模式下、产品、开发、测试团队都在小步快跑,但运维必须有自己的原则,一定要对整个上线流程制定规范、对DevOps工具链进行统一管理。
线上稳定大于一切!

登录后评论
立即登录 注册