
本章将从kubernetes源码层次,对Job内幕原理进行大揭秘。
在开始本篇内容之前,您需要具备如下知识:
golang命令行库:Cobra
推荐chenjian和Jsharkc两篇快速入门教程。
k8s实操教程
最好的方法:官网,如果感觉自己英文不够好,也可以查阅K8s meetup中文本地化翻译文档。
登堂入室
下面我们将进入K8s大厦中的一层:kube-controller-manager。本着言简意赅的原则,我把如下关键代码贴出来,将kube-controller-manager的逻辑按照顺序走到Job controller这个房间。
cmd/kube-controller-manager/controller-manager.go:
func main() {
command := app.NewControllerManagerCommand()
command.Execute()
}
cmd/kube-controller-manager/app/controllermanager.go:
func NewControllerManagerCommand() *cobra.Command{
s, err := options.NewKubeControllerManagerOptions()
cmd := &cobra.Command{
Use: "kube-controller-manager",
Run: func() {
c, err := s.Config(KnownControllers(), ControllersDisabledByDefault.List())
Run(c.Complete(), wait.NeverStop)
}
}
return cmd
}
func KnownControllers() []string {
ret := sets.StringKeySet(NewControllerInitializers(IncludeCloudLoops))
ret.Insert(
saTokenControllerName,
)
return ret.List()
}
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers["cronjob"] = startCronJobController
controllers["job"] = startJobController
controllers["deployment"] = startDeploymentController
...
}
cmd/kube-controller-manager/app/batch.go:
func startJobController(ctx ControllerContext) (http.Handler, bool, error) {
go job.NewJobController(
ctx.InformerFactory.Core().V1().Pods(),
ctx.InformerFactory.Batch().V1().Jobs(),
ctx.ClientBuilder.ClientOrDie("job-controller"),
).Run(int(ctx.ComponentConfig.JobController.ConcurrentJobSyncs), ctx.Stop)
}
通过上面几步层层的问询,我们终于要到了Job的房间号:
pkg/controller/job/job_controller.go:
func NewJobController() *JobController{...}
func (jm *JobController) Run() {...}
玄机就在job_controller.go这个房间里,一场揭秘之旅就此开始!
Job大揭秘
kube-Controller内部实现逻辑
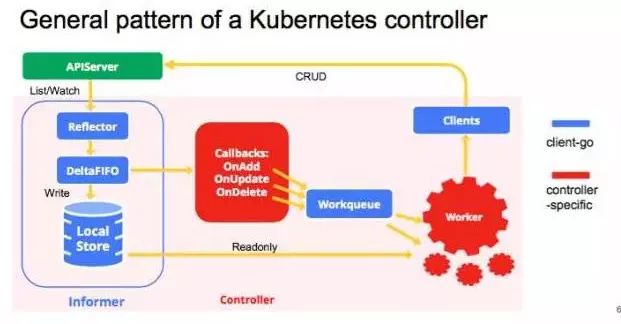
主要使用到 Informer和workqueue两个核心组件。Controller可以有一个或多个informer来跟踪某一个resource。Informter跟API server保持通讯获取资源的最新状态并更新到本地的cache中,一旦跟踪的资源有变化,informer就会调用callback。把关心的变更的Object放到workqueue里面。然后woker执行真正的业务逻辑,计算和比较worker queue里items的当前状态和期望状态的差别,然后通过client-go向API server发送请求,直到驱动这个集群向用户要求的状态演化。
Informer和workqueue两个组件的原理将在另外的章节进行揭秘,接下来将以贴出关键部分源码的方式针对worker业务逻辑进行分析。
JobController结构
type JobController struct {
//访问kube-apiserver的client,获取pod,job信息
kubeClient clientset.Interface
//pod controller,used for creat and delete pod
podControl controller.PodControlInterface
//To allow injection of updateJobStatus for testing.
undateHandler func(job *batch.Job) error {}
//Job Controller核心接口,用于sync job
syncHandler func(jobKey string) (bool, error){}
//podStoreSynced returns true if the pod store has been synced at least once.
podStoreSynced cache.InformerSynced
//jobStoreSynced returns true if the job store has been synced at least once.
jobStoreSynced cache.InformerSynced
//A TTLCache of pod creates/deletes each rc expects to see
expectations controller.ControllerExpectationsInterface
//A store of jobs
//jobLister 用于获取job元数据及根据pod的labels来匹配jobs
//该controller 会使用到的接口如下:
//1. GetPodJobs(): 用于根据pod反推jobs
//2. Get(): 根据namespace & name 获取job 元数据
jobLister batchv1listers.JobLister
//A store of pods, populated by the podController
//podStore 提供了接口用于获取指定job下管理的所有pods
podStore corelisters.PodLister
//Jobs that need to be updated
//job controller通过kubeClient watch jobs & pods的数据变更,
//比如add、delete、update,来操作该queue。
//并启动相应的worker,调用syncJob处理该queue中的jobs。
queue workqueue.RateLimitingInterface
//jobs的相关events,通过该recorder进行广播
recorder record.EventRecorder
}
NewJobController( )
func NewJobController(podInformer coreinformers.PodInformer, jobInformer batchinformers.JobInformer, kubeClient clientset.Interface) *JobController {
jm := &JobController{
// 连接kube-apiserver的client
kubeClient: kubeClient,
// podControl,用于manageJob()中创建和删除pod
podControl: controller.RealPodControl{
KubeClient: kubeClient,
Recorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "job-controller"}),
},
// 维护期望值
expectations: controller.NewControllerExpectations(),
// jobs queue存储要变更的object, 后面会创建对应数量的workers 从该queue 中处理各个jobs。
queue: workqueue.NewNamedRateLimitingQueue(workqueue.NewItemExponentialFailureRateLimiter(DefaultJobBackOff, MaxJobBackOff), "job"),
}
// 注册 jobInformer、podInformer 的Add、Update、Delete 函数
// 该controller 获取到job 的Add、Update、Delete事件之后,会调用对应的function
// 这些function 的核心还是去操作了上面的queue,让syncJob 处理queue 中的jobs
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.enqueueController(obj, true)
},
UpdateFunc: jm.updateJob,
DeleteFunc: func(obj interface{}) {
jm.enqueueController(obj, true)
},
})
jm.jobLister = jobInformer.Lister()
jm.jobStoreSynced = jobInformer.Informer().HasSynced
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jm.addPod,
UpdateFunc: jm.updatePod,
DeleteFunc: jm.deletePod,
})
jm.podStore = podInformer.Lister()
jm.podStoreSynced = podInformer.Informer().HasSynced
jm.updateHandler = jm.updateJobStatus
jm.syncHandler = jm.syncJob
return jm
Run( )
func (jm *JobController) Run(workers int, stopCh <-chan struct{}) {
// 每次启动都会先等待Job & Pod cache 是否有同步过,即指queue是否已经同步过数据,
// 因为每个worker干的活都是从queue中获取,所以只有queue有数据才应该继续往下创建worker。
if !controller.WaitForCacheSync("job", stopCh, jm.podStoreSynced, jm.jobStoreSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(jm.worker, time.Second, stopCh)
}
worker( )
func (jm *JobController) worker() {
for jm.processNextWorkItem() {
}
}
func (jm *JobController) processNextWorkItem() bool {
// 从queque 中获取job key
// key 构成: namespace + "/" + name
key, quit := jm.queue.Get()
// 调用初始化时注册的 syncJob()
// 如果执行成功,且forget = true, 则从queue 中删除该 key。
forget, err := jm.syncHandler(key.(string))
if err == nil {
if forget {
jm.queue.Forget(key)
}
return true
}
// 如果syncJob() 出错,则把该job key 继续丢回queue 中, 等待下次sync。
jm.queue.AddRateLimited(key)
return true
}
syncJob( )
func (jm *JobController) syncJob(key string) (bool, error) {
// 把key 拆分成job namespace & name
ns, name, err := cache.SplitMetaNamespaceKey(key)
// 获取job 信息
// 如果没有找到该job的话,表示已经被删除,并从ControllerExpectations中删除该key
sharedJob, err := jm.jobLister.Jobs(ns).Get(name)
if err != nil {
if errors.IsNotFound(err) {
jm.expectations.DeleteExpectations(key)
return true, nil
}
return false, err
}
job := *sharedJob
// 根据job.Status.Conditions是否处于“JobComplete” or "JobFailed", 来判断该job 是否已经完成。
// 如果已经完成的话,直接return
if IsJobFinished(&job) {
return true, nil
}
// 根据该 job key 失败的次数来计算该job 已经重试的次数。
// job 默认会有6次的重试机会
previousRetry := jm.queue.NumRequeues(key)
// 判断该key 是否需要调用manageJob()进行sync,条件如下:
// 1. 该key 在ControllerExpectations中的adds和dels 都 <= 0
// 2. 该key 在ControllerExpectations中已经超过5min没有更新了
// 3. 该key 在ControllerExpectations中没有查到
// 4. 调用GetExpectations()接口失败
jobNeedsSync := jm.expectations.SatisfiedExpectations(key)
// 获取该job管理的所有pods
pods, err := jm.getPodsForJob(&job)
// 获取处于active 的pods
activePods := controller.FilterActivePods(pods)
// 获取active & succeeded & failed pods数量
active := int32(len(activePods))
succeeded, failed := getStatus(pods)
conditions := len(job.Status.Conditions)
// job first start
// 看下该job是否是第一次启动,是的话,设置StartTime;
// 并判断是否设置了job.Spec.ActiveDeadlineSeconds, 如果设置了的话,在ActiveDeadlineSeconds秒后,在将该key 丢入queue
if job.Status.StartTime == nil {
now := metav1.Now()
job.Status.StartTime = &now
if job.Spec.ActiveDeadlineSeconds != nil {
jm.queue.AddAfter(key, time.Duration(*job.Spec.ActiveDeadlineSeconds)*time.Second)
}
}
// 确认该job是否有新的pod failed
jobHaveNewFailure := failed > job.Status.Failed
// 确认重试次数是否有超出预期值
exceedsBackoffLimit := jobHaveNewFailure && (active != *job.Spec.Parallelism) &&
(int32(previousRetry)+1 > *job.Spec.BackoffLimit)
// 如果job重试的次数超过了job.Spec.BackoffLimit(默认是6次),则标记该job为failed并指明原因;
// 计算job重试的次数,还跟job中的pod template设置的重启策略有关,如果设置成“RestartPolicyOnFailure”,
// job重试的次数 = 所有pods InitContainerStatuses 和 ContainerStatuses 的RestartCount 之和,
// 也需要判断这个重试次数是否超过 BackoffLimit;
if exceedsBackoffLimit || pastBackoffLimitOnFailure(&job, pods) {
// check if the number of pod restart exceeds backoff (for restart OnFailure only)
// OR if the number of failed jobs increased since the last syncJob
jobFailed = true
failureReason = "BackoffLimitExceeded"
failureMessage = "Job has reached the specified backoff limit"
// 如果job 运行的时间超过了ActiveDeadlineSeconds,则标记该job为failed并指明原因
} else if pastActiveDeadline(&job) {
jobFailed = true
failureReason = "DeadlineExceeded"
failureMessage = "Job was active longer than specified deadline"
}
// 如果job failed,则并发等待所有active pods删除结束;
// 修改job.Status.Conditions, 并且根据之前记录的失败信息发送event
if jobFailed {
errCh := make(chan error, active)
jm.deleteJobPods(&job, activePods, errCh)
select {
case manageJobErr = <-errCh:
if manageJobErr != nil {
break
}
default:
}
// update status values accordingly
failed += active
active = 0
job.Status.Conditions = append(job.Status.Conditions, newCondition(batch.JobFailed, failureReason, failureMessage))
jm.recorder.Event(&job, v1.EventTypeWarning, failureReason, failureMessage)
} else {
// 根据之前判断的job是否需要sync,且该job 还未被删除,则调用mangeJob()。
// manageJob() 后面单独解析
if jobNeedsSync && job.DeletionTimestamp == nil {
active, manageJobErr = jm.manageJob(activePods, succeeded, &job)
}
completions := succeeded
complete := false
// job.Spec.Completions 表示该job只有成功创建这些数量的pods,才算完成。
// 如果该值没有设置,表示只要其中有一个pod 成功过,该job 就算完成了,
// 但是需要注意,如果当前还有正在运行的pods,则需要等待这些pods都退出,才能标记该job完成任务了。
if job.Spec.Completions == nil {
if succeeded > 0 && active == 0 {
complete = true
}
// 如果设置了Completions值,只要该job下成功创建的pods数量 >= Completions,该job就成功结束了。
// 还需要发送一些异常events, 比如已经达到要求的成功创建的数量后,还有处于active的pods;
// 或者成功的次数 > 指定的次数,这些应该都是预期之外的事件。
} else {
if completions >= *job.Spec.Completions {
complete = true
if active > 0 {
jm.recorder.Event(&job, v1.EventTypeWarning, "TooManyActivePods", "Too many active pods running after completion count reached")
}
if completions > *job.Spec.Completions {
jm.recorder.Event(&job, v1.EventTypeWarning, "TooManySucceededPods", "Too many succeeded pods running after completion count reached")
}
}
}
// 如果job成功结束,则更新job.Status.Conditions && job.Status.CompletionTime
if complete {
job.Status.Conditions = append(job.Status.Conditions, newCondition(batch.JobComplete, "", ""))
now := metav1.Now()
job.Status.CompletionTime = &now
}
}
forget := false
// 如果这次有成功的pod 产生,则forget 该次job key
if job.Status.Succeeded < succeeded {
forget = true
}
// // 更新job.Status
if job.Status.Active != active || job.Status.Succeeded != succeeded || job.Status.Failed != failed || len(job.Status.Conditions) != conditions {
job.Status.Active = active
job.Status.Succeeded = succeeded
job.Status.Failed = failed
// 更新job失败的话,将该job key继续丢入queue中。
if err := jm.updateHandler(&job); err != nil {
return forget, err
}
// 如果这次job 有新的pod failed,且该job还未完成,则继续把该job key丢入queue中
if jobHaveNewFailure && !IsJobFinished(&job) {
// returning an error will re-enqueue Job after the backoff period
return forget, fmt.Errorf("failed pod(s) detected for job key %q", key)
}
// 否则forget job
forget = true
}
return forget, manageJobErr
}
manageJob( )
在syncJob()中有个关键函数 manageJob(),它主要做的事情就是根据 job 配置的并发数来确认当前处于 active 的 pods 数量是否合理,如果不合理的话则进行调整。
具体实现如下:
func (jm *JobController) manageJob(activePods []*v1.Pod, succeeded int32, job *batch.Job) (int32, error) {
var activeLock sync.Mutex
active := int32(len(activePods))
parallelism := *job.Spec.Parallelism
// 获取job key, 根据 namespace + "/" + name进行拼接。
jobKey, err := controller.KeyFunc(job)
var errCh chan error
// 如果处于active pods 大于job设置的并发数,则并发删除超出部分的active pods。
// 需要注意的是,需要删除的active pods是有一定的优先级的:
// not-ready < ready;unscheduled < scheduled;pending < running。
// 先基于上面的优先级对activePods 进行排序,然后再从头执行删除操作。
// 如果删除pods失败,则需要回滚之前设置的ControllerExpectations 和 active 值。
if active > parallelism {
diff := active - parallelism
errCh = make(chan error, diff)
jm.expectations.ExpectDeletions(jobKey, int(diff))
sort.Sort(controller.ActivePods(activePods))
active -= diff
wait := sync.WaitGroup{}
wait.Add(int(diff))
for i := int32(0); i < diff; i++ {
go func(ix int32) {
defer wait.Done()
if err := jm.podControl.DeletePod(job.Namespace, activePods[ix].Name, job); err != nil {
defer utilruntime.HandleError(err)
jm.expectations.DeletionObserved(jobKey)
activeLock.Lock()
active++
activeLock.Unlock()
errCh <- err
}
}(i)
}
wait.Wait()
// 如果active pods少于设置的并发值,则先计算diff值,具体的计算跟Completions和Parallelism的配置有关。
// 1.job.Spec.Completions == nil && succeeded pods > 0, 则diff = 0;
// 2.job.Spec.Completions == nil && succeeded pods = 0,则diff = Parallelism;
// 3.job.Spec.Completions != nil 则diff等于(job.Spec.Completions - succeeded - active)和parallelism中的最小值(非负值);
// 计算好diff值即知道了还需要创建多少pods,由于等待创建的pods数量可能会非常庞大,所以这里有个分批创建的逻辑:
// 第一批创建1个,第二批创建2个,后续按2的倍数继续往下分批创建,但是每次创建的数量都不会大于diff值(diff值每次都会减掉对应的分批数量)。
// 如果创建pod超时,则直接return;
// 如果创建pod失败,则回滚ControllerExpectations的adds 和 active 值,并不在执行后续未执行的 pods
} else if active < parallelism {
wantActive := int32(0)
if job.Spec.Completions == nil {
if succeeded > 0 {
wantActive = active
} else {
wantActive = parallelism
}
} else {
wantActive = *job.Spec.Completions - succeeded
if wantActive > parallelism {
wantActive = parallelism
}
}
diff := wantActive - active
if diff < 0 {
utilruntime.HandleError(fmt.Errorf("More active than wanted: job %q, want %d, have %d", jobKey, wantActive, active))
diff = 0
}
jm.expectations.ExpectCreations(jobKey, int(diff))
errCh = make(chan error, diff)
klog.V(4).Infof("Too few pods running job %q, need %d, creating %d", jobKey, wantActive, diff)
active += diff
wait := sync.WaitGroup{}
// 分批创建 diff 数量的 pods
for batchSize := int32(integer.IntMin(int(diff), controller.SlowStartInitialBatchSize)); diff > 0; batchSize = integer.Int32Min(2*batchSize, diff) {
errorCount := len(errCh)
wait.Add(int(batchSize))
for i := int32(0); i < batchSize; i++ {
go func() {
defer wait.Done()
err := jm.podControl.CreatePodsWithControllerRef(job.Namespace, &job.Spec.Template, job, metav1.NewControllerRef(job, controllerKind))
if err != nil && errors.IsTimeout(err) {
return
}
if err != nil {
defer utilruntime.HandleError(err)
// Decrement the expected number of creates because the informer won't observe this pod
klog.V(2).Infof("Failed creation, decrementing expectations for job %q/%q", job.Namespace, job.Name)
jm.expectations.CreationObserved(jobKey)
activeLock.Lock()
active--
activeLock.Unlock()
errCh <- err
}
}()
}
wait.Wait()
// 如果这次分批创建pods有失败的情况,则不在处理后续未执行的pods
// 需要计算剩余未执行的pods数量,并更新 ControllerExpectations 的 adds 和 active 值
skippedPods := diff - batchSize
if errorCount < len(errCh) && skippedPods > 0 {
klog.V(2).Infof("Slow-start failure. Skipping creation of %d pods, decrementing expectations for job %q/%q", skippedPods, job.Namespace, job.Name)
active -= skippedPods
for i := int32(0); i < skippedPods; i++ {
jm.expectations.CreationObserved(jobKey)
}
break
}
diff -= batchSize
}
}
select {
case err := <-errCh:
// 只要前面有错误产生,则返回出错并会将该job 继续丢入queue,等待下次sync
if err != nil {
return active, err
}
default:
}
return active, nil
}
以上是对Kubernetes Job技术内幕的大揭秘,意犹未尽的童鞋请持续关注本公众号,接下来本文作者还将继续揭秘cronjob 内幕原理。

登录后评论
立即登录 注册