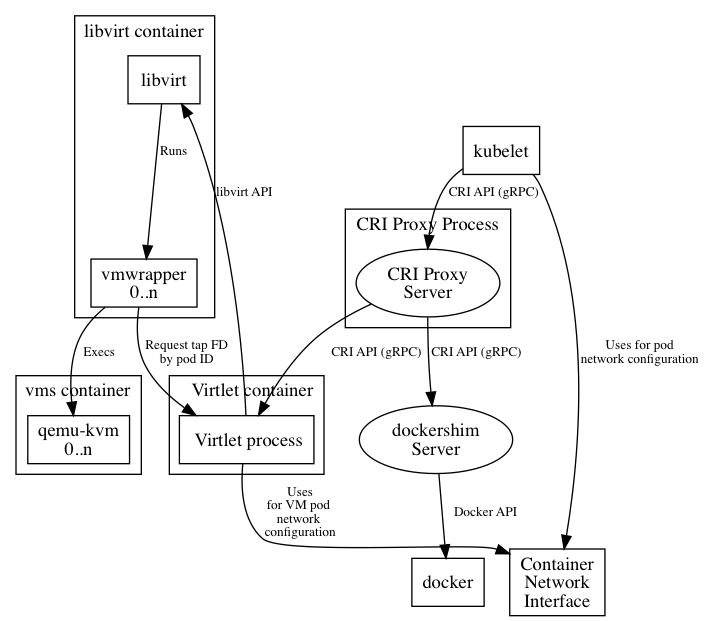
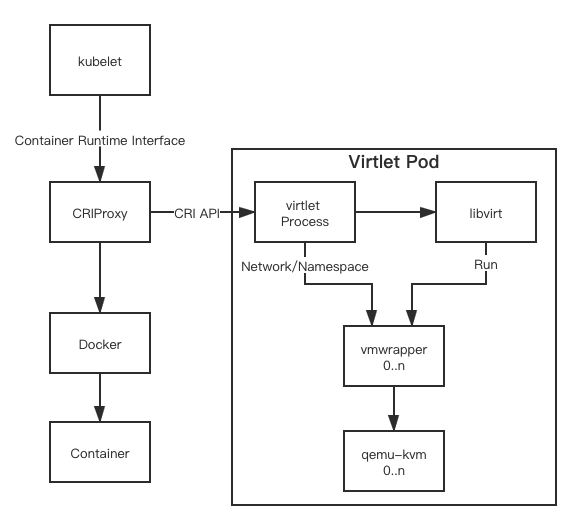
在了解virtual-Kubelet之前,我们先了解下什么是Kubelet。
Kubelet 是在每个Node节点上运行的主要 “节点代理”。在Kubernetes集群中每个节点都会启动一个kubelet进程,kubelet基于PodSpec来工作。每个Pod Spec是一个描述Pod的YAML或JSON对象。Kubelet接受通过各种机制(主要是通过Apiserver)提供的一组Pod Spec,并确保这些Pod Spec中描述的容器处于运行状态且运行状况良好。同时Kubelet还通过cAdvisor监控容器和节点资源,定期向上报当前节点的健康状态以及资源使用情况,可以把Kubelet理解成[Server-Agent]架构中的Agent。
Virtual-Kubelet是基于Kubelet的典型特性实现,向上伪装成Kubelet,从而模拟出Node对象,对接Kubernetes的原生资源对象;向下提供API,可对接其他资源管理平台提供的Provider。不同的平台通过实现Virtual-Kubelet定义的方法,允许节点由其对应的Provider提供(如ACI,AWS Fargate,IoT Edge,Tensile Kube等)支持,实现Serverless,或者将其扩展到如Docker Swarm、Openstack Zun等容器平台中,也可以通过Provider纳管其他Kubernetes集群,甚至是原生的IaaS层平台(VMware、zstack、openstack)。
最好的描述是Kubernetes API on top,programmable back。
Virtual-Kubelet如何管理虚拟机是本文讨论重点。
Virutal-Kubelet的架构
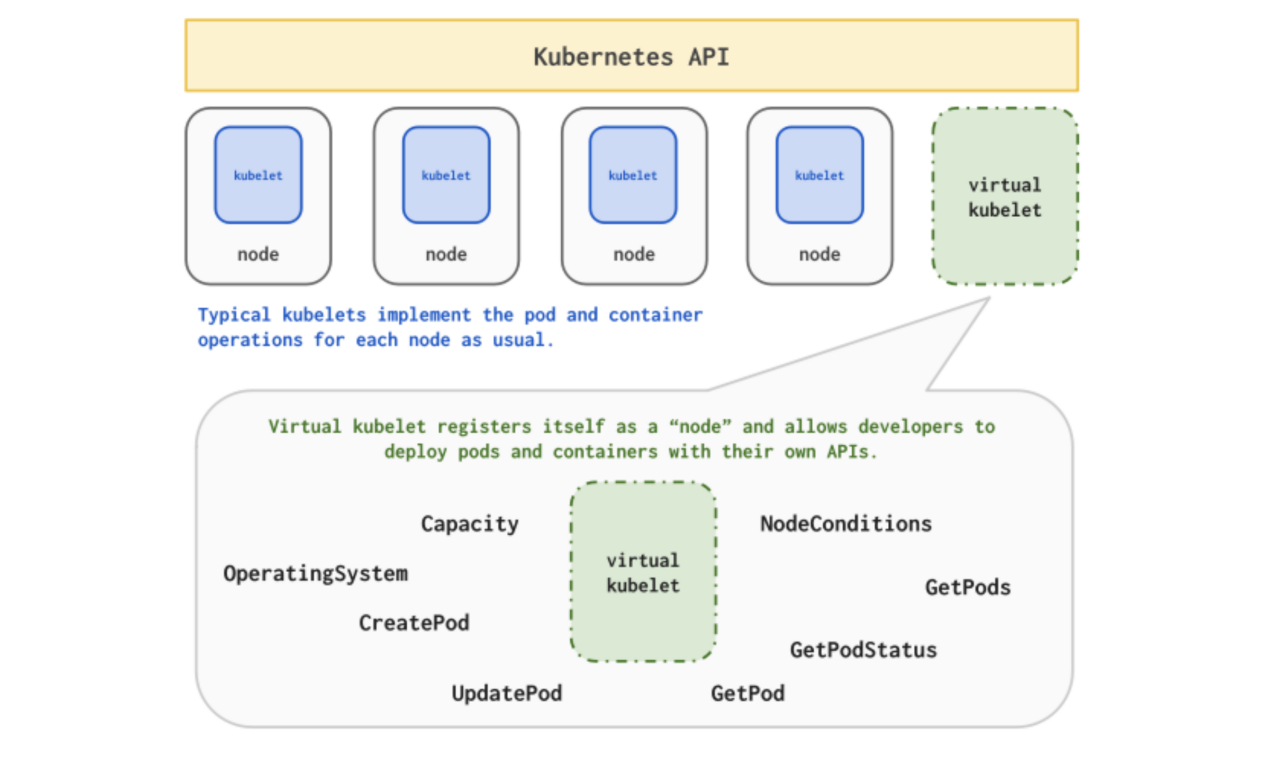
Virtual-Kubelet 模拟了Node资源对象,并负责对Pod调度到Virtual-Kubelet伪装的虚拟节点之后,对Pod进行生命周期管理。
当前支持原生Kubernetes特性:
- 创建,删除和更新Pod
- Container的日志,管理和监控
- 获取单个Pod或多个Pod状态
- 节点地址,节点容量,节点守护程序端点
- 管理操作系统
- 携带私有虚拟网络
Virtual-Kubelet如何管理虚拟机?
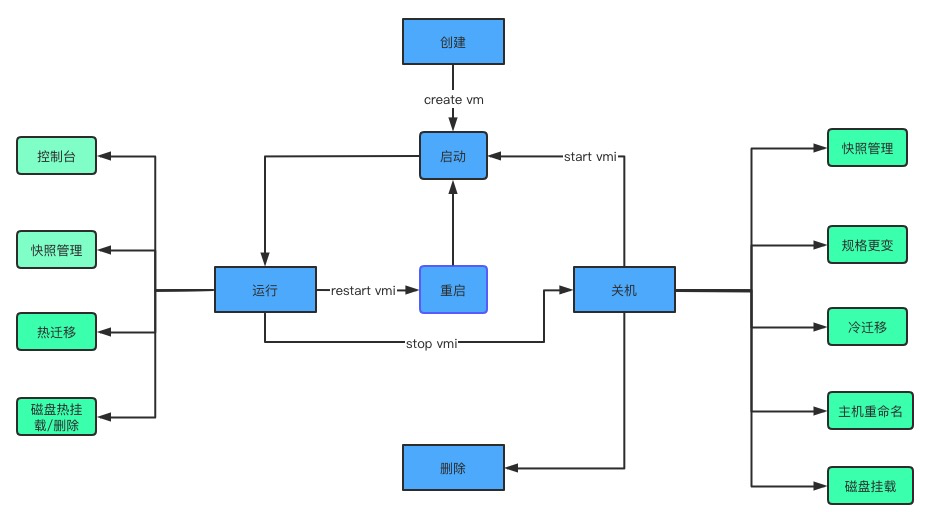
虚拟机生命周期管理
Virtual-Kubelet在虚拟机调度和操作方面可以复用Kubernetes原生的资源对象,但Pod在Kubelet管理下的生命周期仅存在创建、运行和销毁,实际对于虚拟机的开关机、备份和迁移等操作无法实现映射关系,因此对于复杂的生命周期管理,需要通过自定义CRD方式支持不同类型的IaaS平台,每一个VM-CR对应一个IaaS层VM实例。
对于VM-CR操作主要可以分为两类:
- 对VM运行状态变更
- 创建和销毁:可以对应一个VM-CR的create/delete
- VM启停操作对应VM-CR replicas数量的变更:开机0→1关机1→0
- VM规格变更:修改VM-CR Spec资源定义
- kubectl logs/exec VM-pod:实现对Pod的访问
- 对VM进行备份/迁移
- VM备份采用创建对应Backup-Job对象,通过与VM-CR实例pod亲和方式,将Backup-Job调度置VM实际节点所运行的Virtual-Kubelet节点上,备份状态与Job执行状态一致
- VM迁移采用Kubernetes原生的节点调度方式,IaaS平台每一个负载VM的物理机对应一个Kubernetes集群内的Virtual-Kubelet,VM-CR实例Pod的调度由Kubernetes控制面管理
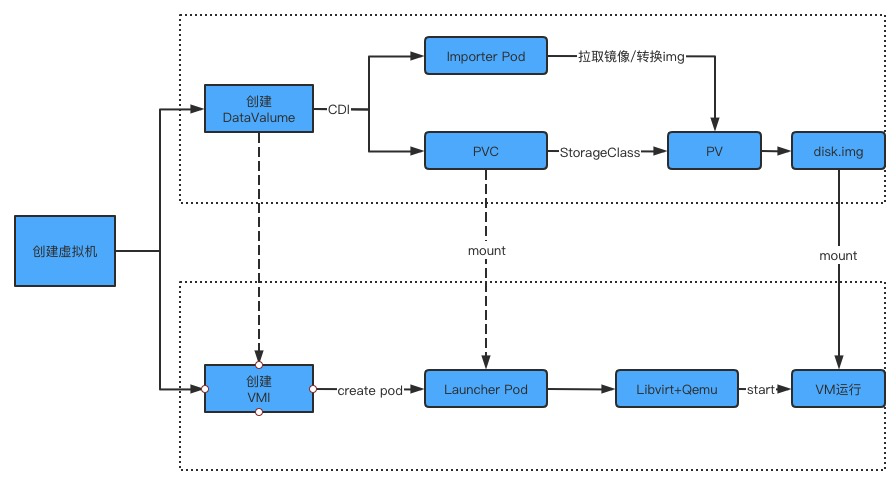
虚拟机存储管理
由于Virtual-Kubelet中Pod仅作为逻辑概念,IaaS层存储无法与Kubernetes集群公用,但可抽象为Kubernetes原生定义的PV/PVC,PV的access mode能力依赖IaaS层能力,并需要实现对应平台和底层存储的Provider和Provisioner。
Virtual-Kubelet如何实现容器与虚拟机交互
容器和虚拟机互通
- Virtual-Kubelet对应的Node会上报节点上Pod的Endpoint,假定Kubernetes集群和IaaS层平台部署在同一个二层网络下,则集群内容器Pod可以访问VM-Pod,但容器Pod对于VM-Pod不可见;
- 针对上一点可以通过Macvlan等网络插件,将容器-Pod,降维至二层网络上,实现容器-Pod和虚拟机互通,有一定硬件要求。
如何实现一套集群下虚拟机与容器的混合调度与资源隔离
- Virtual-Kubelet提供的是一个虚拟节点用来向Kubernetes上报Node对象和Pod的状态和资源情况,虚拟机资源和集群内节点资源完全隔离;
- 在引入Virtual-Kubelet的情况下,需要对Virtual-Kubelet节点配置Taint和Tolerations,保证容器-Pod和VM-Pod调度分离。
服务发现
Virtual-Kubelet,通过Provider实现的API将IaaS层VM信息抽象成对应Pod对象的信息的方式来上报Endpoints,可以通过给CR添加no selector Service,待VM-Pod拉起后补充address至对应的Service。
Virutal-Kubelet适用场景
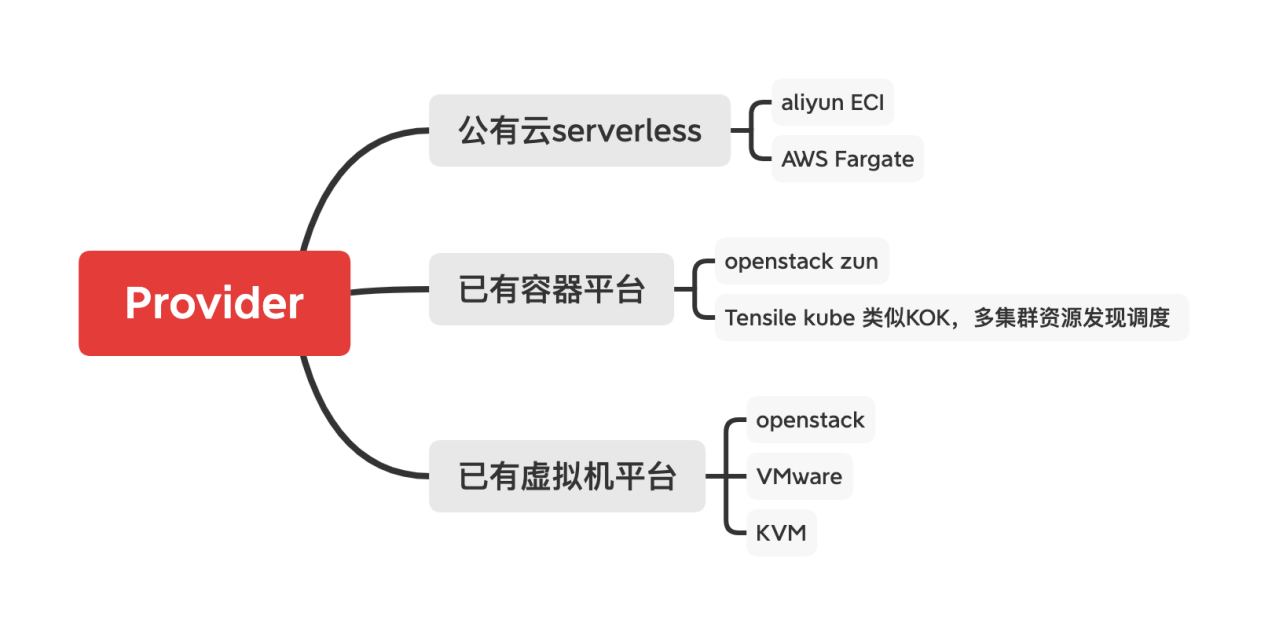
适用场景
Virtual-Kuberlet适合在已有IaaS层管理平台和Kubernetes集群环境下进行二者的打通,实现在Kubernetes集群上统一管理容器和非容器平台,同时由于Virtual-Kubelet在Serverless和纳管其他已有容器平台(Openstack Zun,Docker Swarm)方面也具有很高适配性,Virtual-Kubelet可以提供一套统一的API,方便开发者打通全流程。
Virtual-Kubelet的优缺点
优点
- 一个开源的Kubelet实现,使用Kubernetes源语,使构建、部署更简单
- 提供Kubelet典型特性接口,Provider仅需实现对应服务管理平台资源到Node和Pod对象特性的实现,不需要考虑如何访问Kubernetes
- 灵活性高,Severless实践、对接现有容器平台、对接现有IaaS平台均有一定前景
- Virtual-Kubelet设计将virtual-kubelet和Provider高度分离,Virtual-Kubelet使对于异构服务平台具有很高的兼容性(不同架构如:ARM、S390x,不同CRI如:Kata、PodMan),不光是可以纳关IaaS平台对于其他Kubernetes集群也可以实现管理
缺点
- 将非集群内资源抽象成Node和Pod对象对资源使用上有一定局限性,很难提供超出原有kubelet和IaaS平台能力范畴,IaaS深度整合需要自行实现CRD
- 仅能作为转换器,用于容器和虚拟机统一管理时还是需要依托已有的平台能力,无法像Kubevirt等方案作为一个单独的Iaas管理平台使用
Virtual-Kubelet开发及部署
开发自定义的Provider
Virtual-Kubelet项目本身并不提供Provider,而是提供一系列定义Kubelet典型操作的接口,开发者需要根据应用场景实现对应的Provider。使Kubernetes可以进行按需和几乎即时的Container的计算、调度,而无需管理VM基础结构,同时仍可利用可移植的KubernetesAPI。
实现遵循以下三个准则:
- 提供必要的后端管道(back-end plumbing),以在Kubernetes的Context中支持Pods,Containers和相关资源的的生命周期管理
- 符合Virtual-Kubelet当前提供的API
- 没有访问Kubernetes APIServer的权限,通过实现具有定义良好的回调机制来获取Secrets或Configmap之类的数据
创建一个新的Provider主要需要通过调用Virtual-Kubelet提供的库实现如下三个接口:
- PodLifecylceHandler:用于Pod生命周期的管理
type PodLifecycleHandler interface {
// CreatePod takes a Kubernetes Pod and deploys it within the provider.
CreatePod(ctx context.Context, pod *corev1.Pod) error
// UpdatePod takes a Kubernetes Pod and updates it within the provider.
UpdatePod(ctx context.Context, pod *corev1.Pod) error
// DeletePod takes a Kubernetes Pod and deletes it from the provider.
DeletePod(ctx context.Context, pod *corev1.Pod) error
// GetPod retrieves a pod by name from the provider (can be cached).
GetPod(ctx context.Context, namespace, name string) (*corev1.Pod, error)
// GetPodStatus retrieves the status of a pod by name from the provider.
GetPodStatus(ctx context.Context, namespace, name string) (*corev1.PodStatus, error)
// GetPods retrieves a list of all pods running on the provider (can be cached).
GetPods(context.Context) ([]*corev1.Pod, error)
}
- PodNotifier:该接口允许Provider提供异步通知Virtual-Kubelet有关Pod状态更新的信息,如未实现该接口的话,Virtual-Kubelet会定期检查所有Pod的状态,在计划运行大量Pod的场景中强烈推荐实现该接口
type PodNotifier interface {
// NotifyPods instructs the notifier to call the passed in function when
// the pod status changes.
//
// NotifyPods should not block callers.
NotifyPods(context.Context, func(*corev1.Pod))
}
- NodeProvider:NodeProvider负责通知虚拟小程序有关节点状态更新的信息。Virtual-Kubelet将定期检查节点的状态并相应地更新Kubernetes,如果不打算额外定义Node特性,可以直接使用Virtual-Kubelet提供的NativeNodeProvider
type NodeProvider interface {
// Ping checks if the node is still active.
// This is intended to be lightweight as it will be called periodically as a
// heartbeat to keep the node marked as ready in Kubernetes.
Ping(context.Context) error
// NotifyNodeStatus is used to asynchronously monitor the node.
// The passed in callback should be called any time there is a change to the
// node’s status.
// This will generally trigger a call to the Kubernetes API server to update
// the status.
//
// NotifyNodeStatus should not block callers.
NotifyNodeStatus(ctx context.Context, cb func(*corev1.Node))
}
- API Endpoints:用于实现kubectl logs和kubectl exec
部署
Provider部署简单仅需要在要添加目标集群的主机中添加二进制程序并根据IaaS层配置启动即可:
./bin/virtual-kubelet –provider=”hc-vmware-provider” –exsi=”X.X.X.X”














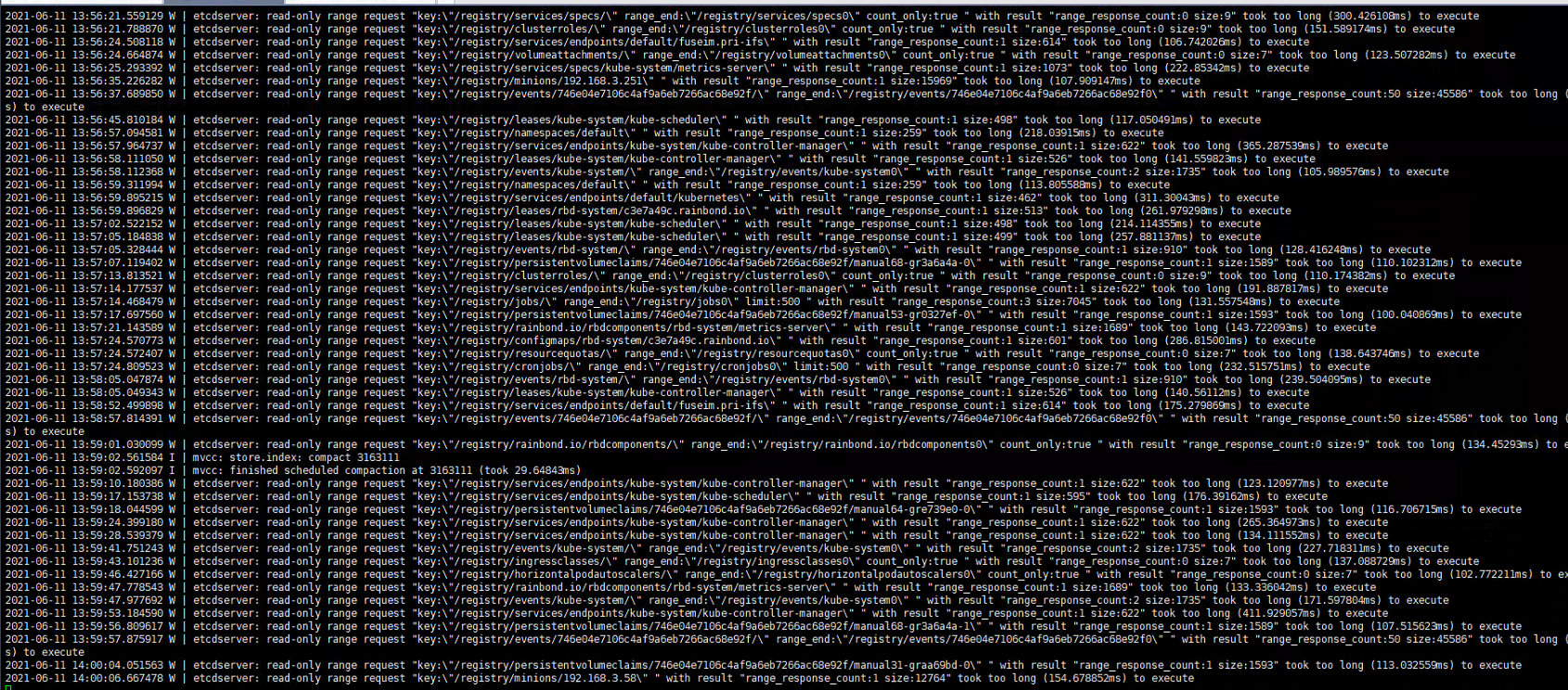
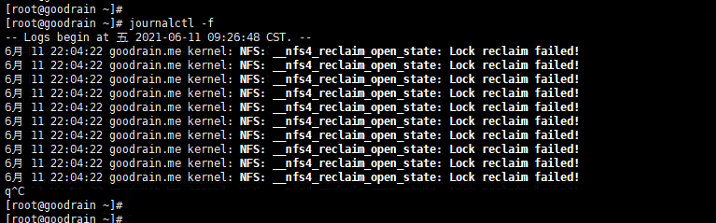 NFS:__nfs4_reclaim_open_state: Lock reclaim failed!指征 nfs client 和 nfs server 之间存在同步差异,差得多了就会开始报警。经过不断摸索,工程师们终于锁定了与 nfs 性能有关的两个系统参数,Linux nfs 客户端对于同时发起的NFS请求数量进行了控制,若该参数配置较小会导致 IO 性能较差。
NFS:__nfs4_reclaim_open_state: Lock reclaim failed!指征 nfs client 和 nfs server 之间存在同步差异,差得多了就会开始报警。经过不断摸索,工程师们终于锁定了与 nfs 性能有关的两个系统参数,Linux nfs 客户端对于同时发起的NFS请求数量进行了控制,若该参数配置较小会导致 IO 性能较差。