
前言
我们的YRCloudFile是一款面向云时代的分布式文件系统,它的主要特点是支持海量小文件的高性能数据访问,对Kubernetes平台的无缝支持,混合云场景下的数据支撑。我们在开发YRCloudFile时,也会去了解业界主流的分布式文件系统,学习其优点,避免其缺点。本文讨论几个我们曾调查过的主流的分布式文件系统,它们都是开源系统,因为这样能收集到丰富的资料,能看到代码,使得了解及讨论更为清晰。
我们在调研一个分布式文件系统时,主要关注其核心架构,包括以下几个方面:
1)它的元数据方案,比如是否有元数据集群,元数据如何组织、元数据的放置策略等。
2)元数据的副本机制及一致性,是EC还是多副本,副本间是同步写还是异步写,数据一致性如何。
3)数据的副本机制及一致性,即是EC还是多副本,以及副本间数据一致性问题。
围绕这几个核心问题,我们会做一些扩展分析,比如系统的可用性、系统的性能等。
本文要讨论的分布式文件系统,以及选取它们进行分析和了解基于以下一些考虑:
1) HDFS: 选取理由是经典,场景主要用于大数据分析,资料丰富,用户数量大。
2) MooseFS:简单、但非常典型的设计,LizardFS是其变种。
3) Lustre:广为人知,被众人当做比较的对象,背后有商业公司,但代码是开放可下载的。
4) GlusterFS: 老牌分布式文件系统,应用众多,国内很早开始就有人投入GlusterFS二次研发,其一致性hash的思路也颇为经典。
5) CephFS: 近年来最火的分布式存储Ceph,没有之一,个人认为是在分布式存储理论和实践上的集大成者。
HDFS
全称为The Hadoop Distributed File System,适用于Hadoop大数据生态,主要存储大文件,并定义文件模式是write-once-read-many,来极大简化数据一致性方面的问题。
引用官网其架构图为:
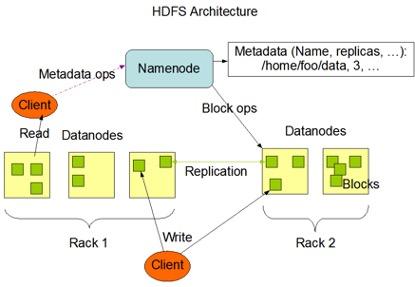
HDFS刚开始是单Namenode(可以理解为HDFS的元数据节点),这成为容量和性能的瓶颈点。后来再去做了多Namenode。
HDFS并不是一个通用型的分布式文件系统,即并不提供完整的POSIX语义,至少它的设计目标就绝不是,它发展到后来也不能胜任为通用性文件系统。它特点明显,积年来资料很多,本文也就不过多赘述。
MooseFS
如果你是一个文件系统的狂热爱好者和开发者,计划短期内写一个分布式文件系统,你可能会这么做:
1) 元数据部分
使用独立的元数据服务,为了简单化,并不做成元数据集群,而做成单元数据服务器,就像HDFS Namenode那样。
为了避免这个单点元数据服务离线、数据损毁带来的集群不可用以及数据丢失,你会部署另一个或多个元数据服务作为backup,形成一主多从架构。但主从之间如何同步数据,可能是实时同步,也可能是异步同步。
另外,关于为了简单化,元数据服务的存储直接基于本地文件系统,如ext4。
2) 数据部分
为了简单化,数据服务存储也是基于本地文件系统。为了容错,跨服务器存储多个数据副本。
这么做的明显缺点是单元数据服务是瓶颈,既限制了集群支持的最大文件数目,也限制了集群并发访问的性能。
MooseFS正好是这个架构,如官方示意图所示,它将元数据服务称之为Master Server,将数据服务称之为Chunk Server。
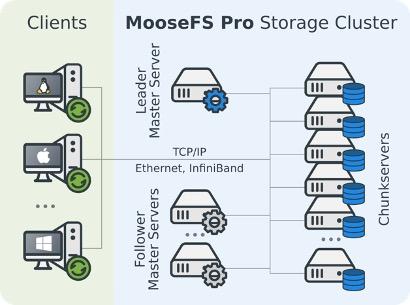
我们通过分析MooseFS的读写流程,来分析它在数据一致性方面是否有问题。这里我们参考了”MooseFS 3.0 User’s Manual” (https://moosefs.com/Content/Downloads/moosefs-3-0-users-manual.pdf)。
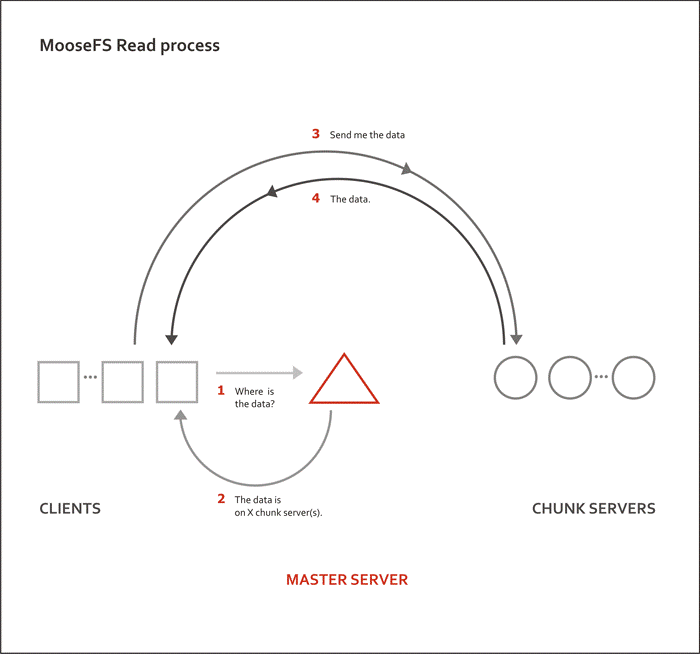
读流程示意图,需特别注意的是MooseFS所有副本都能提供读:
写流程示意图:
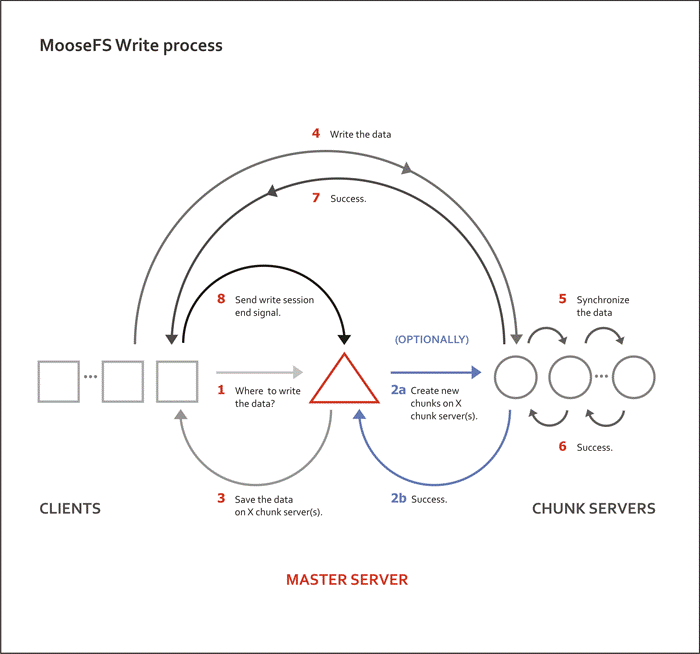
从写流程能看出,MooseFS使用的是chain replication方式,这个方式本身没有问题。不过从公开资料看,并未找到MooseFS多副本写有事务处理,且它的任意副本都支持读取,故而猜测MooseFS在故障情况下是存在数据一致性问题的。
git clone https://github.com/moosefs/moosefs.git
git checkout v3.0.111拿最新的代码,根据keyword CLTOCS_WRITE_DATA,可以看到写数据的代码流程。会发现两个问题:
1)多副本写,针对故障时副本一致性问题,并未有什么机制来确保一致。
2)本地数据写入调用hdd_write(),它在内部调用pwrite(),数据并未实时落盘,而是落在pagecache,再由pagecache下刷机制去负责落盘。
可以构造一个场景,client写入数据ABC,副本1写入了AB,副本2写入了A,此时集群掉电。在集群重启后,集群中存在不一致的数据。
构造另一个场景,client写入数据ABC,副本1和副本2都写入成功,但并未下刷,且MooseFS反馈给client说写入成功。此时集群掉电并重启后,副本1和副本2可能不一致,client读取的数据跟被承诺的可能不同。
实际上我们在之前工作中,维护过一套线上MooseFS系统,我们当时分析出MooseFS这一问题。今天写这个文章时,我们重新拿了MooseFS最新的代码,阅读了针对性部分,发现这个数据一致性问题如故。
Lustre
Lustre在HPC领域应用很广,一定有其特别之处。不过我们仍是主要关注其元数据和数据架构,以及数据一致性方面的问题。
Lustre架构跟MooseFS类似,都是典型的有元数据服务的架构。不过Lustre似乎并未提供副本机制(两副本机制需主动触发,非同步副本),也许是它面对的HPC场景,并且数据空间来源于后端的SAN阵列,所以它不需要提供数据冗余。
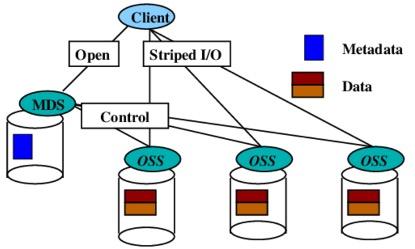
数据冗余依赖后端SAN阵列保障,数据一致性问题就被天然绕开了。我们因此也暂时不去深入了解。
GlusterFS
GlusterFS是非常知名的一个分布式文件系统,国内不少公司很早就在做GlusterFS的二次开发,关于GlusterFS最适合的应用场景,大家讨论的最多的是视频存储和日志存储,其IO特点是大块数据顺序读写,这很好理解,一般文件系统都能胜任这一场景。
另一方面,提及GlusterFS,大家讨论最多的概念是“一致性哈希”,“无中心架构”,“堆栈式设计”,本文会简单聊到这几个概念。GlusterFS网上学习资料很多,本文不再赘述,我们仍然主要分析其元数据设计和数据一致性。
GlusterFS使用无元数据结构,亦即“无中心架构”,或“去中心化”,它使用一致性哈希,或者说是DHT(Distributed Hash Table)来定位数据位置。部署好一个GlusterFS集群,IO节点知悉集群存储节点列表,读写文件时,以文件名和存储节点列表为DHT算法输入,定位出文件存储位置。
在集群无故障时,存储节点列表固定,DHT算法简单有效。但在集群发生节点进出类故障时(比如有存储节点crash等),DHT应对就颇为乏力,应对逻辑复杂,且会对业务可用性产生很大影响,因为存储节点列表变化,不少文件根据DHT计算的定位也发生变化,会涉及数据挪动,会涉及业务IO需等待恢复IO先行完成。
另一方面,这种无中心元数据结构,应对元数据操作时消耗颇大,比如一个ls,会放大到数个存储节点去做ls。而一般认为,文件系统中元数据操作占比很大,无元结构对这一事实颇为头疼。
数据一致性方面,GlusterFS是不提供数据强一致性的。我们数年前有过GlusterFS的开发经验,split-brain —— 中文称为“脑裂” —— 对这一名词,我们至今印象深刻。
split-brain含义就是数据副本间不一致,比如副本1的内容是ABC,副本2的内容是AB,集群判定不出谁是合法数据。
我们构造出一个split brain的场景:
- brick1 down, write fileX
- brick1 up, brick2 down, write fileX
- brick1 brick2都up,split brain发生,brick1 brick2相互blame
GlusterFS官方文档是明确提及这一问题的,参见”Heal info and split-brain resolution” (https://docs.gluster.org/en/latest/Troubleshooting/resolving-splitbrain/)。能感觉出GlusterFS的定位并不是强一致的分布式文件系统,至此,我们也很能理解为什么它主要用于大块顺序IO的视频或日志文件存储,因这类数据文件大,总体文件数目少,性能更偏重于吞吐。且并非关键数据,发生split brain之类数据一致性问题后影响较小。
从GlusterFS社区计划来看,他们也考虑要处理元数据性能问题和数据一致性问题,但我认为这是两大核心问题,跟核心架构强相关,要致力于很好解决颇有难度。不过技术无止境,我们颇为期待。
CephFS
Ceph是近年来最成功的分布式存储系统,这里需注意并非说是分布式文件系统,因为Ceph有三大应用场景,分别是块存储Ceph RBD,对象存储Ceph RGW,以及文件存储CephFS。
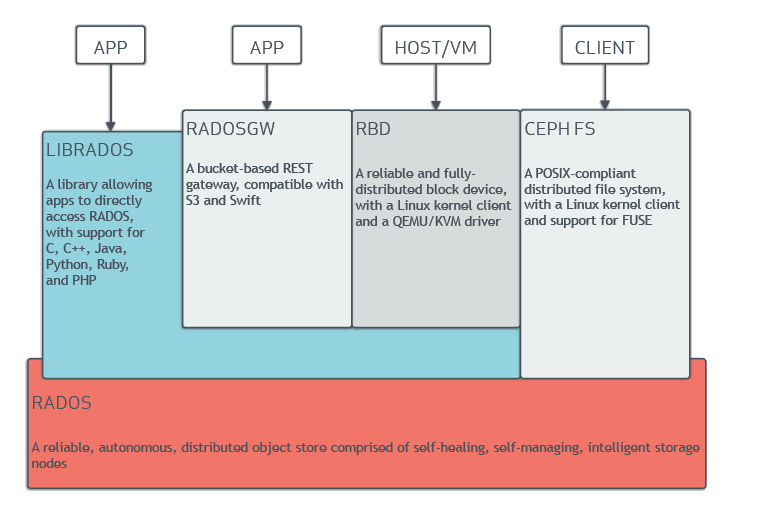
Ceph RBD相信很多人都比较熟悉,因为在数年前云计算在风口的时候,OpenStack如日中天,Ceph RBD与OpenStack一拍即合,应用颇广。
CephFS、RBD、RGW三者的核心都是RADOS,这个模块负责数据定位,多副本,副本间强一致以及数据恢复等核心功能。RADOS数据定位算法是CRUSH,是支持一定程度用户可控的哈希算法。RADOS做了多副本写的事务,保证单次写的原子性,并通过pglog等机制保证副本间的数据一致性。
我们也曾有Ceph RBD的开发经验,我们综合看来,Ceph是分布式存储理论和实践的集大成者。它理论完备,实现上虽代码庞杂,但模块比较清晰,代码质量颇高,非常值得去学习。
理论角度Ceph无可指摘,几年前,投入Ceph二次开发的公司颇多,但大浪淘沙,只剩下一些研发实力较强的厂商在这方面坚持投入。其原因之一在于Ceph代码过于繁杂,一般难以全面掌控,优化的效果和投入的资源不完全成正比。
让我们回归“分布式文件系统”这一主题,回到本文主要讨论元数据和数据一致性的视角。
CephFS是有元数据服务的,它称之为MDS。CephFS的元数据和数据都是存储在RADOS中的,从而CephFS的开发思路跟前面提及的MooseFS就很不相同,比如MooseFS要做元数据服务的Leader Follower,而CephFS不需要考虑这些,它的数据通过RADOS天然就可靠、一致地冗余存储到集群中了。简单来说,CephFS的元数据管理MDS,更像是基于一个稳定数据放置和存储层(这一层负责通过副本或EC方式确保数据强一致)之上,即RADOS之上,建设一个元数据服务层。这种架构在充分利用RADOS架构优势的同时,也带来了一些弊端,我们之前谈到,分布式文件系统中大量操作都和元数据相关,CephFS先访问 MDS,最终再访问RADOS中的数据,IO路径加长,对文件系统性能的影响来看,显得尤为明显。
总结
本文我们概要地讨论了常见的几个开源的分布式文件系统,主要从元数据和数据一致性两大角度去分析,我们认为从理论角度看,目前CephFS是最完备的。
不过,讨论一个分布式文件系统有多种不同的视角,比如大文件备份的应用场景下,MooseFS就比较适合,而如果使用CephFS就太过复杂;HPC场景下,Lustre应用很广,但换上CephFS也很可能面临性能降级。所以本文并非是对提及的分布式文件系统的“笔伐”,而是站在“元数据和数据一致性”视角,讨论我们的看法,从而在设计和实现自己的文件系统时,获得更广泛的思路。
每个系统都有自己的权衡,都有自己的闪光点,本文不能一一而足,以后有机会再行细致讨论,也欢迎大家留言探讨。

登录后评论
立即登录 注册