
Kubernetes 生态系统充斥着各种工具,例如监控、可观察性、跟踪、日志记录等,但一般很难真正理解故障排除与这些工具有何联系。
当故障发生时,我们要掌握是从哪里发生,了解所面临的问题,解决眼前的问题,然后修复根本原因。随着系统规模的扩大,这一切会变得越来越复杂。
一名从事现代、复杂、分布式系统工作的软件工程师,会经常发现,每次出现问题或故障时,都需要了解引发问题的原因以及是谁造成的,但是,这并不是一件容易的事。更难的,是弄清楚幕后发生了什么,以及如何防止它再次发生。
一般,我们会这样思考:
- 究竟发生了什么?
- 哪些事情是相关的?
- 什么与我们试图排除故障的特定症状相关?
- 我们如何确定根本原因?
- 最终,我们还要确保将来不再发生此问题或类似问题?
本文中,我们将之简化为3个步骤:
- 理解
- 管理
- 预防
我将深入探讨如何实施好这三个步,以及它们如何帮助我们对Kubernetes 进行故障排除。我还将回顾哪些生态系统工具适合哪个步,以更好地掌握或使用那些工具。
第一步:理解
毫不奇怪,这是重要的一步。理解系统资源,通常使你能够了解发生了什么、出了什么问题以及我们接下来应该做什么。
为了尝试了解故障原因,开发人员将首先分析系统最近的修改以及可能导致此故障发生的更改。
当然,这说起来容易做起来难。在复杂的分布式系统,尤其是基于 Kubernetes 的系统中,这意味着大量使用 kubectl 来对部署日志、跟踪和指标进行故障排除,验证 pod 健康状况和资源上限,以及服务连接,以及其他常见的 pod 错误,检查 YAML 配置文件,验证第三方工具和集成等等。这可能是一行代码、一行配置的更改,触发了故障。
下图一张图,可以帮助我们在排除 K8s 系统进行故障时,缩小问题的范围。
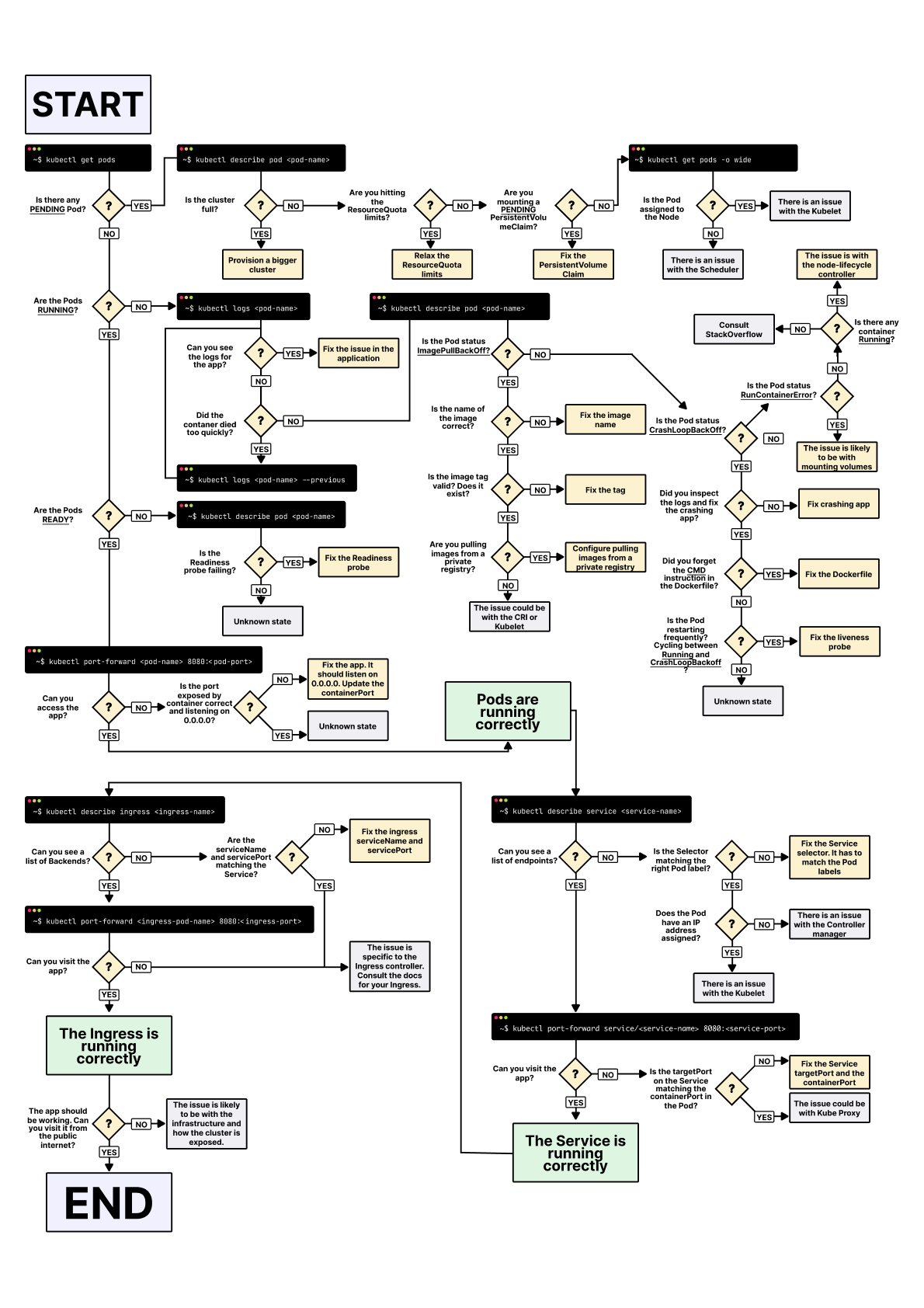
图片来源: 有关 Kubernetes 部署故障排除的指南
接下来,我们将查看事件:系统中实际发生了什么 – 系统是否过载?是否丢失了数据?是否存在服务中断?这与系统的初始变化有何关系?
然后,我们查看一下我们创建的指标、仪表板和数据,以基于数据源对问题进行某种理解。是否不止一个系统表现相同?影响两个系统的服务之一是否存在依赖性?最后,我们能否从看似相似的先前事件中学到一些东西,让我们对我们现在正在经历的事情有所了解?
仅就某些情况而言,下面是你需要使用的一些工具的列表,以便对系统中发生的事情有一个基本的了解。
监控工具: Datadog、Dynatrace、Grafana Labs、New Relic
可观察性工具: Lightstep、Honeycomb
实时调试工具: OzCode、Rookout
日志工具: Splunk、LogDNA、Logz.io
第二步:管理
在当今的微服务架构中,很多时候相互依赖的服务由不同的团队管理。发生故障时,解决问题的关键之一是团队之间的沟通与协作。
根据潜在问题的类型,你可能想要采取的操作,包括像重启系统这样简单的操作,或者更’严厉’的措施,例如版本回滚或恢复最近的配置,直到更清楚地了解潜在问题。最终,你可能需要采取主动措施,如增加内存上限或机器数量的形式增加容量。但是,所有这些都不应该是你实时尝试和弄清楚的。今天有很多工具,从 Jenkins 到 ArgoCD,云提供商的专有工具,甚至更多的 kubectl 来采取这些行动和措施。
一旦更好地理解了潜在问题,补救就不应该是主要是反复试验的临时操作,或者存在于当前团队和实践中的记录。根据公司的技术堆栈和可能的根本原因,应使用定制的运行手册来管理任何给定的事件,并针对每种警报提供具体的任务和操作。
团队中的每一位工程师,无论是高级还是初级,都可以利用这一份友好的运行手册来实时排除故障。
此阶段的工具包将包括以下一些内容:
事件管理: PagerDuty,Kintaba
项目管理: Jira、Monday、Trello
CI/CD 管理: ArgoCD、Jenkins
最后一个步:预防
预防可能是最重要的步,以确保类似事件不再发生。防止类似问题的方法是根据每个事件创建定义明确的策略和规则。在“理解”阶段要采取哪些行动,我们如何最快速地识别问题并将问题上报给相关团队?
我们如何委派责任,确保团队之间无摩擦的沟通和协作?这包括手头任务和操作的完全透明度,以及进度的实时更新。每种警报和事件的任务的规范顺序是什么?
一旦我们弄清楚了上述所有内容,我们就可以开始考虑如何自动化和协调这些事件,并尽可能接近传说中的“自我修复”系统。
这一步的特点是通过不断将系统推向极限,从而创建更具弹性和适应变化的系统的工具。例如:
Chaos Engineering: Gremlin、Chaos Monkey、ChaosIQ
Auto Remediation: Shoreline、OpsGenie
一步都不能少
我们相信,通过以上三步的结合,可以将故障排除与监控、可观察性、跟踪等区别开来。然而,可能最重要的是深入到系统和流程中,以防止它们再次发生。
我们都见过这个表情包:

或者这个:

它们仍然被广泛使用并如此受欢迎的原因是,即使我们在“DevOps 工具”方面取得了巨大进步后,对于实时的问题或故障,很多时候依然捉襟见肘。
因此,我建议将应用程序和运维数据集中到一个平台中,使团队成员能够真正了解他们的系统,并最终了解对复杂系统出现的警报如何采取行动。当我们将最好的开发人员和运维人员结合在一起时,我们可以通过更好地合作来更快地解决故障。
译文链接: https://dzone.com/articles/the-three-pillars-of-kubernetes-troubleshooting

登录后评论
立即登录 注册