
云原生世界中对可观察性的需求
任何系统,如果没有公开其运行状况,公开其的应用程序的状态,都是毫无用处的。
以前,组织中的系统作为一个整体运行,并且很少变更,因此易于观察。但是,在今天的云原生世界中,变化是随时发生的。同时,云原生应用所遵循的微服务模式,使得系统成为高度分布式的系统。这就导致指标收集,监视和日志记录需要以不同的方式进行。
让我们简要了解一下云原生环境中的一些挑战:
- 当你在Kubernetes集群中运行应用程序,Kubernetes会使用Pod作为应用的实例。但是Pod本质上是短暂的,它们经常被删除,重新创建,重新启动并可能从一个节点移到另一个节点。因此,如果应用程序发生异常,在不断变换的运行环境中,你将去哪里寻找线索?
- 由于云原生应用程序的高度分布式特性,有时一个请求可能需要跨越十几种服务。如果用户收到错误消息,你该怀疑是哪个服务造成的?
云原生日志
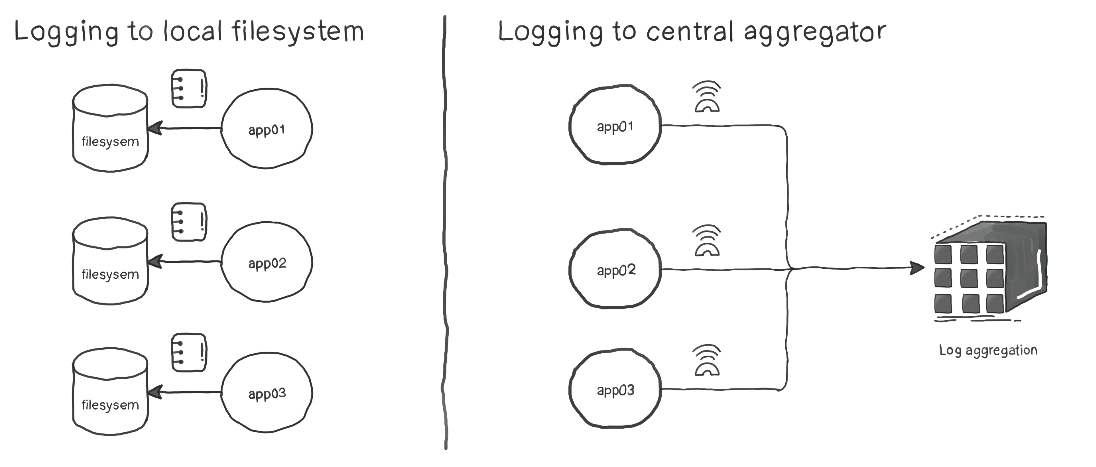
根据经验,在今天的云原生世界中,收集后的日志应该将其存储在托管应用程序的节点之外。其背后的原因是,你需要在一个地方可以查看,分析和关联来自不同来源的不同日志。
有许多工具可以为你完成这项任务;例如Filebeat,Logstash,Log4j等。应用程序应在重要事件发生时对其进行日志记录。
例如,Python应用程序中日志记录–某个新用户已添加到数据库中:
log.info("{} was added successfully".format(user))
我们需要应用程序将日志记录发送到STDOUT和STDERR,这样做的原因有很多:
- Kubernetes中的Pod是短暂的,如果当Pod崩溃,删除等时,你将无法查看这些日志。
- 在微服务架构中,不管是用PHP编写的后端,还是使用Python构建的中间件以及使用NodeJS的前端,这些系统中的每一个都可能使用自身特有的日志记录框架。所以,将日志定向到STDOUT和STDERR可以确保我们可以采用一致的方式来收集日志。
- 云原生架构非常灵活,不仅可以为不同的组件使用不同的编程语言,还可以使用不同的操作系统。例如,后端可能正在使用仅在Windows上工作的旧系统,而其他基础结构则在Linux上运行。但是由于STDOUT和STDERR在设计上是任何OS都有的,因此它提供了更高的一致性,可以将它们用作统一的日志源。
- STDOUT和STDERR是标准流。因此,它们完全适合日志性质。日志是数据流,它没有开始或结束,只是在事件发生时才产生文本字符串。因此,从数据流中启动对日志聚合服务的API调用比使用文件更容易。
测试案例:Kubernetes日志记录
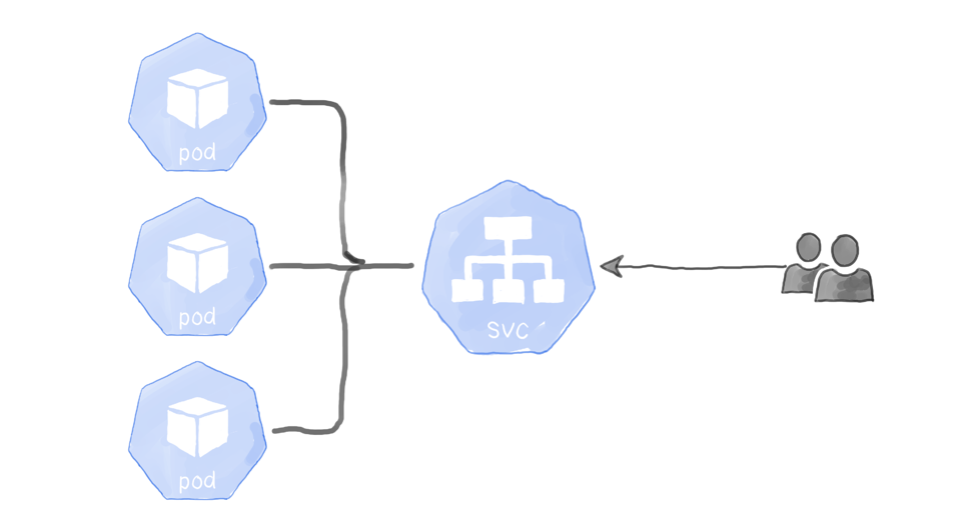
假设你的应用程序,托管在Kubernetes集群的三个Pod上。该应用程序的日志配置是,每当该应用程序接收并响应Web请求时就打印一行日志。
但是,Kubernetes集群的设计使服务(SVC资源)可以将请求随机路由到后端Pod。现在的问题是:当我们要查看应用程序日志时,应该查询哪个Pod?下图描述了这种情况:
这种情况很常见,因此Kubernetes提供了一个简单的命令,使你可以查看与特定标签匹配的所有Pod的集合日志:
$ kubectl get pods NAME READY STATUS RESTARTS AGE frontend-5989794999-6wxhm 1/1 Running 0 2d4h frontend-5989794999-fkq56 1/1 Running 0 124m frontend-5989794999-nzn2f 1/1 Running 0 124m $ kubectl logs -l app=frontend --- output truncated for brevity --- 10.128.0.3 - - [06/Oct/2019:15:16:08 +0000] "GET / HTTP/1.1" 200 22 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" "-" 10.128.0.3 - - [06/Oct/2019:15:16:09 +0000] "GET /favicon.ico HTTP/1.1" 404 232 "http://34.70.214.219:31121/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" "-" [pid: 14|app: 0|req: 2/2] 10.128.0.3 () {40 vars in 646 bytes} [Sun Oct 6 15:16:09 2019] GET /favicon.ico => generated 232 bytes in 12 msecs (HTTP/1.1 404) 2 headers in 72 bytes (1 switches on core 0) WSGI app 0 (mountpoint='') ready in 0 seconds on interpreter 0x555ed3308170 pid: 11 (default app) --- output truncated for brevity ---
如预期的那样,该命令返回了详细输出,因为它是所有标记为app = frontend的Pod的合并日志。
我们感兴趣的日志其中这样的一条信息。
[pid: 14|app: 0|req: 2/2] 10.128.0.3 () {40 vars in 646 bytes} [Sun Oct 6 15:16:09 2019] GET /favicon.ico => generated 232 bytes in 12 msecs (HTTP/1.1 404) 2 headers in 72 bytes (1 switches on core 0)
请注意,这条日志包含容器的IP地址,后跟请求的日期和时间,HTTP请求方式以及其他数据。其他两个Pod也会产生相似的输出,但具有不同的IP地址。这样我们就可以判断是哪个容器的日志信息了。
但是,这样的日志消息的格式不是Kubernetes决定的,而是由应用程序配置的,在记录日志时也输出容器的主机名。
云原生指标
日志和指标之间存在重要区别。日志描述事件的发生。指标则描述了应用程序及其基础结构的状态。你可以在某些指标达到预定义的阈值时设置警报。例如,当CPU超过80%或并发Web请求数达到1k时报警。
获取指标时,我们基本上有两种方法:基于推的方法和基于拉的方法。
基于拉的方法
在这种方法中,应用程序公开了一个或多个运行状况的端点。通过HTTP请求那些URL会返回该应用程序的运行状况和指标数据。例如,我们的python flask API可能具有/health端点,该端点公开有关服务当前状态的重要信息。但是,实现此方法会带来挑战:
你要从哪个Pod中获取数据?
在微服务架构中,不止一个组件负责托管应用程序,而且每个服务都具有不止一个Pod。例如,博客应用程序可能具有身份验证服务,帖子和评论服务。每个服务通常位于负载均衡器之后,以在其实例之间分配流量。
监控系统需要访问应用程序的运行状况端点,并将结果存储在时间序列数据库中(例如InfluxDB或Prometheus)。因此,当监控系统需要为其指标提取服务时,它可能会访问负载均衡器的URL,但是,负载均衡器将请求路由到第一个可用的后端Pod,该后端Pod不能涵盖所有Pod的运行状况。
下图说明了这种情况:
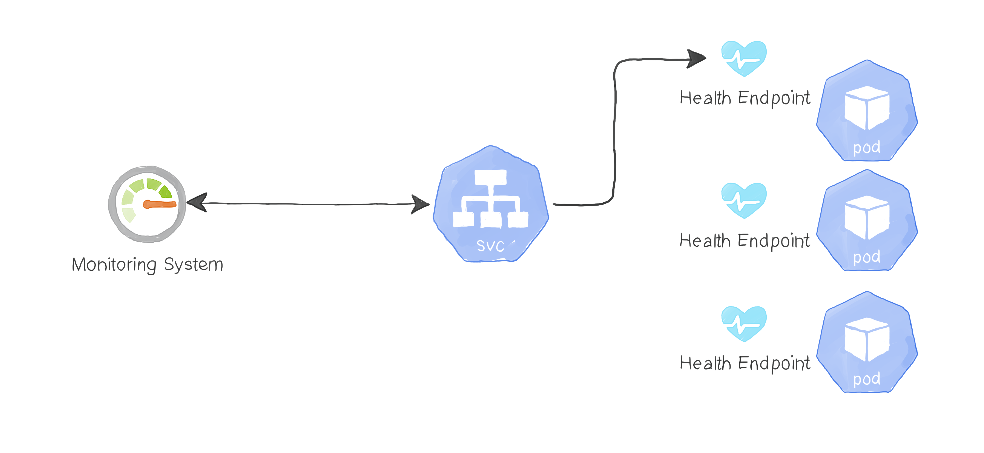
因此我们需要一种机制,每个Pod都可以响应健康检查请求。
解决此问题的一种可能的解决方案是,使监视系统负责检测应用程序中不同服务的URL,而不是依靠负载均衡器。
此处的监控系统定期执行两项任务:
- 发现可用的Pod。在Kubernetes中执行此操作的一种方法是将Pod放置在 headless service 后面, 这将获得svc资源后的所有Pod地址 。
- 通过访问每个Pod的URL,提取Pod的健康指标。
下图描述了这种方法:

使用这种方法,监视系统必须有权访问容器的内部IP地址。因此,需要将监视系统部署为集群的一部分。诸如Prometheus之类的解决方案,不仅提供了与集群内运Pod的深度集成,而且还与集群本身的系统级指标深度集成。
基于推的方法
在这种方法中,应用程序需要推送数据给监控系统。
最初,这种方法似乎给应用程序增加了额外的复杂性。开发人员必须构建用于指标收集和推送的必要模块。但是,通过使用sidecar模式可以完全避免这种情况。
sidecar模式利用一个Pod可以托管多个容器,所有这些容器共享相同的网络地址和存储卷。他们可以通过本地环回地址localhost相互通信。因此,我们可以放置一个仅负责日志或指标收集并将其推送到指标日志服务器或监控系统的容器。
使用此模式,你不需要对应用程序进行更改,因为sidecar容器已经通过运行状况端点收集了必要的指标,并将其发送到服务器。如果服务器的IP地址或类型发生更改,我们只需要更改sidecar容器的实现即可。该应用程序保持不变。下图演示了如何使用sidecar容器来收集和推送指标:
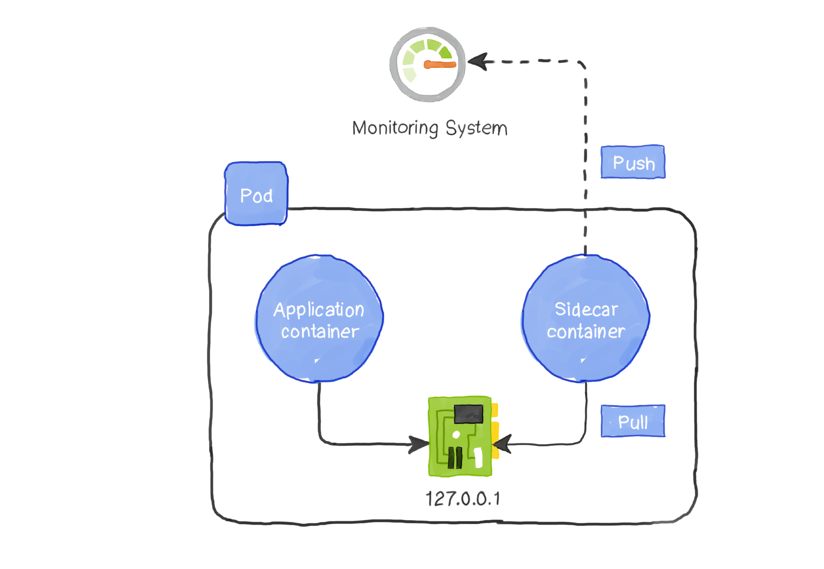
值得一提的是,这种模式还便于公开更多应用程序指标。因为sidecar容器本身可以公开有关应用程序性能的其他数据,例如,响应延迟,失败请求的数量等等。
总结
- 组织需要在问题发生之前,就能够知道应用程序的状况。
- 即使在非云原生环境中,指标也必须存储在生成该指标的节点之外,以获得更好的可见性,关联性和聚合性。
- 在微服务架构中,由于有许多数据来源,因此在日志收集方面存在许多挑战。
- 像Kubernetes这样的编排系统,能够很好地处理或查看多个数据源的日志。例如,使用kubectl log -l参数,你可以在同一标签下收集不同容器的所有输出。
- 将日志存放到标准输出和标准错误通道,比将日志写入本地文件更加有效。这样,日志收集代理可以在多个不同的操作系统/应用程序之间轻松,一致地处理STDOUT和STDERR。
- 对于指标收集,在云原生环境有两种方法:基于拉的方式和基于推的方式。
- 基于拉的方法,依赖于监控系统来发现服务并与之通信。它通过访问运行状况端点来获取指标。
- 基于推的方法,应用程序需要推送数据给监控系统。为了避免增加应用程序的开销,我们使用sidecar容器收集指标并将其发送到监控系统。
译文链接: https://www.magalix.com/blog/cloud-native-logging-and-monitoring-pattern

登录后评论
立即登录 注册