
为什么选择混沌网格(Chaos Mesh)?
在分布式计算的世界中,故障可能随时随地发生在你的集群上。传统上,我们使用单元测试和集成测试来确保系统可以投入生产。但是,随着集群规模的扩大,复杂性的增加以及数据量以PB级增长,这些测试无法涵盖所有内容。
为了更好地识别系统漏洞并提高弹性,Netflix发明了Chaos Monkey,该技术将各种类型的故障注入基础架构和业务系统。这就是混沌工程的开始。
在PingCAP上,我们的产品TiDB(开源的分布式NewSQL数据库)遇到了同样的问题。容错性和弹性是头等大事,因为对于任何数据库用户来说,最重要的资产—数据本身—都处于危险之中。
我们已经在测试框架中内部 实践了Chaos Engineering已有一段时间了。但是,随着TiDB的增长,测试要求也随之提高。
我们意识到,我们不仅需要TiDB,而且还需要其他分布式系统的通用混沌测试平台。考虑到这一点,我们开发了Chaos Mesh,这是一个云原生的Chaos Engineering平台,可在Kubernetes环境中协调混沌实验。这是一个开源项目:https://github.com/pingcap/chaos-mesh。
在以下各节中,我将与你分享什么是Chaos Mesh以及我们如何设计和实现它。
混沌网格(Chaos Mesh)可以做什么?
Chaos Mesh包括针对Kubernetes上复杂系统的故障注入方法,并涵盖了Pod,网络,文件系统甚至内核中的故障。
这是我们如何使用Chaos Mesh定位TiDB系统错误的示例。
我们使用分布式存储引擎(TiKV)模拟了Pod的停机时间,并观察了每秒查询量(QPS)的变化。通常,如果一个TiKV节点发生故障,则QPS在恢复正常前可能会经历短暂的抖动。这就是我们保证高可用性的方式。

从仪表板可以看到:
- 在前两个停机时间中,QPS在大约一分钟后恢复正常。
- 但是,在第三次停机后,QPS需要更长的时间才能恢复-大约9分钟。如此长的停机时间是无法预料的,并且肯定会影响在线服务。
经过诊断后,我们发现在处理TiKV停机时间时,TiDB集群版本(V3.0.1)存在一些棘手的问题。我们在更高版本中解决了这些问题。
除了模拟停机时间之外,Chaos Mesh还包括以下故障注入方法:
- pod-kill: 模拟Kubernetes Pod被杀死
- pod-failure: 模拟Kubernetes Pod长时间不可用
- 网络延迟: 模拟网络延迟
- 网络丢失: 模拟网络数据包丢失
- 网络复制: 模拟网络数据包复制
- 网络损坏: 模拟网络数据包损坏
- 网络分区: 模拟网络分区
- I/O延迟: 模拟文件系统I/O延迟
- I/O 错误: 模拟文件系统I/O错误
混沌网格(Chaos Mesh)设计
Chaos Mesh专为Kubernetes设计。混沌网格:
- 不需要特殊的依赖关系,因此可以将其直接部署在Kubernetes集群(包括Minikube)上。
- 无需修改被测系统(SUT– the system under test )的部署逻辑,因此可以在生产环境中执行混乱的实验。
- 利用现有的实现,以便可以轻松扩展故障注入方法。
- 与其他测试框架集成。
专为Kubernetes设计
在容器世界中,Kubernetes是绝对的领导者。本质上,Kubernetes是用于云的操作系统。
TiDB是云原生的分布式数据库。我们的内部自动化测试平台从一开始就是在Kubernetes上构建的。我们每天在Kubernetes上运行数百个TiDB集群,以进行各种实验,包括广泛的混沌测试,以模拟生产环境中的各种故障或问题。为了支持这些混沌实验,将混沌和Kubernetes结合起来成为我们实现的自然选择和原则。
CustomResourceDefinitions设计
混沌网格(Chaos Mesh)使用CustomResourceDefinitions(CRD)定义混沌对象。
在Kubernetes领域,CRD是用于实现自定义资源的成熟解决方案,具有丰富的实现案例和工具集。使用CRD可使Chaos Mesh与Kubernetes生态系统自然融合。
代替使用统一的CRD对象中定义所有类型的故障注入,我们允许针对不同类型的故障注入使用灵活且独立的CRD对象。如果添加符合现有CRD对象的故障注入方法,则可以直接基于此对象进行缩放;如果这是一种全新的方法,我们将为其创建一个新的CRD对象。
通过这种设计,可以从顶层提取混乱的对象定义和逻辑实现,从而使代码结构更清晰。这种方法还降低了耦合程度和出错的可能性。此外,Kubernetes的控制器运行时是实现控制器的绝佳包装。这节省了很多时间,因为我们不必为每个CRD项目重复实现同一组控制器。
Chaos Mesh实现PodChaos,NetworkChaos和IOChaos对象。这些名称清楚地标识了相应的故障注入类型。
例如,在Kubernetes环境中,Pod崩溃是一个非常普遍的问题。许多本机资源对象会通过典型操作(例如创建新的Pod)自动处理此类错误。我们的应用程序真的可以处理此类错误吗?如果Pod无法启动怎么办?
通过定义明确的动作(例如“ pod-kill ”),PodChaos可以帮助我们有效地查明此类问题的原因。PodChaos对象使用以下代码:
spec: action: pod-kill mode: one selector: namespaces: - tidb-cluster-demo labelSelectors: "app.kubernetes.io/component": "tikv" scheduler: cron: "@every 2m"
此代码执行以下操作:
- “action “属性:定义要注入的特定错误类型。在这种情况下,“ pod-kill”会随机杀死Pod。
- “selector ”属性:限制了混沌实验的范围。在这种情况下,范围是TiDB集群下名称空间为“ tidb-cluster-demo”的TiKV Pods。
- “ scheduler ”属性:定义每个混乱故障操作的间隔。
有关CRD对象(如NetworkChaos和IOChaos)的更多详细信息,请参见Chaos-mesh文档。
混沌网格(Chaos Mesh)如何工作?
解决了CRD设计问题后,让我们看一下Chaos Mesh的工作原理。涉及以下主要组件:
Controller-manager
充当平台的“大脑”。它管理CRD对象的生命周期并安排混乱实验。它具有用于调度CRD对象实例的对象控制器,而admission-webhooks控制器可将边车容器动态注入Pod。
Chaos-daemon(混沌守护进程)
作为特权daemonset 运行,可以在节点和Cgroup上操作网络设备。
Sidecar
作为一种特殊类型的容器运行,该容器由admission-webhooks动态注入到目标Pod中。例如,“ chaosfs”边车容器运行一个fuse-daemon来劫持应用程序容器的I/O操作。
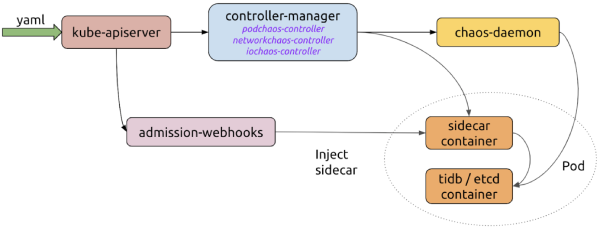
混沌网格工作流程
以下是这些组件简化混乱实验的方式:
- 用户使用YAML文件或Kubernetes客户端,创建或更新混乱对象到Kubernetes API服务器。
- Chaos Mesh使用API服务器来监视混沌对象,并通过创建,更新或删除事件来管理混沌实验的生命周期。控制器管理器,chaos-daemon和sidecar容器一起工作以注入错误。
- 当admission-webhooks收到Pod创建请求时,将动态更新要创建的Pod对象。例如,将其注入边车容器和Pod中。
运行混乱
现在让我们开始展示如何使用Chaos Mesh。请注意,混乱的测试时间可能会有所不同,具体取决于要测试的应用程序的复杂性以及CRD中定义的测试计划规则。
准备环境
Chaos Mesh在Kubernetes v1.12或更高版本上运行。Helm是Kubernetes的软件包管理工具,用于部署和管理Chaos Mesh。在运行Chaos Mesh之前,请确保在Kubernetes集群中正确安装了Helm。要设置环境,请执行以下操作:
- 确保你具有Kubernetes集群。如果已经有,请跳至步骤2;否则,请使用Chaos Mesh提供的脚本在本地启动一个:
// install kind curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.6.1/kind-$(uname)-amd64 chmod +x ./kind mv ./kind /some-dir-in-your-PATH/kind // get script git clone https://github.com/pingcap/chaos-mesh cd chaos-mesh // start cluster hack/kind-cluster-build.sh
注意:本地启动Kubernetes集群会影响与网络相关的故障注入。
git clone https://github.com/pingcap/chaos-mesh.git cd chaos-mesh // create CRD resource kubectl apply -f manifests/ // install chaos-mesh helm install helm/chaos-mesh --name=chaos-mesh --namespace=chaos-testing
等待所有组件安装完毕,然后检查安装状态:
// check chaos-mesh status kubectl get pods --namespace chaos-testing -l app.kubernetes.io/instance=chaos-mesh
如果安装成功,则可以看到所有Pod已启动并正在运行。现在,该玩了。
你可以使用YAML定义或Kubernetes API运行Chaos Mesh。
使用YAML文件运行混乱
你可以通过YAML文件方法定义自己的混乱实验,该方法提供了一种在部署应用程序后进行混乱实验的快速便捷的方法。
要使用YAML文件运行混乱,请执行以下步骤。
注意:出于说明目的,我们将TiDB用作我们的测试系统。你可以使用自己选择的目标系统,并相应地修改YAML文件。
- 部署一个名为“ chaos-demo-1”的TiDB集群。你可以使用TiDB Operator来部署TiDB。
- 创建名为“ kill-tikv.yaml”的YAML文件,并添加以下内容:
apiVersion: pingcap.com/v1alpha1 kind: PodChaos metadata: name: pod-kill-chaos-demo namespace: chaos-testing spec: action: pod-kill mode: one selector: namespaces: - chaos-demo-1 labelSelectors: "app.kubernetes.io/component": "tikv" scheduler: cron: "@every 1m"
- 保存文件。
- 要开始混乱,kubectl apply -f kill-tikv.yaml。
以下混乱实验模拟了在“ chaos-demo-1”集群中经常被杀死的TiKV Pod:
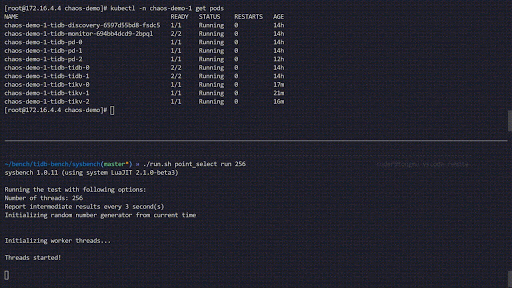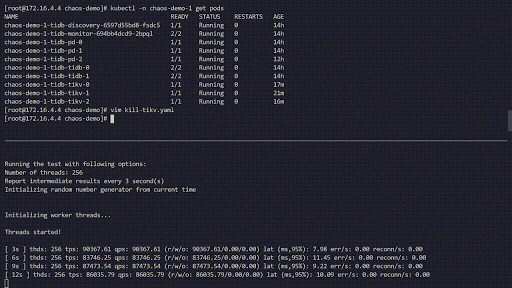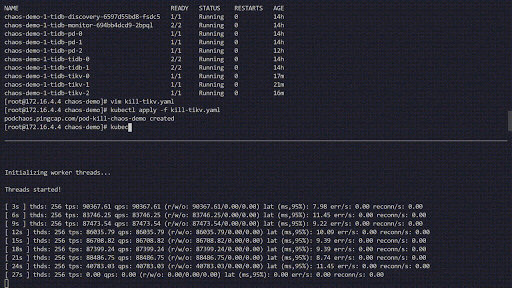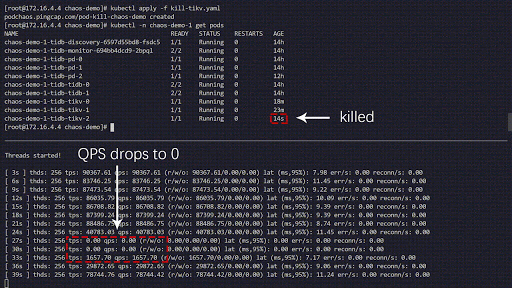
混沌实验运行
我们使用sysbench程序来监视TiDB集群中的实时QPS变化。当我们向集群中注入错误时,QPS会显示剧烈的抖动,这意味着已删除特定的TiKV Pod,然后Kubernetes重新创建了一个新的TiKV Pod。
你可以在此处找到更多YAML文件示例。
使用Kubernetes API运行混乱
Chaos Mesh使用CRD定义混沌对象,因此你可以直接通过Kubernetes API操作CRD对象。这样,通过自定义的测试场景和自动混沌实验,将Chaos Mesh应用于你自己的应用程序非常方便。
在这个测试基础项目中,我们模拟了Kubernetes上ETCD集群中的潜在错误,包括节点重启,网络故障和文件系统故障。
以下是使用Kubernetes API的Chaos Mesh示例脚本:
import ( "context" "github.com/pingcap/chaos-mesh/api/v1alpha1" "sigs.k8s.io/controller-runtime/pkg/client" ) func main() { ... delay := &chaosv1alpha1.NetworkChaos{ Spec: chaosv1alpha1.NetworkChaosSpec{...}, } k8sClient := client.New(conf, client.Options{ Scheme: scheme.Scheme }) k8sClient.Create(context.TODO(), delay) k8sClient.Delete(context.TODO(), delay) }
Chaos Mesh未来何去何从?
本文向你介绍了Chaos Mesh,这是一个开源的云原生Chaos Engineering平台。仍有许多工作正在进行中,还有更多有关设计,用例和开发的详细信息。敬请关注。
开源仅仅是一个起点。除了我们前面讨论的基础架构级别的混乱实验之外,我们还在以更精细的粒度支持更广泛的故障类型,例如:
- 在eBPF和其他工具的帮助下,在系统调用和内核级别注入错误。
- 通过集成failpoint将特定的错误类型注入应用程序功能和语句级别,这将覆盖传统注入方法无法实现的方案。
展望未来,我们将不断改进Chaos Mesh仪表板,以便用户可以轻松查看故障注入是否以及如何影响其在线业务。此外,我们的路线图还包括一个易于使用的故障协调界面。我们正在计划其他很棒的功能,例如Chaos Mesh Verifier和Chaos Mesh Cloud。
GitHub:https : //github.com/pingcap/chaos-mesh
译文链接: https://dzone.com/articles/chaos-mesh-a-chaos-engineering-solution-for-system

登录后评论
立即登录 注册