
StatefulSet是k8s中有状态应用管理的标准实现,今天就一起来了解下其背后设计的场景与原理,从而了解其适用范围与场景
1. 基础概念
首先介绍有状态应用里面的需要考虑的一些基础的事情,然后在下一章我们再去看statefulSet的关键实现
1.1 有状态与无状态
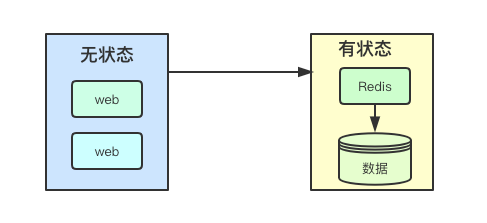
在日常开发的应用中,通常可以分为两大类:有状态与无状态,比如web服务通常都是无状态的,web应用数据主要来自后端存储、缓存等中间件,而本身并不保存数; 而诸如redis、es等其数据也是应用自身的一部分,由此可以看出有状态应用本身会包含两部分:应用与数据
1.2 一致性与数据
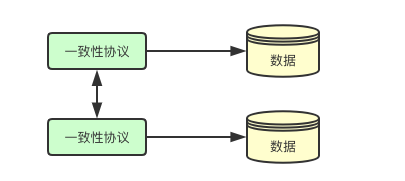
一致性是分布式系统中很常见的问题,上面提到有状态应用包含数据部分,那数据和一致性是不是一个东西呢?答案是并不一定,在诸如zookeeper等应用中,会通过zab协议保证数据写入到集群中的大多数节点, 而在诸如kafka之类的应用其一致性设计要求相对较低,由此可以看出有状态应用数据的一致性,更多的是由对应场景的系统设计而决定
1.3 身份标识
在一些应用中身份标识是系统本身组成的一部分,比如zookeeper其通过server的id来影响最终的zab协议的选举,在kafka中分区的分配时也是按照对应的id来分配的
1.4 单调有序更新
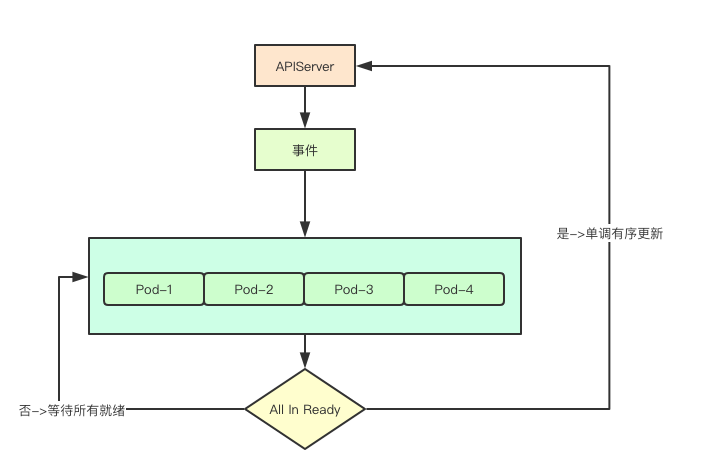
通常分布式系统中都至少要保证分区容忍性,以防止部分节点故障导致整个系统不可用,在k8s中的statefulset中的 Pod的管理策略则是保证尽可能安全的逐个Pod更新,而不是并行启动或停止所有的Pod
1.5 扩缩容与故障转移
在k8s中水平方向上的扩容和缩容都非常简单,删除和添加一个Pod的事情,但是对于有状态应用,其实就不知这些,比如扩容后的数据如何做平衡,节点失败后的故障转移怎么做,这些都是要一个有状态应用需要自己考虑的事情
2. 核心实现
StatefulSet的实现机制整体流程相对简明,接下来按照Pod管理、状态计算、状态管理、更新策略这几部分来依次讲解
2.1 Pod的release与adopt
statefulSet中的pod的名字都是按照一定规律来进行设置的, 名字本身也有含义, k8s在进行statefulset更新的时候,首先会过滤属于当前statefulset的pod,并做如下操作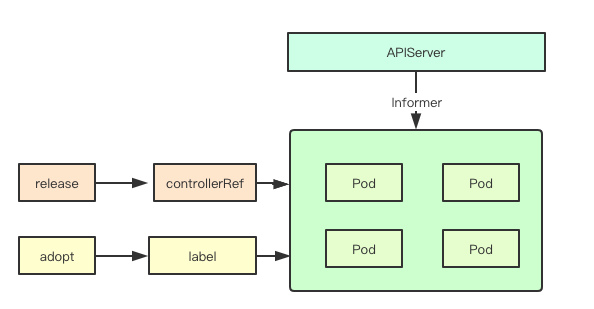
K8s中控制器与Pod的关联主要通过两个部分:controllerRef和label, statefulset在进行Pod过滤的时候,如果发现对应的pod的controllerRef都是当前的statefulset但是其label或者名字并不匹配,则就会尝试release对应的Pod
反之如果发现对应Pod的label和名字都匹配,但是controllerRef并不是当前的statefulSet就会更新对应的controllerRef为当前的statefulset, 这个操作被称为adopt
通过该流程可以确保当前statefulset关联的Pod要么与当前的对象关联,要么我就释放你,这样可以维护Pod的一致性,即时有人修改了对应的Pod则也会调整成最终一致性
2.2 副本分类
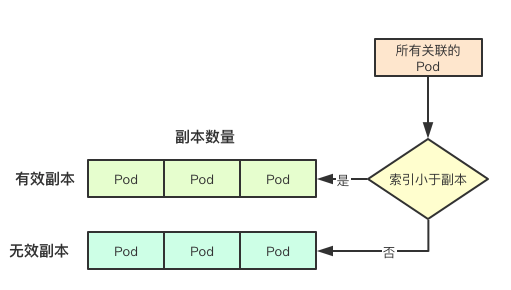
在经过第一步的Pod状态的修正之后,statefulset会遍历所有属于自己的Pod,同时将Pod分为两个大类:有效副本和无效副本(condemned),前面提到过Pod的名字也是有序的即有N个副本的Pod则名字依次是{0…N-1}, 这里区分有效和无效也是依据对应的索引顺序,如果超过当前的副本即为无效副本
2.3 单调更新
单调更新主要是指的当对应的Pod管理策略不是并行管理的时候,只要当前Replicas(有效副本)中任一一个Pod发生创建、终止、未就绪的时候,都会等待对应的Pod就绪,即你要想更新一个statefulset的Pod的时候,对应的Pod必须已经RunningAndReady
func allowsBurst(set *apps.StatefulSet) bool {
return set.Spec.PodManagementPolicy == apps.ParallelPodManagement
}
2.4 基于计数器的滚动更新

滚动更新的实现相对隐晦一点,其主要是通过控制副本计数来实现,首先倒序检查对应的Pod的版本是否是最新版本,如果发现不是,则直接删除对应的Pod,同时将currentReplica计数减一,这样在检查对应的Pod的时候,就会发现对应的Pod的不存在,就需要为对应的Pod生成新的Pod信息,此时就会使用最新的副本去更新
func newVersionedStatefulSetPod(currentSet, updateSet *apps.StatefulSet, currentRevision, updateRevision string, ordinal int) *v1.Pod {
// 如果发现当前的Pod的索引小于当的副本计数,则表明当前Pod还没更新到,但实际上可能因为别的原因
// 需要重新生成Pod模板,此时仍然使用旧的副本配置
if currentSet.Spec.UpdateStrategy.Type == apps.RollingUpdateStatefulSetStrategyType &&
(currentSet.Spec.UpdateStrategy.RollingUpdate == nil && ordinal < int(currentSet.Status.CurrentReplicas)) ||
(currentSet.Spec.UpdateStrategy.RollingUpdate != nil && ordinal < int(*currentSet.Spec.UpdateStrategy.RollingUpdate.Partition)) {
pod := newStatefulSetPod(currentSet, ordinal)
setPodRevision(pod, currentRevision)
return pod
}
// 使用新的配置生成新的Pod配置
pod := newStatefulSetPod(updateSet, ordinal)
setPodRevision(pod, updateRevision)
return pod
}
2.5 无效副本的清理
无效副本的清理应该主要是发生在对应的statefulset缩容的时候,如果发现对应的副本已经被遗弃,就会直接删除,此处默认也需要遵循单调性原则,即每次都只更新一个副本
2.6 基于删除的单调性更新
if getPodRevision(replicas[target]) != updateRevision.Name && !isTerminating(replicas[target]) {
klog.V(2).Infof("StatefulSet %s/%s terminating Pod %s for update",
set.Namespace,
set.Name,
replicas[target].Name)
err := ssc.podControl.DeleteStatefulPod(set, replicas[target])
status.CurrentReplicas--
return &status, err
}
Pod的版本检测位于对应一致性同步的最后,当代码走到当前位置,则证明当前的statefulSet在满足单调性的情况下,有效副本里面的所有Pod都是RunningAndReady状态了,此时就开始倒序进行版本检查,如果发现版本不一致,就根据当前的partition的数量来决定允许并行更新的数量,在这里删除后,就会触发对应的事件,从而触发下一个调度事件,触发下一轮一致性检查
2.7 OnDelete策略
if set.Spec.UpdateStrategy.Type == apps.OnDeleteStatefulSetStrategyType {
return &status, nil
}
StatefulSet的更新策略除了RollingUpdate还有一种即OnDelete即必须人工删除对应的 Pod来触发一致性检查,所以针对那些如果想只更新指定索引的statefulset可以尝试该策略,每次只删除对应的索引,这样只有指定的索引会更新为最新的版本
2.8 状态存储
状态存储其实就是我们常说的PVC,在Pod创建和更新的时候,如果发现对应的PVC的不存在则就会根据statefulset里面的配置创建对应的PVC,并更新对应Pod的配置
3. 有状态应用总结
从核心实现分析中可以看出来,有状态应用的实现,实际上核心是基于一致性状态、单调更新、持久化存储的组合,通过一致性状态、单调性更新,保证期望副本的数量的Pod处于RunningAndReady的状态并且保证有序性,同时通过持久化存储来进行数据的保存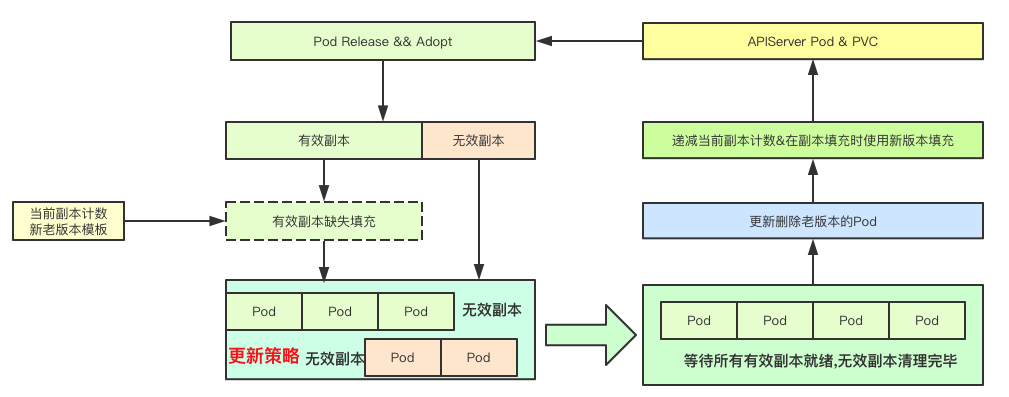
有序的重要性,在分布式系统中比较常见的两个设计就是分区和副本,其中副本主要是为了保证可用性,而分区主要是进行数据的平均分布,二者通常都是根据当前集群中的节点来进行分配的,如果我们节点短暂的离线升级,数据保存在对应的PVC中,在恢复后可以很快的进行节点的信息的恢复并重新加入集群,所以后面如果开发这种类似的分布式应用的时候,可以将底层的恢复和管理交给k8s,数据保存在PVC中,则应用更多的只需要关注系统的集群管理和数据分布问题即,这也是云原生带来的改变
今天就到这里,好久没更新了,读源码的过程不易,欢迎帮转发分享交流,一起进步
kubernetes学习笔记地址: https://www.yuque.com/baxiaoshi/tyado3
微信号:baxiaoshi2020 公共号: 图解源码 欢迎一起交流学习分享

登录后评论
立即登录 注册