
Kubernetes 是一门极其智能化的科学技术,但是如果搞错了方向,它就会以一种非预期的方式响应. 对于大部分 “聪明的” 科技来说, 其智能化程度取决于操作者。 为了通过使用Kubernetes组建团队来达到成功巅峰,其中最关键的是每一位组员能清晰地掌握Kubernetes 集群。这里有5种方法可以使工程师在建立Kubernetes集群时能最好的鉴定出任何未结的任务,并且尽可能确保负载在最健康的水平(想要更深入的了解 Kubernetes 的可观察性,请查阅我们的电子书 Kubernetes Observability)。
幸运的是, 在 Kubernetes 环境中有技术可以收集日志、性能指标、事件和安全警告,从而帮助我们模拟各种集群的健康水平。这些收集器从Kubernetes 集群的所有组件中收集数据,它们汇集起来可以得到一个 集群健康状况的 高层级的视图, 并且可以及时深入的了解诸如 资源(resource), 使用性能(utilization), 配置(configuration)错误和其他问题。
1. 在所有的pod库中设置 CPU requests(请求)和limits(限额)
requests(请求)和limits(限额)是k8s的一种机制,该机制用来给pods 自动分配 像CPU和内存使用量这样的可用资源 。CPU 是用毫核来定义的, 所以1000毫核等于1核。requests(请求)是预期给定容器所需要的资源使用量,limits(限额), 换句话说,就是一个容器被允许使用的资源量的实际上限。

确保所有的pods 都指定requests(请求)。一个最佳的实践是给这些pods 指定1核或者更少,如果需要更多算力的话,就添加额外的副本。还有很重要的需要注意的一点, 如果你配置的太高, 比如2000毫核(2核),但是只有1核可用,那么这个pod将永远不会被调度。 在第5步中,我会告诉你如何去重复确认哪些未被调度的pods。
确保所有的pods 都有CPUlimits(限额)。 如上面提到的,limits(限额)是上限, 所以Kubernetes不允许pod 使用超出limits(限额)所定义的CPU 数量。即便如此,CPU 有点宽容,因为它被认为是一种可压缩资源。如果pod 达到CPU limits(限额), 它将不会被终止, 而是被限制。你的CPU将被限制,所以你可能会遇到性能问题。
2. 在所有的pods 上设置内存requests(请求)和limits(限额) 
确保为所有pod设置了内存requests(请求):内存requests(请求)是指你认为pod将消耗多少数据。与CPU一样,如果内存requests(请求)大于最大节点,Kubernetes也不会调度pod。
确保为所有pod设置了内存limits(限额):内存limits(限额)是允许pod使用多少内存的硬上限。与CPU不同,内存是不可压缩的,不能被限制。如果一个容器超过了它的内存limits(限额),那么它将被终止。
3.审核资源配额
Kubernetes的最佳健康状况的另一检查项是— 是否不足或过度配置资源。如果可用CPU和内存过剩,那么消耗不足,很可能有浪费。另一方面,如果接近100%的利用率,则在需要扩展或有意外负载时可能会遇到问题。
检查剩余的pod容量。一个有用的Kubernete衡量标准是“kube_node_status_allocatable”,这是Kubernetes在给定平均pod资源利用率的情况下,对一个节点将容纳多少个pod的估计。我们可以把剩余的pod容量加起来,粗略估计一下在不遇到问题的情况下可以扩展多少。
检查总的CPU使用率百分比、请求的CPU百分比与CPU limits(限额)百分比:总的CPU使用率表示现在使用了多少,requests(请求)表示预计可能需要多少,而limits(限额)是我们设置的硬性上限。
在下面的例子中,我们只使用了可用算力的2.5%,供应远超实际使用量,而且还可能会减少。相比之下,我们的CPUrequests(请求)是46%,因此我们原以为我们可能需要用到的比实际使用的要多得多。(出现这种情况)要么是预估错误,要么就是有计划以外的突发需求。
最后,我们的CPU Burstable告诉我们所有的CPU limits(限额)总和。由于其低于requests(请求)的CPU资源量,我们可能要回去检查我们的限制设置。要么是我们对每一个pod都没有设置limits(限额),要么我们的limits(限额)配置错误。
检查总内存使用量百分比、内存requests(请求)百分比与内存limits(限额)百分比。就和检查CPU一样,我们可以检查内存是否配置过大。仅仅3.8%的利用率告诉我们,我们的确实供应过剩了,但我们可以舒适地长期扩展。

4. 检查节点间的Pod分布
当我们研究pod是如何在集群中的可用节点上分配时,我们想要一个大致均等的分配。如果某些节点完全超载或欠载,这可能意味着一个值得调查的更大问题出现了。
需要检查的一些可能导致分配不均的因素包括:
节点亲和力(node affinity)。 亲和力(Affinity)是一个pod设置项,使它们偏好具有某些属性的节点。例如,某些pod可能需要在带有GPU或SSD的计算机上运行,或者某些pod可能需要具有特定安全隔离或特定策略的节点。重复检查关联设置可以帮助缩小 导致不均匀分配的原因的范围,并降低严峻问题发生的可能性。
污点(taints)和容忍(tolerations)。污点与亲和力相反。这些是节点的设置项,给节点设置污点,从而使pod 难以调度到这些节点。如果要为特定pod保留节点,或者为了确保该节点上的pod对可用资源具有完全访问权限,则可以使用此选项。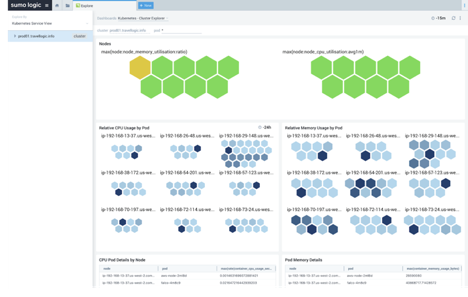 limits(限额)和requests(请求):回顾limits(限额)和requests(请求)设置项。这常常是问题的起因,以至于它值得在本文的三个部分中提及。如果调度器没有关于pods需要什么的正确信息,那么它的调度工作将会做的很差。
limits(限额)和requests(请求):回顾limits(限额)和requests(请求)设置项。这常常是问题的起因,以至于它值得在本文的三个部分中提及。如果调度器没有关于pods需要什么的正确信息,那么它的调度工作将会做的很差。
5.检查pod是否处于不良状态
在Kubernetes环境中,当前的状态每时每刻都在变化,因此过度关注每一个终止的pod会慢慢侵蚀你的时间和理智。然而,为了确保它与您基于当前集群中的事件来作出的预期相符。以下所列项值得关注。 
*Nodes not ready:节点可能由于多种原因而进入此状态,但通常是因为内存或磁盘空间不足。
*Unscheduled pods:pod通常会由于调度器无法满足CPU或内存requests(请求) 而以未被调度的状态终止。重复检查你的集群是否有足够的podsrequests(请求)的可用资源。
*Pods that failed to create :Pods在创建时失败,通常是因为镜像问题,比如启动脚本依赖项缺失。这种情况,建议回到原点。
*Container restarts:只有一部分容器重启是不用担心的,但当你看到大量的(容器重启)则可能意味着pod处于OOMKill(内存不足而被杀死)状态。内存不足是Kubernetes中最常见的错误(error)之一,可能是由于镜像问题、及其引发的依赖问题或意外、limits(限额)和requests(请求)问题引起的。
这些集群健康的最佳实践可以限制Kubernetes环境中的意外行为,并确保您不会在将来遇到可伸缩性问题。这些也是帮你回答那些无定形问题的一个起点,比如,“我的Kubernetes集群健康吗?”,如果所有这些项都是绿色的,那么您的集群可能非常健康,那么您可以轻松休息了。
想要更深入的了解 Kubernetes 的可观察性,请查阅我们的电子书 Kubernetes Observability

登录后评论
立即登录 注册