

如果你使用Kubernetes 的时间足够长,那么你肯定需要对其进行调试,但它是一个分布式系统,有很多组件,有时组件很难理解。在这篇文章中,我将介绍八个命令来调试Kubernetes 集群,它将帮助你了解集群并确保运行 Pod 的核心功能可用。
这篇文章将假设你拥有集群的管理员访问权限。我们将假设你收到了一个可以访问集群的 kubeconfig 文件,但你被告知集群已损坏。你从哪里开始?
以下是要运行的八个命令:
kubectl version --short kubectl cluster-info kubectl get componentstatus kubectl api-resources -o wide --sort-by name kubectl get events -A kubectl get nodes -o wide kubectl get pods -A -o wide kubectl run a --image alpine --command -- /bin/sleep 1d
接下来,让我们分别解释每个命令。对于集群调试,在深入研究工作负载之前,我们将采用广度优先的方法来了解集群中的内容。
1. kubectl version –short

使用此命令,我们将查看正在运行的 API 服务器版本。这为我们稍后对特定错误进行故障排除时提供了重要信息。
了解版本还可以帮助我们搜索错误和阅读变更日志。可能存在需要版本升级或新引入的错误的已知问题。有时不同组件之间存在版本兼容性问题,了解运行的是哪个版本是第一步。
2. kubectl cluster-info

接下来我们应该了解集群在哪里运行以及 CoreDNS 是否正在运行。你可以通过解析控制平面 URL 以了解你是在处理托管集群还是内部部署的集群。
在此示例输出中,我们可以看出我们正在us-east-2 区域运行Amazon Elastic Kubernetes Service (Amazon EKS) 集群。如果你的提供商当前突然出现宕机,此信息对于查找也很有用。你可以查看提供商的服务运行状况仪表板,了解当前问题是与你的集群有关还是与集群之外的其他问题有关。
如果集群需要额外的身份验证,这也可以为你提供线索。可能存在 AWS Identity and Access Management (IAM) 权限问题,或者你可能需要安装身份验证插件,例如aws-iam-authenticator。
3. kubectl get componentstatus

此命令将是发现你的调度程序、控制器管理器和 etcd 节点是否健康的最简单方法。这些都是运行 Pod 的关键控制平面组件。你应该查找任何未显示“ok”状态的组件并查找任何错误。
如果你使用具有托管控制平面的集群(例如 Amazon EKS),你可能无法直接访问调度程序或控制器管理器。
能够从这个输出中看到它们的状态可能是了解 etcd 或其他组件是否有问题的最简单方法。同样重要的是要注意,该componentstatus命令在 CLI 中已弃用,但尚未删除。此命令目前没有替代品,但在从 CLI 中删除之前,它可以安全使用且非常有用。根据你的集群,可能需要多个命令才能获得类似的输出。此命令存在设计限制,这就是它已被弃用的原因。
查看其他健康端点(包括 etcd)的另一种选择是kubectl get –raw ‘/healthz?verbose’:
 尽管此命令不显示调度程序或控制器管理器的输出,但它添加了许多额外的检查,如果出现问题,这些检查可能很有价值。
尽管此命令不显示调度程序或控制器管理器的输出,但它添加了许多额外的检查,如果出现问题,这些检查可能很有价值。
4. kubectl api-resources -o wide –sort-by name
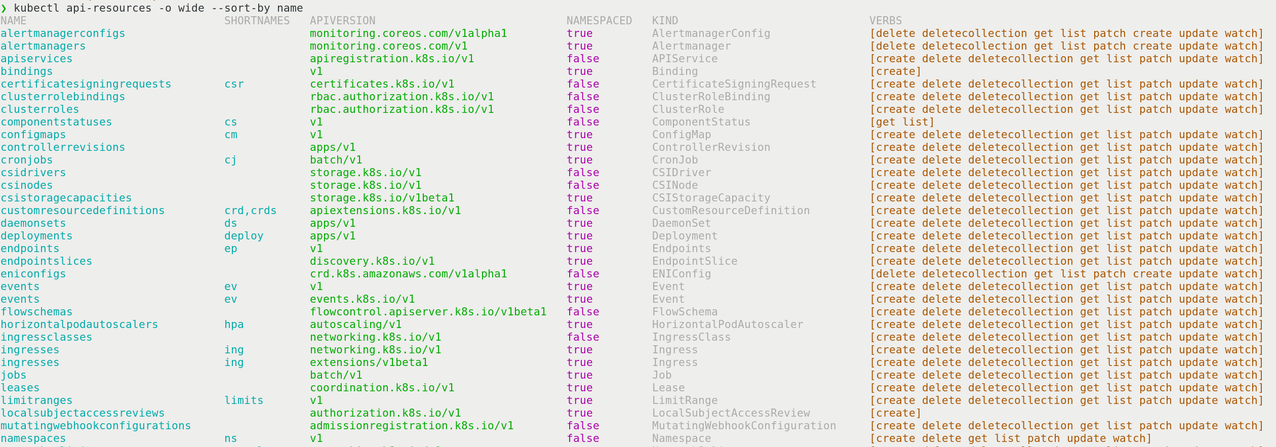
这是第一个包含大量信息的命令。我们已经知道集群运行的版本和位置。至此,我们应该知道控制平面是否健康了,现在我们需要查看集群内部的一些资源。
我喜欢列出按名称排序的所有资源以保持一致性。按字母顺序浏览资源对我来说更容易。添加-o wide将显示每个资源上可用的动词。这可能很重要,因为某些资源比其他资源做得更多。了解哪些动词可用或不可用,将有助于缩小你应该查找错误的范围。
使用此命令将告诉你集群中安装了哪些 CRD(自定义资源定义)以及每个资源的 API 版本。这可以让你深入了解控制器或工作负载定义上的日志。你的工作负载可能使用旧的 alpha 或 beta API 版本,但集群可能只能使用 v1 或 apps/v1。
5. kubectl get events -A
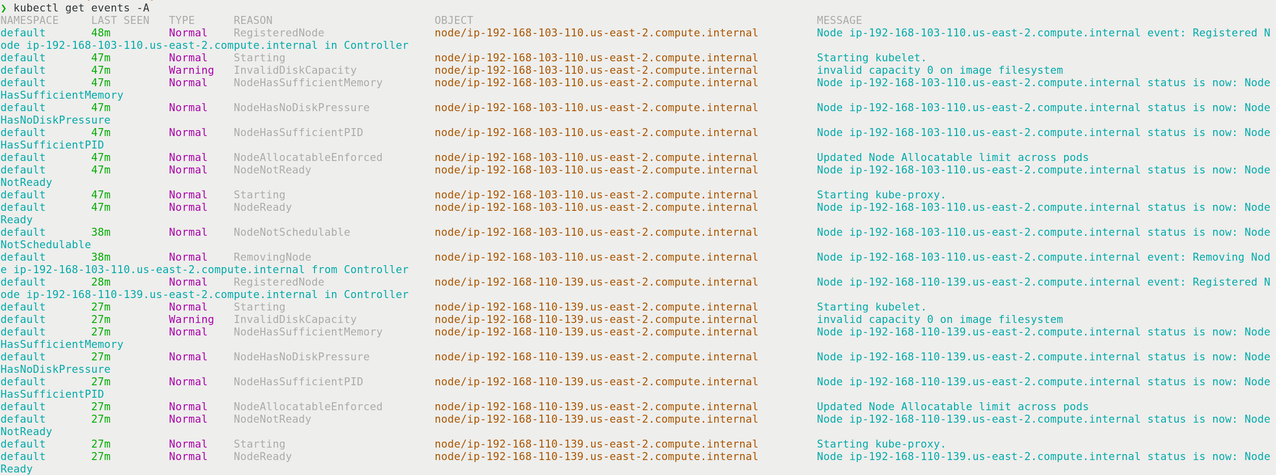
现在我们已经了解了集群中正在运行的内容,我们应该看看发生了什么。如果最近出现故障,你可以查看集群事件以了解故障前后发生的情况。如果你知道只有特定名称空间中存在问题,你可以将事件过滤到该名称空间,并屏蔽来自健康服务的一些额外噪音。
有了这个输出,你应该关注输出的类型、原因和对象。通过这三条信息,你可以缩小要查找的错误以及可能配置错误的组件的范围。
6. kubectl get nodes -o wide

节点是 Kubernetes 中的一流资源,是 Pod 运行的基础。使用该-o wide选项将告诉我们其他详细信息,例如操作系统 (OS)、IP 地址和容器运行时。你应该寻找的第一件事是状态。如果节点没有显示“Ready”,你可能会遇到问题,但并非总是如此。
查看节点的运行时长,以查看状态和运行时长之间是否存在任何相关性。也许只有新节点有问题,因为节点镜像中的某些内容发生了变化。该版本将帮助你快速了解 kubelet 上是否存在版本偏差,以及是否存在由于 kubelet 和 API 服务器之间的版本不同而导致的已知错误。
如果你看到子网之外的 IP 地址,则内部 IP 会很有用。一个节点可能以不正确的静态 IP 地址启动,并且你的 CNI 无法将流量路由到工作负载。
操作系统镜像、内核版本和容器运行时都是可能导致问题的差异的重要指标。你可能只遇到特定操作系统或运行时的问题。此信息将帮助你快速将潜在问题归零,并知道在何处更深入地查看日志。
7. kubectl get pods -A -o wide

列出节点一样,你应该首先查看状态列并查找错误。Ready列将显示需要多少个 Pod 以及有多少个正在运行。
使用-A将列出所有命名空间中的 pod,通过-o wide将向我们显示 IP 地址、节点以及 pod 的指定位置。使用来自列出节点的信息,你可以查看哪些 Pod 在哪些节点上出现故障。将该信息与操作系统、内核和容器运行时等详细信息相关联,可能会为你提供修复集群所需的见解。
8. kubectl run d –image alpine –command — /bin/sleep 1d
有时,调试某些东西的最好方法是从最简单的示例开始。此命令没有任何直接输出,但你应该从中看到一个名为a的正在运行的 pod。
如果我不与其他人一起调试某些东西,我喜欢将我的容器命名为单个字母,因为它输入速度更快,并且易于迭代(例如 b、c、d)。我经常喜欢在调试时保留旧容器,因为有时查看与以前 pod 的不同之处会很有帮助,而且让它们继续运行或崩溃比搜索我的终端输出历史记录更容易。

如果出于某种原因,如果你没有从该命令中看到正在运行的 pod,那么 使用kubectl describe po a是你的下一个最佳选择。查看事件以查找可能出错的错误。

总结
使用这些命令,你应该能够知道集群是否足够健康以运行工作负载。还有其他需要考虑的事情,例如 CoreDNS 扩展、负载均衡、存储卷以及日志记录和指标。
如果你需要对节点或外部资源(例如负载均衡器)进行故障排除,那么你应该查看你的控制器和 API 服务器日志以查找错误。根据日志,你可能需要查看 kube-proxy、CNI 插件或服务网格 sidecar 容器日志。
希望这八个命令将帮助你缩小集群中可能被破坏的范围。如果你不知道问题出在哪里,那么从广度优先搜索开始。注意不匹配的版本和节点或不同设置的异常。如果你寻找发生了什么变化,它可以为你指明正确的方向,以快速找到并解决问题。我们将在以后的文章中介绍如何调试集群中的工作负载。
译文链接: https://thenewstack.io/living-with-kubernetes-debug-clusters-in-8-commands/

登录后评论
立即登录 注册