
![]()
![]() 我在上周的教程中介绍了Node和Pod的亲和性/反亲和性。我们将通过一个真实的场景进一步探索这个概念。
我在上周的教程中介绍了Node和Pod的亲和性/反亲和性。我们将通过一个真实的场景进一步探索这个概念。
目标
我们将要在一个四节点的Kubernetes集群中去部署三个微服务 – MySQL,Redis和一个基于Python/Flask框架的web应用程序。我们要确保MySQL这个Pod被调度到同一个节点上,因为其中一个节点已经附加了SSD磁盘,Redis是用来缓存数据库的查询以提高应用程序性能,但是每个节点只运行一个Redis Pod,因为Redis被用作缓存,所以在每个节点上运行多个Redis Pod是没有意义的,下一个目标是确保web应用程序的Pod和Redis Pod运行在同一个节点上,这将确保web应用程序和Redis缓存层之间的低延迟,即使我们扩展了web应用程序Pod的副本数量,它也不会被调度到没有Redis Pod的节点。
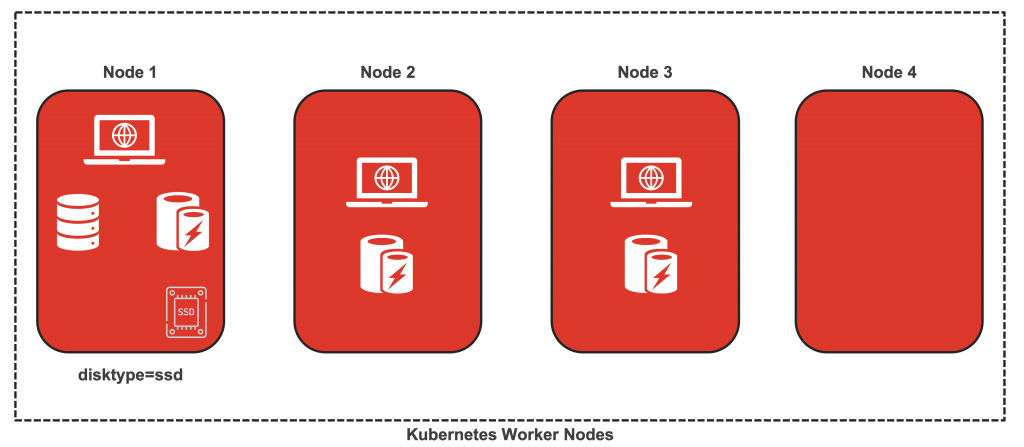
配置一个GKE集群并且增加一块SSD磁盘
我们启动一个GKE集群,附加一块SSD的持久存储的磁盘到集群中其中一个节点上,并且给节点打上标签。
gcloud container clusters create “tns” \–zone “asia-south1-a” \–username “admin” \–cluster-version “1.13.11-gke.14” \–machine-type “n1-standard-4” \–image-type “UBUNTU” \–disk-type “pd-ssd” \–disk-size “50” \–scopes “https://www.googleapis.com/auth/compute”,”https://www.googleapis.com/auth/devstorage.read_only”,”https://www.googleapis.com/auth/logging.write”,”https://www.googleapis.com/auth/monitoring”,”https://www.googleapis.com/auth/servicecontrol”,”https://www.googleapis.com/auth/service.management.readonly”,”https://www.googleapis.com/auth/trace.append” \–num-nodes “4” \–enable-stackdriver-kubernetes \–network “default” \–addons HorizontalPodAutoscaling,HttpLoadBalancing
这将产生一个4节点的GKE集群。
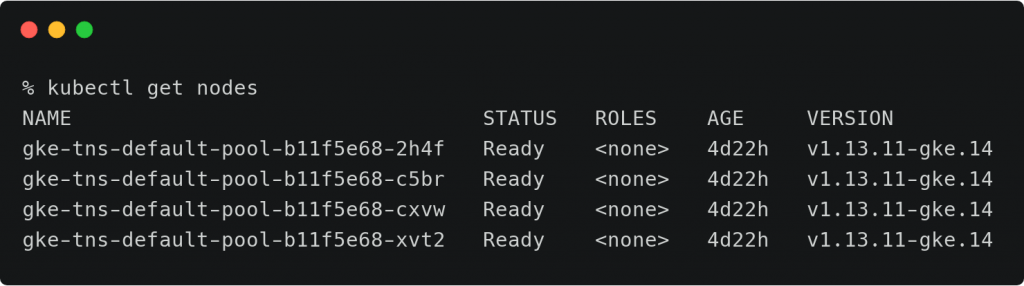
 开始创建一个GCE持久性存储磁盘并且将其附加在GKE集群中的某一个节点上.
开始创建一个GCE持久性存储磁盘并且将其附加在GKE集群中的某一个节点上.
gcloud compute disks create \mysql-disk-1 \–type pd-ssd \–size 20GB \–zone asia-south1-a
gcloud compute instances attach-disk gke-tns-default-pool-b11f5e68-2h4f \–disk mysql-disk-1 \–zone asia-south1-a
我们需要在节点内挂在这快SSD磁盘使应用程序能访问它。
gcloud compute ssh gke-tns-default-pool-b11f5e68-2h4f \–zone asia-south1-a
当你使用SSH登录到GKE节点上后,运行以下命令来挂载磁盘。
sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdbsudo mkdir -p /mnt/datasudo mount -o discard,defaults /dev/sdb /mnt/datasudo chmod a+w /mnt/dataecho UUID=`sudo blkid -s UUID -o value /dev/sdb` /mnt/data ext4 discard,defaults,nofail 0 2 | sudo tee -a /etc/fstab
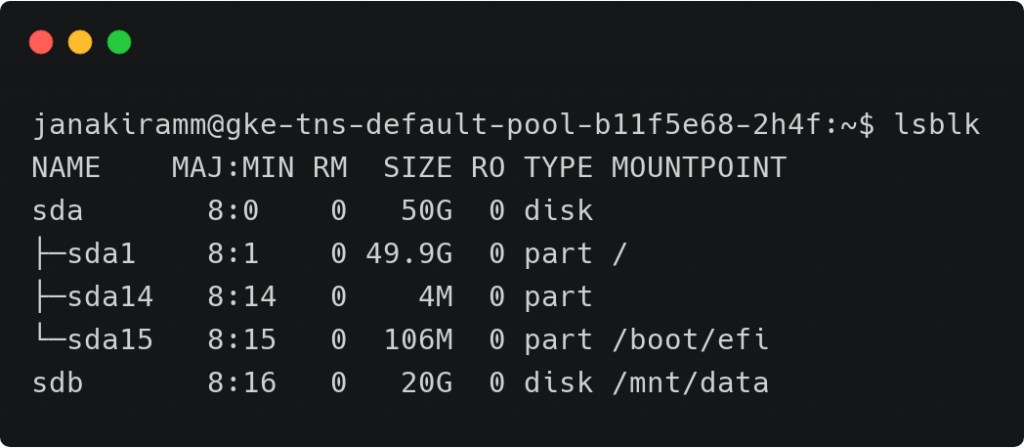
运行 lsblk命令确认磁盘被挂载在 /mnt/data目录
 退出shell后运行以下命令将节点标记为disktype=ssd。
退出shell后运行以下命令将节点标记为disktype=ssd。
kubectl label node gke-tns-default-pool-b11f5e68-2h4f \disktype=ssd –overwrite
验证节点是否确实被标记了。
kubectl get nodes -l disktype=ssd
 开始部署一个数据库Pod
开始部署一个数据库Pod
我们继续在上面被标记disktype=ssd的节点上部署一个MySQL Pod。使用下面的YAML描述配置清单去创建数据库Pod并且将其暴露为一个类型为ClusterIP的服务。
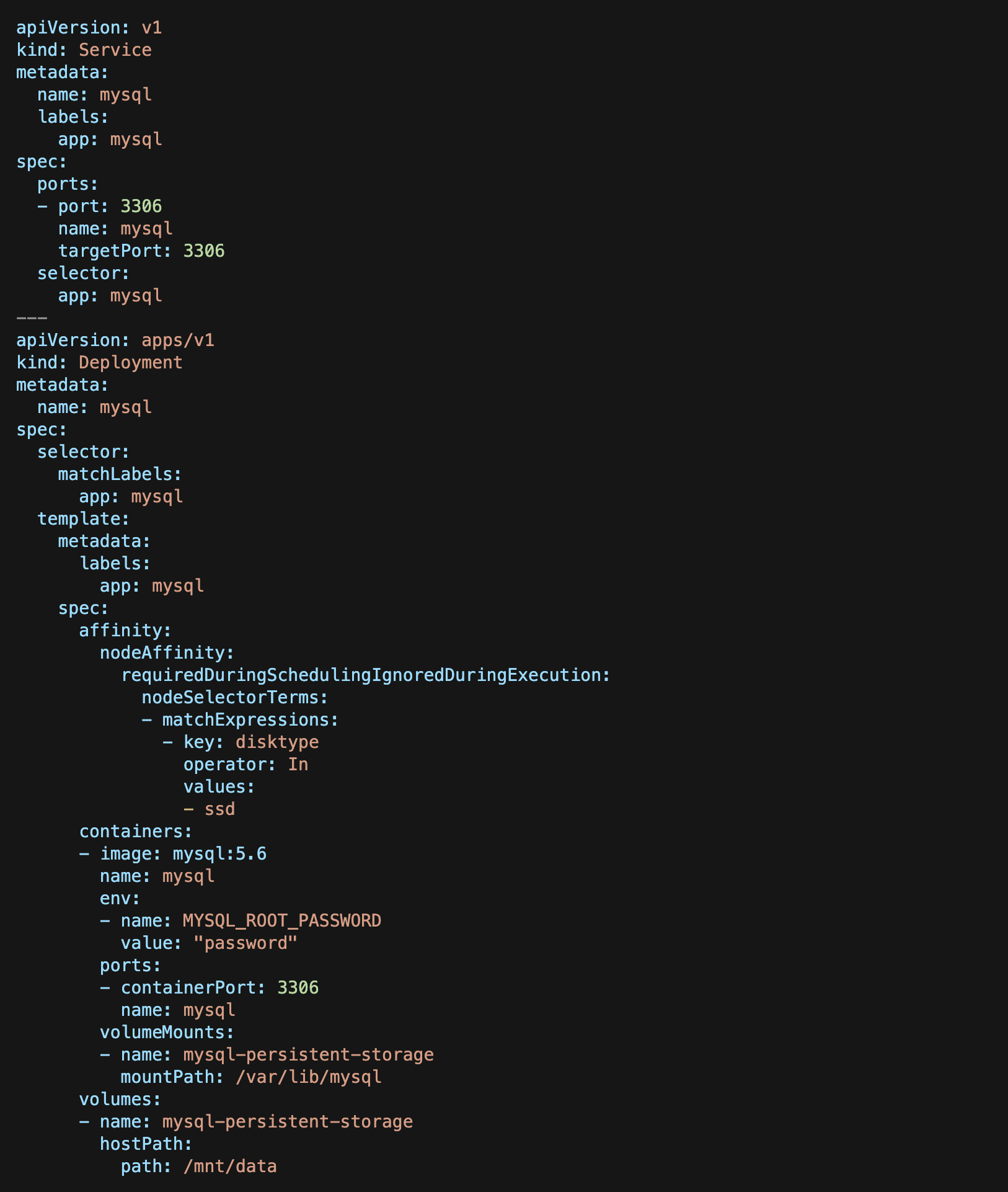
从上面的YAML配置清单中可以注意到,我们首先在YAML配置清单中包含以下配置块来实现Node亲和性:
affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:– matchExpressions:– key: disktypeoperator: Invalues:– ssd
这将确保数据MySQL Pod被调度在带有disktype=ssd标签的节点上,因为我们确保该Pod总是被调度到带有disktype=ssd标签的同一个节点上,我们简单的使用hostPath去创建持久性存储卷,这个 hostPath有一个指向我们之前附加SSD磁盘事被挂在的目录/mnt/data
volumeMounts:– name: mysql-persistent-storagemountPath: /var/lib/mysqlvolumes:– name: mysql-persistent-storagehostPath:path: /mnt/data
我们提交Pod资源的YAML配置清单到kubernetes并且验证该Pod是否真实的调度到匹配标签的节点上。
kubectl apply -f db.yamlkubectl get nodes -l disktype=ssdkubectl get pods -o wide

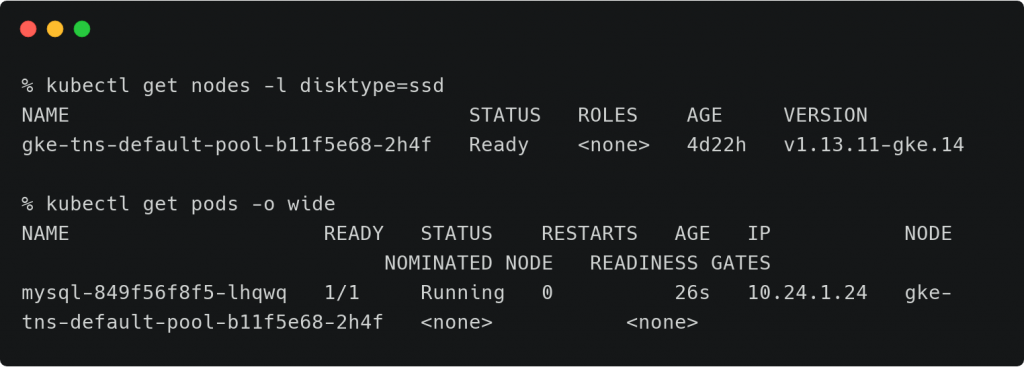
这个Pod很明显被调度到适配Node亲和性规则的节点上。
开始部署缓存Pod
是时候去部署用来充当缓存层的Redis Pod了,我们想确保在同一个节点上只运行一个Redis Pod,为此,我们将定义一个反亲和性的规则。
下面的配置清单使用Deployment对象创建了带有3个副本的Redis Pod并且通过一个ClusterIP来暴露它们。
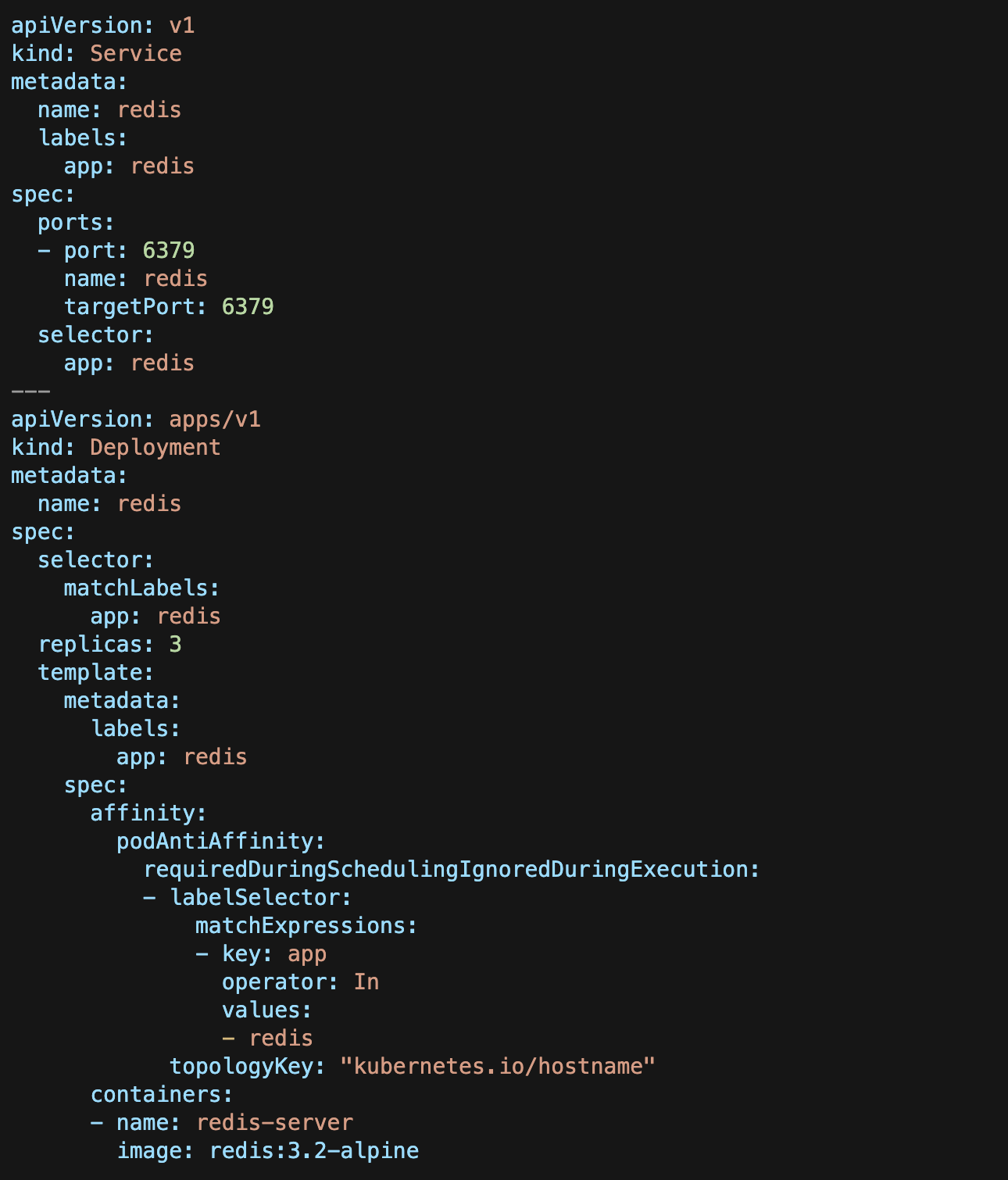
以下配置块确保一个节点运行并且仅运行一个Redis Pod。
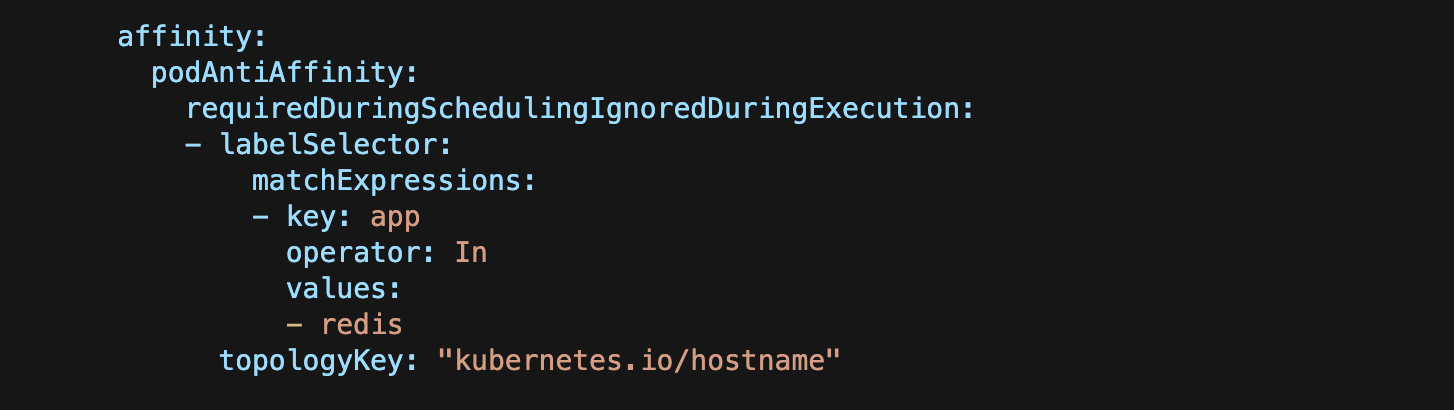
提交Deployment配置清单并且检查Pod的分配。
kubectl apply -f cache.yamlkubectl get pods -l app=redis -o wide


很明显Redis Pod已经被放置在唯一的节点上。
开始部署Web应用程序Pod
最后,我们想去将一个Web Pod放置在和Redis Pod统一个Node节点上。
提交这个Deployment配置清单去创建有三个副本的Web应用程序的Pod并且通过LoadBalancer类型的服务对象来暴露它们。

只有在检查缓存是否可用之后,Web应用程序容器中的镜像才能访问数据库中的行。
我们列出所有的Pods以及它们所被调度到的节点的名称。
kubectl get pods -o wide | awk {‘print $1″ ” $7’} | column -t

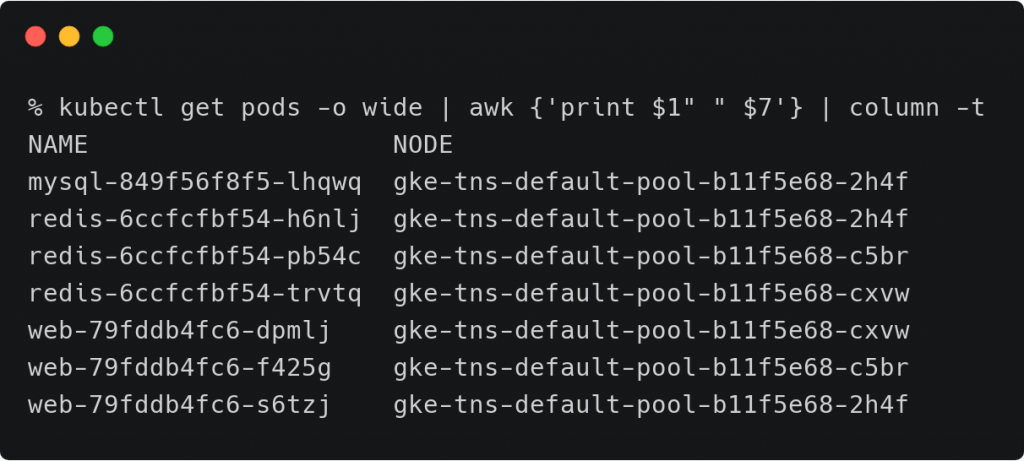
我们可以看到节点gke-tns-default-pool-b11f5e68-2h4f运行着三个Pods – MySQL,Redis和Web,另外两个节点上分别运行一个Redis Pod和Web Pod来降低延迟。
我们来看一下亲和性规则,记住,我们在集群中运行着4个Nodes,其中一个节点上面没有Pod是因为kubernetes调度遵循了Web Pod和Redis Pod运行在同一个节点的原因。
当我们缩放Web Pod的副本数量的时候回发生什么?因为在Web的Deployment部署的反亲和性规则中制定了一个规则,就是一个Node节点上不能运行两个Web Pod,并且每个Web Pod必须与Redis配对,因此调度器不能调度扩展的Pod到任何节点,新扩展的Pod将会永远处于pending状态。尽管事实上有一个节点上面没有运行任何Pod.
kubectl scale deploy/web –replicas=4

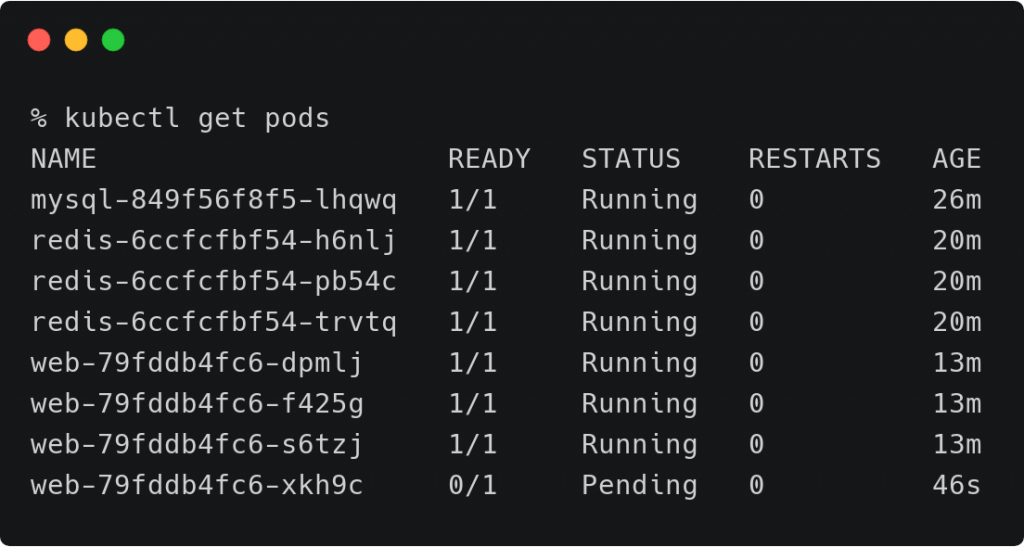
移除Web部署的反亲和性规则然后尝试扩展Web Pod的副本数量,现在Kubernetes可以在任何运行有Redis Pod的节点上调度Web Pod,这将减小对Web Pod部署的限制,允许拥有Redis Pod的节点上运行任意数量的Web Pods.
kubectl get pods -o wide | awk {‘print $1″ ” $7’} | column -t

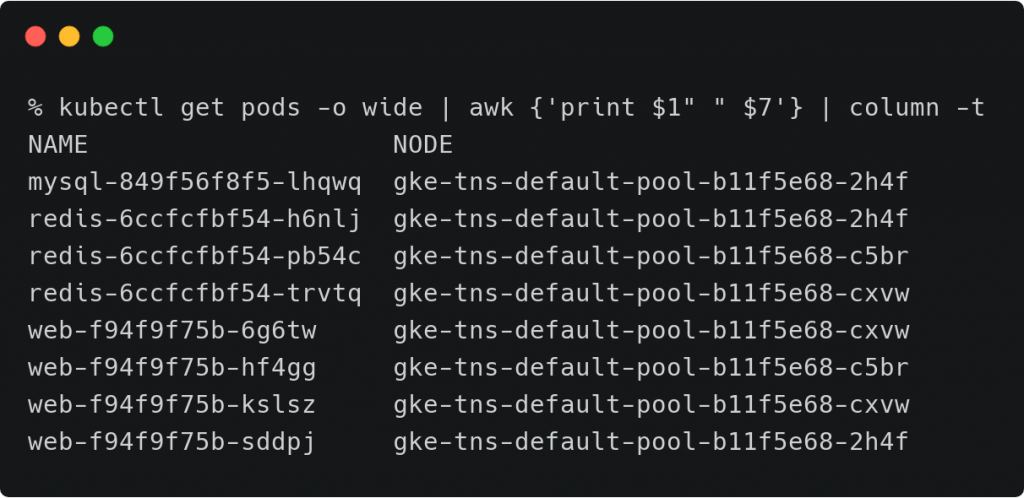
从上面的命令的输出来看,我们注意到节点gke-tns-default-pool-b11f5e68-cxvw运行着两个Web Pod的实例。
但是,由于Pod亲和性/反亲和性规则,集群中的一个节点仍然处于空闲状态。如果你想要使用它,扩展Redis的副本以在空闲节点上运行Pod,然后扩展Web副本将其同样调度到空闲的节点上。 继续这个在同一节点上共治数据库和缓存层的话题,在本系列的下一个部分中,我们将探索在Kubernetes上用 sidecar模式去部署低延迟的微服务。
Janakiram MSV的网络研讨会Machine Intelligence and Modern Infrastructure (MI2)提供了内容丰富且见解深刻的讲座,涵盖了尖端技术。在http://mi2.live上注册即将召开的MI2网络研讨会。 功能图片是由3D动画制作公司Pixabay提供。
原文链接: https://thenewstack.io/implement-node-and-pod-affinity-anti-affinity-in-kubernetes-a-practical-example/

感谢分享。确认一下
1,web和redis亲和在一起以后,如何保证web访问的就是本机上的redis呢?
2,redis的集群是什么模式?sentinel还是主从模式?如何在一个deployment中部署生产级别的redis集群?
谢谢~