
作者 | 杨成立(忘篱) 阿里巴巴高级技术专家
Go 开发关键技术指南文章目录:
- 为什么你要选择 Go?
- Go 面向失败编程
- 带着服务器编程金刚经走进 2020 年
- 敢问路在何方?
Go 开发指南大图
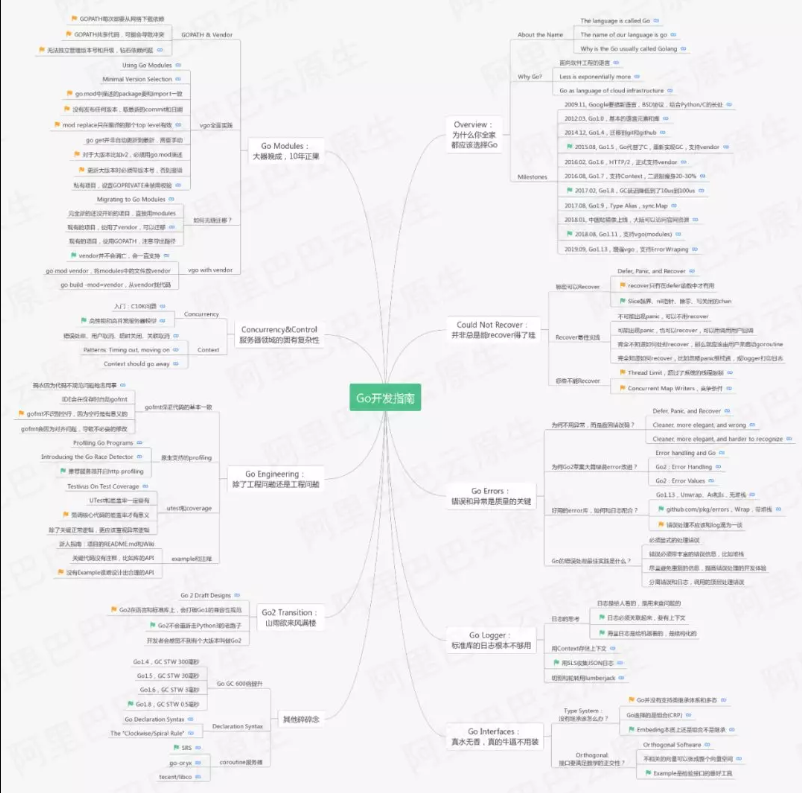
Engineering
我觉得 Go 在工程上良好的支持,是 Go 能够在服务器领域有一席之地的重要原因。这里说的工程友好包括:
- gofmt 保证代码的基本一致,增加可读性,避免在争论不清楚的地方争论;
- 原生支持的 profiling,为性能调优和死锁问题提供了强大的工具支持;
- utest 和 coverage,持续集成,为项目的质量提供了良好的支撑;
- example 和注释,让接口定义更友好合理,让库的质量更高。
GOFMT 规范编码
之前有段时间,朋友圈霸屏的新闻是码农因为代码不规范问题枪击同事,虽然实际上枪击案可能不是因为代码规范,但可以看出大家对于代码规范问题能引发枪击是毫不怀疑的。这些年在不同的公司码代码,和不同的人一起码代码,每个地方总有人喜欢纠结于 if () 中是否应该有空格,甚至还大开怼戒。
Go 语言从来不会有这种争论,因为有 gofmt,语言的工具链支持了格式化代码,避免大家在代码风格上白费口舌。
比如,下面的代码看着真是揪心,任何语言都可以写出类似的一坨代码:
package main import ( "fmt" "strings" ) func foo()[]string { return []string{"gofmt","pprof","cover"}} func main() { if v:=foo();len(v)>0{fmt.Println("Hello",strings.Join(v,", "))} }
如果有几万行代码都是这样,是不是有扣动扳机的冲动?如果我们执行下 gofmt -w t.go 之后,就变成下面的样子:
package main import ( "fmt" "strings" ) func foo() []string { return []string{"gofmt", "pprof", "cover"} } func main() { if v := foo(); len(v) > 0 { fmt.Println("Hello", strings.Join(v, ", ")) } }
是不是心情舒服多了?gofmt 只能解决基本的代码风格问题,虽然这个已经节约了不少口舌和唾沫,我想特别强调几点:
- 有些 IDE 会在保存时自动 gofmt,如果没有手动运行下命令
gofmt -w .,可以将当前目录和子目录下的所有文件都格式化一遍,也很容易的是不是; - gofmt 不识别空行,因为空行是有意义的,因为空行有意义所以 gofmt 不知道如何处理,而这正是很多同学经常犯的问题;
- gofmt 有时候会因为对齐问题,导致额外的不必要的修改,这不会有什么问题,但是会干扰 CR 从而影响 CR 的质量。
先看空行问题,不能随便使用空行,因为空行有意义。不能在不该空行的地方用空行,不能在该有空行的地方不用空行,比如下面的例子:
package main import ( "fmt" "io" "os" ) func main() { f, err := os.Open(os.Args[1]) if err != nil { fmt.Println("show file err %v", err) os.Exit(-1) } defer f.Close() io.Copy(os.Stdout, f) }
上面的例子看起来就相当的奇葩,if 和 os.Open 之间没有任何原因需要个空行,结果来了个空行;而 defer 和 io.Copy 之间应该有个空行却没有个空行。空行是非常好的体现了逻辑关联的方式,所以空行不能随意,非常严重地影响可读性,要么就是一坨东西看得很费劲,要么就是突然看到两个紧密的逻辑身首异处,真的让人很诧异。
上面的代码可以改成这样,是不是看起来很舒服了:
package main import ( "fmt" "io" "os" ) func main() { f, err := os.Open(os.Args[1]) if err != nil { fmt.Println("show file err %v", err) os.Exit(-1) } defer f.Close() io.Copy(os.Stdout, f) }
再看 gofmt 的对齐问题,一般出现在一些结构体有长短不一的字段,比如统计信息,比如下面的代码:
package main type NetworkStat struct { IncomingBytes int `json:"ib"` OutgoingBytes int `json:"ob"` } func main() { }
如果新增字段比较长,会导致之前的字段也会增加空白对齐,看起来整个结构体都改变了:
package main type NetworkStat struct { IncomingBytes int `json:"ib"` OutgoingBytes int `json:"ob"` IncomingPacketsPerHour int `json:"ipp"` DropKiloRateLastMinute int `json:"dkrlm"` } func main() { }
比较好的解决办法就是用注释,添加注释后就不会强制对齐了。
Profile 性能调优
性能调优是一个工程问题,关键是测量后优化,而不是盲目优化。Go 提供了大量的测量程序的工具和机制,包括 Profiling Go Programs, Introducing HTTP Tracing,我们也在性能优化时使用过 Go 的 Profiling,原生支持是非常便捷的。
对于多线程同步可能出现的死锁和竞争问题,Go 提供了一系列工具链,比如 Introducing the Go Race Detector, Data Race Detector,不过打开 race 后有明显的性能损耗,不应该在负载较高的线上服务器打开,会造成明显的性能瓶颈。
推荐服务器开启 http profiling,侦听在本机可以避免安全问题,需要 profiling 时去机器上把 profile 数据拿到后,拿到线下分析原因。实例代码如下:
package main import ( "net/http" _ "net/http/pprof" "time" ) func main() { go http.ListenAndServe("127.0.0.1:6060", nil) for { b := make([]byte, 4096) for i := 0; i < len(b); i++ { b[i] = b[i] + 0xf } time.Sleep(time.Nanosecond) } }
编译成二进制后启动 go mod init private.me && go build . && ./private.me,在浏览器访问页面可以看到各种性能数据的导航:http://localhost:6060/debug/pprof/
例如分析 CPU 的性能瓶颈,可以执行 go tool pprof private.me http://localhost:6060/debug/pprof/profile,默认是分析 30 秒内的性能数据,进入 pprof 后执行 top 可以看到 CPU 使用最高的函数:
(pprof) top Showing nodes accounting for 42.41s, 99.14% of 42.78s total Dropped 27 nodes (cum <= 0.21s) Showing top 10 nodes out of 22 flat flat% sum% cum cum% 27.20s 63.58% 63.58% 27.20s 63.58% runtime.pthread_cond_signal 13.07s 30.55% 94.13% 13.08s 30.58% runtime.pthread_cond_wait 1.93s 4.51% 98.64% 1.93s 4.51% runtime.usleep 0.15s 0.35% 98.99% 0.22s 0.51% main.main
除了 top,还可以输入 web 命令看调用图,还可以用 go-torch 看火焰图等。
UTest 和 Coverage
当然工程化少不了 UTest 和覆盖率,关于覆盖 Go 也提供了原生支持 The cover story,一般会有专门的 CISE 集成测试环境。集成测试之所以重要,是因为随着代码规模的增长,有效的覆盖能显著的降低引入问题的可能性。
什么是有效的覆盖?一般多少覆盖率比较合适?80% 覆盖够好了吗?90% 覆盖一定比 30% 覆盖好吗?我觉得可不一定,参考 Testivus On Test Coverage。对于 UTest 和覆盖,我觉得重点在于:
- UTest 和覆盖率一定要有,哪怕是 0.1% 也必须要有,为什么呢?因为出现故障时让老板心里好受点啊,能用数据衡量出来裸奔的代码有多少;
- 核心代码和业务代码一定要分离,强调核心代码的覆盖率才有意义,比如整体覆盖了 80%,核心代码占 5%,核心代码覆盖率为 10%,那么这个覆盖就不怎么有效了;
- 除了关键正常逻辑,更应该重视异常逻辑,异常逻辑一般不会执行到,而一旦藏有 bug 可能就会造成问题。有可能有些罕见的代码无法覆盖到,那么这部分逻辑代码,CR 时需要特别人工 Review。
分离核心代码是关键。
可以将核心代码分离到单独的 package,对这个 package 要求更高的覆盖率,比如我们要求 98% 的覆盖(实际上做到了 99.14% 的覆盖)。对于应用的代码,具备可测性是非常关键的,举个我自己的例子,go-oryx 这部分代码是判断哪些 url 是代理,就不具备可测性,下面是主要的逻辑:
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { if o := r.Header.Get("Origin"); len(o) > 0 { w.Header().Set("Access-Control-Allow-Origin", "*") } if proxyUrls == nil { ...... fs.ServeHTTP(w, r) return } for _, proxyUrl := range proxyUrls { srcPath, proxyPath := r.URL.Path, proxyUrl.Path ...... if proxy, ok := proxies[proxyUrl.Path]; ok { p.ServeHTTP(w, r) return } } fs.ServeHTTP(w, r) })
可以看得出来,关键需要测试的核心代码,在于后面如何判断URL符合定义的规范,这部分应该被定义成函数,这样就可以单独测试了:
func shouldProxyURL(srcPath, proxyPath string) bool { if !strings.HasSuffix(srcPath, "/") { // /api to /api/ // /api.js to /api.js/ // /api/100 to /api/100/ srcPath += "/" } if !strings.HasSuffix(proxyPath, "/") { // /api/ to /api/ // to match /api/ or /api/100 // and not match /api.js/ proxyPath += "/" } return strings.HasPrefix(srcPath, proxyPath) } func run(ctx context.Context) error { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { ...... for _, proxyUrl := range proxyUrls { if !shouldProxyURL(r.URL.Path, proxyUrl.Path) { continue }
代码参考 go-oryx: Extract and test URL proxy,覆盖率请看 gocover: For go-oryx coverage,这样的代码可测性就会比较好,也能在有限的精力下尽量让覆盖率有效。
Note: 可见,单元测试和覆盖率,并不是测试的事情,而是代码本身应该提高的代码“可测试性”。
另外,对于 Go 的测试还有几点值得说明:
- helper:测试时如果调用某个函数,出错时总是打印那个共用的函数的行数,而不是测试的函数。比如 test_helper.go,如果
compare不调用t.Helper(),那么错误显示是hello_test.go:26: Returned: [Hello, world!], Expected: [BROKEN!],调用t.Helper()之后是 hello_test.go:18: Returned: [Hello, world!], Expected: [BROKEN!]`,实际上应该是 18 行的 case 有问题,而不是 26 行这个 compare 函数的问题; - benchmark:测试时还可以带 Benchmark 的,参数不是
testing.T而是testing.B,执行时会动态调整一些参数,比如 testing.B.N,还有并行执行的testing.PB. RunParallel,参考 Benchamrk; - main: 测试也是有个 main 函数的,参考 TestMain,可以做一些全局的初始化和处理。
- doc.go: 整个包的文档描述,一般是在
package http前面加说明,比如 http doc 的使用例子。
对于 Helper 还有一种思路,就是用带堆栈的 error,参考前面关于 errors 的说明,不仅能将所有堆栈的行数给出来,而且可以带上每一层的信息。
注意如果 package 只暴露了 interface,比如 go-oryx-lib: aac 通过
NewADTS() (ADTS, error)返回的是接口ADTS,无法给 ADTS 的函数加 Example;因此我们专门暴露了一个ADTSImpl的结构体,而 New 函数返回的还是接口,这种做法不是最好的,让用户有点无所适从,不知道该用ADTS还是ADTSImpl。所以一种可选的办法,就是在包里面有个doc.go放说明,例如net/http/doc.go文件,就是在package http前面加说明,比如 http doc 的使用例子。
注释和 Example
注释和 Example 是非常容易被忽视的,我觉得应该注意的地方包括:
- 项目的 README.md 和 Wiki,这实际上就是新人指南,因为新人如果能懂那么就很容易了解这个项目的大概情况,很多项目都没有这个。如果没有 README,那么就需要看文件,该看哪个文件?这就让人很抓狂了;
- 关键代码没有注释,比如库的 API,关键的函数,不好懂的代码段落。如果看标准库,绝大部分可以调用的 API 都有很好的注释,没有注释怎么调用呢?只能看代码实现了,如果每次调用都要看一遍实现,真的很难受了;
- 库没有 Example,库是一种要求很高的包,就是给别人使用的包,比如标准库。绝大部分的标准库的包,都有 Example,因为没有 Example 很难设计出合理的 API。
先看关键代码的注释,有些注释完全是代码的重复,没有任何存在的意义,唯一的存在就是提高代码的“注释率”,这又有什么用呢,比如下面代码:
wsconn *Conn //ws connection // The RPC call. type rpcCall struct { // Setup logger. if err := SetupLogger(......); err != nil { // Wait for os signal server.WaitForSignals(
如果注释能通过函数名看出来(比较好的函数名要能看出来它的职责),那么就不需要写重复的注释,注释要说明一些从代码中看不出来的东西,比如标准库的函数的注释:
// Serve accepts incoming connections on the Listener l, creating a // new service goroutine for each. The service goroutines read requests and // then call srv.Handler to reply to them. // // HTTP/2 support is only enabled if the Listener returns *tls.Conn // connections and they were configured with "h2" in the TLS // Config.NextProtos. // // Serve always returns a non-nil error and closes l. // After Shutdown or Close, the returned error is ErrServerClosed. func (srv *Server) Serve(l net.Listener) error { // ParseInt interprets a string s in the given base (0, 2 to 36) and // bit size (0 to 64) and returns the corresponding value i. // // If base == 0, the base is implied by the string's prefix: // base 2 for "0b", base 8 for "0" or "0o", base 16 for "0x", // and base 10 otherwise. Also, for base == 0 only, underscore // characters are permitted per the Go integer literal syntax. // If base is below 0, is 1, or is above 36, an error is returned. // // The bitSize argument specifies the integer type // that the result must fit into. Bit sizes 0, 8, 16, 32, and 64 // correspond to int, int8, int16, int32, and int64. // If bitSize is below 0 or above 64, an error is returned. // // The errors that ParseInt returns have concrete type *NumError // and include err.Num = s. If s is empty or contains invalid // digits, err.Err = ErrSyntax and the returned value is 0; // if the value corresponding to s cannot be represented by a // signed integer of the given size, err.Err = ErrRange and the // returned value is the maximum magnitude integer of the // appropriate bitSize and sign. func ParseInt(s string, base int, bitSize int) (i int64, err error) {
标准库做得很好的是,会把参数名称写到注释中(而不是用 @param 这种方式),而且会说明大量的背景信息,这些信息是从函数名和参数看不到的重要信息。
咱们再看 Example,一种特殊的 test,可能不会执行,它的主要作用是为了推演接口是否合理,当然也就提供了如何使用库的例子,这就要求 Example 必须覆盖到库的主要使用场景。举个例子,有个库需要方式 SSRF 攻击,也就是检查 HTTP Redirect 时的 URL 规则,最初我们是这样提供这个库的:
func NewHttpClientNoRedirect() *http.Client {
看起来也没有问题,提供一种特殊的 http.Client,如果发现有 Redirect 就返回错误,那么它的 Example 就会是这样:
func ExampleNoRedirectClient() { url := "http://xxx/yyy" client := ssrf.NewHttpClientNoRedirect() Req, err := http.NewRequest("GET", url, nil) if err != nil { fmt.Println("failed to create request") return } resp, err := client.Do(Req) fmt.Printf("status :%v", resp.Status) }
这时候就会出现问题,我们总是返回了一个新的 http.Client,如果用户自己有了自己定义的 http.Client 怎么办?实际上我们只是设置了 http.Client.CheckRedirect 这个回调函数。如果我们先写 Example,更好的 Example 会是这样:
func ExampleNoRedirectClient() { client := http.Client{} //Must specify checkRedirect attribute to NewFuncNoRedirect client.CheckRedirect = ssrf.NewFuncNoRedirect() Req, err := http.NewRequest("GET", url, nil) if err != nil { fmt.Println("failed to create request") return } resp, err := client.Do(Req) }
那么我们自然知道应该如何提供接口了。
其他工程化
最近得知 WebRTC 有 4GB 的代码,包括它自己的以及依赖的代码,就算去掉一般的测试文件和文档,也有 2GB 的代码!!!编译起来真的是非常耗时间,而 Go 对于编译速度的优化,据说是在 Google 有过验证的,具体我们还没有到这个规模。具体可以参考 Why so fast?,主要是编译器本身比 GCC 快 (5X),以及 Go 的依赖管理做的比较好。
Go 的内存和异常处理也做得很好,比如不会出现野指针,虽然有空指针问题可以用 recover 来隔离异常的影响。而 C 或 C++ 服务器,目前还没有见过没有内存问题的,上线后就是各种的野指针满天飞,总有因为野指针搞死的时候,只是或多或少罢了。
按照 Go 的版本发布节奏,6 个月就发一个版本,基本上这么多版本都很稳定,Go1.11 的代码一共有 166 万行 Go 代码,还有 12 万行汇编代码,其中单元测试代码有 32 万行(占 17.9%),使用实例 Example 有 1.3 万行。Go 对于核心 API 是全部覆盖的,提交有没有导致 API 不符合要求都有单元测试保证,Go 有多个集成测试环境,每个平台是否测试通过也能看到,这一整套机制让 Go 项目虽然越来越庞大,但是整体研发效率却很高。
Go2 Transition
Go2 的设计草案在 Go 2 Draft Designs ,而 Go1 如何迁移到 Go2 也是我个人特别关心的问题,Python2 和 Python3 的那种不兼容的迁移方式简直就是噩梦一样的记忆。Go 的提案中,有一个专门说了迁移的问题,参考 Go2 Transition。
Go2 Transition 还不是最终方案,不过它也对比了各种语言的迁移,还是很有意思的一个总结。这个提案描述了在非兼容性变更时,如何给开发者挖的坑最小。
目前 Go1 的标准库是遵守兼容性原则的,参考 Go 1 compatibility guarantee,这个规范保证了 Go1 没有兼容性问题,几乎可以没有影响的升级比如从 Go1.2 升级到 Go1.11。几乎的意思,是很大概率是没有问题,当然如果用了一些非常冷门的特性,可能会有坑,我们遇到过 json 解析时,内嵌结构体的数据成员也得是 exposed 的才行,而这个在老版本中是可以非 exposed;还遇到过 cgo 对于链接参数的变更导致编译失败,这些问题几乎很难遇到,都可以算是兼容的吧,有时候只是把模糊不清的定义清楚了而已。
Go2 在语言和标准库上,会打破 Go1 的兼容性规范,也就是和 Go1 不再兼容。不过 Go 是分布式开源社区在维护,不能依赖于 flag day,还是要容许不同 Go 版本写的 package 的互操作性。
先了解下各个语言如何考虑兼容性:
- C 是严格向后兼容的,很早写的程序总是能在新的编译器中编译。另外新的编译器也支持指定之前的标准,比如
-std=c90使用ISO C90标准编译程序。关键的特性是编译成目标文件后,不同版本的 C 的目标文件,能完美的链接成执行程序;C90 实际上是对之前K&R C版本不兼容的,主要引入了volatile关键字、整数精度问题,还引入了 trigraphs,最糟糕的是引入了 undefined 行为比如数组越界和整数溢出的行为未定义。从 C 上可以学到的是:后向兼容非常重要;非常小的打破兼容性也问题不大特别是可以通过编译器选项来处理;能将不同版本的目标文件链接到一起是非常关键的;undefined 行为严重困扰开发者容易造成问题;
- C++ 也是 ISO 组织驱动的语言,和 C 一样也是向后兼容的。C++和C一样坑爹的地方坑到吐血,比如 undefined行为等。尽管一直保持向后兼容,但是新的C++代码比如C++11 看起来完全不同,这是因为有新的改变的特性,比如很少会用裸指针、比如 range 代替了传统的 for 循环,这导致熟悉老C++语法的程序员看新的代码非常难受甚至看不懂。C++毋庸置疑是非常流行的,但是新的语言标准在这方面没有贡献。从C++上可以学到的新东西是:尽管保持向后兼容,语言的新版本可能也会带来巨大的不同的感受(保持向后兼容并不能保证能持续看懂)。
- Java 也是向后兼容的,是在字节码层面和语言层面都向后兼容,尽管语言上不断新增了关键字。Java 的标准库非常庞大,也不断在更新,过时的特性会被标记为 deprecated 并且编译时会有警告,理论上一定版本后 deprecated 的特性会不可用。Java 的兼容性问题主要在 JVM 解决,如果用新的版本编译的字节码,得用新的 JVM 才能执行。Java 还做了一些前向兼容,这个影响了字节码啥的(我本身不懂 Java,作者也不说自己不是专家,我就没仔细看了)。Java 上可以学到的新东西是:要警惕因为保持兼容性而限制语言未来的改变。
- Python2.7 是 2010 年发布的,目前主要是用这个版本。Python3 是 2006 年开始开发,2008 年发布,十年后的今天还没有迁移完成,甚至主要是用的 Python2 而不是 Python3,这当然不是 Go2 要走的路。看起来是因为缺乏向后兼容导致的问题,Python3 刻意的和之前版本不兼容,比如 print 从语句变成了一个函数,string 也变成了 Unicode(这导致和 C 调用时会有很多问题)。没有向后兼容,同时还是解释型语言,这导致 Python2 和 3 的代码混着用是不可能的,这意味着程序依赖的所有库必须支持两个版本。Python 支持
from __future__ import FEATURE,这样可以在 Python2 中用 Python3 的特性。Python 上可以学到的东西是:向后兼容是生死攸关的;和其他语言互操作的接口兼容是非常重要的;能否升级到新的语言是由调用的库支持的。
- Perl6 是 2000 年开始开发的,15 年后才正式发布,这也不是 Go2 应该走的路。这么漫长的主要原因包括:刻意没有向后兼容,只有语言的规范没有实现而这些规范不断的修改。Perl 上可以学到的东西是:不要学 Perl;设置期限按期交付;别一下子全部改了。
特别说明的是,非常高兴的是 Go2 不会重新走 Python3 的老路子,当初被 Python 的版本兼容问题坑得不要不要的。
虽然上面只是列举了各种语言的演进,确实也了解得更多了,有时候描述问题本身,反而更能明白解决方案。C 和 C 的向后兼容确实非常关键,但也不是它们能有今天地位的原因,C11 的新特性到底增加了多少 DAU 呢,确实是值得思考的。另外 C11 加了那么多新的语言特性,比如 WebRTC 代码就是这样,很多老 C 程序员看到后一脸懵逼,和一门新的语言一样了,是否保持完全的兼容不能做一点点变更,其实也不是的。
应该将 Go 的语言版本和标准库的版本分开考虑,这两个也是分别演进的,例如 alias 是 1.9 引入的向后兼容的特性,1.9 之前的版本不支持,1.9 之后的都支持。语言方面包括:
- Language additions 新增的特性。比如 1.9 新增的 type alias,这些向后兼容的新特性,并不要求代码中指定特殊的版本号,比如用了 alias 的代码不用指定要 1.9 才能编译,用之前的版本会报错。向后兼容的语言新增的特性,是依靠程序员而不是工具链来维护的,要用这个特性或库升级到要求的版本就可以。
- Language removals 删除的特性。比如有个提案 #3939 去掉
string(int),字符串构造函数不支持整数,假设这个在 Go1.20 版本去掉,那么 Go1.20 之后这种string(1000)代码就要编译失败了。这种情况没有特别好的办法能解决,我们可以提供工具,将代码自动替换成新的方式,这样就算库维护者不更新,使用者自己也能更新。这种场景引出了指定最大版本,类似 C 的-std=C90,可以指定最大编译的版本比如-lang=go1.19,当然必须能和 Go1.20 的代码链接。指定最大版本可以在 go.mod 中指定,这需要工具链兼容历史的版本,由于这种特性的删除不会很频繁,维护负担还是可以接受的。
- Minimum language version 最小要求版本。为了可以更明确的错误信息,可以允许模块在
go.mod中指定最小要求的版本,这不是强制性的,只是说明了这个信息后编译工具能明确给出错误,比如给出应该用具体哪个版本。
- Language redefinitions 语言重定义。比如 Go1.1 时,int 在 64 位系统中长度从 4 字节变成了 8 字节,这会导致很多潜在的问题。比如 #20733 修改了变量在 for 中的作用域,看起来是解决潜在的问题,但也可能会引入问题。引入关键字一般不会有问题,不过如果和函数冲突就会有问题,比如 error: check。为了让 Go 的生态能迁移到 Go2,语言重定义的事情应该尽量少做,因为我们不再能依赖编译器检查错误。虽然指定版本能解决这种问题,但是这始终会导致未知的结果,很有可能一升级 Go 版本就挂了。我觉得对于语言重定义,应该完全禁止。比如 #20733 可以改成禁止这种做法,这样就会变成编译错误,可能会帮助找到代码中潜在的 BUG。
- Build tags 编译 tags。在指定文件中指定编译选项,是现有的机制,不过是指定的 release 版本号,它更多是指定了最小要求的版本,而没有解决最大依赖版本问题。
- Import go2 导入新特性。和 Python 的特性一样,可以在 Go1 中导入 Go2 的新特性,比如可以显式地导入
import "go2/type-aliases",而不是在 go.mod 中隐式的指定。这会导致语言比较复杂,将语言打乱成了各种特性的组合。而且这种方式一旦使用,将无法去掉。这种方式看起来不太适合 Go。
如果有更多的资源来维护和测试,标准库后续会更快发布,虽然还是 6 个月的周期。标准库方面的变更包括:
- Core standard library 核心标准库。有些和编译工具链相关的库,还有其他的一些关键的库,应该遵守 6 个月的发布周期,而且这些核心标准库应该保持 Go1 的兼容性,比如
os/signal、reflect、runtime、sync、testing、time、unsafe等等。我可能乐观的估计net,os, 和syscall不在这个范畴。
- Penumbra standard library 边缘标准库。它们被独立维护,但是在一个 release 中一起发布,当前核心库大部分都属于这种。这使得可以用
go get等工具来更新这些库,比 6 个月的周期会更快。标准库会保持和前面版本的编译兼容,至少和前面一个版本兼容。
- Removing packages from the standard library 去掉一些不太常用的标准库,比如
net/http/cgi等。
如果上述的工作做得很好的话,开发者会感觉不到有个大版本叫做 Go2,或者这种缓慢而自然的变化逐渐全部更新成了 Go2。甚至我们都不用宣传有个 Go2,既然没有 C2.0 为何要 Go2.0 呢?主流的语言比如 C、C++ 和 Java 从来没有 2.0,一直都是 1.N 的版本,我们也可以模仿它们。事实上,一般所认为的全新的 2.0 版本,若出现不兼容性的语言和标准库,对用户也不是个好结果,甚至还是有害的。
Others
关于 Go,还有哪些重要的技术值得了解呢?下面将进行详细的分享。
GC
GC 一般是 C/C 程序员对于 Go 最常见、也是最先想到的一个质疑,GC 这玩意儿能行吗?我们以前 C/C 程序都是自己实现内存池的,我们内存分配算法非常牛逼的。
Go 的 GC 优化之路,可以详细读 Getting to Go: The Journey of Go's Garbage Collector。
2014 年 Go1.4,GC 还是很弱的,是决定 Go 生死的大短板。
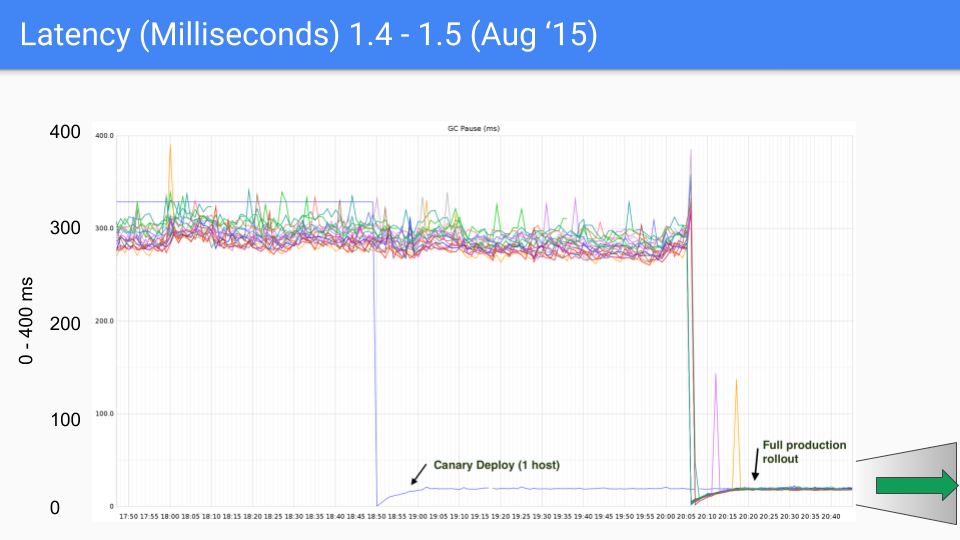
上图是 Twitter 的线上服务监控。Go1.4 的 STW(Stop the World) Pause time 是 300 毫秒,而 Go1.5 优化到了 30 毫秒。
而 Go1.6 的 GC 暂停时间降低到了 3 毫秒左右。
Go1.8 则降低到了 0.5 毫秒左右,也就是 500 微秒。从 Go1.4 到 Go1.8,优化了 600 倍性能。
如何看 GC 的 STW 时间呢?可以引入 net/http/pprof 这个库,然后通过 curl 来获取数据,实例代码如下:
package main import ( "net/http" _ "net/http/pprof" ) func main() { http.ListenAndServe("localhost:6060", nil) }
启动程序后,执行命令就可以拿到结果(由于上面的例子中没有 GC,下面的数据取的是另外程序的部分数据):
$ curl 'http://localhost:6060/debug/pprof/allocs?debug=1' 2>/dev/null |grep PauseNs # PauseNs = [205683 79032 202102 82216 104853 142320 90058 113638 152504 145965 72047 49690 158458 60499 99610 112754 122262 52252 49234 68420 159857 97940 226085 103644 135428 245291 141997 92470 79974 132817 74634 65653 73582 47399 51653 86107 48619 62583 68906 131868 111903 85482 44531 74585 50162 31445 107397 10903081771 92603 58585 96620 40416 29763 102248 32804 49394 83715 77099 108983 66133 47832 35379 143949 69235 27820 35677 99430 104303 132657 63542 39434 126418 63845 167969 116438 68904 77899 136506 119708 47501]
可以用 python 计算最大值是 322 微秒,最小是 26 微秒,平均值是 81 微秒。
Declaration Syntax
关于 Go 的声明语法 Go Declaration Syntax,和 C 语言有对比,在 The "Clockwise/Spiral Rule" 这个文章中也详细描述了 C 的顺时针语法规则。其中有个例子:
int (*signal(int, void (*fp)(int)))(int);
这是个什么呢?翻译成 Go 语言就能看得很清楚:
func signal(a int, b func(int)) func(int)int
signal 是个函数,有两个参数,返回了一个函数指针。signal 的第一个参数是 int,第二个参数是一个函数指针。
当然实际上 C 语言如果借助 typedef 也是能获得比较好的可读性的:
typedef void (*PFP)(int); typedef int (*PRET)(int); PRET signal(int a, PFP b);
只是从语言的语法设计上来说,还是 Go 的可读性确实会好一些。这些点点滴滴的小傲娇,是否可以支撑我们够浪程序员浪起来的资本呢?至少 Rob Pike 不是拍脑袋和大腿想出来的规则嘛,这种认真和严谨是值得佩服和学习的。
Documents
新的语言文档支持都很好,不用买本书看,Go 也是一样,Go 官网历年比较重要的文章包括:
- 语法特性及思考:
Go Declaration Syntax,The Laws of Reflection,Constants,Generics Discussion,Another Go at Language Design,Composition not inheritance,Interfaces and other types - 并发相关特性:
Share Memory By Communicating,Go Concurrency Patterns: Timing out, moving on,Concurrency is not parallelism,Advanced Go Concurrency Patterns,Go Concurrency Patterns: Pipelines and cancellation,Go Concurrency Patterns: Context,Mutex or Channel - 错误处理相关:
Defer, Panic, and Recover,Error handling and Go,Errors are values,Stack traces and the errors package,Error Handling In Go,The Error Model - 性能和优化:
Profiling Go Programs,Introducing the Go Race Detector,The cover story,Introducing HTTP Tracing,Data Race Detector - 标准库说明:
Go maps in action,Go Slices: usage and internals,Arrays, slices (and strings): The mechanics of append,Strings, bytes, runes and characters in Go - 和C的结合:
C? Go? Cgo! - 项目相关:
Organizing Go code,Package names,Effective Go,versioning,Russ Cox: vgo - 关于GC:
Go GC: Prioritizing low latency and simplicity,Getting to Go: The Journey of Go Garbage Collector,Proposal: Eliminate STW stack re-scanning
其中,文章中有引用其他很好的文章,我也列出来哈:
Go Declaration Syntax,引用了一篇神作,介绍 C 的螺旋语法,写 C 的多,读过这个的不多,The "Clockwise/Spiral Rule"Strings, bytes, runes and characters in Go,引用了很好的一篇文章,号称每个人都要懂的,关于字符集和 Unicode 的文章,Every Software Developer Must Know (No Excuses!)- 为何错误码模型,比异常模型更有优势,参考 Cleaner, more elegant, and wrong 以及 Cleaner, more elegant, and harder to recognize。
- Go 中的面向对象设计原则 SOLID。
- Go 的版本语义 Semantic Versioning,如何在大型项目中规范版本,避免导致依赖地狱 (Dependency Hell) 问题。
SRS
SRS 是使用 ST,单进程单线程,性能是 EDSM 模型的 nginx-rtmp 的 3 到 5 倍,参考 SRS: Performance,当然不是 ST 本身性能是 EDSM 的三倍,而是说 ST 并不会比 EDSM 性能低,主要还是要根据业务上的特征做优化。
关于 ST 和 EDSM,参考本文前面关于 Concurrency 对于协程的描述,ST 它是 C 的一个协程库,EDSM 是异步事件驱动模型。
SRS 是单进程单线程,可以扩展为多进程,可以在 SRS 中改代码 Fork 子进程,或者使用一个 TCP 代理,比如 TCP 代理 go-oryx: rtmplb。
在 2016 年和 2017 年我用 Go 重写过 SRS,验证过 Go 使用 2CPU 可以跑到 C10K,参考 go-oryx,v0.1.13 Supports 10k(2CPUs) for RTMP players。由于仅仅是语言的差异而重写一个项目,没有找到更好的方式或理由,觉得很不值得,所以还是放弃了 Go 语言版本,只维护 C++ 版本的 SRS。Go 目前一般在 API 服务器用得比较多,能否在流媒体服务器中应用?答案是肯定的,我已经实现过了。
后来在 2017 年,终于找到相对比较合理的方式来用 Go 写流媒体,就是只提供库而不是二进制的服务器,参考 go-oryx-lib。
目前 Go 可以作为 SRS 前面的代理,实现多核的优势,参考 go-oryx。
关注“阿里巴巴云原生”公众号,回复 Go 即可获取清晰知识大图及最全脑图链接!
作者简介
杨成立(花名:忘篱),阿里巴巴高级技术专家。他发起并维护了基于 MIT 协议的开源流媒体服务器项目 – SRS(Simple Rtmp Server)。感兴趣的同学可以扫描下方二维码进入钉钉群,直面和大神进行交流!
“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”

登录后评论
立即登录 注册