
第一部分 How about Calico
About Calico
Calico为容器和虚拟机工作负载提供一个安全的网络连接。
Calico可以创建并管理一个3层平面网络,为每个工作负载分配一个完全可路由的IP地址。 工作负载可以在没有IP封装或网络地址转换的情况下进行通信,以实现裸机性能,简化故障排除和提供更好的互操作性。 在需要使用overlay网络的环境中,Calico提供了IP-in-IP隧道技术,或者也可以与flannel等其他overlay网络配合使用。
Calico还提供网络安全规则的动态配置。 使用Calico的简单策略语言,就可以实现对容器、虚拟机工作负载和裸机主机各节点之间通信的细粒度控制。
Calico v3.4于2018.12.10号发布,可与Kubernetes、OpenShift和OpenStack良好地集成使用。
注意: 在Mesos, DC/OS和Docker orchestrators中使用Calico时,目前只支持到了 Calico v2.6.
How it works
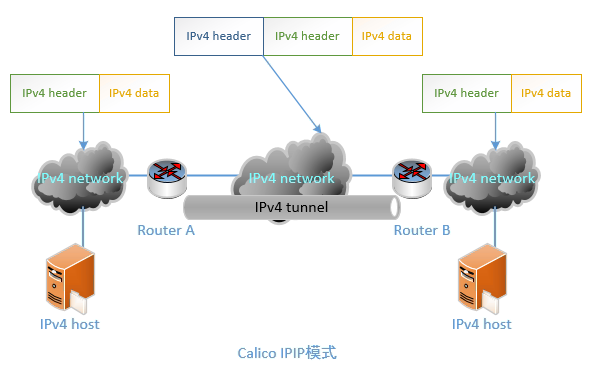
Calico的IPIP与BGP模式
- IPIP是一种将各Node的路由之间做一个tunnel,再把两个网络连接起来的模式。启用IPIP模式时,Calico将在各Node上创建一个名为”tunl0″的虚拟网络接口。如下图所示。
- BGP模式则直接使用物理机作为虚拟路由路(vRouter),不再创建额外的tunnel。
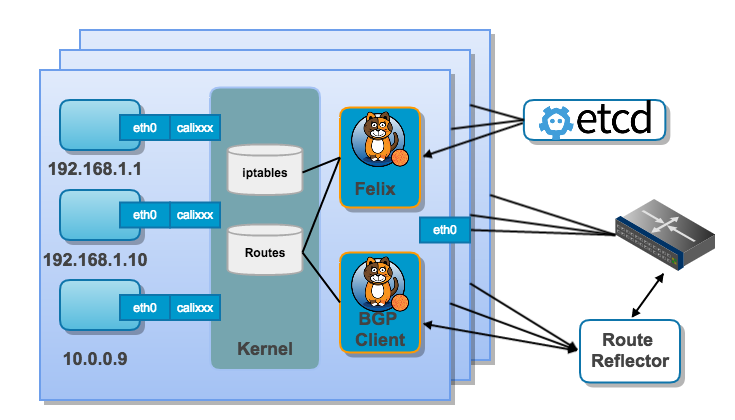
Calico的部署规模
Calico BGP模式在小规模集群中可以直接互联,在大规模集群中可以通过额外的BGP route reflector来完成。
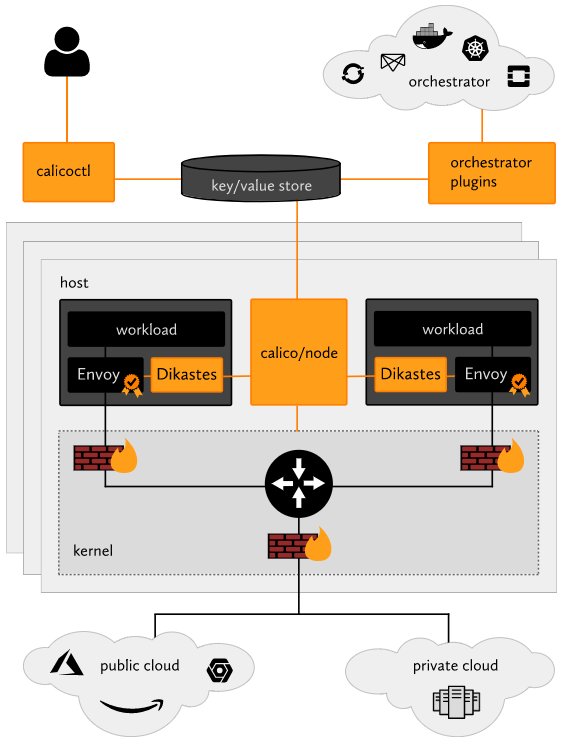
Calico主要组件
Calico利用了Linux内核原生的路由和iptables防火墙功能。 进出各个容器、虚拟机和物理主机的所有流量都会在路由到目标之前遍历这些内核规则。
- Felix:主要的Calico代理agent,运行每台计算机上管理endpoints资源。
- calicoctl:允许从命令行界面配置实现高级策略和网络。
- orchestrator plugins:提供与各种流行的云计算编排工具的紧密集成和同步支持。
- key/value store:存储Calico的策略配置和网络状态信息,目前主要使用etcdv3或k8s api。
- calico/node:在每个主机上运行,从key/value存储中读取相关的策略和网络配置信息,并在Linux内核中实现它。
- Dikastes/Envoy:可选的Kubernetes sidecars,可以通过相互TLS身份验证保护工作负载到工作负载的通信,并增加应用层控制策略。
Felix
Felix是一个守护程序,它在每个提供endpoints资源的计算机上运行。在大多数情况下,这意味着它需要在托管容器或VM的宿主机节点上运行。 Felix 负责编制路由和ACL规则以及在该主机上所需的任何其他内容,以便为该主机上的endpoints资源正常运行提供所需的网络连接。
根据特定的编排环境,Felix负责以下任务:
- 管理网络接口,Felix将有关接口的一些信息编程到内核中,以使内核能够正确处理该endpoint发出的流量。 特别是,它将确保主机正确响应来自每个工作负载的ARP请求,并将为其管理的接口启用IP转发支持。它还监视网络接口的出现和消失,以便确保针对这些接口的编程得到了正确的应用。
- 编写路由,Felix负责将到其主机上endpoints的路由编写到Linux内核FIB(转发信息库)中。 这可以确保那些发往目标主机的endpoints的数据包被正确地转发。
- 编写ACLs,Felix还负责将ACLs编程到Linux内核中。 这些ACLs用于确保只能在endpoints之间发送有效的网络流量,并确保endpoints无法绕过Calico的安全措施。
- 报告状态,Felix负责提供有关网络健康状况的数据。 特别是,它将报告配置其主机时发生的错误和问题。 该数据会被写入etcd,以使其对网络中的其他组件和操作才可见。
Orchestrator Plugin
每个主要的云编排平台都有单独的Calico网络插件(例如OpenStack,Kubernetes)。 这些插件的目的是将Calico更紧密地绑定到编排工具中,允许用户管理Calico网络,就像他们管理编排工具中内置的网络工具一样。
一个好的Orchestrator插件示例是Calico Neutron ML2 驱动程序。 该插件与Neutron的ML2插件集成,允许用户通过Neutron API调用来配置Calico网络,实现了与Neutron的无缝集成。
Orchestrator插件负责以下任务:
- API Translation,每个云编排工具都不可避免地拥有自己的一套用于管理网络的API接口规范, Orchestrator插件的主要工作就是将这些API转换为Calico的数据模型,然后将其存储在Calico的数据存储区中。这种转换中的一些工作将非常简单,其他一部分可能更复杂,以便将单个复杂操作(例如,实时迁移)转换为Calico网络期望的一系列更简单的操作。
- Feedback,如有需要,orchestrator插件将从Calico网络向编排器提供管理命令的反馈信息。 包括提供有关Felix存活的信息,以及如果网络配置失败则将某些endpoints标记为失败。
etcd
etcd是一个分布式键值存储数据库,专注于实现数据存储一致性。 Calico使用etcd提供组件之间的数据通信,并作为可以保证一致性的数据存储,以确保Calico始终可以构建出一个准确的网络。
根据orchestrator插件的不同,etcd既可以是作为主数据存储使用,也可以是一个单独数据存储的轻量级镜像。例如,在OpenStack部署中,OpenStack数据库被认为是“真实配置信息的来源”,而etcd用于镜像其中有关网络配置的信息,并用于服务其他Calico组件。
etcd组件穿插在整个部署中。它可以被分为两组主机节点:核心集群和代理。
对于小型部署,核心集群可以是一个节点的etcd集群(通常与orchestrator插件组件位于同一节点上)。这种部署模型很简单但没有为etcd提供冗余。在etcd失败的情况下,orchstrator插件必须重建数据库,例如OpenStack,它需要插件从OpenStack数据库重新同步状态到etcd。
在较大的部署中,核心群集可以根据etcd管理指南进行扩展。
此外,在运行Felix或orchstrator插件的每台计算机上,会运行一个etcd代理服务。这减少了etcd核心集群上的负载,并为主机节点屏蔽了etcd服务集群的细节。在etcd集群与orchstrator插件在同一台机器上都有成员的情况下,可以放弃在该机器上使用etcd代理。
etcd负责执行以下任务:
- Data Storage,etcd以分布式、一致和容错的方式存储Calico网络的数据(对于至少三个etcd节点的cluster大小)。 这确保Calico网络始终处于已知良好状态,同时允许运行etcd的个别机器节点失败或无法访问。Calico网络数据的这种分布式存储提高了Calico组件从数据库读取的能力。
- Communication,etcd也用作组件之间的通信服务。 我们通过让非etcd组件监视键值空间中的某些点来确保他们看到已经做出的任何更改,从而允许他们及时响应这些更改。 该功能允许将状态信息提交到数据库,然后触发基于该状态数据的进一步网络配置管理。
BGP Client (BIRD)
Calico在每个运行Felix服务的节点上都部署一个BGP客户端。 BGP客户端的作用是读取Felix程序编写到内核中并在数据中心内分发的路由信息。
BGP客户端负责执行以下任务:
- 路由信息分发,当Felix将路由插入Linux内核FIB时,BGP客户端将接收它们并将它们分发到集群中的其他工作节点。
BGP Route Reflector (BIRD)
对于较大规模的部署,简单的BGP可能成为限制因素,因为它要求每个BGP客户端连接到网状拓扑中的每一个其他BGP客户端。这需要越来越多的连接,迅速变得难以维护,甚至会让一些设备的路由表撑满。
因此,在较大规模的部署中,Calico建议部署BGP Route Reflector。通常是在Internet中使用这样的组件充当BGP客户端连接的中心点,从而防止它们需要与群集中的每个BGP客户端进行通信。为了实现冗余,也可以同时部署多个BGP Route Reflector服务。Route Reflector仅仅是协助管理BGP网络,并没有endpoint数据会通过它们。
在Calico中,此BGP组件也是使用的最常见的BIRD,配置为Route Reflector运行,而不是标准BGP客户端。
BGP Route Reflector负责以下任务:
- 集中式的路由信息分发,当Calico BGP客户端将路由从其FIB通告到Route Reflector时,Route Reflector会将这些路由通告给部署集群中的其他节点。
BIRD是什么
BIRD是布拉格查理大学数学与物理学院的一个学校项目,项目名是BIRD Internet Routing Daemon的缩写。 目前,它由CZ.NIC实验室开发和支持。
BIRD项目旨在开发一个功能齐全的动态IP路由守护进程,主要针对(但不限于)Linux,FreeBSD和其他类UNIX系统,并在GNU通用公共许可证下分发。详细信息参照官网https://bird.network.cz/。
作为一个开源的网络路由守护进程项目,BRID设计并支持了以下功能:
- both IPv4 and IPv6 protocols
- multiple routing tables
- the Border Gateway Protocol (BGPv4)
- the Routing Information Protocol (RIPv2, RIPng)
- the Open Shortest Path First protocol (OSPFv2, OSPFv3)
- the Babel Routing Protocol
- the Router Advertisements for IPv6 hosts
- a virtual protocol for exchange of routes between different routing tables on a single host
- a command-line interface allowing on-line control and inspection of status of the daemon
- soft reconfiguration (no need to use complex online commands to change the configuration, just edit the configuration file and notify BIRD to re-read it and it will smoothly switch itself to the new configuration, not disturbing routing protocols unless they are affected by the configuration changes)
- a powerful language for route filtering
第二部分、搭建一套单节点K8s+Calico的测试环境
这个快速入门可以让你快速获得一个使用Calico作为网络插件的单节点Kubernetes集群。 你可以使用此群集进行测试和开发。如果是部署一套用于生产环境的集群服务,请参考下一章节的Kubernetes生产环境Calico网络插件安装指南。
环境要求
- AMD64 processor
- 2CPU
- 2GB RAM
- 10GB free disk space
- RedHat Enterprise Linux 7.x+, CentOS 7.x+, Ubuntu 16.04+, or Debian 9.x+
在开始之前
1)配置NetworkManager
确保Calico可以管理主机上的cali和tunl接口。 如果主机上存在NetworkManager,请按照下面方法配置NetworkManager。
NetworkManager管理默认网络命名空间中接口的路由表的功能,可能会干扰Calico正确处理网络路由的能力。
创建一个配置文件/etc/NetworkManager/conf.d/calico.conf,来制止这种干扰:
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*
2)安装kubeadm工具
参照kubernetes官网 https://kubernetes.io/docs/setup/independent/install-kubeadm/
注意:安装kubeadm后,请勿关闭电源或重新启动主机。 请回到本文,继续配置下一部分以创建群集。
创建一个单节点的Kubernetes集群
1)因为google被墙,kubeadm默认从gcr.io上获取镜像,所以我们改为使用下面脚本和命令手动处理一下需要使用的镜像文件
cat <<EOF > /tmp/get-images.sh
#!/bin/bash
images=(kube-apiserver:v1.13.0 kube-controller-manager:v1.13.0 kube-scheduler:v1.13.0 kube-proxy:v1.13.0 pause:3.1 etcd:3.2.24)
for imageName in \${images[@]} ; do
docker pull mirrorgooglecontainers/\$imageName
docker tag mirrorgooglecontainers/\$imageName k8s.gcr.io/\$imageName
docker rmi mirrorgooglecontainers/\$imageName
done
EOF
sh /tmp/get-images.sh
docker pull coredns/coredns:1.2.6
docker tag coredns/coredns:1.2.6 k8s.gcr.io/coredns:1.2.6
docker rmi coredns/coredns:1.2.6
2)初始化master节点配置信息
[root@calico-test ~]# kubeadm init --pod-network-cidr=192.168.0.0/16 I1205 18:14:34.533350 4096 version.go:94] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://storage.googleapis.com/kubernetes-release/release/stable-1.txt: net/http: request canceled (Client.Timeout exceeded while awaiting headers) I1205 18:14:34.533900 4096 version.go:95] falling back to the local client version: v1.13.0 [init] Using Kubernetes version: v1.13.0 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.09.0. Latest validated version: 18.06 [WARNING Hostname]: hostname "calico-test" could not be reached [WARNING Hostname]: hostname "calico-test": lookup calico-test on 192.168.5.66:53: server misbehaving ......
省略部分内容
...... [bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join 10.0.2.15:6443 --token oe4k9q.mzfnn71cfekx9as4 --discovery-token-ca-cert-hash sha256:c45bd3588c40453951f0177451fbf797370ffbf9b1514b3350d5bf237a100249 [root@calico-test ~]#
- 开头地方有几处warning信息,可以按提示优化一下
3)配置kubectl
增加一个名为k8s的普通系统用户,并设置为可以免密sudo。
执行kubeadm初始化master配置时提示的kubectl配置方法:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
4)部署一个etcd实例
[k8s@calico-test ~]$ kubectl apply -f \ https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/etcd.yaml daemonset.extensions/calico-etcd created service/calico-etcd created
5)部署Calico实例
[k8s@calico-test ~]$ kubectl apply -f \ https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/calico.yaml configmap/calico-config created secret/calico-etcd-secrets created daemonset.extensions/calico-node created serviceaccount/calico-node created deployment.extensions/calico-kube-controllers created serviceaccount/calico-kube-controllers created clusterrole.rbac.authorization.k8s.io/calico-kube-controllers created clusterrolebinding.rbac.authorization.k8s.io/calico-kube-controllers created clusterrole.rbac.authorization.k8s.io/calico-node created clusterrolebinding.rbac.authorization.k8s.io/calico-node created
6)观察并确认所有的pods都创建成功了
[k8s@calico-test ~]$ watch kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-etcd-h5bqq 1/1 Running 0 69s kube-system calico-kube-controllers-b68c4c7dd-55l4p 1/1 Running 0 2m11s kube-system calico-node-lzlh9 2/2 Running 2 2m12s kube-system coredns-86c58d9df4-76rrk 1/1 Running 0 45m kube-system coredns-86c58d9df4-8tv2k 1/1 Running 0 45m kube-system etcd-calico-test 1/1 Running 0 45m kube-system kube-apiserver-calico-test 1/1 Running 0 44m kube-system kube-controller-manager-calico-test 1/1 Running 0 44m kube-system kube-proxy-qlnwq 1/1 Running 0 45m kube-system kube-scheduler-calico-test 1/1 Running 0 45m
- 在使用kubeadm部署时,Calico并没有使用kubeadm在Kubernetes master中部署的etcd服务,而是创建了一个Calico自己使用的etcd pod,服务地址为 http://10.96.232.136:6666
7)删除master节点上的taints标记信息
因为我们是部署的单节点测试集群,需要让scheduler可以向master上面调度创建pods。
[k8s@calico-test ~]$ kubectl taint nodes --all node-role.kubernetes.io/master- node/calico-test untainted [k8s@calico-test ~]$
8)查看并确认在你的测试集群中已经有一个node节点了
[k8s@calico-test ~]$ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME calico-test Ready master 15h v1.13.0 10.0.2.15 <none> CentOS Linux 7 (Core) 3.10.0-862.14.4.el7.x86_64 docker://18.9.0 [k8s@calico-test ~]$
至此,你已经成功得创建出了一个单节点的Kubernetes+Calico的测试集群了。
第三部分、Kubernetes生产环境下的Calico网络插件安装指南
安装Calico并使用其为Kubernetes提供网络和访问策略的服务。
安装的过程与方法,受数据库软件的选型以及nodes节点数量多少的影响。
- etcd datastore
- Kubernetes API datastore—50 nodes or less (beta)
- Kubernetes API datastore—more than 50 nodes (beta)
注:Calico可以使用 Kubernetes API datastore作为数据库,这还是一个beta版本的功能。因为该API还不支持Calico IPAM功能。
1、使用etcd作为数据库
1)获取用于etcd的Calico网络服务配置清单
curl https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/calico.yaml -O
如果你的pod CIDR 使用的是 192.168.0.0/16,可以跳过,否则执行下面命令,更新一下pod CIDR的配置信息:
POD_CIDR="<your-pod-cidr>" \ sed -i -e "s?192.168.0.0/16?$POD_CIDR?g" calico.yaml
2)根据实际环境参数定制calico.yaml文件中的配置信息
calico.yaml用于创建出以下的资源对象:
- 创建名为calico-config的ConfigMap,包含Calico服务运行所需的配置信息。
- 创建名为calico-etcd-secrets的Secret,用于使用TLS方式连接etcd。
- 在每个Node上运行名为calico-node容器,部署为DaemonSet, Calico服务程序,用于设置Pod的网络资源,保证Pod的网络与各Node互联互通,它还需要以hostNetwork模式运行,直接使用宿主机网络。
- 通过创建一个名为install-cni的容器,在每个Node上部署Calico CNI二进制文件和网络配置相关的文件。
- 创建名为calico-node的ServiceAccount。
- 部署一个名为calico-kube-controllers的Deployment,部署一个Calico Kubernetes控制器,只允许创建出一个容器实例,用于对接k8s集群中为Pod设置的Network Policy。
- 创建名为calico-kube-controllers的ServiceAccount。
一般需要修改以下配置项的内容:
- 在名为calico-config的ConfigMap中,将etcd_endpoints的值设置为etcd服务器的IP地址和端口。如果你是通过https访问etcd服务的,还需要在data部分配置证书和密钥的参数。
- 在名为calico-etcd-secrets的Secret中,如果是通过https访问etcd服务的,需要配置为正确的证书和密钥信息。
- 在名为calico-node的DaemonSet中,评估是否需要按k8s集群的实际网络地址资源规划,修改CALICO_IPV4POOL_CIDR这个容器环境变量的值,该环境变量所定义的是集群网络服务将会分配使用的Pod IPs网段资源。
calico-node服务的主要参数如下:
- CALICO_IPV4POOL_CIDR:Calico IPAM的IP地址池,Pod的IP地址将从该池中进行分配。
- CALICO_IPV4POOL_IPIP:是否启用IPIP模式。启用IPIP模式时,Calico将在Node上创建一个名为”tunl0″的虚拟隧道。使用IPIP模式,设置CALICO_IPV4POOL_IPIP=“always”,不使用IPIP模式时,设置CALICO_IPV4POOL_IPIP=”off”,此时将使用BGP模式。
- FELIX_IPV6SUPPORT:是否启用IPV6。
- FELIX_LOGSEVERITYSCREEN:日志级别。
3)使用以下命令创建出需要的资源
kubectl apply -f calico.yaml
4)应用层策略
如果你还希望通过双向TLS身份验证强制实施应用层策略,保护工作负载到工作负载的通信,请继续配置和启用应用层策略(可选)。
Calico的应用层策略允许你编写并强制执行应用程序层属性(如HTTP方法或路径)以及加密安全身份的策略。Calico安装中默认不启用对应用层策略的支持,因为它需要额外的CPU和内存资源才能运行。
配置使用Calico+应用层策略时需要满足以下依赖条件:
安装Istio
详细说明请参考: Istio project documentation
确认已经启用了双向TLS安全认证。
例如,执行下面命令创建一个istio auth demo:
curl -L https://git.io/getLatestIstio | sh –
cd $(ls -d istio-*)
kubectl apply -f install/kubernetes/istio-demo-auth.yaml
注:如果遇到“unable to recognize”这样的报错,再执行一次上面的kubectl apply命令即可,这是因为创建的多个资源项之间有依赖联系导致。
更新Istio sidecar注入器
sidecar注入器可以在创建pods时自动修改必要的配置信息以与Istio配合使用。 下面的步骤修改注入器的配置,以将Dikastes(一种Calico组件)添加为sidecar容器。
- 按照自动sidecar注入的配置说明安装sidecar注入器并在你选择的命名空间中启用它。
- 应用以下ConfigMap以启用Dikastes与Envoy一起注入。
kubectl apply -f \
https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/manifests/app-layer-policy/istio-inject-configmap.yaml
新增Calico需要的授权服务
应用以下清单以配置Istio以查询Calico以获取应用程序层策略授权决策
kubectl apply -f \
https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/manifests/app-layer-policy/istio-app-layer-policy.yaml
新增namespace标签
应用层策略仅对使用Envoy和Dikastes sidecar启动的pod生效。 没有这些sidecar的pods只会执行标准的Calico网络策略。
你可以基于每个命名空间来进行控制。 要在命名空间中启用Istio和应用层策略,请为namespace添加一个标签istio-injection = enabled。
kubectl label namespace <your namespace name> istio-injection=enabled
- 如果命名空间中已包含pod,则必须重新创建它们才能使其生效。
- Envoy必须能够访问到istio-pilot.istio-system服务。
6)观察部署结果
calico-node在正常运行之后,会根据CNI规范,在/etc/cni/net.d/目录下生成如下文件和目录,并在/opt/cni/bin目录下安装二进制文件calico和calico-ipam,供kubelet调用。
- 10-calico.conf:符合CNI规范的网络配置,其中type=calico表示该插件的二进制文件名为calico。
- calico-kubeconfig:Calico所需的kubeconfig文件。
- calico-tls目录:以TLS方式连接etcd的相关文件。
查看下kube-system命名空间下的calico-node容器和calico-kube-controllers容器的运行状态。
测试下几个Node节点间容器网络的路由信息
这样通过Calico就完成了Node间容器网络的设置。在后续的Pod创建过程中,kubelet将通过CNI接口调用Calico进行Pod网络的设置,包括IP地址、路由规则、iptables规则等。
注:如果设置CALICO_IPV4POOL_IPIP=”off”,即不使用IPIP模式,则Calico将不会创建tunl0网络接口,路由规则直接使用物理机网卡作为路由器进行转发。
2、通过Kubernetes API 进行数据存储的Calico部署方案
3、Calico的更多高级用法
4、Calico与已有基础设施的集成部署方案
对于一些已经在使用的技术系统,或是受整体网络环境影响制约的项目会因为一些特殊的情况,以致于不能直接采取前面介绍的几种Calico部署方案。官网上提供了在Kubernetes上自定义安装Calico所需的关键组件的方法,以便与配置管理集成。
建议大多数用户采用前面介绍的几种部署方法, 只有具有无法满足的特定需求的用户再遵循下面的说明,自定义安装和配置你的Calico服务。
- Installing calico/node
- Installing the Calico CNI plugins
- Installing the Calico Kubernetes controllers
- Role-based access control (RBAC)
第四部分、Calico与Kubernetes NetworkPolicy
1、关于quay.io/calico/kube-controllers容器
quay.io/calico/kube-controllers容器包含以下控制器:
- policy controller:监视网络策略和编程Calico策略,它会把Kubernetes的network policies同步到Calico datastore中,该控制器需要有访问Kubernetes API的只读权限,以监听NetworkPolicy事件。 用户在k8s集群中设置了Pod的Network Policy之后,calico-kube-controllers就会自动通知各个Node上的calico-node服务,在宿主机上设置相应的iptables规则,完成Pod间网络访问策略的设置。
- namespace controller:监视命名空间和编程Calico配置文件,它会把Kubernetes的namespace label变化同步到Calico datastore中,该控制器需要有访问Kubernetes API的只读权限,以监听Namespace事件。
- serviceaccount controller:监视服务帐户和编程Calico配置文件,它会把Kubernetes的service account变化同步到Calico datastore中,该控制器需要有访问Kubernetes API的只读权限,以监听ServiceAccount事件。
- workloadendpoint controller:监视pod标签的更改并更新Calico工作负载中的endpoints配置,它会把Kubernetes的pod label变化同步到Calico datastore中,该控制器需要有访问Kubernetes API的只读权限,以监听Pod事件。
- node controller:监视删除Kubernetes nodes节点的操作并从Calico中也删除相应的数据,该控制器需要有访问Kubernetes API的只读权限,以监听Node事件。
注:
- 除node controller外,其它功能的控制器均是默认启用的。但是如果你直接使用Calico提供的manifest部署 calico-kube-controllers容器,则仍然是通过配置ENABLED_CONTROLLERS选项打开了node controller控制器。启用node controller控制器,还需要配置第二个地方,就是在calico-node daemon set的manifest文件中需要添加一个环境变量CALICO_K8S_NODE_REF,取值为nodeName 。
- 以上所有的控制器都是仅在使用etcd作为Calico数据存储区时才有效。
- 该容器只能存在一个容器实例。
- 该容器必须在宿主机网络的命名空间中运行(hostNetwork: true),以使其不受容器网络访问控制策略的阻止。
2、Calico支持设置Pod间的访问策略,基本原理如下图所示
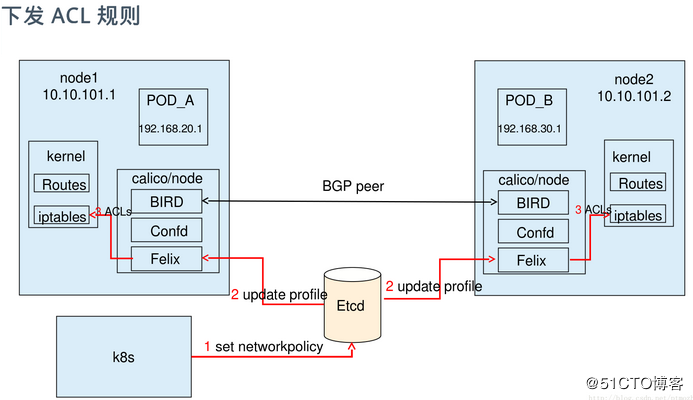
3、NetworkPolicy示例一:Calico NetworkPolicy的简单例子
下面提供了一种使用Calico实现Kubernetes NetworkPolicy的简单方法。 它需要使用Calico网络配置的Kubernetes集群,并需要使用kubectl以与集群进行交互。
1)创建一个新的Namespace
[k8s@calico-test net.d]$ kubectl create ns policy-demo
namespace/policy-demo created
- 我们针对新创建的这个命名空间启用并配置网络隔离策略
2)创建演示用的Pods
[k8s@calico-test ~]$ kubectl run --namespace=policy-demo nginx --replicas=2 --image=nginx kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead. deployment.apps/nginx created [k8s@calico-test ~]$ kubectl get pods --namespace=policy-demo NAME READY STATUS RESTARTS AGE nginx-7cdbd8cdc9-7svxc 1/1 Running 0 69s nginx-7cdbd8cdc9-hctg6 1/1 Running 0 69s [k8s@calico-test ~]$ kubectl get deployment --namespace=policy-demo NAME READY UP-TO-DATE AVAILABLE AGE nginx 2/2 2 2 86s [k8s@calico-test ~]$
为nginx创建一个对外的service:
[k8s@calico-test ~]$ kubectl expose --namespace=policy-demo deployment nginx --port=80 service/nginx exposed [k8s@calico-test ~]$ kubectl get svc --namespace=policy-demo NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx ClusterIP 10.106.255.161 <none> 80/TCP 9s
测试下nginx的服务是否正常:
[k8s@calico-test ~]$ kubectl run --namespace=policy-demo access --rm -ti --image busybox /bin/sh kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead. If you don't see a command prompt, try pressing enter. / # wget -q nginx -O -
3)启用网络隔离策略
我们为policy-demo命名空间设置启用网络隔离策略,Calico会阻止对该命名空间中pods的访问请求。
创建一个NetworkPolicy,默认阻止所有的访问请求,对policy-demo中全部的pods生效:
kubectl create -f - <<EOF
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: default-deny
namespace: policy-demo
spec:
podSelector:
matchLabels: {}
EOF
测试一下网络隔离策略的效果:
[k8s@calico-test ~]$ kubectl run --namespace=policy-demo access --rm -ti --image busybox /bin/sh kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead. If you don't see a command prompt, try pressing enter. / # wget -q --timeout=5 nginx -O - wget: download timed out / #
- 我们创建的这个临时容器会自动生成一个Label标签,即run=access。我们暂时保留这个临时容器,等增加一个授权策略后,再测试
新打开一个登录容器,创建一个网络策略的授权,允许我们创建的名为”access”的临时容器可以访问policy-demo中的nginx服务:
kubectl create -f - <<EOF kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: access-nginx namespace: policy-demo spec: podSelector: matchLabels: run: nginx ingress: - from: - podSelector: matchLabels: run: access EOF
- 回到前面的临时容器中再执行一下wget -q –timeout=5 nginx -O -,发现已经可以访问nginx服务了
创建另一个名为”cant-access”测试容器,可以看到无法访问到nginx服务了:
[k8s@calico-test ~]$ kubectl run --namespace=policy-demo cant-access --rm -ti --image busybox /bin/sh kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead. If you don't see a command prompt, try pressing enter. / # wget -q --timeout=5 nginx -O - wget: download timed out / #
可以执行下面命令,删除以上测试资源 :
kubectl delete ns policy-demo
4、NetworkPolicy示例二:Stars Policy Demo
1)创建frontend, backend, client, and management-ui 等应用
kubectl create -f https://docs.projectcalico.org/v3.4getting-started/kubernetes/tutorials/stars-policy/manifests/00-namespace.yaml
kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/manifests/01-management-ui.yaml
kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/manifests/02-backend.yaml
kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/manifests/03-frontend.yaml
kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/manifests/04-client.yaml
观察资源创建过程,因为涉及到镜像下载,所以需要几分钟:
kubectl get pods –all-namespaces –watch
检查下是否成功创建出以下资源:
[k8s@calico-test ~]$ kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE client client-qkvg7 1/1 Running 0 9m16s management-ui management-ui-5g2x2 1/1 Running 0 9m36s stars backend-67dl9 1/1 Running 0 9m35s stars frontend-ns44p 1/1 Running 0 9m33s
management-ui在Kubernetes上作为NodePort服务运行,并显示在此示例中服务的网络连接。
您可以通过在浏览器中访问http:// <k8s-node-ip>:30002来查看UI。
页面中的图标的:
- backend -> Node “B”
- frontend -> Node “F”
- client -> Node “C”
2)启用隔离策略
[k8s@calico-test ~]$ kubectl create -n stars -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/policies/default-deny.yaml networkpolicy.networking.k8s.io/default-deny created [k8s@calico-test ~]$ kubectl create -n client -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/policies/default-deny.yaml networkpolicy.networking.k8s.io/default-deny created
[k8s@calico-test ~]$
- 我们为stars和client两个命名空间都设置的默认拒绝所有访问的网络隔离策略
- 此时回到浏览器中访问http:// <k8s-node-ip>:30002,刷新下页面,发现management-ui已经无法获取和展示服务节点之间的网络连接信息了,仔细观察可以看到节点连接之间的网络流量示意
3)增加一个授权策略以允许UI应用访问stars和client命名空间中的服务
[k8s@calico-test ~]$ kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/policies/allow-ui.yaml
networkpolicy.networking.k8s.io/allow-ui created
[k8s@calico-test ~]$ kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/policies/allow-ui-client.yaml
networkpolicy.networking.k8s.io/allow-ui created
- 再刷新下UI界面,发现可以展示出所有的服务节点了
- 各个服务节点之间仍然是不能访问的,所以节点之间没有网络流量
4)创建一个backend-policy.yaml的授权策略,允许frontend访问backend
kubectl create -f https://docs.projectcalico.org/v3.4getting-started/kubernetes/tutorials/stars-policy/policies/backend-policy.yaml
- 等待一会,再刷新UI网页发现frontend可以访问到backend了,当然仅限于是tcp port 6379
- backend仍然不能访问到frontend
- client仍然不能访问到frontend和backend
5)增加一个授权client命名空间访问stars命名空间中frontend服务的网络策略
kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/tutorials/stars-policy/policies/frontend-policy.yaml
frontend-policy.yaml的内容如下:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: namespace: stars name: frontend-policy spec: podSelector: matchLabels: role: frontend ingress: - from: - namespaceSelector: matchLabels: role: client ports: - protocol: TCP port: 80
- 刷新下UI页面,看到client到frontend的连接也有流量了
如果需要使用Calico强化对egress policy的管理,继续看下面的章节。
6)一键清除以上测试资源
[k8s@calico-test ~]$ kubectl delete ns client stars management-ui namespace "client" deleted namespace "stars" deleted namespace "management-ui" deleted
5、NetworkPolicy示例三:使用网络策略控制入口和出口流量
Kubernetes NetworkPolicy API允许用户根据标签和端口配置Kubernetes pod的入口和出口网络流量管理策略(从Kubernetes 1.8.0开始)。
下面将介绍如何使用Kubernetes NetworkPolicy定义更复杂的网络策略。
1)创建一个新的命名空间并运行一个测试用途的nginx容器
[k8s@calico-test ~]$ kubectl create ns advanced-policy-demo namespace/advanced-policy-demo created [k8s@calico-test ~]$ kubectl run --namespace=advanced-policy-demo nginx --replicas=2 --image=nginx kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead. deployment.apps/nginx created [k8s@calico-test ~]$ kubectl expose --namespace=advanced-policy-demo deployment nginx --port=80 service/nginx exposed [k8s@calico-test ~]$
验证下入口和出口网络访问
另外打开一个登录容器,创建一个基于busybox的测试容器:
[k8s@calico-test ~]$ kubectl run --namespace=advanced-policy-demo access --rm -ti --image busybox /bin/sh kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead. If you don't see a command prompt, try pressing enter. / #
访问同命名空间里的另一个nginx服务,访问公网上的网站服务:
/ # wget -q --timeout=5 nginx -O - / # wget -q --timeout=5 baidu.com -O -
2)创建一个网络策略,阻止所有的入口网络流量
kubectl create -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
namespace: advanced-policy-demo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Ingress
EOF
再回到busybox的测试容器中验证上网络服务的可访问性:
/ # wget -q --timeout=5 nginx -O - wget: download timed out / # wget -q --timeout=5 baidu.com -O - <html> <meta http-equiv="refresh" content="0;url=http://www.baidu.com/"> </html> / #
- 可以看到入口流量已经被阻止,而出口网络流量还是正常的
3)创建一个nginx服务的入口网络策略
运行以下命令以创建NetworkPolicy,允许从advanced-policy-demo命名空间中的任何pod流量到nginx pod。
kubectl create -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
namespace: advanced-policy-demo
spec:
podSelector:
matchLabels:
run: nginx
ingress:
- from:
- podSelector:
matchLabels: {}
EOF
- 再回到busybox测试容器中,使用wget访问nginx服务,会发现已经可以访问了
4)阻止所有的出口网络流量
kubectl create -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
namespace: advanced-policy-demo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Egress
EOF
- 此时在busybox测试容器中执行wget -q –timeout=5 com-O -,会得到一个地址解析报错信息
- 执行nslookup nginx会发现,也不能访问到DNS服务
5)放行访问DNS的出口网络流量
运行以下命令以在kube-system命名空间上创建名称为kube-system的标签和一个NetworkPolicy策略,允许从advanced-policy-demo命名空间中的任何pod到kube-system命名空间的DNS服务的出口流量。
[k8s@calico-test ~]$ kubectl label namespace kube-system name=kube-system
namespace/kube-system labeled
kubectl create -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-dns-access
namespace: advanced-policy-demo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchLabels:
name: kube-system
ports:
- protocol: UDP
port: 53
EOF
6)继续放行访问nginx服务的网络出口流量
运行以下命令以创建NetworkPolicy,该策略允许从advanced-policy-demo命名空间中的任何pod的出口流量到具有与相同命名空间中的run:nginx匹配的标签的pod。
kubectl create -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-egress-to-advance-policy-ns
namespace: advanced-policy-demo
spec:
podSelector:
matchLabels: {}
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
run: nginx
EOF
从busybox测试容器中测试下访问同命名空间中的nginx服务,访问外部网站服务:
/ # wget -q --timeout=5 nginx -O - <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ...... </body> </html> / # wget -q --timeout=5 baidu.com -O - wget: download timed out / #
7)一键清除以上测试资源
[k8s@calico-test ~]$ kubectl delete ns advanced-policy-demo namespace "advanced-policy-demo" deleted [k8s@calico-test ~]$
第五部分、安装calicoctl命令行工具
calicoctl命令允许你通过命令行方式创建、访问、更新或删除Calico资源对象。
可以在任何具有访问Calico数据存储服务权限的主机上运行calicoctl作为二进制程序或容器服务。
有以下三种部署方法。
在单个主机上将calicoctl作为二进制文件安装
1)选择一个主机节点并进入/usr/local/bin/
2)下载calicoctl二进制文件
[k8s@calico-test ~]$ cd /usr/local/bin [k8s@calico-test bin]$ sudo curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.4.0/calicoctl % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 599 0 599 0 0 87 0 --:--:-- 0:00:06 --:--:-- 138 100 29.4M 100 29.4M 0 0 771k 0 0:00:39 0:00:39 --:--:-- 924k 3)增加执行权限 [k8s@calico-test bin]$ sudo chmod +x calicoctl 4)创建配置文件或环境变量 [k8s@calico-test ~]$ cd /etc/calico/ [k8s@calico-test calico]$ cat calicoctl.cfg apiVersion: projectcalico.org/v3 kind: CalicoAPIConfig metadata: spec: datastoreType: "etcdv3" etcdEndpoints: "http://10.96.232.136:6666" [k8s@calico-test calico]$ [k8s@calico-test calico]$ calicoctl get nodes NAME calico-test
- calicoctl需要从配置文件或环境变量中获取访问etcd服务的配置信息,详细配置可参考官网。
如果你的etcd服务启用了TLS时,可以这样配置calicoctl.cfg文件:
apiVersion: projectcalico.org/v3 kind: CalicoAPIConfig metadata: spec: etcdEndpoints: https://etcd1:2379,https://etcd2:2379,https://etcd3:2379 etcdKeyFile: /etc/calico/key.pem etcdCertFile: /etc/calico/cert.pem etcdCACertFile: /etc/calico/ca.pem
测试下命令是否可以正常使用了:
[k8s@calico-test calico]$ calicoctl get nodes NAME calico-test [k8s@calico-test calico]$ calicoctl get bgppeers NAME PEERIP NODE ASN
查看当前有哪些使用中的NetworkPolicy:
[k8s@calico-test calico]$ calicoctl get policy --all-namespaces NAMESPACE NAME advanced-policy-demo knp.default.access-nginx advanced-policy-demo knp.default.allow-dns-access advanced-policy-demo knp.default.allow-egress-to-advance-policy-ns advanced-policy-demo knp.default.default-deny-egress advanced-policy-demo knp.default.default-deny-ingress [k8s@calico-test ~]$ calicoctl get ippool NAME CIDR default-ipv4-ippool 172.200.0.0/16
在单个主机上将calicoctl作为容器安装
docker pull quay.io/calico/ctl:v3.4.0
将calicoctl作为Kubernetes pod安装
etcd作为后端datastore时
kubectl apply -f \
https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/calicoctl.yaml
- 如果启用了etcd TLS,则需要对上面配置文件更新证书和密钥部分
Kubernetes API datastore时
kubectl apply -f \
https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calicoctl.yaml
使用calicoctl命令的方法
kubectl exec -ti -n kube-system calicoctl — /calicoctl get profiles -o wide
推荐设置成一个alias别名
alias calicoctl=”kubectl exec -i -n kube-system calicoctl /calicoctl — ”
第六部分、关于使用Calico可能会涉及到的一些重要知识
1、kube-proxy modes in Calico
Calico支持kube-proxy的以下两种工作模式:
- iptables(默认)
- ipvs,要求K8s v1.9.3+
配置使用Calico+kube-proxy ipvs模式,可以参照:
- https://docs.projectcalico.org/v3.4/usage/enabling-ipvs
- https://docs.projectcalico.org/v3.4/reference/felix/configuration#ipvs-portranges
2、查看Calico插件日志的方法
Calico默认的日志输出级别为WARNING,输出到stderr,可以按需配置为INFO或DEBUG,日志由kubelet记录,如果是使用的systemd管理服务,则可以使用journalctl -u kubelet查看日志信息。
3、怎么使用Calico为pod分配一个固定的IP地址
相信我们很多传统的应用程序,在上容器云时或多或少都会遇到要求使用固定IP地址的难题,虽然这种要求很不符合k8s风格。使用Calico插件时,可以通过Calico IPAM的Kubernetes annotations功能达到请求特定的IP地址的目的。
用于请求特定IP地址的Annotations有两个批注可以使用。
注:annotations(批注)实际上和labels(标签)功能是相似的,不过annotations的数据格式上相对没有那么严格。
cni.projectcalico.org/ipAddrs
指定一个要分配给Pod的IPv4和/或IPv6地址列表。 请求的IP地址将从Calico IPAM分配,并且必须存在于已配置的IP pool中。
例如:
annotations:
“cni.projectcalico.org/ipAddrs”: “[\”192.168.0.1\”]”
cni.projectcalico.org/ipAddrsNoIpam
指定一个要分配给Pod的IPv4和/或IPv6地址列表,绕过IPAM。 任何IP冲突和路由配置都必须由人工或其他系统处理。 Calico仅处理那些属于Calico IP pool 中的IP地址,将其路由分发到Pod。 如果分配的IP地址不在Calico IP pool中,则必须确保通过其他机制正确地处理该IP地址的路由。
示例:
annotations:
“cni.projectcalico.org/ipAddrsNoIpam”: “[\”10.0.0.1\”]”
默认情况下是禁用了ipAddrsNoIpam功能。 使用该功能,则需要在CNI网络配置的feature_control部分中启用:
{
"name": "any_name",
"cniVersion": "0.1.0",
"type": "calico",
"ipam": {
"type": "calico-ipam"
},
"feature_control": {
"ip_addrs_no_ipam": true
}
}
- 此功能允许通过IP欺骗绕过网络策略。 用户应确保适当的准入控制,以防止用户使用了不当的IP地址。
注意事项:
- ipAddrs和ipAddrNoIpam不能同时使用;
- 只能使用这些批注指定一个IPv4/IPv6地址或一个IPv4和一个IPv6地址。
- 当ipAddrs或ipAddrsNoIpam与ipv4pools或ipv6pools一起使用时,ipAddrs/ipAddrsNoIpam有更高的优先级。
4、Calico CNI plugins配置说明
Calico CNI插件是按照标准的CNI配置规范进行配置的。
一个最小化的配置文件,像下面这样:
{
"name": "any_name",
"cniVersion": "0.1.0",
"type": "calico",
"ipam": {
"type": "calico-ipam"
}
}
如果节点上的calico-node容器注册了节点主机名以外的NODENAME,则此节点上的CNI插件必须配置使用相同的nodename,像下面这样:
{
"name": "any_name",
"nodename": "<NODENAME>",
"type": "calico",
"ipam": {
"type": "calico-ipam"
}
}
1)通用配置项
- datastore_type,Datastore type,default: etcdv3,设置为kubernetes时表示直接使用k8s api存取数据库服务;
- etcd location,在使用etcd作为后端数据库服务时,以下配置项有效:
- etcd_endpoints
- etcd_key_file
- etcd_cert_file
- etcd_ca_cert_file
- log_level,可选值为WARNING,INFO,DEBUG,默认值是WARNING,日志打印到stderr;
- ipam,IP地址管理工具,值为一个json字典,可以包含以下子配置项:
- “type”: “calico-ipam”
- “assign_ipv4”: “true”
- “assign_ipv6”: “true”
- “ipv4_pools”: [“10.0.0.0/24”, “20.0.0.0/16”, “default-ipv4-ippool”]
- “ipv6_pools”: [“2001:db8::1/120”, “default-ipv6-ippool”]
- “container_settings”: {“allow_ip_forwarding”: true} ,默认值为false,该选项允许在容器命名空间内配置设置。
2)Kubernetes相关的配置信息
将Calico CNI插件与Kubernetes一起使用时,插件必须能够访问Kubernetes API服务器才能找到分配给Kubernetes pod的标签。 建议的配置访问方式是通过网络配置的kubernetes部分中指定的kubeconfig文件。
例如
{
"name": "any_name",
"cniVersion": "0.1.0",
"type": "calico",
"kubernetes": {
"kubeconfig": "/path/to/kubeconfig"
},
"ipam": {
"type": "calico-ipam"
}
}
或者通过k8s API:
{
"name": "any_name",
"cniVersion": "0.1.0",
"type": "calico",
"kubernetes": {
"k8s_api_root": "http://127.0.0.1:8080"
},
"ipam": {
"type": "calico-ipam"
}
}
3)启用Kubernetes Policy
如果希望使用Kubernetes NetworkPolicy功能,则必须在网络配置中设置策略类型。 只有一个支持的策略类型,k8s。
{
"name": "any_name",
"cniVersion": "0.1.0",
"type": "calico",
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/path/to/kubeconfig"
},
"ipam": {
"type": "calico-ipam"
}
}
- 使用type:k8s时,Calico CNI插件需要对所有命名空间中的Pods资源具有只读Kubernetes API访问权限。
4)IPAM
使用CNI的host-local IPAM插件时,subnet字段允许使用一个特殊的值 “usePodCidr”(at the top-level or in a “range”)。 这告诉插件从Kubernetes API去获取Node.podCIDR字段,以确定自己要使用的子网。 Calico不使用网段范围的网关字段,因此不需要该字段,如果提供了则也将忽略该字段。
注意:usePodCidr只能用作子网字段的值,不能在rangeStart或rangeEnd中使用,因此如果子网设置为usePodCidr,则这些值无用。
Calico支持host-local IPAM插件的routes 字段,如下所示:
- 如果没有routes字段,Calico将在pod中安装默认的0.0.0/0和/或::/0的路由规则(取决于pod是否具有IPv4和/或IPv6地址)。
- 如果存在routes字段,则Calico将仅将routes字段中的路由规则添加到pod中。 由于Calico在pod中实现了点对点链接,因此不需要gw字段,如果存在则会忽略它。 Calico安装的所有路由都会将Calico的link-local IP作为下一跳。
- node_name字段,指定用于查询”usePodCidr”的节点的nodename,默认值为当前节点的hostname。
{
"name": "any_name",
"cniVersion": "0.1.0",
"type": "calico",
"kubernetes": {
"kubeconfig": "/path/to/kubeconfig",
"node_name": "node-name-in-k8s"
},
"ipam": {
"type": "host-local",
"ranges": [
[
{ "subnet": "usePodCidr" }
],
[
{ "subnet": "2001:db8::/96" }
]
],
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "2001:db8::/96" }
]
}
}
5)基于每个命名空间或每个pod指定专属IP pool
Calico IPAM支持为每个命名空间或者是每个pod,指定专用的IP pool资源,这一功能是通过应用Kubernetes annotations来实现的。
cni.projectcalico.org/ipv4pools
已配置的IPv4 pool列表,可从中选择Pod的地址。
annotations:
“cni.projectcalico.org/ipv4pools”: “[\”default-ipv4-ippool\”]”
cni.projectcalico.org/ipv6pools
已配置的IPv6 pool列表,可从中选择Pod的地址。
annotations:
“cni.projectcalico.org/ipv6pools”: “[\”2001:db8::1/120\”]”
如果提供上面这样的配置,这些指定的IP pool将覆盖CNI基础配置中指定的任何IP pool资源。
Calico CNI插件支持为每个命名空间设置annotation批注信息。 如果命名空间和pod都有此配置,则将使用pod的信息。 否则,如果只有命名空间做了这样的批注,则命名空间的批注信息将用于其中的每个pod。
5、配置BGP Peers
本文描述了calicoctl中用于管理BGP的命令。 它涵盖了以下配置:
- Global default node AS Number
- The full node-to-node mesh
- Route reflector function
- BGP peers in general
- Global BGP Peers
- Node-specific BGP peers
1)一些关键概念
自治系统(AS)编号
全局默认节点AS编号是未明确指定时Calio 节点上BGP agent使用的AS编号。 当你的网络拓扑允许所有Calico节点使用相同的AS编号时,设置此值可简化配置。
Calico节点的AS编号通过以下方式定义:
- 通过Node的bgp.asNumber(如果已定义);
- 否则由默认BGPConfiguration resource的asNumber(如果已定义);
- 否则,设置为64512(在IANA范围内供私有使用)。
Node-to-node mesh
一个节点到节点的全网状网络配置选项提供了一种机制,可以自动配置所有Calico节点之间的对等关系。 启用该机制后,每个Calico节点都会自动与网络中的每个其他Calico节点建立BGP对等关系。 默认情况下已启用此功能。
全网状网络提供了一种简单的机制,用于在小规模集群部署中自动配置BGP网络(比如少于50个节点)。这个限制并非绝对,Calico已有在全网状拓扑中部署了100多个节点的例子。
对于大规模集群部署,或者对于需要特定的BGP拓扑(例如 peering with ToR switches)的部署,应该禁用全网状网络,并为Calico节点显示配置 BGP 对等体。 既可以在Calico网络中将BGP对等体配置为全局BGP对等体,也可以配置为单节点BGP对等体。
Route reflector function
可以将Calico节点配置为充当其他Calico节点的Route reflector,同时作为其自身工作负载的始发路由。 通过设置Node的spec.bgp.routeReflectorClusterID来启用此功能。 通常,你还需要添加一个标签以将该node节点标识为Route reflector。
Calico节点也支持与群集外的其他路由反射器设备建立对等关系。
BGP peers in general
Calico BGPPeer resource提供了几种方式来表示某些Calico节点应与其他Calico节点或与IP标识的其他BGP speakers建立对等。 除了使用默认的全网状网络之外,还可以选择使用这些配置方式建立需要的BGP网络。 BGPPeer可以指定所有Calico节点都应该具有某些对等体,或者只与一个特定的Calico节点建立对等,再或者与指定标签选择器匹配的一组Calico节点都建立对等。
Global BGP peers
在BGPPeer的spec.node和spec.nodeSelector字段都为空时即代表是一个全局BGP对等体。
全局BGP对等体是与网络中的每个Calico节点对等的BGP代理。 全局对等体的典型使用场景是中等规模的集群部署,其中所有Calico节点在相同的一个L2网络上,并且每个节点都与相同的路由反射器(或一组路由反射器)对等。
Node-specific BGP peers
这是BGPPeer的spec.node或spec.nodeSelector字段非空时的情况。
从部署规模上看,可以使用不同的网络拓扑结构。 例如,在AS/Rack模型中,每个Calico节点与机架顶部(ToR)交换机中的路由反射器对等。 在这种情况下,BGP对等基于每个节点配置,或者由给定标签选择器标识的一组节点配置(即,这些是节点特定的对等体)。 在每机架AS模型中,机架中的每个Calico节点将配置为ToR路由反射器的节点的特定对等。
2)配置默认的node AS number
创建Calico节点时,可以选择指定要用于节点的AS编号。 如果未指定AS编号,则节点将使用全局默认值。
请参见下面的示例以设置全局默认AS编号。 设置全局默认AS编号时, 如果未配置任何值,则默认AS编号为64512。
如果所有Calico节点都在同一个AS内,但您需要使用不同的AS编号(例如,因为您正在使用边界路由器),将默认AS编号更改为您需要的值无需基于每个Calico节点显式设置它。 对于在每个节点上显式设置AS编号的更复杂的拓扑,将不使用默认值,因此不需要使用此命令。
3)禁用全网状BGP网络
如果你需要明确为Calico网络配置BGP拓扑,则可能希望禁用默认的全网状网络。 有关更改nodeToNodeMeshEnabled全局BGP设置参数的说明,请参阅下面的示例。
如果是构建一套新的网络环境并且不需要使用full node-to-node mesh网络,建议在配置节点之前就关闭它。 如果要将网络从当前的全网状拓扑更新为不同的拓扑(例如,增加使用路由反射器来增加扩展性),请在禁用全网状网络之前先配置好相应的对等体,以确保网络服务的连续性。
关闭full node-to-node mesh网络或修改全局AS编号,请参照以下配置示例。
a)检查下是否已经有default BGP配置资源
[k8s@calico-test ~]$ calicoctl get bgpconfig default
Failed to get resources: resource does not exist: BGPConfiguration(default) with error: <nil>
b)如果资源已存在,则直接跳到下一步骤,否则执行以下命令创建该资源
可以按实际需要修改nodeToNodeMeshEnabled 和 asNumber这两个参数值。
cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPConfiguration metadata: name: default spec: logSeverityScreen: Info nodeToNodeMeshEnabled: false asNumber: 63400 EOF [k8s@calico-test ~]$ calicoctl get bgpconfig default NAME LOGSEVERITY MESHENABLED ASNUMBER default Info false 63400
c)如果default资源已经存在,执行以下命令导出一份配置文件
calicoctl get bgpconfig default –export -o yaml > bgp.yaml
d)按需修改bgp.yaml中的配置参数,执行以下命令使配置生效
calicoctl replace -f bgp.yaml
4)配置一个全局BGP对等体
如果你的网络拓扑包括将与部署中的每个Calico节点建立对等的BGP speakers,则可以使用calicoctl命令在Calico节点上与其设置对等。 我们将这种类型的对等体称为全局对等体,因为它们在Calico中只需要配置一次(全局),Calico将安排每个Calico节点都去与这些对等体对准。
全局BGP对等配置有两种使用场景。
(1)添加边界路由器,该边界路由器对等于full node-to-node mesh网络。
(2)在Calico网络中配置使用一个或两个路由反射器以提供适度的部署规模支持。在后一种情况下,每个Calico节点将与每个路由反射器对等,并且将禁用全网状网络。
配置示例。
添加一个IP地址为192.20.30.40且AS号为64567的全局BGP对等体,请在集群中所有节点上运行以下命令:
cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: bgppeer-global-3040 spec: peerIP: 192.20.30.40 asNumber: 64567 EOF
查看:
[k8s@calico-test ~]$ calicoctl get bgpPeer NAME PEERIP NODE ASN bgppeer-global-3040 192.20.30.40 (global) 64567
删除:
calicoctl delete bgppeer bgppeer-global-3040
5)配置特定节点的BGP对等体
如果你的网络拓扑需要配置Calico节点与特定的节点建立bgp对等,则可以使用calicoctl命令来设置指定Calico节点的对等体。 我们将这些称为node-specific的对等体。
当BGP拓扑变得更复杂并且在不同节点上需要使用不同的对等时,就必须配置node-specific的对等体了。
配置示例。
要添加一个IP地址1.2.3.4,AS号为64514,Calico节点名称“node1”的BGP对等体,请在集群中所有节点上运行以下命令:
cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: bgppeer-node-1234 spec: peerIP: 1.2.3.4 node: node1 asNumber: 64514 EOF 查看:
[k8s@calico-test ~]$ calicoctl get bgpPeer bgppeer-node-1234 NAME PEERIP NODE ASN bgppeer-node-1234 1.2.3.4 node1 64514
删除:
[k8s@calico-test ~]$ calicoctl delete bgppeer bgppeer-node-1234 Successfully deleted 1 'BGPPeer' resource(s) [k8s@calico-test ~]$
6)检查BGP peers的健康状态
要查看指定节点的所有BGP对等的运行状态,可以使用calicoctl node status命令。 这将显示该节点的所有BGP对等方的状态。这包括自动配置为full node-to-node mesh的一部分的对等方以及显式配置的全局对等方和node-specific的对等方。
了解BGP对等的运行状态是诊断无法在网络中通告路由故障的第一步。
[root@calico-test mysql-python]# calicoctl node status Calico process is running. IPv4 BGP status No IPv4 peers found. IPv6 BGP status No IPv6 peers found.
7)配置集群内部使用的路由反射器
对于更大规模的部署,你可以禁用full node-to-node mesh网络,然后配置一些节点作为集群内部的路由反射器使用。 Calico在calico/node镜像中包含了可选的route reflector功能,启用该功能后,每个节点仍然可以获得所有的工作负载路由,但使用的BGP连接数量要少得多。
配置Route reflector的示例
a)挑选一个或多个Calico节点作为路由反射器。 只要该节点保持运行,虽然最少只需要一个,但建议选择两个或三个,以便在其中一些节点需要停机维护时,可以继续保证路由得到正确的传播。
b)修改选中节点的Node resource配置信息:
- 配置bgp.routeReflectorClusterID ,设置一个非空的值作为 cluster ID,比如 224.0.0.1,启用当前节点作为集群内的route reflector;
- 添加一个标签,指明该节点是路由反射器。
例如:
[k8s@calico-test ~]$ calicoctl get node calico-test --export -o yaml > node.yml [k8s@calico-test ~]$ cat node.yml apiVersion: projectcalico.org/v3 kind: Node metadata: creationTimestamp: null name: calico-test spec: bgp: ipv4Address: 10.0.2.15/24 ipv4IPIPTunnelAddr: 172.200.89.192 orchRefs: - nodeName: calico-test orchestrator: k8s [k8s@calico-test ~]$
编辑node.yml文件:
apiVersion: projectcalico.org/v3 kind: Node metadata: creationTimestamp: null name: calico-test labels: i-am-a-route-reflector: true spec: bgp: ipv4Address: 10.0.2.15/24 ipv4IPIPTunnelAddr: 172.200.89.192 routeReflectorClusterID: 224.0.0.1 orchRefs: - nodeName: calico-test orchestrator: k8s
应用配置:
[k8s@calico-test ~]$ calicoctl apply -f node.yml
Successfully applied 1 ‘Node’ resource(s)
- 对于一个简单部署,所有的路由反射器节点可以设置为相同的群集ID。
c)配置一个BGPPeer resource,告诉其他Calico节点与路由反射器节点建立对等
calicoctl apply -f - <<EOF kind: BGPPeer apiVersion: projectcalico.org/v3 metadata: name: peer-to-rrs spec: nodeSelector: !has(i-am-a-route-reflector) peerSelector: has(i-am-a-route-reflector) EOF
d)配置一个 BGPPeer resource告诉route reflector节点之间相互建立对等
calicoctl apply -f - <<EOF kind: BGPPeer apiVersion: projectcalico.org/v3 metadata: name: rr-mesh spec: nodeSelector: has(i-am-a-route-reflector) peerSelector: has(i-am-a-route-reflector) EOF
至此,路由反射器之间的这个全网状网络已经配置完成,即将所有工作负载路由传播到了所有节点。 或者,路由反射器可能不会直接相互对等,而是通过某些上游设备(如Top of Rack路由器)。
参考资料:
https://docs.projectcalico.org/v3.4
https://istio.io/docs/setup/kubernetes
https://blog.csdn.net/watermelonbig/article/details/84981945
《Kubernetes权威指南——从Docker到Kubernetes实践全接触》
http://cizixs.com/2017/10/19/docker-calico-network
作者:高庆 百悟科技 高级运维工程师

博主,你好,一直想知道calico这个怎么读呢?/kalikou/吗?