
左宇鹏
2014年毕业于北京工业大学计算机学院,曾就职于某大型国企从事数据库运维工作。2018年3月加入民生银行信息科技部系统管理中心团队,目前主要致力于基于kubernetes和docker的容器平台和ceph分布式存储的研究和运维工作。
背景
近年来,随着人工智能、机器学习、深度学习等技术的火热,GPU也得到了快速的发展。GPU的使用可以从很大程度上加快深度学习任务的运行速度,而诸如tensorflow框架的出现和应用更是离不开对GPU资源的依赖。
民生银行在一个深度学习项目中,部署了一套支持GPU的Kubernetes集群,开始了Kubernetes+GPU+Tensorflow的深度学习之旅。
Kubernetes(以下简称k8s)在版本1.6后正式支持对Nvidia GPU的调度功能,在版本1.9后又加入了对AMD GPU的支持。本文以Nvidia GPU为例,具体介绍k8s集群GPU节点的部署与使用实践,供大家参考借鉴。
二、环境介绍
操作系统版本:SUSE12SP3
K8s版本:1.9
Docker版本:17.06
Nvidia GPU型号:GeForce GTX 1080 Ti
K8s集群已提前部署好,并且将GPU节点加入到集群中。
三、Device Plugin概述
K8s从1.8版本开始到1.10版本之前,为了支持GPU的调度,必须设置–feature-gates=”DevicePlugins=true”参数来开启DevicePlugins功能,从1.10版本开始不再需要设置该参数。
Device Plugin实际上是一个gRPC接口,设备厂商只需要根据Device Plugin的接口实现一个特定设备的插件,而不需要修改k8s的核心代码。
Nvidia GPU Device Plugin需要k8s集群的GPU节点具备如下条件:
节点必须预先安装好nvidia 驱动
节点必须预先安装好nvidia-docker 2.0
docker的default runtime必须配置成nvidia-container-runtime,而不是runc
nvidia驱动版本在361.93以上
四、GPU节点驱动安装
一
确认主机有nvidia显卡
# lspci |grep -i nvidia
04:00.0 VGA compatible controller: NVIDIA Corporation Device 1b06 (rev a1)
04:00.1 Audio device: NVIDIA Corporation Device 10ef (rev a1)
二
安装依赖包
# zypper install -y gcc make
三
安装与kernel版本一致的kernel development packages
# zypper install -y kernel–devel=
其中,上面的variant和version需要与当前运行的kernel的variant和version保持一致。
# uname -r
4.4.92-6.18-default
从上面的结果可以确定,variant=default,version=4.4.92-6.18,所以安装如下devel package
# zypper install -y kernel-default-devel=4.4.92-6.18
由于kernel-default-devel依赖于kernel-devel,所以需要先安装相同版本的kernel-devel
# zypper install -y kernel-devel=4.4.92-6.18
四
nvidia官网下载驱动
登录nvidia官网https://www.nvidia.com/download/index.aspx设置检索条件下载相应的驱动。
这里下载的驱动版本是NVIDIA-Linux-x86_64-390.87.run
五
安装nvidia驱动
# sh NVIDIA-Linux-x86_64-390.87.run -a -s -q
六
验证是否安装成功
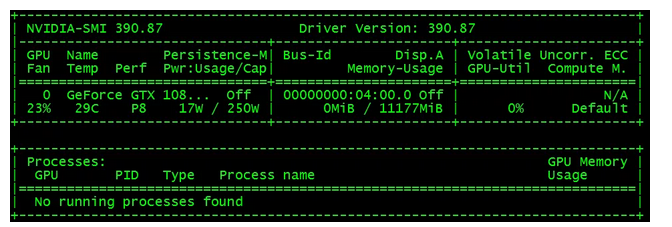
# nvidia-smi
显示如下结果,说明安装成功。
五、nvidia-docker安装配置
nvidia-docker是nvidia为了提高Nvidia GPU在docker中的易用性, 通过对原生docker的封装实现了自己的 nvidia-docker 工具。
nvidia-docker 对于使用GPU资源的docker容器支持的层次关系如下图所示:
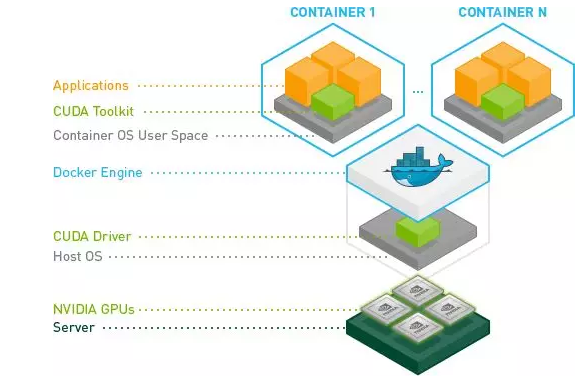
nvidia-docker 使得 docker 对于 GPU 资源的使用更加容易。截止到目前 nvidia-docker 官方经过了两次大版本的迭代,nvidia-docker和nvidia-docker2。nvidia-docker2在 nvidia-docker的基础上易用性和架构层面做了更多的优化。nvidia-docker2目前官方支持的操作系统版本主要包括Ubuntu 14.04/16.04/18.04、Debian Jessie/Stretch、Centos 7、Redhat 7.4/7.5、Amazon Linux 1/2,详细信息及安装方法可参考https://nvidia.github.io/nvidia-docker。
由于nvidia-docker2目前还不支持suse操作系统,所以为了使suse环境下的docker能够使用GPU资源,我们将nvidia-container的相关组件重新编译以兼容当前环境下的docker版本,达到与nvidia-docker2相同的效果。
一
安装nvidia-container-runtime
# rpm -ivh libnvidia-container1-1.0.0-0.1.alpha.3.x86_64.rpm # rpm -ivh libnvidia-container-tools-1.0.0-0.1.alpha.3.x86_64.rpm # rpm -ivh nvidia-container-runtime-1.1.1-99.docker17.06.2.x86_64.rpm
二
修改docker的default runtime
编辑/etc/docker/daemon.json文件,添加如下内容:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
六、K8s开启DevicePlugins功能
一
在master各节点和GPU节点上的kubelet加入启动参数
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf文件的配置
Environment=”KUBELET_FEATURE_GATES_ARGS=–feature-gates=DevicePlugins=true”
重启kubelet使参数生效
# systemctl daemon-reload
# systemctl restart kubelet
检查新增参数是否生效
# ps -ef|grep kubelet
二
在master各节点的kube-apiserver、kube-controller-manager、kube-scheduler加入启动参数
各节点依次修改/etc/kubernetes/manifests目录下的3个文件。
分别是kube-apiserver.yaml、kube-controller-manager.yaml、kube-scheduler.yaml,添加如下内容:
– –feature-gates=DevicePlugins=true
检查新增参数是否生效
# ps -ef|grep apiserver # ps -ef|grep controller # ps -ef|grep scheduler
七、部署nvidia-device-plugin
创建nvidia-device-plugin.yaml文件,添加如下内容:
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: nvidia-device-plugin-daemonset namespace: kube-system spec: template: metadata: annotations: scheduler.alpha.K8s.io/critical-pod: "" labels: name: nvidia-device-plugin-ds spec: tolerations: - key: CriticalAddonsOnly operator: Exists containers: - image: nvidia/k8s-device-plugin:1.9 name: nvidia-device-plugin-ctr securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins
在master节点上执行如下命令部署nvidia-device-plugin
# kubectl apply -f nvidia-device-plugin.yaml
查看部署情况
# kubectl get pod -n kube-system|grep nvidia nvidia-device-plugin-mlp3com 1/1 Running 29 7d
在master节点上查看GPU节点信息,看k8s能否识别节点的GPU资源
# kubectl describe node
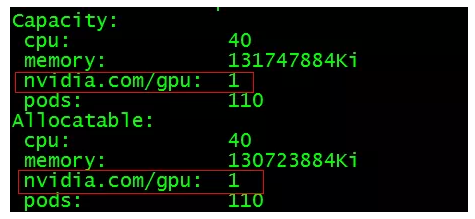
如上图所示,表明配置成功。如果未出现GPU或者GPU后面的数字是0,说明配置失败。至此,k8s集群就可以调度节点上的GPU资源了。
八、Tensorflow应用部署测试
为了进一步验证k8s可以成功调度GPU,我们部署了一个基于GPU的tensorflow应用做一下简单的测试。
下面是应用的部署配置文件gpu-test.yaml
apiVersion: v1 kind: Service metadata: name: cmbc-serving labels: app: tensorflow-serving spec: type: NodePort ports: - name: http-serving port: 5000 targetPort: 5000 selector: app: tensorflow-serving --- # Source: tensorflow-serving/templates/deployment.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: cmbc-serving labels: app: tensorflow-serving spec: replicas: 1 strategy: type: RollingUpdate template: metadata: labels: app: tensorflow-serving spec: hostNetwork: true containers: - name: serving image: "fast-style-transfer-serving:la_muse" imagePullPolicy: "IfNotPresent" env: command: ["python", "app.py"] ports: - containerPort: 5000 name: http-serving resources: limits: nvidia.com/gpu: 1
执行下面命令创建应用:
# kubectl apply -f gpu-test.yaml
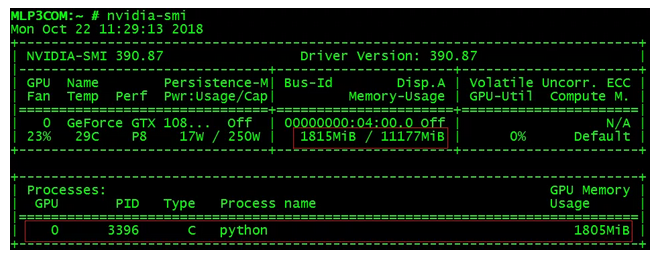
此时在GPU节点上执行nvidia-smi,查看GPU使用情况,从下图中可以看到,k8s会自动选择带有GPU的节点部署应用,并且应用成功地使用GPU资源进行计算,以处理外部的访问请求。
九、总结
至此,使用k8s调度GPU部署tensorflow应用的主要流程已经介绍完了,还有很多需要完善的地方,比如tensorflow在k8s中的模型训练、k8s如何支持GPU的亲和性等等。总之,这只是我们前期的初步探索,未来会根据进展情况再与大家分享。
来源:民生运维

登录后评论
立即登录 注册