
文章楔子
本文旨在通过最简易的方式指导读者将现有的,kubeadm创建的单master集群升级为HA master集群。
升级过程无痛,使用kubeadm原生的功能实现,不需要重启docker及无关容器。
除k8s集群控制相关功能(部署、升级、删除、查看、调度等),用户的服务不会被中断。
升级过程可以将原来是worker的机器平滑纳入HA master中,同时不影响原来worker上的容器。
本文中的自动化部署脚本可以在Lentil1016/kubeadm-ha找到,欢迎Star/Fork/提issue和PR。
在我的环境上进行示例升级的录像可以在该链接查看。
额外的,考虑到需要平滑升级的集群一般为正在使用中的集群,甚至可能涉及到生产集群,因此特别提醒读者。
本文升级过程中如果产生故障,通常需要手动修改ETCD的Cluster状态以回退或继续升级。
因此要求维护人员对于ETCD集群重建,成员添加、删除等有一定经验。
数据无价,请不要贸然操作。
本文升级过程为作者原创(可能是首创),尚处于验证的早期,仅在为数不多的集群上进行过测试。
本指导文章很可能还会继续演进,完善指导,并添加故障恢复等内容。
作者在kubernetes/website提交了一份proposal,想申请将”平滑升级”的内容加入到官方文档。
如果有人对该文档有什么需求或者期望可以去上面的链接里提,让社区看到这种需求是存在的。
但也不要随便@人家哈,社区的维护者比较忙。
升级前
升级摘要
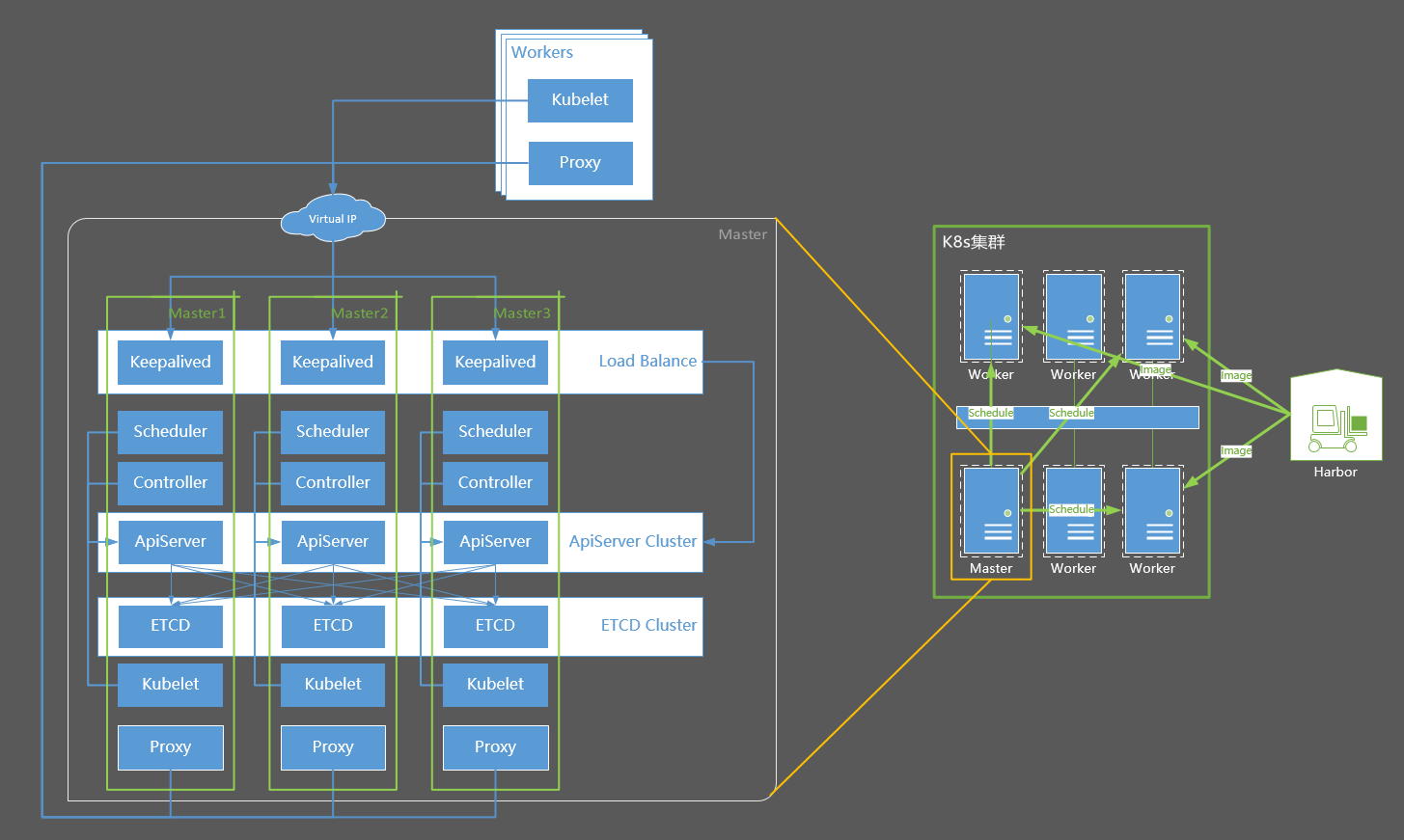
升级后,原来的单master将变成HA master中的master-1,另外会有两台master备机作为master-2/master-3被加入集群,其中master-2/master-3既可以是新的、集群外部的机器,也可以是原来集群中的worker机器。
升级的基本步骤如下:
- 删除master-1上原有的 KubeConfig、manifest/etcd、pki/etcd-server、pki/etcd-peer、pki/apiserver
- 使用 kubeadm alpha phase 命令重新创建上列配置
- 重启master-1上的 apiserver/controller/scheduler/etcd 容器
- 修改master-1上ETCD中0号member的PeerUrl=https://127.0.0.1:2380为https://{master_1_IP}:2380
- 配置新的master备机到集群中
各个机器的主机信息以及IP分布如下:
- Distribute: CentOS 7
- Docker: 17.03.2-ce
- Kernel: 4.4.152-1.el7.elrepo.x86_64
- Kubernetes: 1.11.0
- NetPlugin: Calico
- Proxy-Mode: IPVS
- Master-Mode: HA Master
- DNS: CoreDNS
|
Host Name
|
Old Role
|
New Role
|
IP
|
|---|---|---|---|
| centos-7-x86-64-29-80 | master | master-1 | 10.130.29.80 |
| centos-7-x86-64-29-81 | worker | master-2 | 10.130.29.81 |
| centos-7-x86-64-29-82 | Not in cluster | master-3 | 10.130.29.82 |
| harbor | image registry | image registry | 10.130.38.80 |
| – | Virtual IP | 10.130.29.83 |
前置条件
- master-2/master-3上已经正确的部署了kubeadm/kubectl/kubelet/docker
- 集群所有机器上的内核版本高于4.0,并且安装了ipvsadm。以便开启ipvs,如果不想开启,请自行修改升级脚本,去掉kube-proxy的ipvs配置
- master-1/master-2/master-3上已经安装了keepalived,并且规划了一个VIP以备使用。
- master-1/master-2/master-3上可以拉取到k8s相关镜像。如果需要离线包,请参考kubeadm HA集群搭建指南中“安装私有镜像库”一节
配置免密码登陆
请格外注意,请以现有的单master作为master-1机器,另两台master备机分别作为master-2 master-3。
ssh-keygen# 三次回车后,密钥生成完成 cat ~/.ssh/id_rsa.pub # 得到该机器的公钥如下图

将该公钥复制,并分别登陆到master-1 master-2 master-3的root用户,将它令起一行粘贴到 ~/.ssh/authorized_keys 文件中,包括master-1自己
复制完成后,从master-1上分别登陆master-1 master-2 master-3测试是否可以免密码登陆(请不要跳过这一步),可以的话便可以继续执行下一步
升级至HA Master
升级脚本解析
本节内容为升级脚本的过程简介,章节中出现的代码均为从升级脚本中节选的代码,不需要单独执行。具体的升级命令在下一节给出。
升级脚本和kubeadm HA集群搭建指南一文中的自动部署脚本只有细微的不同,在kubeha-gen.sh脚本中本应执行“kubeadm init”命令的地方,在kubeha-upgrade.sh脚本中变成了以下步骤
- 删除master-1上原有的 KubeConfig、manifest/etcd、pki/etcd-server、pki/etcd-peer、pki/apiserver
- 使用 kubeadm alpha phase 命令重新创建上列配置
- 重启master-1上的 apiserver/controller/scheduler/etcd 容器
- 修改master-1的PeerUrl=https://127.0.0.1:2380为https://{master_1_IP}:2380
在升级脚本中,上述步骤对应的代码如下
pushd /etc/kubernetes;
# 删除master-1上原有的 KubeConfig、manifest/etcd、pki/etcd-server、pki/etcd-peer、pki/apiserver
rm admin.conf controller-manager.conf kubelet.conf scheduler.conf manifests/etcd.yaml pki/apiserver.crt pki/apiserver.key pki/etcd/server.crt pki/etcd/server.key pki/etcd/peer.crt pki/etcd/peer.key
# 使用 kubeadm alpha phase 命令重新创建上列配置
kubeadm alpha phase certs apiserver --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase certs etcd-server --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase certs etcd-peer --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase etcd local --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubeconfig all --config /etc/kubernetes/kubeadm-config.yaml
# 重启master-1上的 apiserver/controller/scheduler/etcd 容器
echo "Restarting etcd/apiserver/controller/scheduler containers."
docker ps|grep -E 'k8s_kube-scheduler|k8s_kube-controller-manager|k8s_kube-apiserver|k8s_etcd'|awk '{print $1}'|xargs -i docker rm -f {} > /dev/null
systemctl restart kubelet
cp /etc/kubernetes/admin.conf ~/.kube/config
popd
# 修改master-1的PeerUrl=https://127.0.0.1:2380为https://{master_1_IP}:2380
ETCD=`kubectl get pods -n kube-system 2>&1|grep etcd|awk '{print $3}'`
echo "Waiting for etcd bootup..."
while [ "${ETCD}" != "Running" ]; do
sleep 1
ETCD=`kubectl get pods -n kube-system 2>&1|grep etcd|awk '{print $3}'`
done
ETCD_MASTER_ID=`kubectl exec \
-n kube-system etcd-${CP0_HOSTNAME} -- etcdctl \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--cert-file /etc/kubernetes/pki/etcd/peer.crt \
--key-file /etc/kubernetes/pki/etcd/peer.key \
--endpoints=https://${CP0_IP}:2379 \
member list | awk -F ':' '{print $1}'`
echo "Updating the PeerUrl of ETCD master [${ETCD_MASTER_ID}]"
kubectl exec \
-n kube-system etcd-${CP0_HOSTNAME} -- etcdctl \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--cert-file /etc/kubernetes/pki/etcd/peer.crt \
--key-file /etc/kubernetes/pki/etcd/peer.key \
--endpoints=https://${CP0_IP}:2379 \
member update ${ETCD_MASTER_ID} https://${CP0_IP}:2380
kubectl exec \
-n kube-system etcd-${CP0_HOSTNAME} -- etcdctl \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--cert-file /etc/kubernetes/pki/etcd/peer.crt \
--key-file /etc/kubernetes/pki/etcd/peer.key \
--endpoints=https://${CP0_IP}:2379 \
member list
开始升级
请格外注意,请以现有的单master作为master-1机器,对应下面cluster-info中的CP0,另两台master备机分别作为master-2 master-3。否则可能部署失败,使集群状态难以恢复。
示例升级的过程可以在该链接查看。
# 创建集群信息文件 echo """ CP0_IP=10.130.29.80 CP0_HOSTNAME=centos-7-x86-64-29-80 CP1_IP=10.130.29.81 CP1_HOSTNAME=centos-7-x86-64-29-81 CP2_IP=10.130.29.82 CP2_HOSTNAME=centos-7-x86-64-29-82 VIP=10.130.29.83 NET_IF=eth0 CIDR=172.168.0.0/16 """ > ./cluster-info bash -c "$(curl -fsSL https://raw.githubusercontent.com/Lentil1016/kubeadm-ha/1.11.0/kubeha-upgrade.sh)" # 该步骤将可能持续2到10分钟,在该脚本进行安装部署前,将有一次对安装信息进行检查确认的机会
随后升级完成
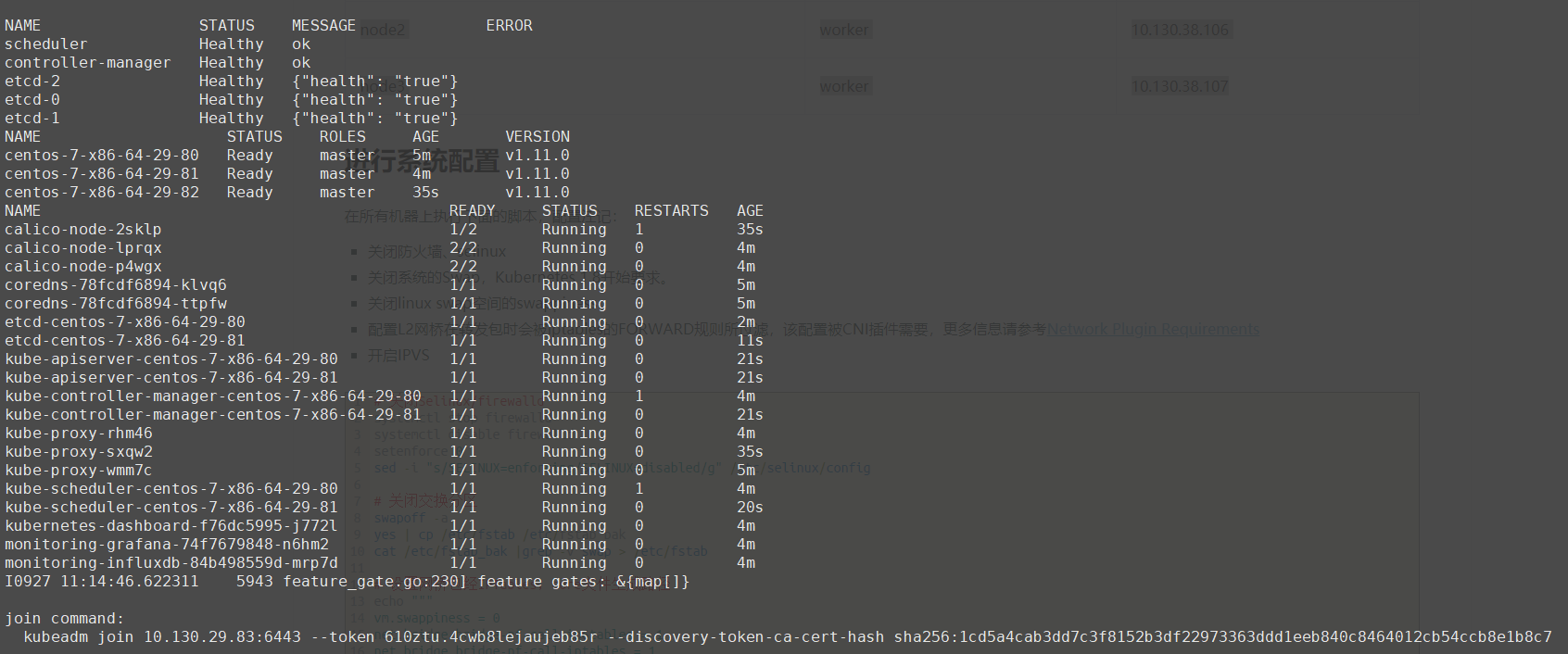
后续处理
刚刚升级完成后,三台master机器上都被加上了node-role.kubernetes.io/master:NoSchedule这个瑕疵,即使之前已经删除掉,升级后也会被重新加上。如果需要某个节点既做master又做worker,还需要重新执行下面的命令去掉这个瑕疵
kubectl taint node {node_name} node-role.kubernetes.io/master-

登录后评论
立即登录 注册