
作者/讲师:杨朝乐/才云科技软件工程师
才云基础设施部分运维开发工程师,专注于 Kubernetes 部署及运维。
来源:K8sMeetup
大家好,我叫杨朝乐,来自才云科技基础设施部门。今天给大家分享一个平时可能接触得较少的话题:关于 Kubernetes 的稳定性和可用性。
下面是今天分享以下 5 个主题:
- 认识稳定性
- 认识异常
- Kubernetes 里面的高可用方案
- 如何处理异常
- 我的经验分享
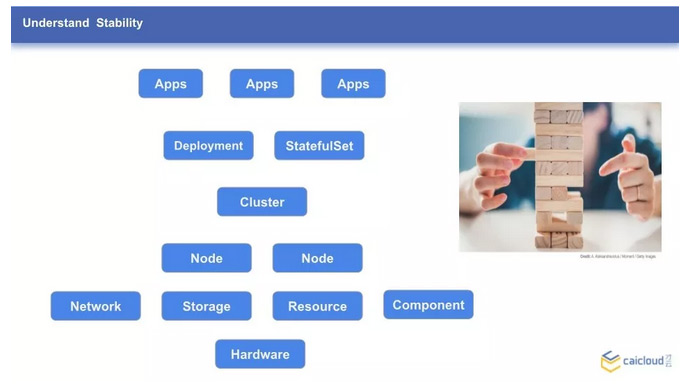
认识稳定性
Kubernetes 集群的稳定性和众多因素相关。比如我们有一个集群,上面会有很多应用,这些应用可能是无状态的,通过 Deployment 来管理;也可能是有状态的应用,通过 StatefulSet 来管理。Kubernetes 集群之上,通过多种 Controller 来管理我们的应用。而在集群之下,比如集群节点的存储、网络、资源等,比如物理硬件的好坏,都是影响集群稳定性的重要一环。
就像有一个叫做 “Jenga” 这个游戏,某些元素的单个故障不会导致集群不可用,一旦某些关键元素或者多个元素故障,超过了集群的自恢复能力,集群便不再可用了。
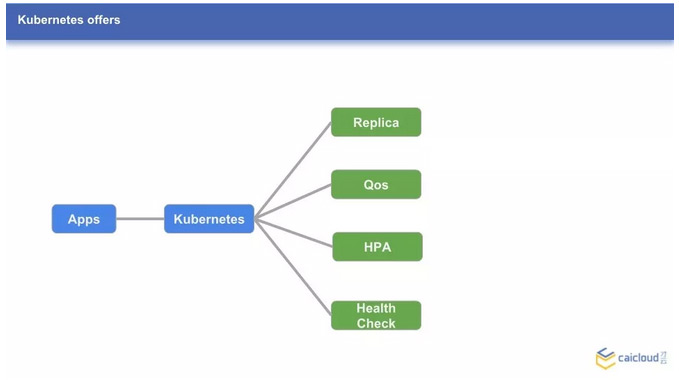
那么,Kubernetes 为我们提供了哪些提高集群可用性的利器呢?下面分享几个使用较多的特性:Replica,Qos,HPA,Health Check。
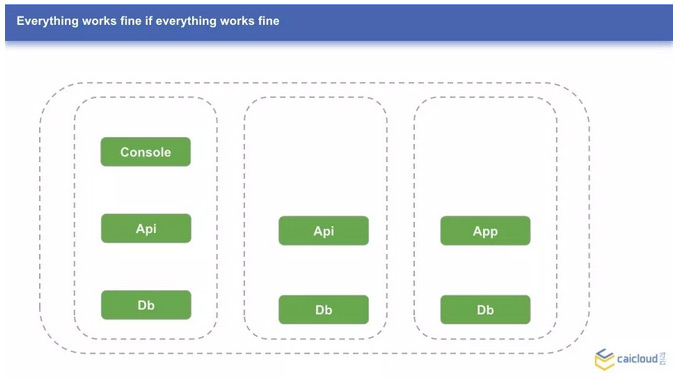
我们先来看一个一切正常的 Kubernetes 集群,包含 3 个节点,每个节点上跑了一些应用。可以注意到,有些应用有多个实例,有些只有一个实例。下面,如果第一个节点的 Console 和第二个节点的 Api 故障了,集群服务的可用性会怎样呢?
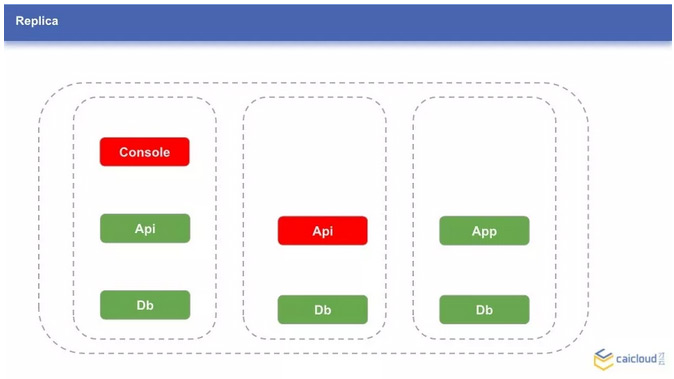
1、Replica
我们可以联想到,对于 Console 的故障,当 Console 不可用时,Console 对应的服务也不可用;而 Kubernetes 会保证应用的副本时,所以 Console 这个应用会重新的创建出来,并正常提供服务。但在重新调度和创建起来之前,服务是会中断的。作为对比,Api 服务因为使用了多个副本,在图中的故障情况下,服务是仍然可用的。所以这里我们推荐使用多个副本。

2、QoS
下面再看一张图,图中应用的大小对应应用的资源占用,这里以占用的内存为例。比如在节点 3 上,Db 因为资源不足,无法正常运行。
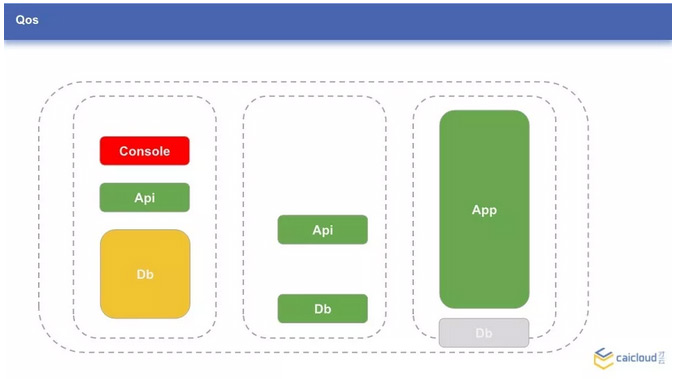
这里列出了几个可能的场景:
- 应用(节点 1 上的 Db)使用了过多的内存,会发生什么呢?Db 自己可能会因为内存不足或超限而被 kill 掉;Db 可能会导致其他优先级低的应用被 kill 掉。
- 应用(节点 3 上的 App)申请了过多的内存,导致原先想调度到这个节点上的应用无法调度上来
这些场景会在配置不同的 QoS classes 策略下有所不同,Kubernetes 提供了三种资源使用策略,根据应用的资源申请(request)和资源限额(limit)的不同、对于到 Guaranteed Burstable 和 BestEffort 三种模式。实际场景下,应该合理分配资源,避免资源的浪费和服务的不稳定。

3、HPA
和 Qos 类似的,HPA 是应用水平自动扩容。切换到这样场景:集群的 Db 服务负载很低,多个副本显得浪费;或者,集群的 Api 服务,突然流量剧增,当前的副本数已经不够了。这个时候,通过配置 HPA,可以使应用在负载高的时候,自动的添加副本数来减小单个实例的压力;也可以在压力小的时候,降低副本数,释放资源。
说到这里,可以提一下这里的负载,目前 Kubernetes HPA 实现上是通过衡量 CPU 的负载来评估服务负载的,实际使用中可能不能满足我们的需求。不过 Kubernetes 还提供了 Custom metric 让我们来自定义负载的指标。而与 HPA 类似的,还有集群的自动扩缩容(Cluster Autoscaler)和应用的垂直扩容(VPA)。
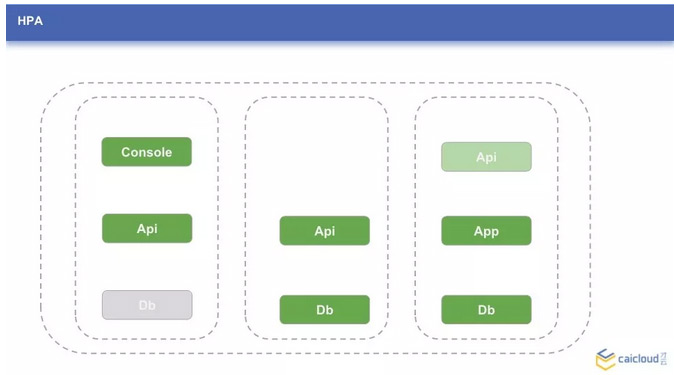

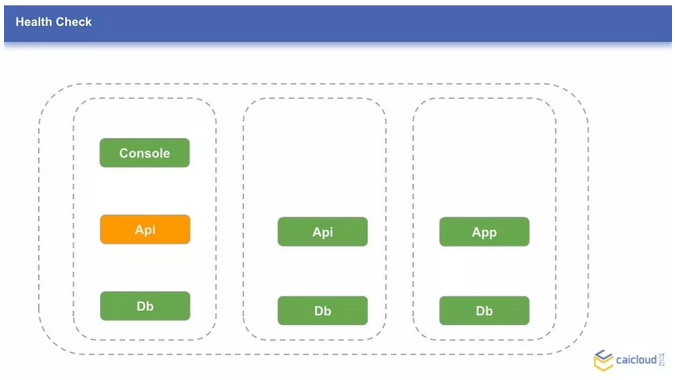
4、Health Check
下面讲讲健康检测(Health Check)。比如应用 Api 出现了问题,我们实际访问 Api 服务时发现这个服务确实不可用了,但我们查询到的 Api pod 运行的状态的 Running,也就是正常在跑,Kubernetes 不会知道这个应用不工作了。默认情况下,如果应用没有异常退出,Kubernetes 会认为这个应用是正常的,不会做特殊处理。
但我们或许会遇到以下 2 种情况:
- 应用因为死锁而卡死;
- 应用还在初始化阶段等导致服务不可用,我们可以借助健康检测来让 Kubernetes 发现和处理这类异常。
对于状况 1,我们可以配置存活性检测(Liveness Probes),如果存活性检测没有通过,Kubernetes 会自动来重启这个应用。
对于状态 2,我们可以配置可用性检测(Readiness Probes),这样在服务初始化完成前,通过 Service 不能访问到这个服务,避免造成意想不到的后果。


提高集群的稳定性,Kubernetes 还提供了许多高级功能,这些功能可能没有前面提到的那几个常见,但却也是十分有用的。下面分享两个功能特性:资源预留和关键组件调度保证。
资源预留
实际场景下的资源使用,除开用户运行的实际业务,操作系统本身也会占有一定的资源,比如系统内核,比如系统服务(sshd udev 等)。如果用户业务使用了过多的资源,以至于系统的资源得不到保障,导致系统不稳定,集群服务就也得不到保障了。这个时候,我们可以通过配置 System-reserved 来给系统预留部分的资源。
但是这样就够了么?我们知道,Kubernetes 集群本身也有许多控制组件,这些组件如果因为资源不足出现故障,整个集群也没法保障稳定了。这个时候,我们可以类似配置 System-reserved 一样,配置 Kube-reserved,来预留资源给 Kubernetes 相关的组件,比如 Kubelet 和 Docker daemon。这样一来,哪怕用户业务负载很高,也可一定程度上通过保证系统核心组件的稳定来提高集群的稳定性。



关键组建调度保证
除了 Kubernetes 的系统组件,还有一些组件,这些组件如果没有跑起来,整个集群都可能不可用,比如 dns 服务,比如网络插件等。这些关键的应用(Critical Add-On),Kubernetes 提供了一种机制,来保证这些关键应用的存活。
比如这样一种情况,DNS 调度到了一个节点,这个节点存在一些问题,导致 DNS 一直不停的出错重启。默认情况下,除非 Kubernetes 认为这个节点不可用,进而重新调度 DNS,DNS 服务是不会重新调度的,这样会导致集群不可用,并且不能自动修复。这个时候,如果配置了 Rescheduler 组件,并且把 DNS 配置成了关键应用,DNS 会被重新调度到另外一个节点。这样,集群的服务一定程度下,可以自动的修复。

认识异常
讲了许多的提高集群稳定性的方法,下面谈谈集群使用中可能遇到的异常。回到最初的那个图,图上每一个节点,都可能出现异常,比如:应用没有跑起来;节点挂掉了;网络故障;Docker 卡死等。下面以电力故障为例,来谈谈出现异常时候,对集群服务的影响。
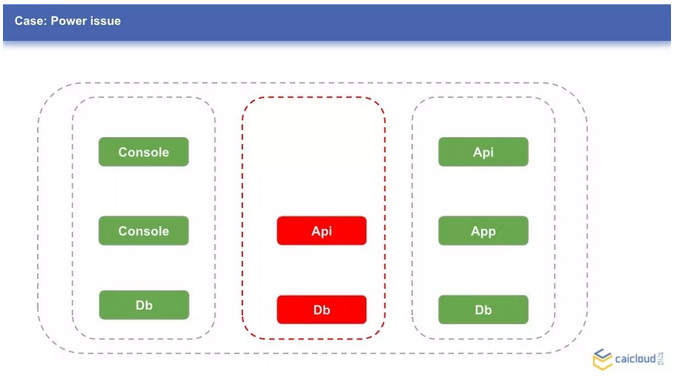
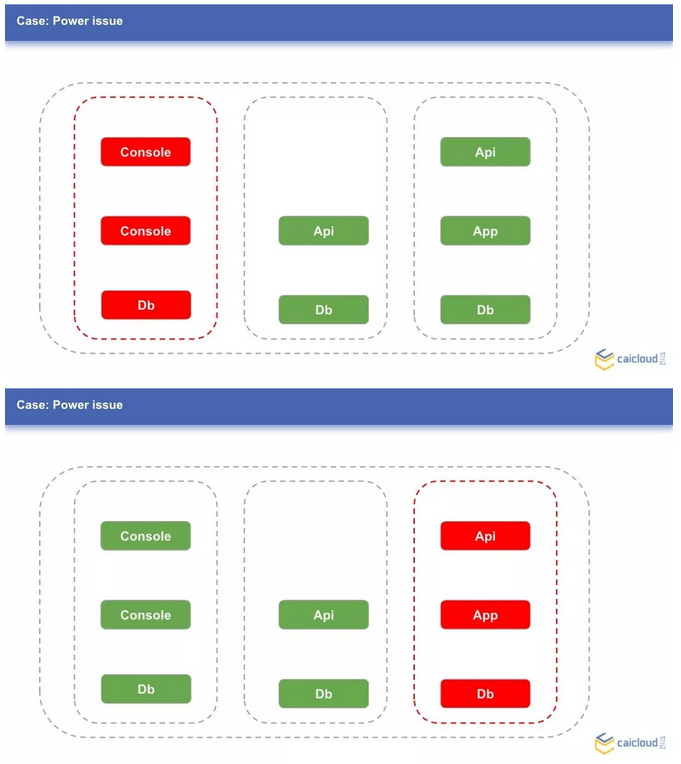
下面三张图中三个节点上分别跑着一些服务,假设故障分别出现在这三个节点上,会发生什么呢?前面提到了 Replica,我们知道如果 Replica 为 1,服务是会中断的。这个中断时间可能没有大家想象的那么短。
默认情况下,从节点状态变为不可用,到 pod 重新调度到其他可用节点,可能需要几分钟的时间。我们可以通过配置 pod-eviction-timeout 来调整这个时间,但不建议配的太小,这样可能因为比如网络不稳导致 pod 不停地重新调度,造成抖动。
那是否 Replica 配置成 2 或者更多就可以了呢?我们可以想想节点 1 出现故障,服务 Console 全部跑在了节点 1 上,哪怕 Console 有多个服务,故障还是会造成 Console 服务中断。这个时候,我们可以配置 podAntiAffinity,来保证服务的多个副本不会调度到相同的节点上,以此来进一步提高可用性。

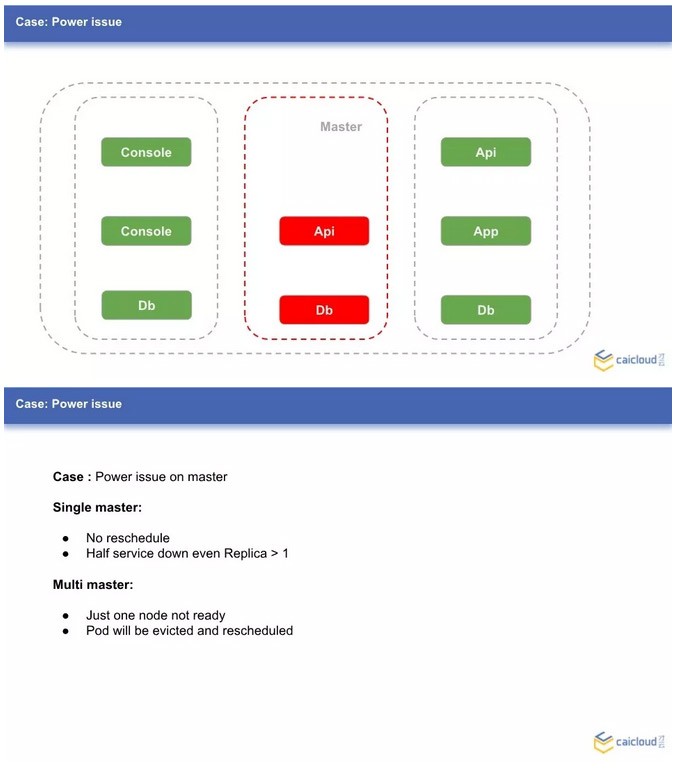
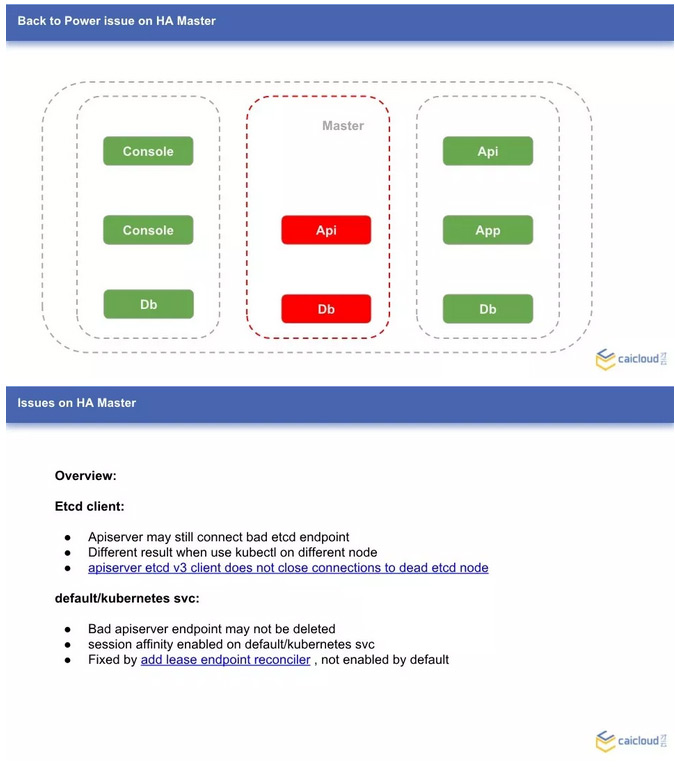
我们继续假设,如果出现电力故障的节点是 Master 呢?如果这是唯一的 Master,那么故障的服务不会重新调度和恢复;通过 Service 方式访问这个应用,有可能访问到故障的后端服务。
K8S 里的高可用方案
如果是有多个 Master 呢?理想的情况下,故障节点上的应用会重新调度,故障的服务也会自动恢复。为什么说理想的情况下呢,这个我们稍后会解释,在此之前,我们先看看高可用在 Kubernetes 是如何实现和工作的。
图中描述了一个典型的 Kubernetes HA 方案架构,包括几个重要的地方:
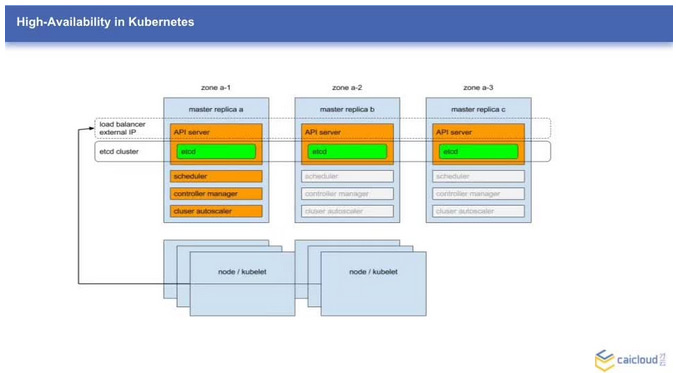
- Masters:集群 Master 节点数不再是一个,而是三个,etcd 作为集群的模式工作在三个 Master 节点上,每个节点上都会跑一个 apiserver,并连接这个 etcd 集群;其他有状态的组件比如 controller scheduler 会采用主备的方式,在三个 Master 上都会运行,但是只有一个节点上的会选举为主,提供服务。
- Nodes:集群 Node 节点的 Kubelet proxy 服务,连接 apiserver 的负载均衡地址。
- load balancer:一个负载均衡服务,把流量导入到存活的 Master 节点的 apiserver 服务上。这个负载均衡即可以是一个外部 IaaS 提供的云负载均衡,也可以是自己通过keepalived 和 nginx 搭建出来的内部负载均衡。

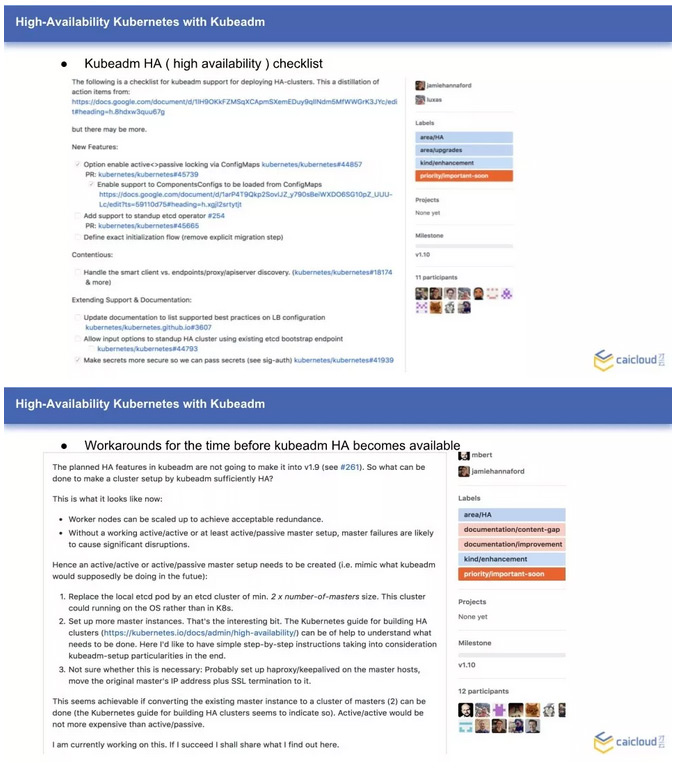
社区热门的部署工具 Kubeadm,也有整合 HA master 的计划,下图是一个目前的完成度情况,可以发现里面还有不少工作要做,预计的发布版本是 v1.10。如果不想等得太久,社区也给出了一个基于 Kubeadm 手动创建一个 HA master 集群的方案和操作流程。这里给出了相关文档的链接,感兴趣的同学可以自己选择阅读。
回到刚才说的理想的情况,HA 方案可以保证集群高可用。但实际情况呢?
目前的 HA 集群,在实际使用上,会有一些坑,虽然某些可能在最新的上游版本修复了,但如果没有更新版本,这些问题还会存在。
- etcd client 问题:当三台 Master 节点挂掉一台时,apiserver 可能仍然连接的是停止服务的那台 Master 节点上的 etcd ,这样 apiserver 无法获取和更新最新的集群状态,导致可能通过 kubectl get node 查询集群的状态,在一个节点上查询到的是三个节点全正常,另外一个节点显示有一台 not ready。
- default/kubernetes svc 问题:一台 Master 节点故障时,default/kubernetes 这个服务不会像其他服务那样,去更新它的 endpoint,异常的 Master 节点 IP 仍然会保留在 endpoint 里面。这样许多通过 svc 方式来访问 apiserver 的应用都会出问题。默认 svc 的实现是通过 iptables 规则来实现的。目前的 kubernetes svc 会根据 client IP 做会话保持,这样如果访问的恰好是坏掉的 Master 节点 IP,这个节点上的 kubernetes svc 就会一直不可用了。如果去掉会话保持,会有三分之一的概率服务不可用。

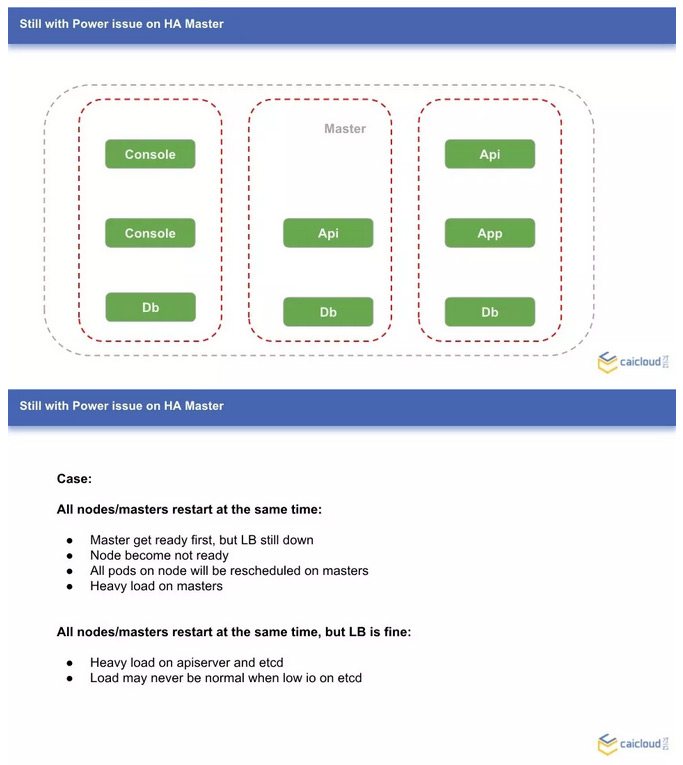
抛开上面提到的两个问题,还是电力故障的情况,这次情况比较糟糕,所有节点都受到了影响。但运气比较好,电力很快就恢复了,这个时候,集群服务会怎样呢?
场景一:负载均衡服务没有恢复,Master 节点很快恢复正常了。因为负载均衡还未恢复,所有 Node 节点都会认为是不可用的,导致的一个可能后果是,所有 Node 上的服务都重新调度并在 Master 节点创建,Master 节点负载会非常高。哪怕后面 LB 恢复了,master 节点的任务也不会自己迁出,集群的负载会极度不均衡。
场景二:负载均衡服务正常,Master 节点和 Node 节点都在快速的启动服务中。这个时候,如果 Node 节点规模很大,apiserver 和 etcd 的请求会非常的多。比较糟糕的情况是,Master 节点的 etcd 因为负载太高不能正常提供服务,导致 Node 节点注册失败,然后不断尝试重新注册 Node;哪怕负载降下来后,Node 节点全部注册成功,大量应用重新调度,产生大量的事件,etcd 很可能马上又坏掉了。这个时候,就需要对 apiserver 做限流了,防止突发的压力增长导致集群不可用。
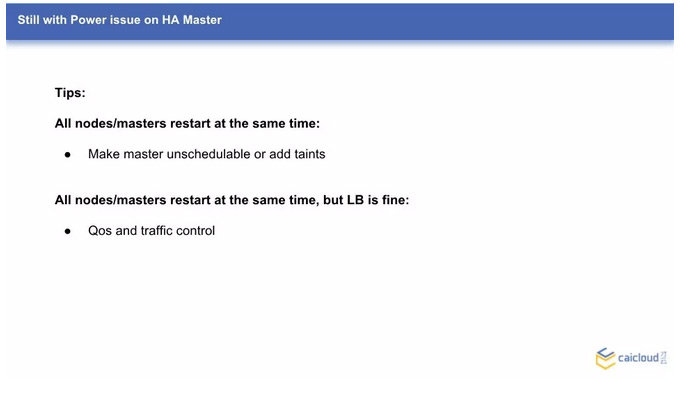
处理异常
谈了很多异常的状态,那么有什么好的办法来处理这些异常呢?限于时间关系,以下图为例给大家简单讲讲如何处理异常。
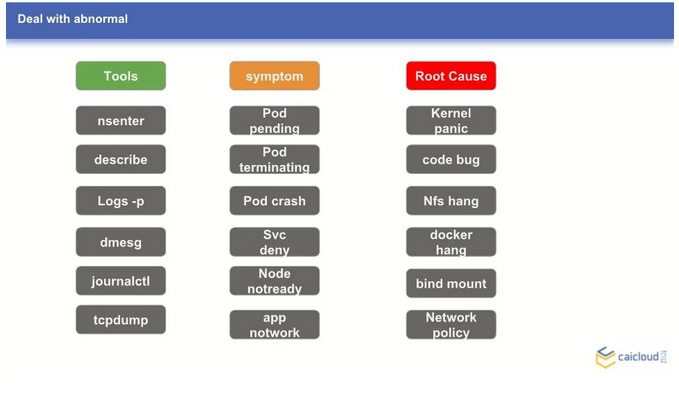
- Symptom:通常发现异常时,是因为发现了一些不寻常的征状,比如某个服务不可用了,某个 pod 卡在了 terminating 状态;某个创建的 deployment 没有看到运行的 pod。根据这些征状,我们对于出现的异常有了一个初步的了解,便于借助工具做进一步的诊断。
- Tools:诊断问题时,我们可以借助许多工具。比如 kubectl describe 来查看事件,kubectl logs 来查看日志,nsenter 进入容器的命名空间诊断问题,tcpdump 抓包来诊断网络问题等。借助这些工具,和诊断的一些结论,我们可以猜测可能的原因
- Root Cause:导致异常的原因多种多样,异常的直接原因,借助工具可以快速发现,比如创建了 deployment 没有创建出 pod 原因是节点资源不足。我们可以继续追踪这个异常,为什么会突然资源不足了呢,借助工具可以发现是有一个节点不可用了。继续追查,可能是这个节点的 kubelet 异常退出了。通过一步步,找到了根本原因,才能从根源上解决这个问题。
上图中列出了一些有趣的 Root Cause,比如内核的 panic,dockerd 卡死,错误的挂载目录,配置了错误的网络策略等。
我的经验分享
这里给大家分享一下经验:
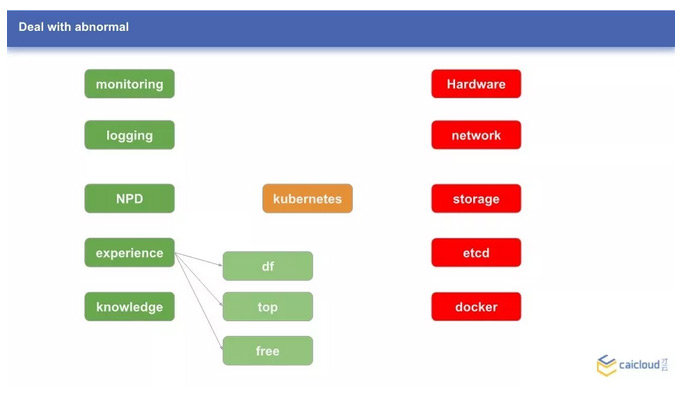
- 借助日志系统和监控系统发现和诊断异常
- 优先查看节点的负载情况,确保不是资源不足,磁盘写满导致的
- 诊断问题不仅限于 Kubernetes 本身,相关的存储、网络、容器运行时等都可能出问题
- 不要忽略硬件本身的问题,比如磁盘本身有故障
今天的分享到这里,感谢大家!

写的真好。