
本文是才云科技(CaiCloud)5月6日沙龙“Kubernetes Meetup 中国 2017”IBM中国系统部软件架构师马达的演讲实录。PPT下载

IBM中国系统部软件架构师马达
大家好,很高兴能参加这次活动,今天主要会讲到关于策略的资源调度,做自己的产品也好,基本都是由资源调度为强项,我现在主要负责 Kubernetes 这边,主要做 Batch Job Admission and flexible resource allocation。最近也是在跟 Google 的人去聊如何基于策略去调度。我2005年开始做技术,这个题目大概就是这个,关于这个 Kuberentes#269,如果感兴趣,大家可以去上面看一看,还有这个 @k82cn,可以点进去看一下。

为什么我们要去做这样的事情?现在 Kubernetes,大家去部署所有的东西,感觉蛮不错的。我们为什么还要去聊这件事,这个最早的时候是很早的一个理念,我们当时大概分了几个步骤,mesos 有自己的调度,最主要是资源的管理和资源的分配,然后我们上层由 Kubernetes 去管理,然后是 spark,这两个是有专门的项目去做,现在的 spark 是 Kubernetes 的一个模式,然后我们自己去做了一个叫 session scheduler 的事情。Google 有一个人也在做,他们的想法,现在 spark 也是有一定的资源管理能力。
包括我们在做这个事情的时候也在想,这个系统是不是可以把 mesos 的功能放在 spark 里面去做。他里面自己搞的一个策略分配,这个图在哪里提供,在 Kubernetes 提供。我们有一个网站,这是我们内部的一个产品,所以这个说的比较少。当时这个想法在社区里面跟他们聊了一下,他们比较感兴趣,做了一些 PPT 聊了一下,这个项目在去年11月份开始到现在落地,大家可以去看一下。这个 PPT 也是基于以前的,加了一些内容。
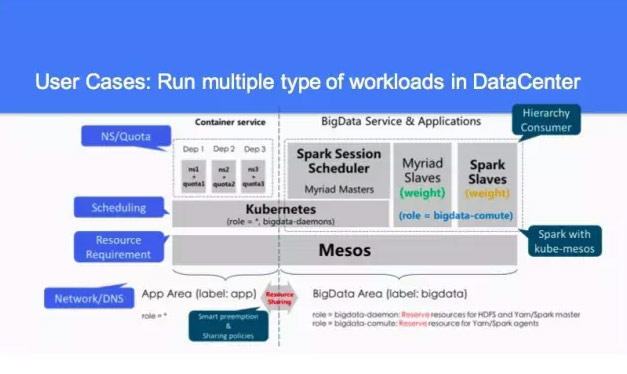
这个是主要做的几件事情,Run multiple type of workloads in DataCenter 我们希望在数据中心里面,好的东西是多种多样的。然后我们也希望有其他的一些服务,对资源划分的话,资源现在看没有动态的划分,我们按照组织来分机器,有一些是研发,大家在分机器的时候,应该是这个组织有多少机器,大家有相应的预算去买机器,但是每个公司对机器的使用率程度不一样。有的部门机器蛮紧张的,有时候跟项目运行时间、跟整体的休假时间、跟产品上线的时间都是有关系的。
之前跟很多互联网公司聊都有这样的情况,公司想把所有的机器以资源调配的方式把它管理起来,所以有很多用这个。整个需求无论对传统的企业,像银行、电信,这个需求都是在这儿的。通过社区的人会有这样的想法,我们会做这样的事情。
当时忽略了几个意见,现在 Kubernetes 有解决用户的问题,第一个 Quota 就是部门上限能用多少,如果你想用的话,资源在哪儿,如果其他的 Quota,这个部门机器不要钱可以抢占,但是 Quota 是没有的。你这个部门能做这么多的机器,不要超过了这个。如果不用的时候,大家可以彼此共享的。

还提到说 multiple scheduler,如果资源不够的话,会造成很多的冲突。然后另外还提到 auto sualing,这个做完了以后,没有一个全面的调度。这两个是提的一个主要的功能,他有一个 rescheduling,当你整个运行一段时间之后,之前做的决定是最优的,有些机器可能最造成一些碎片,但是没办法,所以 Rescheduling 在过一段时间之后从全局再看一遍,调节一个更优的。所以这个事情只有在 Rescheduling 才有存在的意义。
对于这种短作业一般跑几分钟就完事了,这个也是社区里面来做的事情。然后 Work Specific,这个做的事情就是删除,再重新来做。在整个体系下,把这两个都考虑进去了,所以现在尽量不再去添加新的顶级的默认支持。另外就是 Controlller,就是定义什么行为就做什么行为,他基于原数据来做的。通过修改这些原数据的状态来驱动其他协作,从整体架构是不太一样的。你自己去调度修改你的原数据值就可以了。

这个大概是分了几个步骤,我们会以一个 Batchjob Controller ,我们把资源调度和现有的功能分开,对资源调度这一块现在有一个问题,资源调度的分配是经过完全验证的,这个是100%没有问题的。另外一个问题我不知道大家有没有看过 borg 的事情,完全是基于这个来做的。
所以当时我们在做这个的时候,商量了一下还是将他们分开了,基于策略的抢占还是做 borg 的路线。然后把之前说的基于资源调度的策略展示放在 batchjob controller 上面,至于后面是不是两个合在一起,这个要到后面去谈。现在两边都有不同的事情,两种方式都是有案例做这样的事情。很难说孰优孰劣,还是两个都去做。
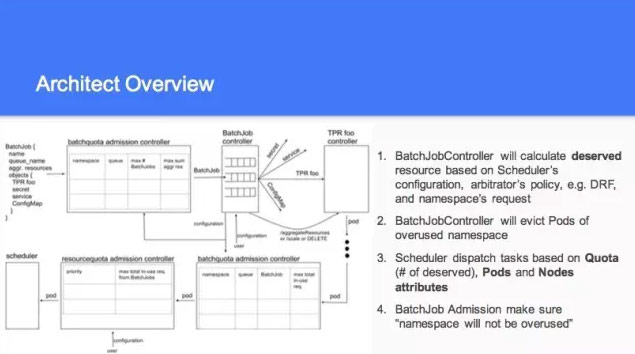
说到整个的话,根据策略去算这个 Quota 里面应该分布多少资源,这一块有很多还是在讨论的地方。关于 Quota 这一块有很多的争论,从功能上都是做一件事情,基本都支持层级的。

所以我们讨论的时候,这一块有两个观念,一个想建立一个概念,也叫 Quota,但是现在还没有层级的,这个到后续再做。所以 Batchjob Controller 还得根据当前的来分配。如果我有100个资源,那剩下的80就分给另外的资源里面进行调取。所以抢占回来的时候,这里面的每一个点都是有策略的。比如你先抢占什么的,跑的时间最长的,刚开始跑的,没干什么事。这一块大概列了一下。一个是算他的数值,第二个是20和80,平分是一人50,所以我往回抢的时候,你只能把30个抢回来。另外这一块整个现在做的这个事情,只涉及到资源分配,这块基本算的一个数,你这一个用多少资源,具体你放在那个里面对你是最好的。其实这个现在只是一个初步的想法。
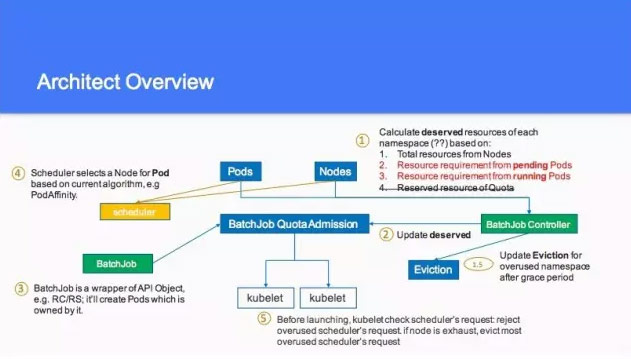
这个是刚才说的这个事情,又提到之前说的 Quota,你一定不会超过这个,另外想把 Deserved 加进去,比如有一些特定的硬件,最后大家去聊的时候,还是希望这个暂时不要考虑,只考虑这个 Deserved,这个是 Architect Overview 的一个值,如果这个 pods 到 nodes,这一块大家要不要把这个换成另外一个。基于 reserved 大家不太想做,这个也划掉了。所无我有的这些信息到 Batchjob Controller 的时候都可以算出来。所以在第二个的时候,把他归到 deserved 里面。
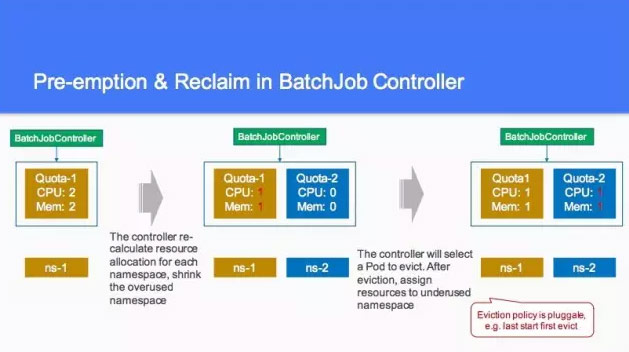
另外有1.5的值,由于作业的数量是有浮动的,所以一定会去做 eviction,就是把当前的用多的资源杀掉,然后用别的抢回来。然后第三步的时候,我们可以看到有资源可以去用,这个叫 Batchjob Controller,包含任何的东西,包含多个东西。这块现在好像支持率也不是特别好,然后像刚才说的到第四步的时候,就是 scheduler。
这个是刚才所说的一个事情,重新算这个 Batchjob Controller 的一个值,就可以达到两个 CPU 和 2个mem,在另外一个里面,上了一些作业的时候,我们要重新计算这个值,然后大家平分,大家以人一个 CPU 和 mem,这个就已经有策略了。
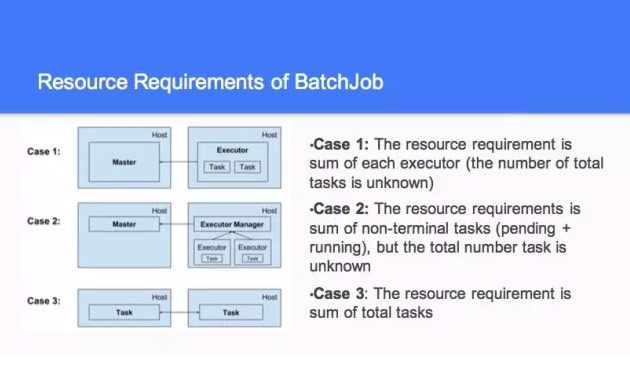
然后在做这个策略也好,我们之前做了一个资源的策略。第二种是你的这个根据当前的请求来进行调节的,然后我们有一个产品就跑一个。面对这一块的时候,当你跑的作业不一样的时候,我们做了第二种情况,你有了 case1,还有 case2,这里跑比较慢,这儿结束了,这儿又开始了。
这是比较复杂的事情,你这个是动态的,你不知道到底有多少的资源,这个跟下面有关联,有的说我拿最小的值去动态划分,那个也不需要拿最小的值去做。这个要去算他的值到底是多少,那个值是不断变的。
第三种的时候,它要求所有的资源都满足了以后,才能跑起来。彼此之间有等待了,你只要杀了一个,就整个都跑不了了。说白了,你的整个的 task 和 host 之间是有关联的。我要有两个 CPU,我能保证自己的 mem,这块是不同的方式和不同的结构,我们最后看资源到底一样不一样。另外我有个小的需求,能满足这个最小的需求。然后是整个的到底有多少资源,这一块还有一个事情,你像 case1 和 case2 你不知道到底什么时候结束,但是 case3 你就知道什么时候结束。

所以这些的数据方式和 case 都要考虑,会提供统一的来做这个事情,可以灵活做自己定制的。讲了这么多 case,但也不见得可以。这个是后面的 backlog,这个放在比较靠后。这个有需要考虑的事情,现在 backlog 只考虑你的 resource。另外 deserved 的值,主要是要做基层的时候要做,所以这些后面才会去考虑。

然后这个是 Reference,基于资源调度把他都放在一起了,这个会考虑整个空间的资源共享的一个情况,将来在1.7的版本看做什么样的资源共享,这个还在看。有一些细节还在讨论,这里面是一些相关的东西,第一个就是根据第一张图,然后这个是 borg 的那个事情,下面是刚才说的 rescheduler,这个是另外的一个人在做。暂时就是这些,谢谢大家!

登录后评论
立即登录 注册