
Standalone 是 Spark 自身提供的一种主从集群部署模式。本文讲述一个常规1主多从的集群部署模式,该模式下master服务依靠Rainbond平台监控保障其可用性,支持重新调度重启。 worker服务可以根据需要伸缩多个节点。
部署效果截图如下:
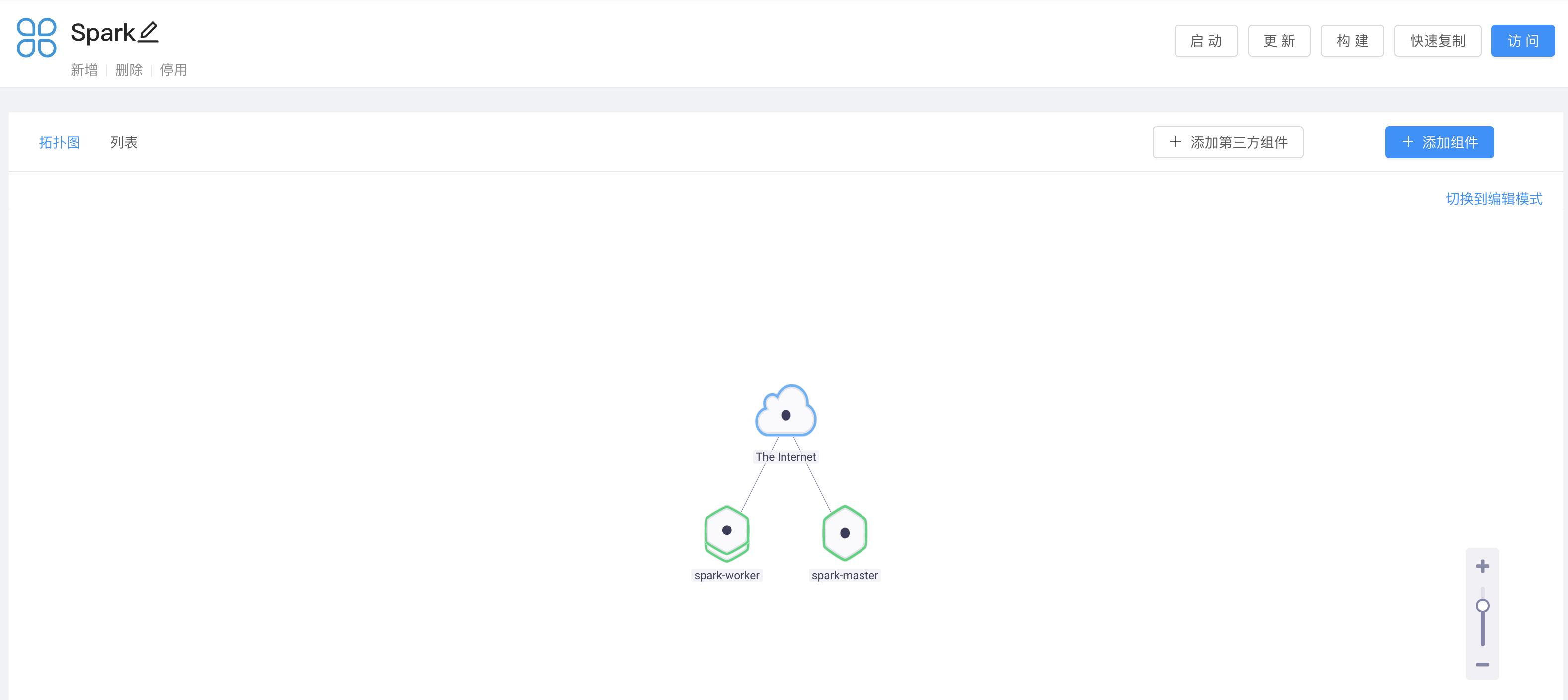
部署步骤
开始前,你需要完成Rainbond平台的安装和搭建,参考Rainbond 安装与部署 本参考文档适合已掌握Rainbond 基础操作的同学,因此如果你还刚接触Rainbond平台,请先参考 Rainbond 快速入门指南
部署单实例的master服务
-
部署spark-master,采用Rainbond基于Docker镜像创建组件:
bde2020/spark-master:3.0.1-hadoop3.2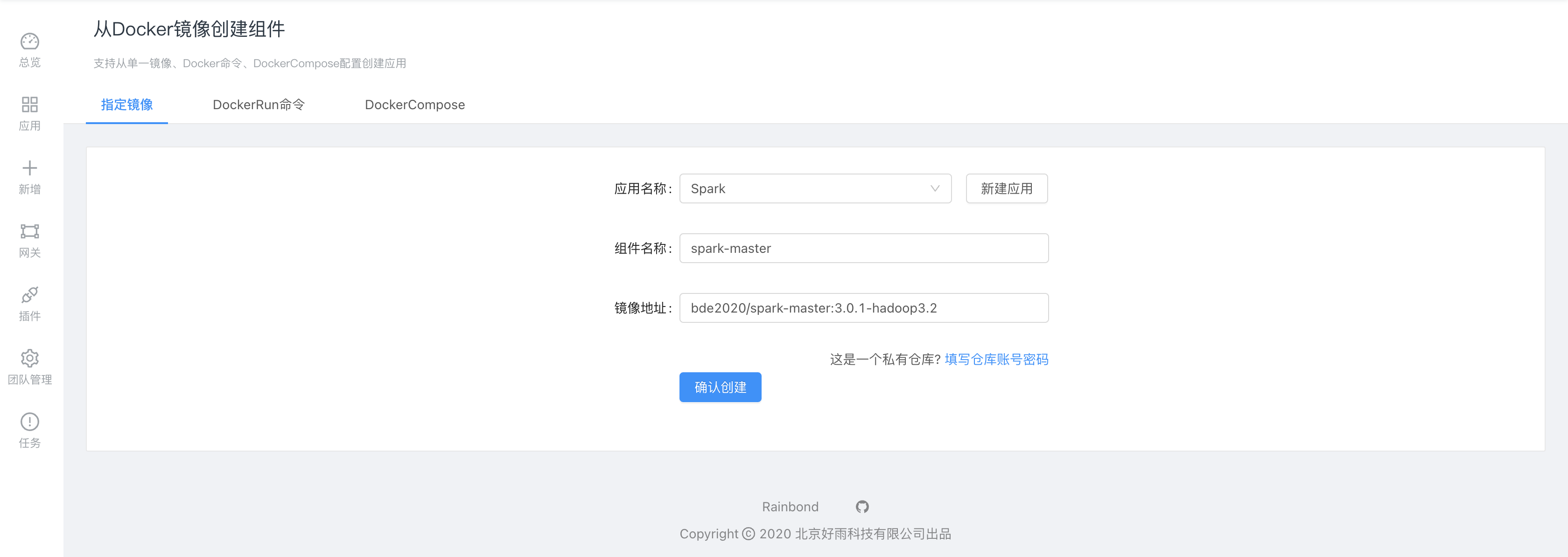
-
确认创建检测成功后选择
高级设置进行三个特殊设置。-
在环境变量模块中添加环境变量
SPARK_DAEMON_JAVA_OPTS=-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/data我们需要设置spark-master为“Recovery with Local File System”模式。可以在master发生重启后从持久化文件中恢复数据,保持master服务的可用性。
-
在存储设置中添加共享存储
/data持久化master的数据,使其可以重启后恢复。 -
在端口管理中将 8080端口的对外服务打开,组件启动成功后即可访问master的UI。
-
在部署属性中选择组件类型为
有状态单实例部署为有状态组件后,其可以获得一个稳定的内部访问域名,供worker组件连接。有状态服务控制权可以保障master节点不会重复启动多个实例。
-
-
设置完成后选择确认创建即可启动master服务。
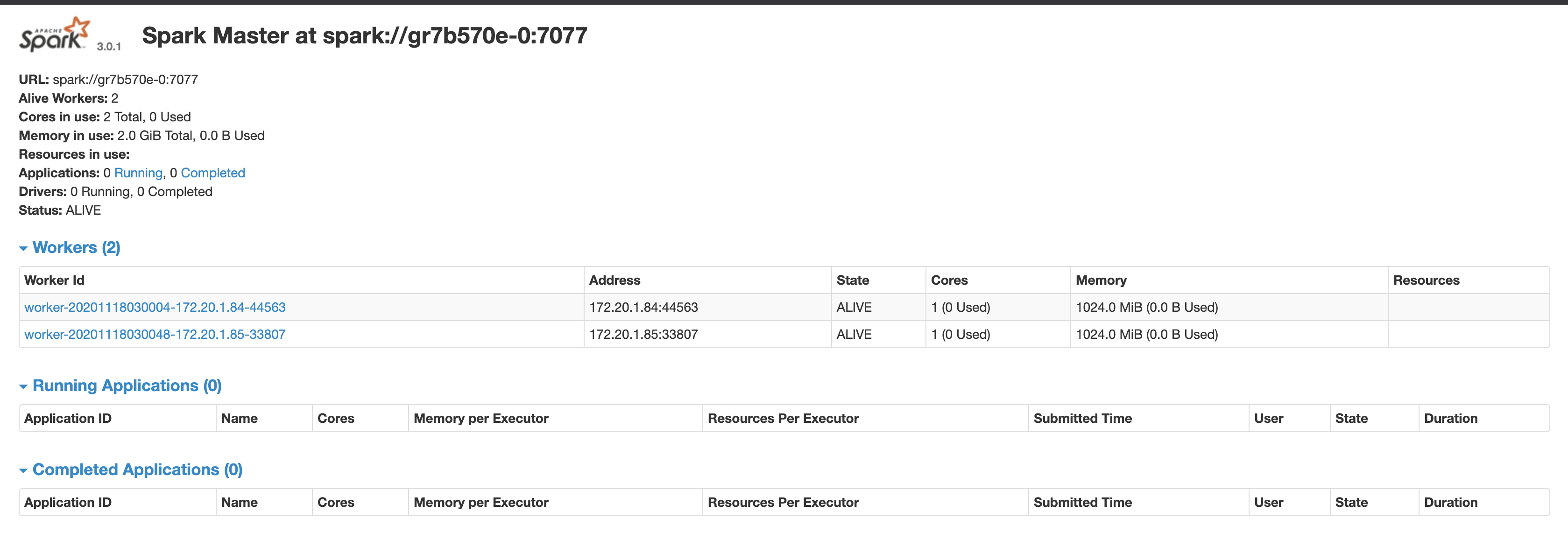
组件成功点击访问即可打开master UI。如上图所示,我们可以在UI中获取到master服务的访问地址是:spark://gr7b570e:7077 ,注意UI上显示的地址是spark://gr7b570e-0:7077 我们需要使用的是spark://gr7b570e:7077 ,复制并记录这个地址。
注意,地址实际值请查看你的UI显示,这里只是举例说明。
部署多实例的worker实例
-
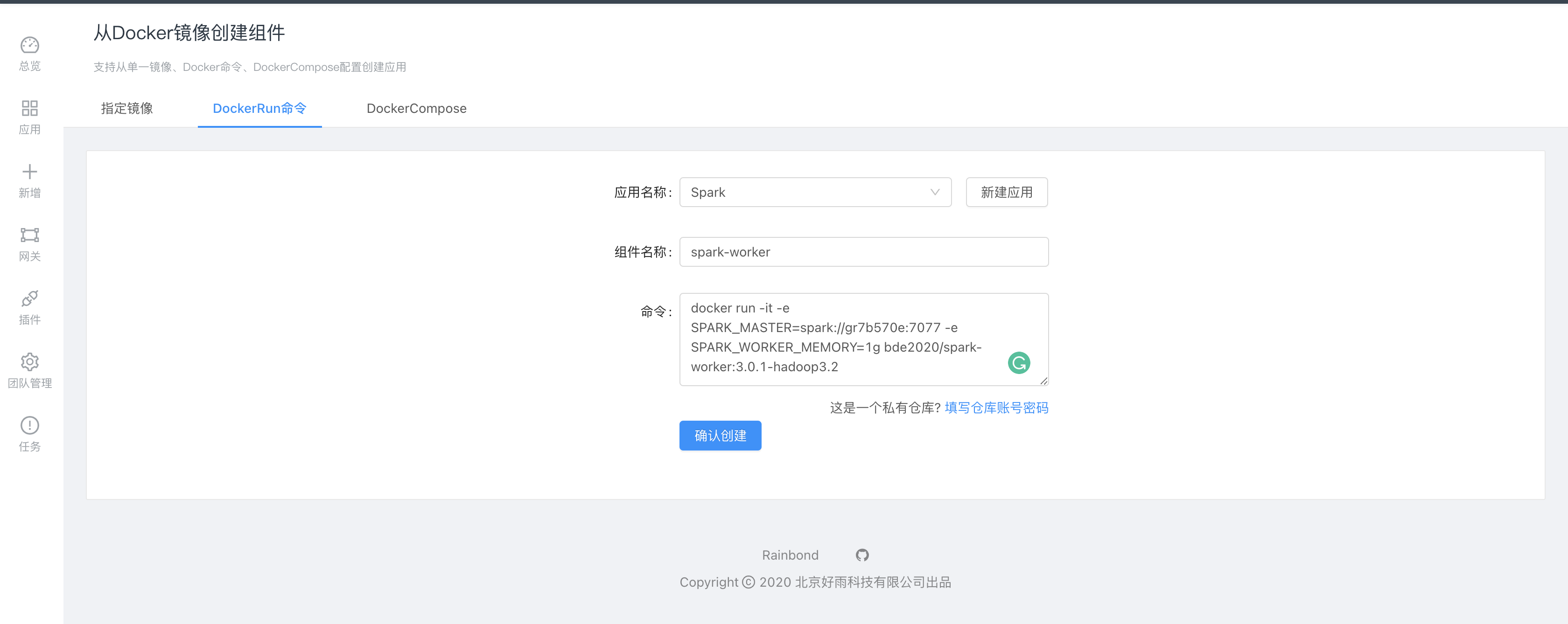
部署spark-worker,采用基于Docker-run命令创建组件,这种创建方式可以直接设置一些必要属性:
docker run -it -e SPARK_MASTER=spark://gr7b570e:7077 -e SPARK_WORKER_MEMORY=1g bde2020/spark-worker:3.0.1-hadoop3.2-
SPARK_MASTER 指定的是master的地址,由上一步创建的组件获取。
-
SPARK_WORKER_MEMORY 设置worker单个实例的内存量,这个根据每个实例分配的内存进行设置即可。比如每个实例分配1GB, 则设置SPARK_WORKER_MEMORY=1g 。如果不设置此变量,服务会自动读取操作系统的内存量。由于我们是采用的容器部署方式,读取的值会是宿主机的全部内存。将远大于worker实例实际分配的可用内存值。
如上创建方式指定了两个环境变量。
-
-
同样进入高级设置,设置组件部署模式为
有状态多实例。 -
确认创建组件,启动成功后即可在组件的伸缩页面中设置worker的运行实例数。
到此,我们的Spark集群已部署完成。
Spark数据读取
-
就近数据处理原则逐步打破
过去我们更偏爱于把数据处理服务(hadoop、yarn等)部署到离数据最近的地方。主要原因是hadoop计算数据的模式对IO消耗较多,如果数据与计算分类,网络IO带来的消耗将更大,对网络带宽要求较大。
但Spark机制不同,Spark计算模式是将数据尽可能缓存到内存中,也就意味着Spark消耗的资源主要是内存和CPU。然后存储数据的设备内存和CPU配属不一定充足。因此数据与计算分离将是更好的选择。
-
数据与计算分离后的更多选择
本文讲述的在Rainbond中部署Spark集群即是这种用例。
Master节点主备高可用
Spark 基于 ZooKeeper可以提供master服务的主备切换。 配置方式也比较简单,参考 官方文档。
Rainbond 云原生应用管理平台,实现微服务架构不用改代码,管理 Kubernetes 不用学容器,帮企业实现应用上云,一站式将任何企业应用持续交付到 Kubernetes 集群、混合云、多云等基础设施。是 Rainstore 云原生应用商店的支撑平台。

登录后评论
立即登录 注册