
Prometheus 是一个开源的监控解决方案,部署简单易使用,难点在于如何设计符合特定需求的 Metrics 去全面高效地反映系统实时状态,以助力故障问题的发现与定位。本文即基于最佳实践的 Metrics 设计方法,结合具体的场景实例——TKE 的网络组件 IPAMD 的内部监控,以个人实践经验谈一谈如何设计和实现适合的、能够更好反映系统实时状态的监控指标(Metrics)。该篇内容适于 Prometheus 或相关监控系统的初学者(可无任何基础了解),以及近期有 Prometheus 监控方案搭建和维护需求的系统开发管理者。通过这篇文章,可以加深对 Prometheus Metrics 的理解,并能针对实际的监控场景提出更好的指标(Metrics)设计。
1 引言
Prometheus 是一个开源的监控解决方案,它能够提供监控指标数据的采集、存储、查询以及监控告警等功能。作为云原生基金会(CNCF)的毕业项目,Prometheus 已经在云原生领域得到了大范围的应用,并逐渐成为了业界最流行的监控解决方案之一。
Prometheus 的部署和使用可以说是简单易上手,但是如何针对实际的问题和需求设计适宜的 Metrics 却并不是那么直接可行,反而需要优先解决暴露出来的诸多不确定问题,比如何时选用 Vector,如何设计适宜的 buckets,Summary 和 Histogram 指标类型的取舍等。然而,要想有效助力故障及问题的发现与定位,必须要有一个合理有效的 Metrics 去全面高效地反映系统实时状态。
本文将介绍基于最佳实践的 Metrics 设计方法,并结合具体的场景实例——TKE 的网络组件 IPAMD 的内部监控,以个人实践经验谈一谈如何设计和实现适合的、能够更好反映系统实时状态的监控指标(Metrics)。
本文之后的第 2 节将对 Prometheus 的 Metrics 做简单的介绍,对此已有了解的读者可跳过。之后第 3 节将介绍 Metrics 设计的最佳实践。第 4 节将结合具体的实例应用相关设计方法。第 5 节将介绍 Golang 上指标收集的实现方案。
2 Prometheus Metrics Type 简介
Prometheus Metrics 是整个监控系统的核心,所有的监控指标数据都由其记录。Prometheus 中,所有 Metrics 皆为时序数据,并以名字作区分,即每个指标收集到的样本数据包含至少三个维度的信息:名字、时刻和数值。
而 Prometheus Metrics 有四种基本的 type:
– Counter: 只增不减的单变量
– Gauge:可增可减的单变量
– Histogram:多桶统计的多变量
– Summary:聚合统计的多变量
此外,Prometheus Metrics 中有一种将样本数据以标签(Label)为维度作切分的数据类型,称为向量(Vector)。四种基本类型也都有其 Vector 类型:
– CounterVec
– GaugeVec
– HistogramVec
– SummaryVec
Vector 相当于一组同名同类型的 Metrics,以 Label 做区分。Label 可以有多个,Prometheus 实际会为每个 Label 组合创建一个 Metric。Vector 类型记录数据时需先打 Label 才能调用 Metrics 的方法记录数据。
如对于 HTTP 请求延迟这一指标,由于 HTTP 请求可在多个地域的服务器处理,且具有不同的方法,于是,可定义名为 `http_request_latency_seconds` 的 SummaryVec,标签有`region`和`method`,以此表示不同地域服务器的不同请求方法的请求延迟。
以下将对每个类型做详细的介绍。
### 2.1 Counter
– 定义:是单调递增的计数器,重启时重置为0,其余时候只能增加。
– 方法:
type Counter interface { Metric Collector // 自增1 Inc() // 把给定值加入到计数器中. 若值小于 0 会 panic Add(float64)}
– 常测量对象:
– – 请求的数量
– 任务完成的数量
– 函数调用次数
– 错误发生次数
– …
### 2.2 Gauge
– 定义:表示一个可增可减的数字变量,初值为0
– 方法:
“`
type Gauge interface { Metric Collector Set(float64) // 直接设置成给定值 Inc() // 自增1 Dec() // 自减1 Add(float64) // 增加给定值,可为负 Sub(float64) // 减少给定值,可为负 // SetToCurrentTime 将 Gauge 设置成当前的 Unix 时间戳 SetToCurrentTime()}
“`
– 常测量对象:
– – 温度
– 内存用量
– 并发请求数
– …
### 2.3 Histogram
– 定义:Histogram 会对观测数据取样,然后将观测数据放入**有数值上界**的桶中,并记录**各桶中数据的个数**,所有数据的个数和数据数值总和。
– 方法:
“`
type Histogram interface { Metric Collector // Observe 将一个观测到的样本数据加入 Histogram 中,并更新相关信息 Observe(float64)}
“`
– 常测量对象:
– – 请求时延
– 回复长度
– …各种有样本数据
– 具体实现:Histogram 会根据观测的样本生成如下数据:
inf 表无穷值,a1,a2,…是单调递增的数值序列。
– – [basename]_count: 数据的个数,类型为 counter
– [basename]_sum: 数据的加和,类型为 counter
– [basename]_bucket{le=a1}: 处于[-inf,a1]的数值个数
– [basename]_bucket{le=a2}: 处于[-inf,a2]的数值个数
– …
– [basename]_bucket{le=<+inf>}:处于[-inf,+inf]的数值个数,prometheus默认额外生成,无需用户定义
– Histogram 可以计算样本数据的百分位数,其计算原理为:通过找特定的百分位数值在哪个桶中,然后再通过插值得到结果。比如目前有两个桶,分别存储了[-inf, 1]和[-inf, 2]的数据。然后现在有20%的数据在[-inf, 1]的桶,100%的数据在[-inf, 2]的桶。那么,50%分位数就应该在[1, 2]的区间中,且处于(50%-20%) / (100%-20%) = 30% / 80% = 37.5% 的位置处。Prometheus计算时假设区间中数据是均匀分布,因此直接通过线性插值可以得到 (2-1)*3/8+1 = 1.375.
### 2.4 Summary
– 定义:Summary 与 Histogram 类似,会对观测数据进行取样,得到数据的个数和总和。此外,还会取一个滑动窗口,计算窗口内样本数据的分位数。
– 方法:
“`
type Summary interface { Metric Collector // Observe 将一个观测到的样本数据加入 Summary 中,并更新相关信息 Observe(float64)}
“`
– 常测量对象:
– – 请求时延
– 回复长度
– …各种有样本数据
– 具体实现:Summary 完全是在client端聚合数据,每次调用 obeserve 会计算出如下数据:
– – [basename]_count: 数据的个数,类型为 counter
– [basename]_sum: 数据的加和,类型为 counter
– [basename]{quantile=0.5}: 滑动窗口内 50% 分位数值
– [basename]{quantile=0.9}: 滑动窗口内 90% 分位数值
– [basename]{quantile=0.99}: 滑动窗口内 99% 分位数值
– …
实际分位数值可根据需求制定,且是对每一个 Label 组合做聚合。
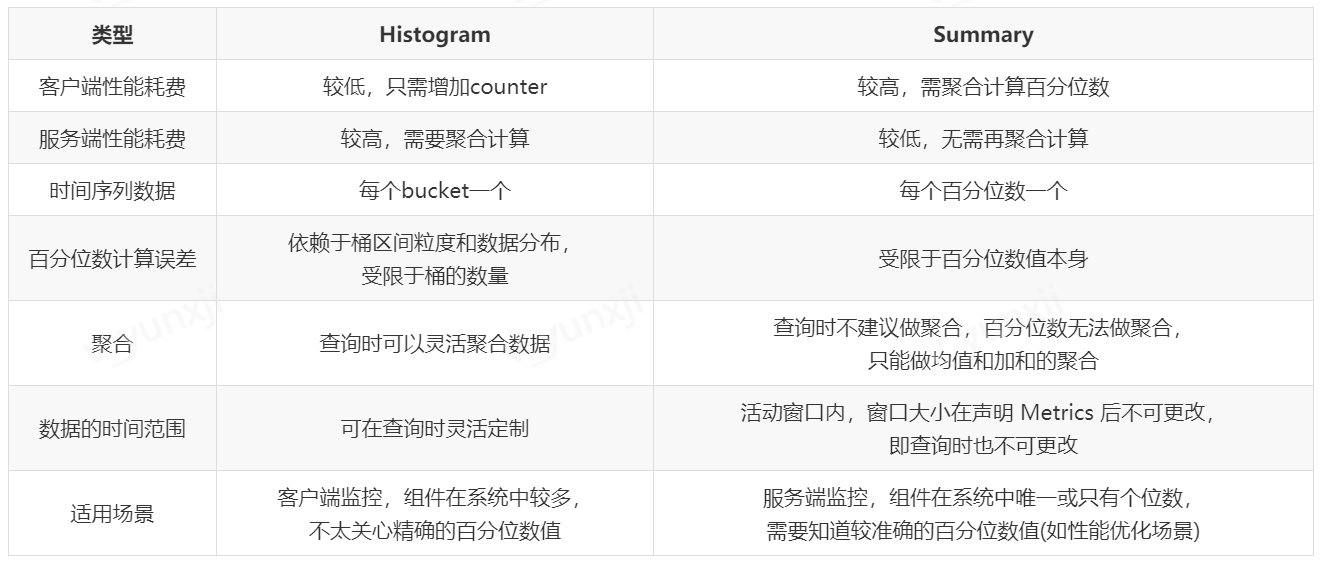
### 2.5 Histogram 和 Summary 简单对比
可以看出,Histogram 和 Summary 类型测量的对象是比较接近的,但根据其实现方式和其本身的特点,在性能耗费、适用场景等方面具有一定差别,本文总结如下:
## 3 Metrics 设计的最佳实践
### 3.1 如何确定需要测量的对象
在具体设计 Metrics 之前,首先需要明确需要测量的对象。需要测量的对象应该依据具体的问题背景、需求和需监控的系统本身来确定。
##### 思路1:从需求出发
Google 针对大量分布式监控的经验总结出四个监控的黄金指标,这四个指标对于一般性的监控测量对象都具有较好的参考意义。这四个指标分别为:
– 延迟:服务请求的时间。
– 通讯量:监控当前系统的流量,用于衡量服务的容量需求。
– 错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
– 饱和度:衡量当前服务的饱和度。主要强调最能影响服务状态的受限制的资源。例如,如果系统主要受内存影响,那就主要关注系统的内存状态。
而笔者认为,以上四种指标,其实是为了满足四个监控需求:
– 反映用户体验,衡量系统核心性能。如:在线系统的时延,作业计算系统的作业完成时间等。
– 反映系统的服务量。如:请求数,发出和接收的网络包大小等。
– 帮助发现和定位故障和问题。如:错误计数、调用失败率等。
– 反映系统的饱和度和负载。如:系统占用的内存、作业队列的长度等。
除了以上常规需求,还可根据具体的问题场景,为了排除和发现以前出现过或可能出现的问题,确定相应的测量对象。比如,系统需要经常调用的一个库的接口可能耗时较长,或偶有失败,可制定 Metrics 以测量这个接口的时延和失败数。
##### 思路2:从需监控的系统出发
另一方面,为了满足相应的需求,不同系统需要观测的测量对象也是不同的。在 官方文档 的最佳实践中,将需要监控的应用分为了三类:
– 线上服务系统(Online-serving systems):需对请求做即时的响应,请求发起者会等待响应。如 web 服务器。
– 线下计算系统(Offline processing):请求发起者不会等待响应,请求的作业通常会耗时较长。如批处理计算框架 Spark 等。
– 批处理作业(Batch jobs):这类应用通常为一次性的,不会一直运行,运行完成后便会结束运行。如数据分析的 MapReduce 作业。
对于每一类应用其通常情况下测量的对象是不太一样的。其总结如下:
– 线上服务系统:主要有请求、出错的数量,请求的时延等。
– 线下计算系统:最后开始处理作业的时间,目前正在处理作业的数量,发出了多少 items, 作业队列的长度等。
– 批处理作业:最后成功执行的时刻,每个主要 stage 的执行时间,总的耗时,处理的记录数量等。
除了系统本身,有时还需监控子系统:
– 使用的库(Libraries): 调用次数,成功数,出错数,调用的时延。
– 日志(Logging):计数每一条写入的日志,从而可找到每条日志发生的频率和时间。
– Failures: 错误计数。
– 线程池:排队的请求数,正在使用的线程数,总线程数,耗时,正在处理的任务数等。
– 缓存:请求数,命中数,总时延等。
– …
最后的测量对象的确定应结合以上两点思路确定。
### 3.2 如何选用 Vector
选用 Vec 的原则:
– 数据类型类似但资源类型、收集地点等不同
– Vec 内数据单位统一
例子:
– 不同资源对象的请求延迟
– 不同地域服务器的请求延迟
– 不同 http 请求错误的计数
– …
此外,官方文档 中建议,对于一个资源对象的不同操作,如 Read/Write、Send/Receive, 应采用不同的 Metric 去记录,而不要放在一个 Metric 里。原因是监控时一般不会对这两者做聚合,而是分别去观测。
不过对于 request 的测量,通常是以 Label 做区分不同的 action。
### 3.3 如何确定 Label
根据3.2,常见 Label 的选择有:
– resource
– region
– type
– …
确定 Label 的一个重要原则是:同一维度 Label 的数据是可平均和可加和的,也即单位要统一。如风扇的风速和电压就不能放在一个 Label 里。
此外,不建议下列做法:
“`
my_metric{label=a} 1my_metric{label=b} 6my_metric{label=total} 7
“`
即在 Label 中同时统计了分和总的数据,建议采用 PromQL 在服务器端聚合得到总和的结果。或者用另外的 Metric 去测量总的数据。
### 3.4 如何命名 Metrics 和 Label
好的命名能够见名知义,因此命名也是良好设计的一环。
Metric 的命名:
– 需要符合 pattern: [a-zA-Z*:][a-zA-Z0-9*:]*
– 应该包含一个单词作为前缀,表明这个 Metric 所属的域。如:
– – **prometheus**_notifications_total
– **process**_cpu_seconds_total
– **ipamd**_request_latency
– 应该包含一个单位的单位作为后缀,表明这个 Metric 的单位。如:
– – http_request_duration_seconds
– node_memory_usage_bytes
– http_requests_total (for a unit-less accumulating count)
– 逻辑上与被测量的变量含义相同。
– 尽量使用基本单位,如 seconds,bytes。而不是 Milliseconds, megabytes。
Label 的命名:
– 依据选择的维度命名,如:
– – region: shenzhen/guangzhou/beijing
– owner: user1/user2/user3
– stage: extract/transform/load
### 3.5 如何设计适宜的 Buckets
根据前述 histogram 的统计原理可知,适宜的 buckets 能使 histogram 的百分位数计算更加准确。
理想情况下,桶会使得数据分布呈阶梯状,即各桶区间内数据个数大致相同。如图1所示,是本人在实际场景下配置的buckets 数据直方图,y 轴为 buckets 内的数据个数,x 轴是各 buckets,可以看出其近似成阶梯状。这种情况下,当前桶个数下对数据的分辨率最大,各百分位数计算的准确率较高。
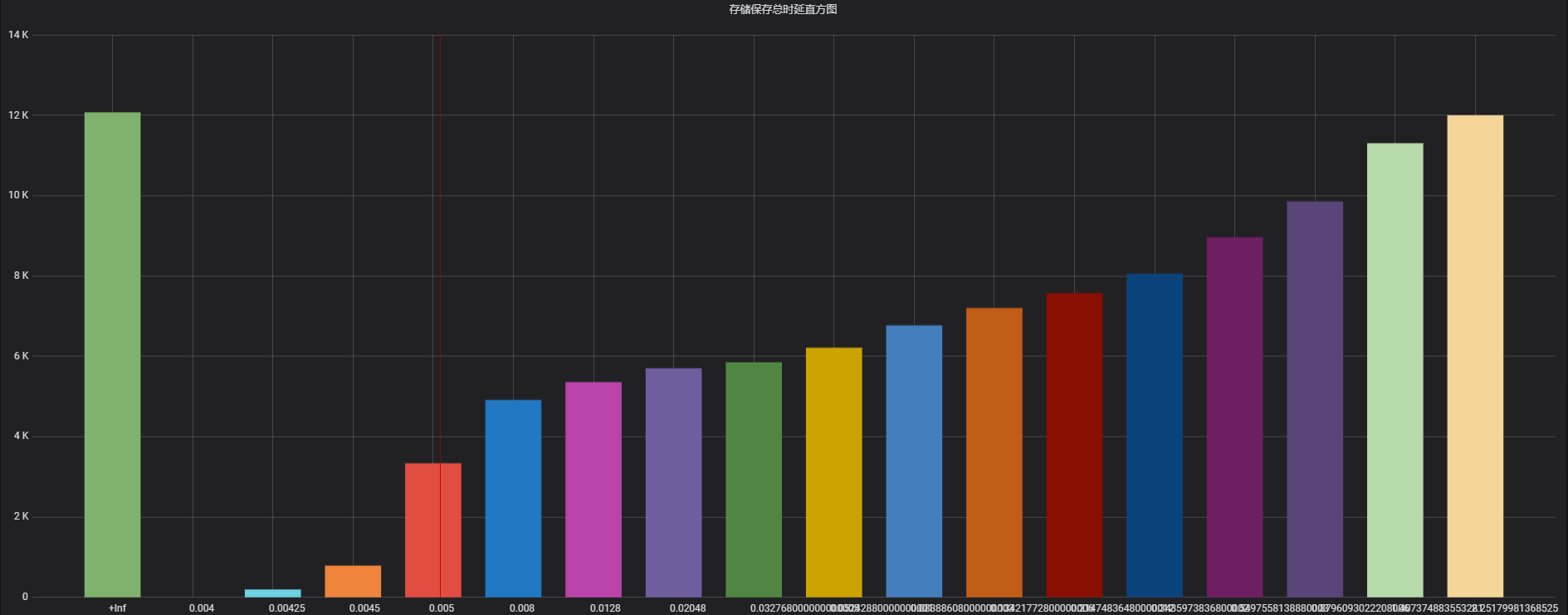
**图1 较为理想的桶数据分布**
而根据笔者实践经验,为了达成以上目标,buckets 的设计可遵从如下经验:
– 需要知道数据的大致分布,若事先不知道可先用默认桶 ({.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10})或 2 倍数桶({1,2,4,8…})观察数据分布再调整 buckets。
– 数据分布较密处桶间隔制定的较窄一些,分布稀疏处可制定的较宽一些。
– 对于多数时延数据,一般具有长尾的特性,较适宜用指数形式的桶(ExponentialBuckets)。
– 初始桶上界一般覆盖10%左右的数据,若不关注头部数据也可以让初始上界更大一些。
– 若为了更准确计算特定百分位数,如90%,可在90%的数据处加密分布桶,即减少桶的间隔。
## 4 实例:TKE-ENI-IPAMD Metrics 设计与规划
### 4.1 组件简介
该组件用于支持腾讯云 TKE 的策略路由网络方案。在这一网络方案中,每个 pod 的 IP 都是 VPC 子网的一个IP,且绑定到了所在节点的弹性网卡上,通过策略路由连通网络,并且使得容器可以支持腾讯云的 VPC 的所有特性。
其中,在 2.0.0 版本以前,tke-eni-ipamd 组件是一个 IP 分配管理的 GRPC Server,其主要职责为:
– cni IP 真正分配/删除的 GRPC Server,分配/释放 IP 会调用腾讯云弹性网卡接口执行相应的 IP 绑定/解绑操作
– Node 控制器(用于给 Node 绑定/解绑弹性网卡)
– Stateulfset 控制器(用于给 Statefulset 预留 IP 资源)
其工作原理和流程如图 2 所示:
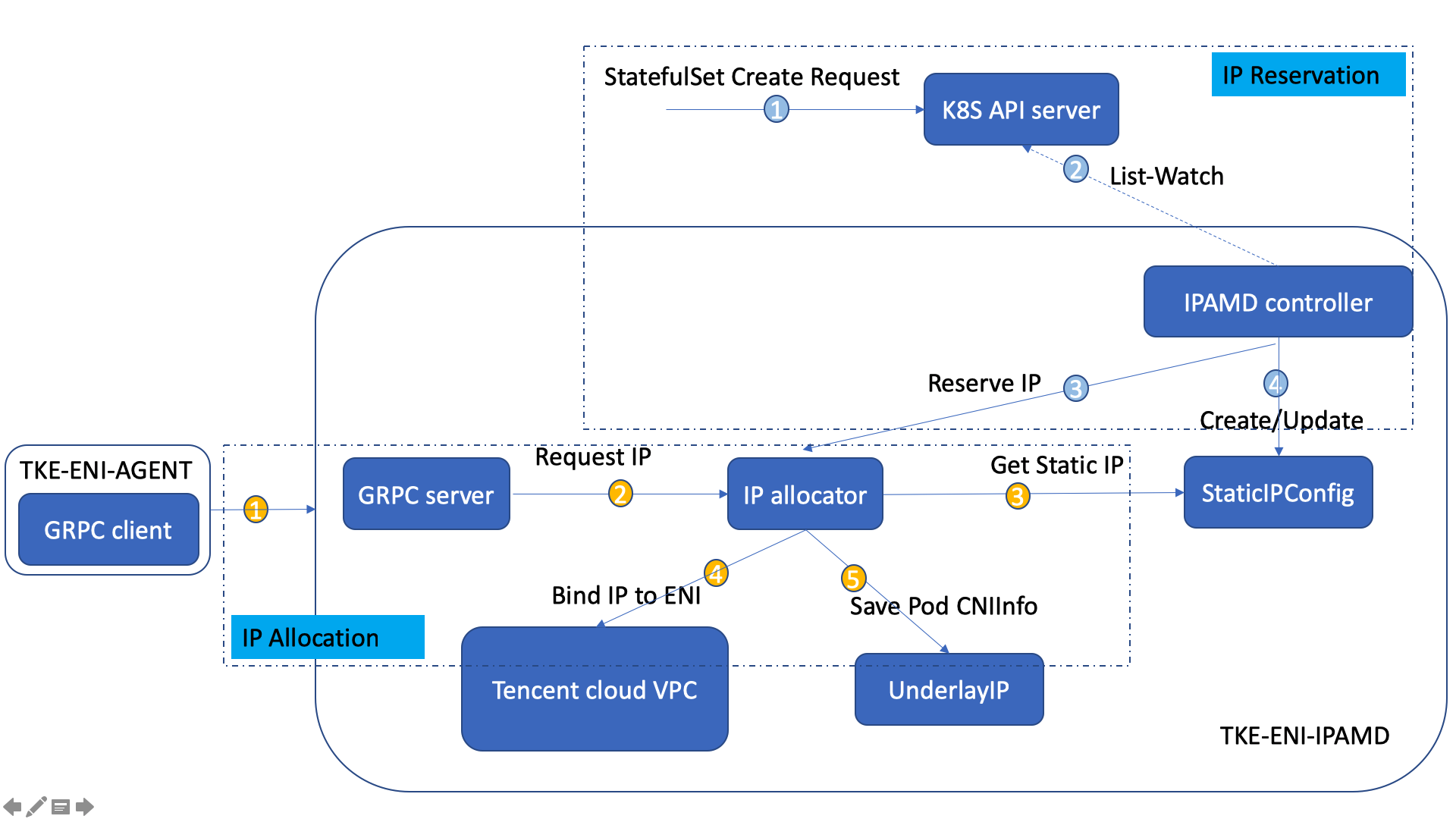
**图2 tke-eni-ipamd(v2.0.0-) 工作原理和流程**
### 4.2 IPAMD 的使用场景和我们的要求
背景:
– ip 分配/释放对时延比较敏感,为了方便确定 ip 分配/释放过程中性能瓶颈是由我们自身代码造成的还是底层模块造成的(如 ipamd 调用的 vpc 接口等)。同时也方便对我们的代码和推进底层模块的性能优化。
– ipamd 运行过程中可能会出现故障等问题,为了及时发现故障,定位问题,也需要有内部监控。
需求:
– 需要能够统计 ip 分配和释放各个阶段的时延,以确定性能瓶颈
– 需要知道当前的并发请求数,以确定 IPAMD 负载
– vpc 接口 ip分配/释放,弹性网卡创建/绑定/解绑/释放耗时比较长,并且经常有失败情况。需要能够统计这些接口的时延和调用成功率,以定位性能瓶颈。
– node controller,statefulset controller 进行 sync 阶段会有一系列流程,希望能清楚主要流程耗时,方便定位瓶颈
– 弹性网卡的创建/删除等过程中容易产生脏数据,需要能够统计脏数据的个数,以发现脏数据问题。
– 需要有较强的实时性,能够清楚的看到最近(~分钟级别)系统的运行状态
我们的场景:
– ipamd 是部署在每个用户集群中的一个组件
– 每个用户集群内有 prometheus server 做聚合,然后每个 region 也有 server 去拉取数据
### 4.3 总体设计
因此,需要以下几类 Metric:
– ip alloc/free 各阶段时延
– 基本运行信息:请求并发数、内存用量、goroutine 数,线程数
– vpc 接口时延
– vpc 接口调用成功率
– controller sync 时延
– 脏数据计数
### 4.4 Histogram vs. Summary
时延可选择 Histogram 或 Summary 进行测量,如何选择?
基于 2.5 节的两者对比,有如下分析:
**Summary:**
– 优点:
– 1. 能够非常准确的计算百分位数
2. 不需要提前知道数据的分布
– 缺点:
– 1. 灵活性不足,实时性需要通过 maxAge 来保证,写死了后灵活性就不太够(比如想知道更长维度的百分位数)
2. 在 client 端已经做了聚合,即在各个用户集群的 ipamd 中已经聚合了,我们如果需要观察全部 user 下的百分位数数据是不行的(只能看均值)
3. 用户集群的 ipamd 的调用频率可能很低(如小集群或者稳定集群),这种情况下 client 端聚合计算百分位数值失去意义(数据太少不稳定),如果把 maxAge 增大则失去实时性
**Histogram:**
– 优点:
– 1. 兼具灵活性和实时性
2. 可以灵活的聚合数据,观察各个尺度和维度下的数据
– 缺点:
– 1. 需要提前知道数据的大致分布,并以此设计出合适而准确的桶序列
2. 难以通过 Label 串联多种 Metrics,因为各个 Metrics 的数据分布可能差异较大,如果都只用一种桶序列的话会导致百分位数计算差异较大
Summary 的缺点过于致命,难以回避。Histogram 的缺点可以通过增加工作量(即通过测试环境中的实验来确定各 Metrics 的大致分布)和增加 Metrics(不用 Label 区分)来较好解决。
所以倾向于使用 Histogram。
### 4.5 Metrics 规划示例
详细的 Metrics 规划内容较多,这里选取了一些代表性的样例,列举如下:
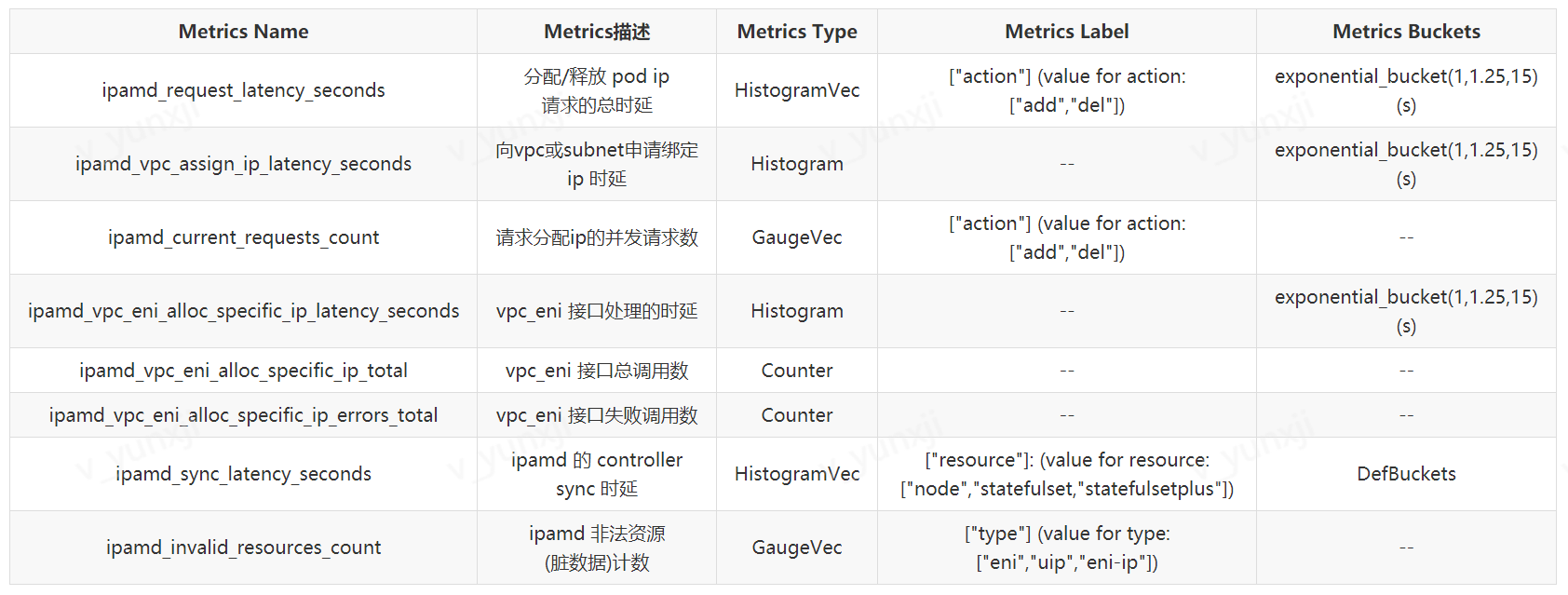
*注1:DefBuckets指默认桶 ({.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10})。*
*注2:以上 buckets 持续微调中。*
## 5 指标收集的 Golang 实现方案
### 5.1 总体实现思路
– 利用 prometheus 的 golang client 实现自定义的 exporter(包括自定义的 Metrics ),并嵌入到 ipamd 代码中,以收集数据
– 所有的 Metrics 作为 Metrics 包的外部变量可供其他包使用,调用测量方法
– 自定义 exporter 参考 prometheus client golang example
– 将收集到的数据通过 http server 暴露出来
### 5.2 Metrics 收集方案
**方案1:非侵入式装饰器模式**
样例: kubelet/kuberuntime/instrumented_services.go
“`
type instrumentedRuntimeService struct { service internalapi.RuntimeService}func recordOperation(operation string, start time.Time) { metrics.RuntimeOperations.WithLabelValues(operation).Inc() metrics.DeprecatedRuntimeOperations.WithLabelValues(operation).Inc() metrics.RuntimeOperationsDuration.WithLabelValues(operation).Observe(metrics.SinceInSeconds(start)) metrics.DeprecatedRuntimeOperationsLatency.WithLabelValues(operation).Observe(metrics.SinceInMicroseconds(start))}func (in instrumentedRuntimeService) Status() (*runtimeapi.RuntimeStatus, error) { const operation = “status” defer recordOperation(operation, time.Now()) out, err := in.service.Status() recordError(operation, err) return out, err}
“`
优点:
– 上层调用函数处几乎不用修改,只需修改调用的实例
– 抽象较好,非侵入式设计,代码耦合度低
缺点:
– 需单独封装每个调用函数,复用度低
– 无法封装内部函数,只能适用于测量对外服务函数的数据
**方案2:defer 函数收集**
样例:
“`
func test() (retErr error){ defer func(){ metrics.LatencySeconds.Observe(…) }() … func body …}
“`
优点:
– 上层调用函数处完全不用修改
– 适用于所有函数的测量
缺点:
– 有点滥用 defer
– 侵入式设计,具有一定的耦合度
### 5.3 目前 IPAMD 的指标收集实现方案
– 时延统计:通过 golang 的 time 模块计时,在函数中嵌入 time.Now 和并在其后 defer time.Since 来统计。
– 调用成功率统计:调用次数在接口函数里直接用 counter 进行统计,失败次数在defer里获取命名返回值统计,最后在 prometheus server 端聚合的时候通过 PromQL 利用这两个数据计算出调用成功率。
– 并发请求数的统计:在最外层的 AddPodIP 和 DelPodIP 中,在函数中和 defer func 中分别调用Inc和Dec。
## 6 总结
本文介绍了 Prometheus Metrics 及最佳实践的 Metrics 设计和收集实现方法,并在具体的监控场景—— TKE 的网络组件 IPAMD 的内部监控中应用了相关方法。
具体而言,本文基于最佳实践,回答了 Prometheus Metrics 设计过程中的若干问题:
– 如何确定需要测量的对象:依据需求(反映用户体验、服务量、饱和度和帮助发现问题等)和需监控的具体系统。
– 何时选用 Vec:数据类型类似但资源类型、收集地点等不同,数据单位统一。
– 如何确定 Label:可平均和可加和的,单位要统一;总和数据另外计。
– 如何命名 Metrics 和 Label:见名知义,应包含监控的系统名/模块名,指标名,单位等信息。
– 如何设计适宜的 Buckets:依据数据分布制定,密集部分桶区间较窄,总体桶分布尽量接近阶梯状。
– 如何取舍 Histogram 和 Summary:Histogram 计算误差大,但灵活性较强,适用客户端监控、或组件在系统中较多、或不太关心精确的百分位数值的场景;Summary 计算精确,但灵活性较差,适用服务端监控、或组件在系统中唯一或只有个位数、或需要知道较准确的百分位数值(如性能优化场景)的场景。
此外,Metrics 设计并不是一蹴而就的,需依据具体的需求的变化进行反复迭代。比如需新增 Metrics 去发现定位可能出现的新问题和故障,再比如 Buckets 的设计也需要变化来适应测量数据分布发生的变化,从而获得更精确的百分位数测量值。
## 参考资料
1. Prometheus 官方文档 :https://prometheus.io/docs/introduction/overview/Prometheus
2. Go client library:https://github.com/prometheus/client_golang

登录后评论
立即登录 注册