
灰度发布,是指在黑与白之间能够平滑过渡的一种发布方式。通俗来说,即让产品的迭代能够按照不同的灰度策略对新版本进行线上环境的测试,灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以对新版本进行测试、发现和调整问题。
KubeSphere 基于 Istio 提供了蓝绿部署、金丝雀发布、流量镜像等三种灰度策略,无需修改应用的业务代码,即可实现灰度、流量治理、Tracing、流量监控、调用链等服务治理功能。本文使用 Istio 官方提供的 Bookinfo 微服务示例,基于 KubeSphere 快速创建一个微服务应用并对其中的服务组件进行灰度发布与熔断。
KubeSphere 是一个基于 Kubernetes 构建的开源的企业级容器管理平台,源代码和安装使用文档已在 GitHub 上开放:
https://github.com/kubesphere/kubesphere
Bookinfo 微服务应用架构
开始之前,先简单介绍一下 Bookinfo 示例微服务应用的架构,该应用分为四个单独的微服务:
- productpage :productpage 微服务会调用 details 和 reviews 两个微服务,用来生成页面。
- details :这个微服务包含了书籍的信息。
- reviews :这个微服务包含了书籍相关的评论,它还会调用 ratings 微服务。
- ratings :ratings 微服务中包含了由书籍评价组成的评级信息。
reviews 微服务有 3 个版本:
- v1 版本不会调用 ratings 服务,因此在界面不会显示星形图标。
- v2 版本会调用 ratings 服务,并使用 1 到 5 个黑色星形图标来显示评分信息。
- v3 版本会调用 ratings 服务,并使用 1 到 5 个红色星形图标来显示评分信息。
(Bookinfo 架构图与示例说明参考自 https://istio.io/docs/examples/bookinfo/)
Step 1:部署 Bookinfo
1.1. KubeSphere 内置了 Bookinfo 示例应用,在项目中可一键部署 Bookinfo。
1.2. 确认应用状态显示 Ready,则说明 bookinfo 微服务创建成功。
Step 2:访问 Bookinfo 应用
2.1. 点击 bookinfo 进入应用详情页,可以看到应用路由下自动生成的 hostname。
提示:本地需在 /etc/hosts 文件中为 hostname 添加一条记录:
{$公网 IP} {$hostname},才可以访问该示例应用。
2.2. 在应用路由下选择 「点击访问」,可以看到 bookinfo 的 details 页面。
2.3. 点击 Normal user 访问 productpage。注意此时 Book Reviews 部分的版本为 v1,只显示了 Reviewer1 和 Reviewer2。
Step 3:添加灰度发布
3.1. 回到 KubeSphere,选择 「灰度发布」,点击 「发布灰度任务」。
3.2. 本文选择 「金丝雀发布」 作为灰度策略,点击 「发布任务」。
3.3. 在弹窗中,填写发布任务名称为 bookinfo-canary,点击 「下一步」。点击 reviews 一栏的 「选择」,即选择对应用组件 reviews 进行灰度发布,点击 「下一步」。
3.4. 参考如下填写灰度版本信息,完成后点击 「下一步」。
- 灰度版本号:v2;
- 镜像:istio/examples-bookinfo-reviews-v2:1.10.1 (将 v1 改为 v2)。
3.5. 金丝雀发布允许按流量比例下发与按请求内容下发等两种发布策略,来控制用户对新老版本的请求规则。本示例选择 按流量比例下发,流量比例选择 v1 与 v2 各占 50 %,点击 「创建」。
Step 4:验证金丝雀发布
再次访问 Bookinfo 网站,重复刷新浏览器后,可以看到 bookinfo 的 reviews 模块在 v1 和 v2 模块按 50% 概率随机切换。

Step 5:查看流量拓扑图
打开命令行窗口输入以下命令,引入真实的访问流量,模拟对 bookinfo 应用每 0.5 秒访问一次。注意以下命令是模拟 Normal user 访问,需要输入完整的命令访问到具体的服务在链路图中才有流量数据。
$ watch -n 0.5 "curl http://productpage.demo-namespace.139.198.111.111.nip.io:31680/productpage?u=normal"
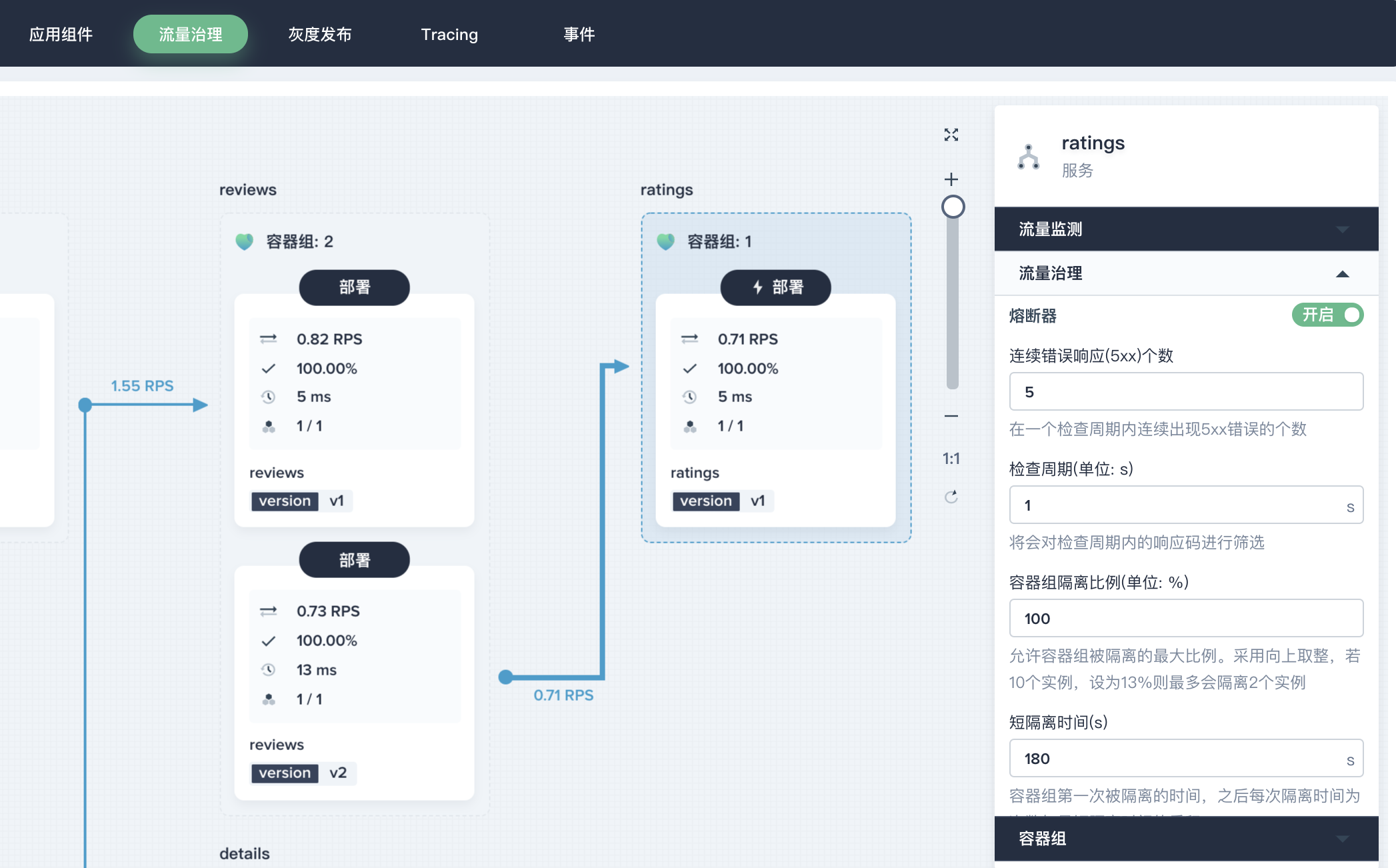
从流量治理的链路图中,可以看到各个微服务之间的服务调用和依赖、健康状况、性能等情况。
查看 Tracing
如果在链路图中发现了服务的流量监测异常,还可以在 Tracing 中追踪一个端到端调用经过了哪些服务,以及各个服务花费的时间等详细信息,支持进一步查看相关的 Header 信息,每个调用链由多个 Span 组成。如下可以清晰的看到某个请求的所有阶段和内部调用,以及每个阶段所耗费的时间。
Step 6:设置熔断规则
从上述的流量拓扑图中可以看到,实际上一个微服务系统的各个服务之间在网络上可能存在大量的调用。在调用过程中,如果某个服务繁忙或者无法响应请求,可能会引发集群的大规模级联故障,从而造成整个系统不可用,引发服务雪崩效应。当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用,达到服务降级的效果,这种通过牺牲局部保全整体的措施就叫做熔断(Circuit Breaking)。
接下来将对 Bookinfo 其中的一个服务设置熔断规则,并通过一个负载测试客户端 (fortio) 来触发熔断机制。
点击 ratings,在右侧展开 「流量治理」,打开 「连接池管理」 和 「熔断器」,参考如下设置。
- 连接池管理:将
最大连接数和最大等待请求数(等待列队的长度)都设置为1,表示如果超过了一个连接同时发起请求,Istio 就会熔断,阻止后续的请求或连接; - 熔断器:参考如下设置,表示每
1秒钟扫描一次上游主机,连续失败5次返回 5xx 错误码的100%数量的主机 (Pod) 会被移出连接池180秒,参数释义参考 熔断器。- 连续错误响应(5xx)个数:5;
- 检查周期(单位: s):1;
- 容器组隔离比例(单位: %):100;
- 短隔离时间(s):180。
连接池参数说明:
- 最大连接数:表示在任何给定时间内, Envoy 与上游集群(比如这里是 ratings 服务)建立的最大连接数,适用于 HTTP/1.1;
- 每连接最大请求数:表示在任何给定时间内,上游集群中所有主机(比如这里是 ratings 服务)可以处理的最大请求数。对后端连接中最大的请求数量若设为 1 则会禁止 keep alive 特性;
- 最大请求重试次数:在指定时间内对目标主机最大重试次数;
- 连接超时时间:TCP 连接超时时间,最小值必须大于 1ms。最大连接数和连接超时时间是对 TCP 和 HTTP 都有效的通用连接设置;
- 最大等待请求数 (等待列队的长度):表示待处理请求队列的长度,默认为 1024。如果该断路器溢出,集群的
upstream_rq_pending_overflow计数器就会递增。
Step 7:设置客户端
由于我们已经在 reviews-v2 中 reviews 容器中注入了负载测试客户端 (fortio),它可以控制连接数量、并发数以及发送 HTTP 请求的延迟,能够触发在上一步中设置的熔断策略。因此可以通过 reviews 容器来向后端服务发送请求,观察是否会触发熔断策略。
在右下角找到小锤子图标打开 Web kubectl (或直接 SSH 登录集群任意节点)。执行以下命令登录客户端 Pod (reviews-v2) 并使用 Fortio 工具来调用 ratings 服务,-curl 参数表明只调用一次,返回 200 OK 表示调用成功。
$ FORTIO_POD=$(kubectl get pod -n demo-namespace | grep reviews-v2 | awk '{pri
nt $1}')
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c reviews /usr/bin/fortio -- load -curl http://ratings:9080/ratings/0
HTTP/1.1 200 OK
···
Step 8:触发熔断机制
8.1. 在 ratings 中设置了连接池管理的熔断规则,最大连接数 和 最大等待请求数(等待列队的长度) 都设置为 1,接下来设置两个并发连接(-c 2),发送 20 请求(-n 20):
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c reviews /usr/bin/fortio -- load -c 2 -qps 0 -n 20 -loglevel Warning http://ratings:9080/ratings/0
···
Code 200 : 18 (90.0 %)
Code 503 : 2 (10.0 %)
···
8.2. 以上可以看到,几乎所有请求都通过了,Istio-proxy 允许存在一些误差。接下来把并发连接数量提高到 3:
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c reviews /usr/bin/fortio --
load -c 3 -qps 0 -n 30 -loglevel Warning http://ratings:9080/ratings/0
···
Code 200 : 22 (73.3 %)
Code 503 : 8 (26.7 %)
···
8.3. 查看结果发现熔断行为按照之前的设置规则生效了,此时仅 73.3 % 的请求允许通过,剩余请求被断路器拦截了。由于此时 503 的返回次数为 8,超过了预先设置的连续错误响应(5xx)个数 5,此时 ratings 的 Pod 将被 100% 地隔离 180 s,ratings 与 reviews-v2 之间也出现了灰色箭头,表示服务间的调用已断开,ratings 被完全隔离。
8.4. 可以给 reviews-v2 的部署 (Deployment) 添加如下一条 annotation,即可查询 ratings 的 istio-proxy 的状态。在 「工作负载」→ 「部署」列表中找到 reviews-v2,点击右侧 ··· 选择 「编辑配置文件」,添加一条 sidecar.istio.io/statsInclusionPrefixes 的 annotation,完成后点击 「更新」。
···
annotations:
sidecar.istio.io/inject: 'true'
sidecar.istio.io/statsInclusionPrefixes: 'cluster.outbound,cluster_manager,listener_manager,http_mixer_filter,tcp_mixer_filter,server,cluster.xds-grpc'
···
8.5. 查询 istio-proxy 的状态,获取更多相关信息。如下所示 upstream_rq_pending_overflow 的值是 10,说明有 10 次调用被熔断。
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c istio-proxy -- sh -c 'curl localhost:15000/stats' | grep ratings | grep pending ··· cluster.outbound|9080|v1|ratings.demo-namespace.svc.cluster.local.upstream_rq_pending_overflow: 10 cluster.outbound|9080|v1|ratings.demo-namespace.svc.cluster.local.upstream_rq_pending_total: 41 ···
Step 9:接管流量下线旧版本
中间顺带演示了熔断,回到之前创建的灰度发布。当新版本 v2 灰度发布后,发布者可以对线上的新版本进行测试和收集用户反馈。如果测试后确定新版本没有问题,希望将流量完全切换到新版本,则进入灰度发布页面进行流量接管。
9.1. 点击 「灰度发布」,进入 bookinfo 的灰度发布详情页,点击 ··· 选择 「接管所有流量」,正常情况下所有流量将会指向 v2。
9.2. 再次打开 bookinfo 页面,多次刷新后 reviews 模块也仅仅只显示 v2 版本。
9.3. 当新版本 v2 上线接管所有流量后,并且测试和线上用户反馈都确认无误,即可下线旧版本,释放资源 v1 的资源。下线应用组件的特定版本,会同时将关联的工作负载和 istio 相关配置资源等全部删除。
总结
本文先简单介绍了微服务示例应用 Bookinfo 的架构,然后使用 KubeSphere 容器平台通过 Step-by-Step Guide 说明了灰度发布、流量治理与熔断的操作。微服务治理与监控是微服务管控中非常重要的一环,而 Service Mesh 作为下一代微服务技术的代名词,KubeSphere 基于 Istio 提供了更简单易用的 Service Mesh 可视化与治理功能。KubeSphere 还在持续迭代和快速发展,欢迎大家在 GitHub 关注和下载体验。
技术交流
欢迎大家加入云原生技术交流群,与 KubeSphere 工程师和用户们共同交流云原生技术与开发实践经验。


看起来有点不错
这个很酷啊,不需要再去调研istio了
厉害!