
作者:Evan Powell,MayaData首席执行官
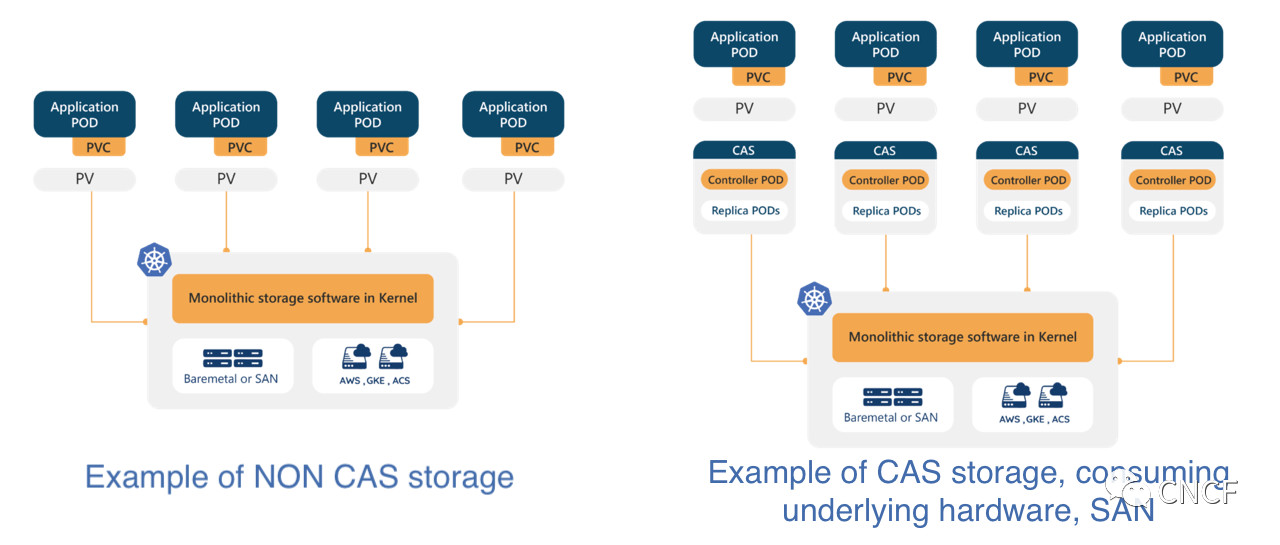
去年,我们发布了一篇博客,其中有来自CNCF团队的大量指导和反馈,开始定义容器附加存储(Container Attached Storage, CAS)方法。提醒一下,我们当然倾向于将OpenEBS以及具有类似架构的解决方案,如专有的PortWorx和StorageOS,包括在CAS类别中。
https://www.cncf.io/blog/2018/04/19/container-attached-storage-a-primer/
现在OpenEBS已经作为CAS方法的开源示例,作为沙箱项目贡献给了CNCF(2019年5月14日),我认为现在应该及时更新这个类别的概述。
去年的定义者类别的博客建立在我多年前在存储开发者大会(Storage Developer Conference)上分享的方法愿景,MayaData的首席技术官Jeffry Molanus在FOSDEM(免费和开源软件开发人员的欧洲会议)和其他地方上进行了更深入的讨论,包括展示即将推出的可用软件突破百万IOPS障碍:

快速回顾一下:
CAS的关键属性包括:
- 使用Kubernetes和容器向运行在Kubernetes上的工作负载交付存储和数据管理服务;
- 添加底层存储,无论是云卷、传统存储SAN、一堆磁盘、NVMe或其他;
- 每个工作负载存储意味着每个组和工作负载都有自己的微存储系统,由一个或多个控制器组成,这些控制器本身是无状态的,此外还有底层数据容器。
CAS的主要好处:
- 立即部署 – 几秒钟,存储保护你的数据和管理底层的环境,甚至为常见的CI/CD提供快照和克隆和迁移的用例(注意,一些CAS方案有内核模块,取决于你的环境而影响性能)。
- 零操作 — 实际上并不存在NoOps之类的东西 — 但是,将存储智能嵌入Kubernetes本身可以大大减轻存储操作的负担。
- 以相同的方式在任何地方运行 — 特别是使用运行在用户空间中的OpenEBS这样的解决方案,你可以抽象出不同的存储风格;这当然与Kubernetes的使命是一致的!
- 节省资金,提高云存储的弹性 — 这要归功于精简配置和跨可用区域的能力,以及在某些情况下,用户通过使用容器附加存储节省了30%或更多的云存储
而关键的驱动因素 — 为什么现在有可能,甚至是必要的?
- 应用程序已经发生了变化 — 应用程序和构建它们的团队现在有非常不同的需求;例如,请参见NoSQL和称为NewSQL解决方案的增长。
- Kubernetes正在变得无处不在 — 第一次提供了一种方法来扩展比如容器附加存储软件的解决方案。
- 容器更高效 — 也更短暂 — 所以在典型的环境中,你会看到比VM多10到100倍的容器,而且它们比传统VM更具动态性。
- 存储介质的速度可能比CEPH编写时快10,000倍 — 你的环境中的瓶颈曾经是磁盘驱动器,而存储软件通过跨环境的分割出色地解决了这个瓶颈;现在存储介质的速度快得惊人,而存储软件倾向于分割数据,这就增加了延迟.
如果你对充满幽默的存储历史感兴趣,请看看这几张充满GIF的演示文稿:
https://docs.google.com/presentation/d/11dNx7-HEqUg6ZeUAtaKAzfqfscmuDcXaKWbjxbM3us4/edit#slide=id.g4d8fc3d7a4_1_0
有关过去一年的资料:
MayaData和其他CAS解决方案体验到的增长,验证了容器附加存储方法对于许多用户来说非常有意义。
我们已经学习了很多关于这些部署模式和常见工作负载的知识,我在这里总结了其中的一些。下面的数据来自于对OpenEBS用户的调查,但是CAS的模式在更广泛的范围内是相似的 — 请记住OpenEBS是开源的,而且特别轻量级,因此它可能会稍微偏向于云部署。
以下是一些有趣的数据点:
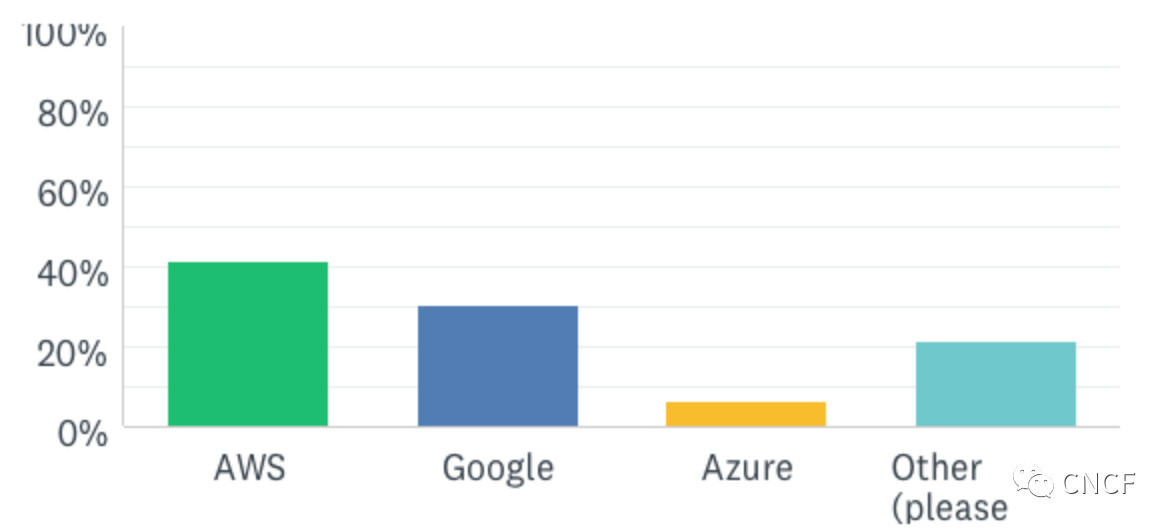
1. 当被问及在哪里运行OpenEBS时,用户的回答都是肯定的(即以上所有):
公共云还是私有云?

哪家云?
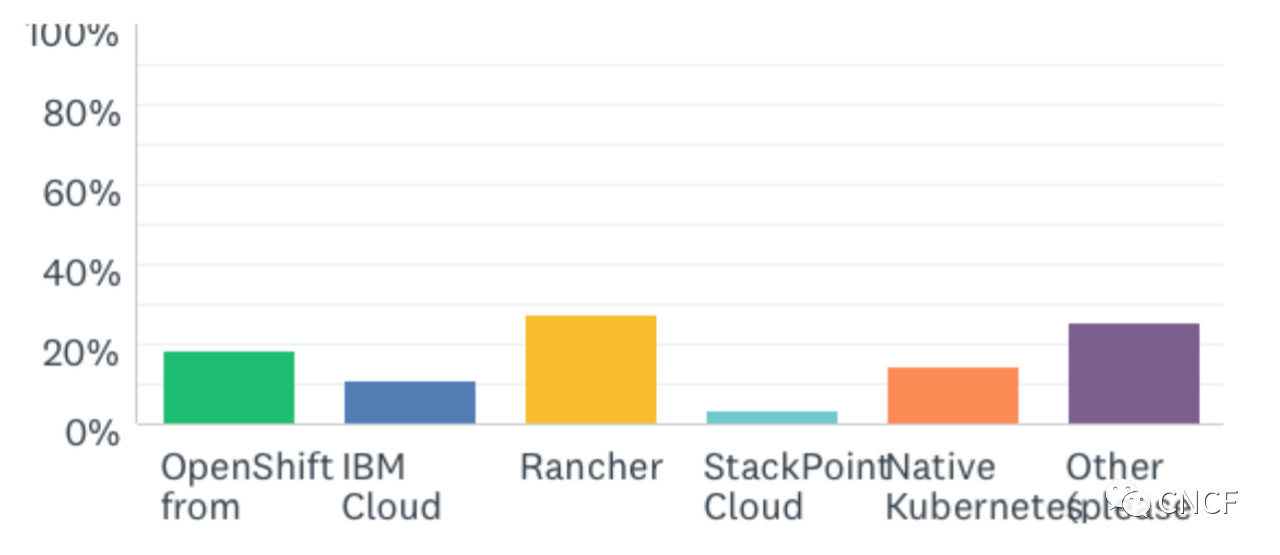
哪个Kubernetes发行版?
2. 同样,当被问及OpenEBS上运行的工作负载时,我们再次看到了各种各样的答案:
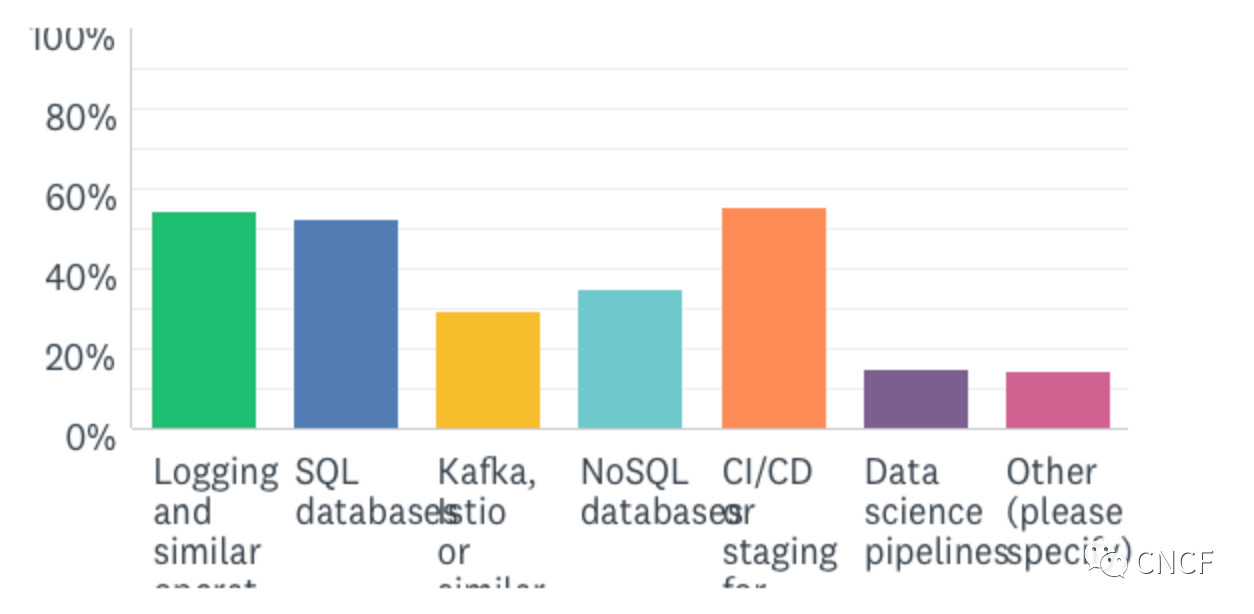
我们的发现与我认为所有在存储领域工作过的人多年来的发现类似 — 工作负载和解决方案会拉动存储。
在过去的一年里,我们也看到了与其他CAS解决方案供应商者合作的机会。例如,我们与Portworx合作支持和改进WeaveScope。MayaData团队为WeaveScope项目提供了扩展,以增加PVC和PV的可见性,以及底层存储;Portworx工程师提供了对用例的反馈和洞察。当然,该软件贡献上游项目WeaveScope本身,而我们还为社区成员提供了一个名为MayaOnline的免费监控和管理解决方案,其中包含了这些代码。
CAS允许Kubernetes数据和工作负载一起编排 — 经常被问到的自然问题是“伙计,我的数据在哪里?”。正如你所看到的,WeaveScope和MayaOnline为这些问题和相关问题提供了实时跟新的答案:
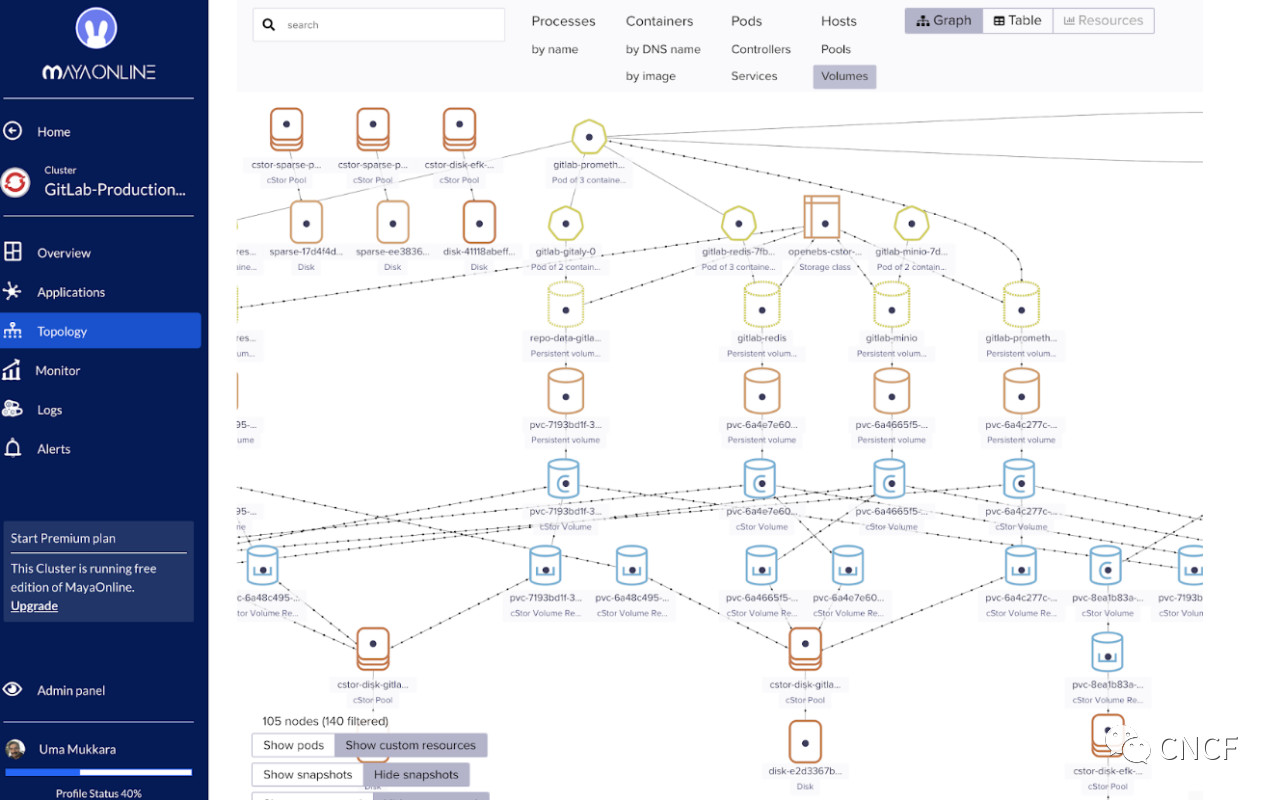
结论
自从我们在2017年初首次开源OpenEBS以来,也自从我们在2018年春天帮助定义了容器附加类别以来,感谢大家在过去几年里的反馈和支持。我们越来越多听到和看到评论员和“思想领袖”使用CAS类别 — 这很好。为数据服务添加真正的Kubernetes原生解决方案的想法太有意义了。
毕竟,对应用程序和工作负载本身有好处的东西,对所有形式的基础设施,包括存储服务也有好处。尽管解决云锁定问题可能会影响云供应商的主要收入来源,但总体而言,我们仍然看到Kubernetes和云原生社区对CAS模式的支持。
我们比以往任何时候都更接近于数据的开放性和灵活性,来跟上应用程序的步伐。再次感谢你对CAS模式的兴趣。请与你的反馈、用例和见解保持联系。
文章来源:CNCF
原文:https://mp.weixin.qq.com/s/c7-rH3v3f5E7D5sx8d87Lg

登录后评论
立即登录 注册