
目的
redis clustor 需要6台服务器才能正常运⾏,由于种种原因,开发或者某些特别的需求,只能在3台服务器上运⾏redis clustor。在不使用哨兵模式情况下,而使⽤最新的clustor模式运行redis。
本文仅作为redis部署方式的研究及理解
准备工作
制作redis docker.latest镜像其中包含以下组件:
1. redis-cli
2. ruby
3. redis-trib
打包到镜像上传到阿里镜像服务器中cluster-redis:latest
创建集群操作
3台服务器上各自运行两个redis容器
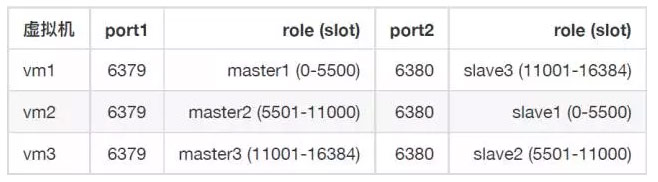
使用以下编写好的redis-cluster部署文件,可在一台部署出两个不同端口,不同角⾊的redis容器。
redis-cluster.yaml
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: redis-blue labels: app: redis member: redis-blue spec: replicas: 3 template: metadata: labels: app: redis member: redis-blue spec: hostNetwork: true containers: - name: redis image: registry.cn-hangzhou.aliyuncs.com/wise2c/cluster-redis:latest command: ["/bin/sh", "-c"] args: ["echo 'dir /tmp/data' >> /root/redis.conf && /usr/local/bin/redis-server /root/redis.conf"] #- /usr/local/bin/redis-server #- /root/redis.conf ports: - name: redis-port containerPort: 6379 - name: cluster-port containerPort: 16379 volumeMounts: - mountPath: /tmp/data name: data volumes: - name: data hostPath: path: /tmp/redis-blue --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: redis-green labels: app: redis member: redis-green spec: replicas: 3 template: metadata: labels: app: redis member: redis-green spec: hostNetwork: true containers: - name: redis image: registry.cn-hangzhou.aliyuncs.com/wise2c/cluster-redis:latest command: ["/bin/sh", "-c"] args: ["sed -i 's/6379/6380/g' /root/redis.conf && echo 'dir /tmp/data' >> /root/redis.conf && /usr/local/ports: - name: redis-port containerPort: 6380 - name: cluster-port containerPort: 16380 volumeMounts: - mountPath: /tmp/data name: data volumes: - name: data hostPath: path: /tmp/redis-green
kubectl create -f redis-cluster.yaml
执行以下脚本,创建出整个redis集群。redis会自动分配哈希槽,使得master与其对应的slave不会出现在同一台服务器上。
create_cluster.sh
#!/usr/bin/env bash
redis_count=`kubectl get pod -o wide -l app=redis | grep Running | wc -l`
#echo "redis_count:"$redis_count
if [ $redis_count -ne 6 ]; then
echo "the running redis count: ${redis_count} is error"
exit 1
fi
redis_blue_ips=`kubectl get pod -o wide -l app=redis -l member=redis-blue | awk 'NR>1{printf $6":6379 "}'
redis_green_ips=`kubectl get pod -o wide -l app=redis -l member=redis-green | awk 'NR>1{printf $6":6380 "}'
redis_ips=$redis_blue_ips" "$redis_green_ips
echo "redis_ips:"$redis_ips
redis_blue_name=`kubectl get pod -o wide -l app=redis -l member=redis-blue | grep Running | awk '{printf $1" "}'
#echo $redis_ips | awk -F' ' '{for( i=1;i<NF; i++ ) print $i}' `` kubectl create -f redis-cluster.yaml bash create_cluster.sh
关掉其中一台机器 由于master和slave 不在同一台机器上,当我们直接关掉其中⼀一台vm,比如vm2
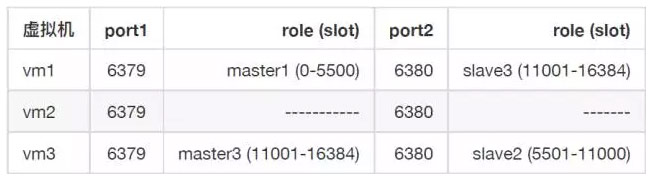
这时vm3上,由redis cluster自动恢复vm3slave2(6380) —> master2(6380) 提升为master,集群工作正常,业务不中断。
恢复关掉的的机器
当我们重新启动vm2, 这时候集群的状态:
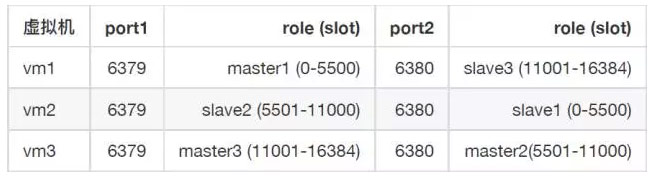
这时集群工作正常,此时vm3有2个master。如果我们关掉vm3,会让集群中2个master同时下线,导致集群无法自动恢复。
重点:执行以下脚本,提升slave2到master2,恢复集群的自动修复功能。
failover.sh
#!/usr/bin/env bash
redis_blue_name=`kubectl get pod -o wide -l app=redis -l member=redis-blue | grep Running | awk '{printf $1":6379 redis_names=`kubectl get pod -o wide -l app=redis -l member=redis-blue | grep Running | awk '{printf $1","}'
redis_array=${redis_names//,/ }
for redis_name in $redis_array
do
kubectl exec -it ${redis_name} -- redis-cli cluster failover
done
bash failover.sh
集群自动恢复,变成下面的状态。

集群工作正常,业务不中断。
作者后话
以上的操作,目的是让各台虚拟上不出现有2个master。当其中一台虚拟机出现当机,集群就不能正常工作.。如果是3台master和3台slave分别在不同的机器刚好错开,redis cluster能自动恢复.。最好的解决方案,依然是有6台虚拟机、3台master、3台slave的redis cluster。
To do
我们可以进⼀一步将
- create-redis.sh
- failover.sh
- kubectl
制作为镜像, k8s deployment运行此镜像。实现:
- 创建集群
- 恢复集群的自动修复功能(任意关掉其中一台服务器,业务不中断。每过一秒,检查集群中是否有slave需要提升权限,集群都能正常工作.业务不中断。)

请问可以贴一下redis.conf内容吗
yaml文件格式不对呀。还有括号的缺失呀
博主不愿意分享真实yaml文件吧
hostNetwork: true使用这个参数是必须的吗?使用这个参数的话,只能部署小于k8s nodes个数的副本数