通过Portworx云原生存储,在Amazon EKS里运行高可用SQL Server容器
在本文我们将分析,如何使用Amazon Elastic Container Service for Kubernetes (Amazon EKS, https://amazonaws-china.com/eks/),来在容器中部署Microsoft SQL Server。文中讨论的方式和与原理,也适用于其他需要高可用和持久性、并符合可复用的DevOps方式的有状态应用。例如运行MongoDB、Apache Cassandra、MySQL、或者大数据处理等。
首先能够被支持在容器中运行的是SQL Server 2017版本。我们可以在Linux容器中,使用Kubernetes (https://amazonaws-china.com/kubernetes/)来运行SQL Server生产负载。
Microsoft SQL Server是被广泛使用的数据库。SQL Server提供一系列很不错的功能,也有很不错的开发者社区。但是它需要比较多的运维,也比开源的或者云端的数据库成本要更高。很多为了降低成本的用户会转向开源方案来降低软件授权的成本。另一些用户会迁移工作负载到关系数据库管理系统(RDBMS)服务里,比如Amazon RDS for Microsoft SQL Server或者Amazon Aurora。
但也有许多情况,用户无法离开SQL Server。这有很多可能的原因,比如需要重新部署和开发的成本,以及需要配置具备相关技能的开发工程师和运维工程师资源的成本等。用户可能无法使用云服务,可能是软件授权和支持的问题,或者一些技术问题。
在这样的情况下,可以通过把SQL Server数据库部署到Amazon Elastic Compute Cloud (Amazon EC2, https://amazonaws-china.com/ec2/)实例上,来使用云服务。这种方式保持了需要满足特定需要的灵活性,也提供了云的各种好处。这些好处包括对于物理硬件层的抽象,以及按需付费的模式,以及其他的云端服务能力。虽然这种方式比本地部署SQL Server要更有优势,但管理额外的数据库实例的管理成本仍然有可提升的空间。
使用Kubernetes来运行SQL Server会有更多优势:
- 简化:在容器中部署和运维SQL Server会很简单和快捷,比起传统的部署模式会大幅降低工作量。这是因为部署不需要安装,而是通过上载新的镜像来完成。容器提供了一个可以任何环境运行的抽象层。
- 更优化的资源使用:容器化的SQL Server提供了高密度,允许内部负载共享一个通用的资源池(内存、CPU、存储)。因此减少了闲置的资源,增加了基础架构资源的利用率。
- 降低软件授权的成本:在容器中运行SQL Server的一些场景,不论是高密度还是低密度,都会降低软件授权的成本。我们会在本文后面详细介绍软件授权的成本。
目前,AWS里有四种容器服务:
- Amazon Elastic Container Service (Amazon ECS,https://amazonaws-china.com/ecs/):一个高度可扩展的,高性能的调度服务,与AWS的多项服务原生集成。
- Amazon Elastic Container Service for Kubernetes (Amazon EKS):一个AWS提供的管理服务,可以方便的使用Kubernetes部署、管理和扩展容器应用。
- AWS Fargate (https://amazonaws-china.com/fargate/):一个Amazon ECS的计算引擎,可以帮助用户在不需要管理服务器/集群的情况下,来运行容器。
- Amazon Elastic Container Registry (Amazon ECR,https://amazonaws-china.com/ecr/):一个完整的被管理的Docker容器注册表,便于用户来存储、管理和部署Docker容器镜像。
在AWS上作架构的一个重要原则是 Multi-AZ部署,来产生高可用的和高性能的负载。你可以直接使用Amazon Elastic Block Storage (Amazon EBS, https://amazonaws-china.com/ebs/) 卷作为SQL Server容器的存储解决方案,但这会限制这些容器只能在单一的可用区域内。Portworx可以用来解决这个问题。
Portworx是AWS全球的合作伙伴,也是微软的高可用和容灾方案合作伙伴。Portworx使得SQL Server能够以高可用的方式,跨多个AWS可用区域,作为EKS集群来运行。Portworx也可以配置成跨越AWS Auto Scaling Groups的高可用。当使用SQL Server实例的存储层的时候,这些功能确保了存储的可用性。存储的可用性是保证容器化SQL Sever实例高可用性所必须的。
这篇文章介绍了,如何使用Amazon EKS和Portworx云原生存储(基于Amazon EBS 卷)来在生产环境中运行SQL Server负载。我们也提供了一份样例脚本( https://github.com/awslabs/aws-eks-portworx-sql) ,来自动地在几分钟内完成SQL Server实例的部署过程。
使用容器最大的好处是简单和有效。不需要安装SQL Server或者配置容错集群。使用简单的命令就可以部署SQL Server容器,然后Kubernetes会提供SQL Server部署的高可用。在一些情况下,Kubernetes中部署的SQL Server的容器实例,可用性甚至高于那些部署在容错集群上的。后面“高可用性”部分我们会介绍更多细节。
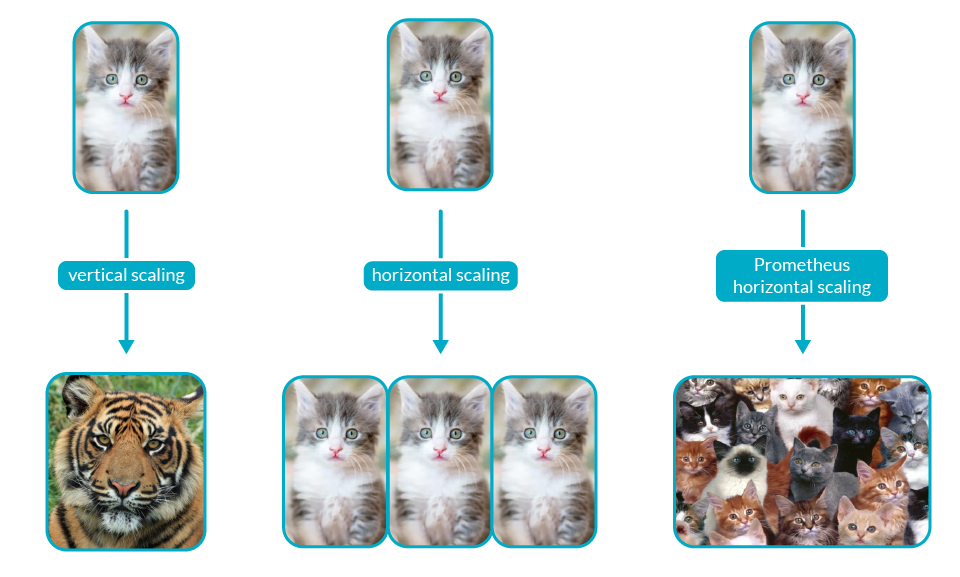
在容器中运行SQL Server的主要好处来自于高密度部署和资源共享。容器和虚拟机(VMs)的根本性的不同是:在运行过程中,与虚拟机不同,容器并不是被限定到一系列固定的资源上的。一个共享的资源池经常被一组容器在同一个主机上共享来使用。这使得容器可以随时调整使用更多或者更少的资源。只要资源的总消耗不高于总资源池的资源容量,所有的容器都能有足够的资源来运行。
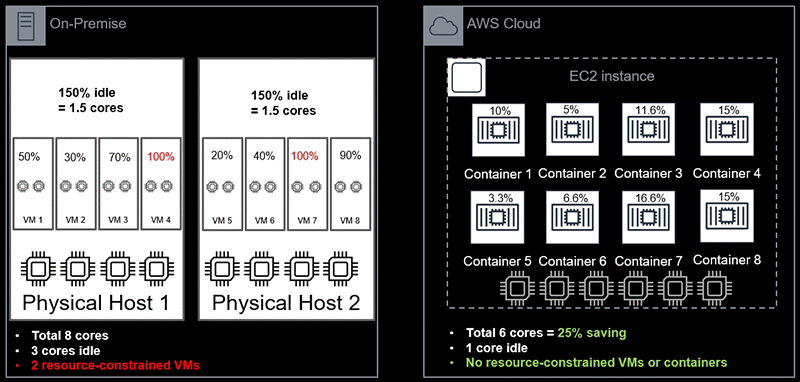
如图中所示,一个按照自身配置满负荷资源运行的VM,无法在使用主机上闲余的资源。在这个例子中,资源池有两台物理主机,包括8个CPU核。尽管有3个CPU核仍然闲余未被使用,VM4和VM7仍然在自身满资源的状态下运行,而无法扩展使用闲余的资源。
让我们来看一下能够更有效利用资源的另一种方式。假设存在一种情况,你不需要担心物理主机资源的数量。你只需部署一个满资源的VM来运行一组应用,比如一些SQL Server实例。假设你可以让你的应用共享所有资源,并且确保互相之间没有冲突。图右侧的部分就是这样的解决方案:使用Amazon EC2实例上的容器服务。
使用这种解决方案。没有容器存在资源限制,总体的CPU核资源从8个减少到了6个。对于内存资源来说也是一样的。容器化,可以增加底层架构的使用效率和有效性。这对于运行SQL Server这样的有峰值使用量的应用来说尤其合适。
另一个在容器中运行SQL Server的好处是可以减少软件授权的成本。SQL Server是一个商业产品,使用授权的限制会影响我们从技术角度的决策,或者可能大幅推高我们的商业成本。微软授权SQL Server在容器中使用的方式,会很大程度上缓解这些问题。在后续“SQL Server容器软件授权”部分有更多的细节。
Kubernetes是一个开源软件,可以用来部署和管理可扩展的容器化应用。它是一个中心化管理的分布式系统,用来运行和调度容器。
当你手边已经有一个Kubernetes集群,使用和部署应用还是比较直接的。但是部署和运维一个Kubernetes集群本身还是比较复杂的。
Amazon EKS把复杂的Kubernetes集群的进行抽象。它提供一个完整的受管理的Kubernetes,用户可以调用AWS API进行部署和管理。作为响应,用户会收到一个上游Kubernetes api-server端点,这个端点允许用户连接到新的Kubernetes集群并使用。
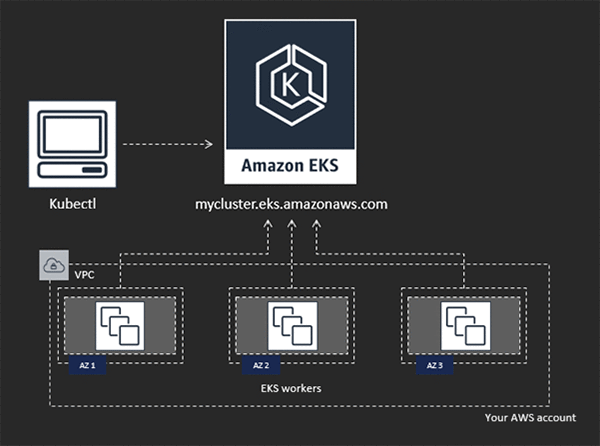
SQL Server在每一个Pod (一组总是一起运行的容器)中,被部署为一个单独的容器。多个SQL Server的实例可以被部署为多个Pods。Kubernetes调度这些位于集群的节点上的Pods,确保有足够的资源来运行它们。
为了在Kubernetes上运行SQL Server,你需要创建一个Kubernetes部署。这个部署创建了一个属于该部署且可以被管理的复制集(ReplicaSet)。这个ReplicaSet确保包含一个单独SQL Server容器的一个单独的Pod,可以在集群上运行。当然,你也可以在同一个集群上部署SQL Server的多个实例来达到高密度。
存储的使用也进行了抽象化。对Kubernetes来说,持久卷(PV)是一个封装了存储解决方案实施细节的对象。这可能是Amazon EBS卷,一个网络五年间系统(NFS)共享,或者其他解决方案。PV的生命周期跟使用它的Pod的生命周期互相独立不相干。
要使用PV,另一个对象 – 持久卷声明(PVC, Persistent Volume Claim)需要被创建。PVC是一个使用请求,用来请求使用定义了大小和访问模式(读/写)的存储。一个PVC也可以定义存储类(Storage Class)的值。存储类是另一类抽象,允许用户定义存储解决方案的一些参数,比如延迟(latency)和IOPS。
管理员需要定义一个存储类,例如AWS标准目的GP2 EBS卷,或者Portworx高(中) I/O卷。管理员然后可以基于这个存储类来创建PV,或者允许用户基于PVCs来动态的创建PV。而后应用可以Include一个PVC,把PV分配给某个特定的pod。为了让这个过程更加简单,你可以定义一个默认的存储类。例如,假设一个Amazon EBS标准目的SSD (gp2)卷,被定义成Kubernetes集群上的默认存储类,即使一个PVC没有Include某一个特定的存储类注解,Kubernetes将会自动注解它到AWS GP2 EBS存储类上。
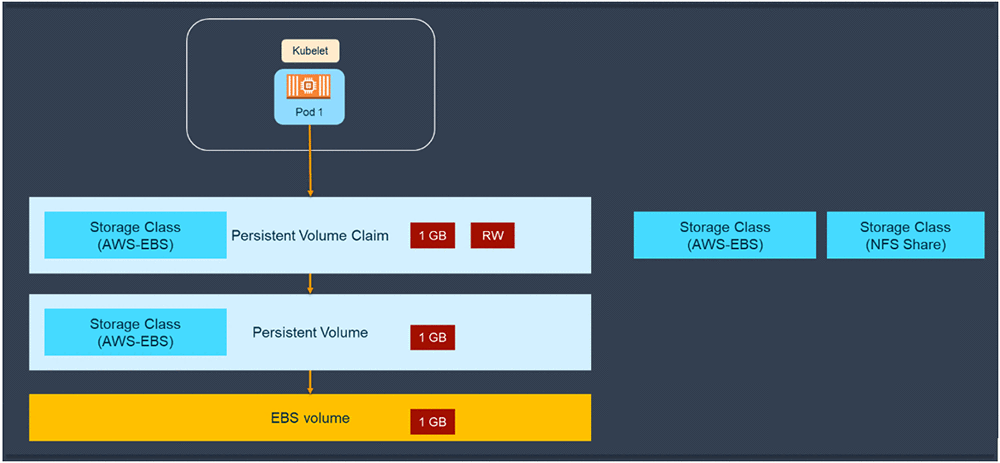
存储是SQL Server部署中的一个关键部分。在AWS上部署SQL Server最常用的存储方式是使用EBS卷。在Kubernetes集群中有两种存储类可以直接用来使用EBS卷。
- Aws-gp2 (https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.html) 提供了一个平衡成本和性能的解决方案。
- Aws-io1 (https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.html),适用于需要稳定的IOPS和通道速度的生产环境负载。
你可以直接在EBS卷上存储SQL Server文件。然而,在许多情况下,一个单独的EBS卷并不能满足要求。例如,你也许需要在Multi – AZ架构下的高可用性,需要超出单独EBS卷限制的存储容量,或者需要单独卷无法达到的IOPS和通道速度。你可以尝试使用SQL Server Always On可用性组来解决高可用性问题,但是它无法解决存储容量、IOPS、和通道速度问题。同时针对SQL Server容器的Always On可用性组功能,目前也仅在SQL Server 2019是Preview发布。
你可以满足所有这些要求,包括高可用性、IOPS和通道速度,通过把几个EBS卷合并成存储池,在每一个EC2实例里Striping卷,并且把存储池延展到不同可用性区域的多个实例里。你可以部署一个独立的存储集群,并且通过NFS存储类在Kubernetes集群中使用该存储集群。但这些操作会增加一些管理复杂度。
Portworx是一个存储集群解决方案,可以在Kubernetes集群中服务应用和部署。Portworx是部署在Kubernetes之上的。Portworx使用Kubernetes来抽象化所有复杂的管理存储集群的操作。Portworx提供一个简单的存储类,可以被Kubernetes集群里的所有的有状态应用来使用。
在AWS里,Portworx通过对附加在Kubernetes集群(EC2实例)上的Worker Node上的EBS卷进行声明,来提供存储类。Portworx会把所有卷放进一个抽象的存储池里,然后从存储池里创建逻辑卷。当SQL Server的应用创建一个包括Portworx存储类的PVC,并且限定卷大小,一个包括具体大小的Portworx PV就被分配给了应用。
Portworx可以创建快照,称为3DSnaps。通过这个功能,你可以在SQL Server不停机的情况下,或者把SQL Server调成 read-only模式的情况下,来创建SQL Server卷的连续快照。Portworx的另一个功能是可以导入已有的EBS卷到Portworx逻辑集群卷里。这使得负载的迁移变得很容易。通过Portworx,集群可以变得密度很高,意味着你可以在一个主机上运行更多的容器。针对Kubernetes的一般性建议是每个VM/100个Pods。Portworx有一些客户甚至可以在每个主机上运行200~300个Pod (https://portworx.com/architects-corner-aurea-beyond-limits-amazon-ebs-run-200-kubernetes-stateful-pods-per-host/)。

Portworx在EBS卷之上,使用自己最佳颗粒度的快照层。
Portworx快照的创建和存储都是实时的。这是因为Portworx的快照是re-direct-on-write快照,实际上,Portworx可以通过书签方式(bookmark)即时地创建一个卷的实时快照。因为实际上的存储块并没有被copy,不论作多少次快照,都没有由于写入带来的资源使用。你可以创建一个每15分钟一次的快照组,而不影响到任何使用性能。快照可以跨多个EBS卷,集群,并且以应用一致持续的状态。
Portworx也支持重新定义虚拟卷的尺寸。你可以使用这个功能,结合EBS弹性卷,动态的来扩大或者缩小存储,来避免由于过度部署带来的额外成本损失。Portworx快照并不消耗额外的空间,这是因为存储方式是redirect-on-write,包括一个B-tree–based的文件系统,这样Portworx可以保持追踪同一个块的不同版本的数据。因此,这些快照非常节省空间。
你可以使用Portworx云快照策略来自动上载所有的快照到Amazon Simple Storage Service (S3, https://amazonaws-china.com/s3/),并且删除本地的快照。这个功能帮助防止本地不断增加的快照来消耗EBS卷空间。Portworx也有一个本地快照保留策略,来帮助在本地保存一些特定的快照。这个策略可以基于每个卷,也可以在卷被创建或者卷被更新的时候动态的来配置。Amazon S3是一个对象存储服务,提供99.999999999百分比的可用性。被上载到S3的Portworx快照,包括实际的存储块,而不仅仅是书签。因此它提供了预防数据丢失的另一个保护层。
对本地的快照来说,恢复操作也是即时的,对于cloudsnaps (https://docs.portworx.com/cloud/backups.html) 来说,恢复操作也几乎是即时的,因为Portworx仅仅在Amazon S3中存储快照的不同部分。
关于性能和延迟,Portworx逻辑卷被每个Pod在本地访问。在后台,Portworx把block复制到其他可用性区域的其他worker node上。这样,当pod意外恢复到其他可用性区域后,可以快速的重新访问本地数据,继续运行。
Portworx有客户运行大规模数据库比如Cassandra和Elasticsearch (https://portworx.com/ge-mesosphere-dcos-portworx/),在AWS上成功运行上百T的数据。这些客户认可在EBS上运行Portworx带来的成本节省收益。需要了解更多Portworx的功能,可以访问Portworx的网站 (https://portworx.com/products/features/)。
以上我们解释了,你可以结合使用Amazon EKS和Portworx存储,作为一个运行SQL Server的可靠的并且灵活的解决方案。接下来,我们将描述把SQL Server部署到Amazon EKS上的具体步骤。你可以按照下面的说明,在自己的环境里快速部署并验证解决方案。
本文描述的解决方案基于PowerShell脚本。可以是Windows PowerShell或者PowerShell Core。如果你希望在Windows 10或者Windows Server 2016来运行脚本,你可以使用自带的Windows PowerShell。你也可以在MacBook或者Linux机器上来运行这些脚本。首先你需要在你的目标设备上安装PowerShell Core (https://docs.microsoft.com/en-us/powershell/scripting/setup/installing-powershell?view=powershell-6)。另一种选择,Mac的用户可以使用ReadMe文件里的说明来部署一个本地的Docker容器,来包括所有这些前置条件。
这个脚本会调用在AWS Tools for PowerShell ( https://amazonaws-china.com/powershell/) 里的PowerShell cmdlets 。确保你的机器上安装了最新版本的 AWS Tools for Windows PowerShell (https://www.powershellgallery.com/packages/AWSPowerShell/3.3.343.0),或者AWS Tools for PowerShell Core (https://www.powershellgallery.com/packages/AWSPowerShell.NetCore/3.3.343.0)
这些脚本有时候需要AWS 命令行界面(AWS CLI)工具来调用Amazon EKS APIs。确保你安装了最新版本的AWS CLI (https://docs.aws.amazon.com/cli/latest/userguide/installing.html)。
最后,你需要必须的AWS账户的权限来运行脚本。这包括运行AWS CloudFormation模板、创建虚拟私有云(VPCs)、子网、安全组、以及EC2实例,并且部署和访问EKS集群。你可以使用一个IAM用户(在你的计算机上保存一对可长期使用的Keys)。这种情况下,你需要允许AWS在PowerShell 和 AWS CLI上使用这些Keys。
另一种方式,你可以使用IAM角色,它具有被分配给EC2实例的所有必须的权限,可以用来运行脚本。这个方式,不需要额外的配置,AWS PowerSheel Tool和AWS CLI会从EC2实例的元数据那里自动获得临时的身份信息。
作为可选,这个包里面包括一个Docker文件,它会直接创建脚本,以及直接创建以上所有的必须的部分(AWS CLI、AWS cmdlets这些)到microsoft/powershell Docker镜像里。这样你就可以直接使用docker run来setup环境,不论是在MacOS、Linux或者Windows上,只要你安装了Docker。
你可以通过运行被include的脚本,传递必须的参数,来部署SQL Server。脚本包括许多参数,最重要的一些参数已经有默认的值,来帮助不熟悉的用户。反复运行同样参数的脚本也是安全的,它会检查底层的资源是不是已经存在,如果已经存在,会复用它们。
以下是脚本运行的所有步骤:
1. 首先,它为Amazon EKS创建一个IAM服务角色。这个角色会允许AWS来创建必要的资源。
2. 你需要一个VPC来运行你的集群。脚本会接收一个AWS CloudFormation VPC Stack的名称作为一个参数。如果Stack已经存在,它就会复用这个Stack,否则,它就通过AWS提供的模板创建一个新的Stack。Stack包括VPC、子网和安全组,这些必须的内容来运行集群。
3. 你使用一个客户端工具kubectl来配置和与Kubernetes交互。脚本会下载AWS版本的Kubectl,并且安装到你的本地计算机。
4. 当你使用Kubectl来查询Amazon EKS,你正在使用的AWS PowerShell工具的身份信息也会被传递给Amazon EKS。这个任务是被另一个工具aws-iam-authenticator来完成的,这个工具也会被脚本下载并安装。
5. 它创建了一个新的EKS集群。这个EKS集群包括被管理的一组3个 Master节点,分布在3个AWS可用区域上。
6. 它配置Kubectl来连接到上面步骤创建的EKS集群上。
7. 它创建了新的EC2实例,并且配置它们加入到EKS集群和Worker nodes上。
8. 它创建了一个Etcd集群,让Portworx与之通信。
9. 它然后下载一个DaemonSet规格参数,并且应用到EKS集群上。这就自动安装了Portworx云原生存储 – 含有GP2和IO1 EBS卷,供用户选择其中一种或者全部。
10. 它为Portworx卷创建了一个存储类,其中EKS集群内的复制因子数值为3。这样你就可以在主机发生错误的时候,维持SQL Server集群的高可用。甚至Kubernetes可以把你的SQL Server Pod调度到另一个可用性区域。
11. 它在EKS集群内,为gp2 EBS卷创建了一个存储类。
12. 它在EKS集群内创建了一个新的Persistent Volume声明(PVC)。PVC允许Portworx来部署由Amazon EBS卷支持的持久卷(PV)。
13. 它提示你输入SQL Server SA用户的密码。输入符合SQL Server密码要求的强度较高的密码。脚本会把密码作为Secret保存到EKS集群里。
14. 然后它会创建SQL Server的部署。部署包括一个复制集,它会按顺序创建Kubernetes的Pods。Pod是由一个运行SQL Server的单独容器组成。PVC卷被Mount到了这个容器里。SA的密码也被使用。
15. 最后,它输出端点的名称,在连接字符串里使用来连接到SQL Server实例里。
运行脚本会部署EKS集群,以及一个单独的SQL Server实例。你也可以在同一个EKS集群上部署另一个SQL Server实例,只需要再次运行同一个脚本即可。然后为appName参数传递一个不同的名称。
脚本部署SQL Server使用Multi-AZ Kubernetes集群,和一个有Portworx卷支持的存储类(Storage Class)。由于Portworx在SQL Server容器里保护和复制数据,部署针对下列情况具备高可用:
- 容器错误
- Pod错误
- EC2实例错误
- EC2主机错误
- EBS磁盘错误
- EC2网络分区
- AWS有效性区域错误
如果一个容器或者Pod错误,Kubernetes会立即调度另一个容器或者Pod。甚至Kubernetes把Pod调度到了另一个可用性区域。你也不会有数据损失,因为Portworx自动的在可用性区域之间复制数据。
在前面的部分,我们注意到Portworx复制因子的数值被设定成了3。这意味着除了我们的主PV之外,Portworx会在集群上的其他地方一直保持两个额外的PV副本。因为Amazon EBS卷只在一个单独的可用性区域保持高可用性,默认情况下,Portworx把这些复制扩展到多个可用性区域里。相对于本地部署时:通常一个SQL Server错误恢复集群实例(FCI)是部署在同一个数据中心里的,很大的进步就是Kubernetes和Portworx集群是分布在多个可用性区域里的。因此,可用性更高。
在Portworx存储集群上的Kubernetes里运行SQL Server容器,类似在跨多个可用性区域的Storage Spaces Direct 集群(https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/storage-spaces-direct-overview)上运行SQL Server Always On FCI。这样Recovery Point Objective (RPO)是零,而且Recovery Time Objective (RTO,https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-container-ha-overview?view=sqlallproducts-allversions) 小于10分钟,这样可以应对可能出现的可用性区域的错误,达到极高的可用性。区别是在EKS里运行容器,比起在Windows Server容错恢复集群上配置和维护SQL Server要更加容易。
如果你运行SQL Server标准版,你也可以通过使用容器和Amazon EKS获得相比于传统Windows部署的更高的可用性。这是因为SQL Server标准版FCI只能授权最多两个节点的使用。(一个第二节点)。然而,容器可以被部署到含有任何数量节点的集群上。SQL Server Always On FCI的企业版可以超过两个节点。取决于你的软件授权协议,你可能要为每个额外的实例购买新的授权。这不是容器的使用方式。你可以只支付一个容器的费用,不论你在集群上有多少standby的实例。
也可以把SQL Server容器和Always On可用性组(SQL Server 2019 preview版本)一起部署。这样的配置类似部署Always On可用性组(每个节点自己就是一个Always On FCI集群)。这样,容器就会摆脱一些Always On可用性组和FCI的限制。例如,这些限制包括从一个可用性组的节点自动容错恢复到另一个节点,和为每一个节点设置FCI的复杂操作。
基于SQL Server 2017软件授权说明:“SQL Server 2017使用授权给虚拟机和容器,为客户的部署提供灵活性。有两种可选的给虚拟机和容器的授权方式,为每个虚拟机和容器授权,以及为高度虚拟化或高密度容器环境的最大密度授权(每物理主机授权)”。
有机会通过把SQL Server负载容器化来降低软件授权成本。你可以基于不同的实际场景,使用每容器授权的模式,或者使用每物理主机授权的模式(高密度),来降低软件授权的数量。
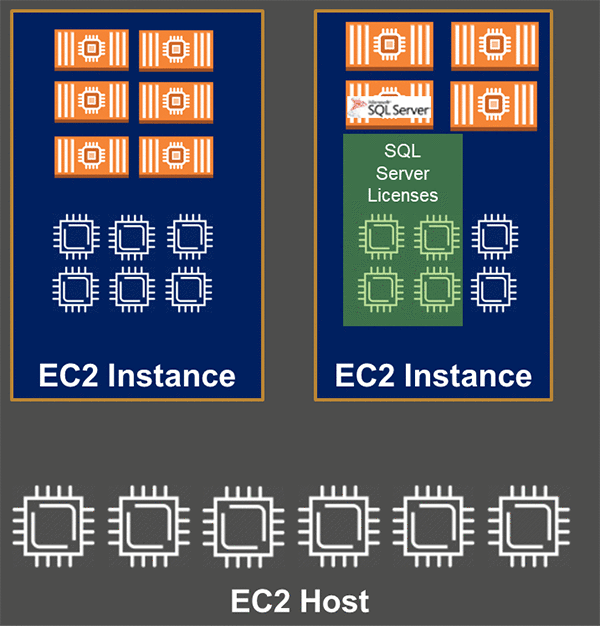
如果你有一些应用在EC2实例上运行,并且希望在同一个主机上运行应用的同时,也运行SQL Server,你可以使用每容器授权的模式。如果没有容器,是在虚拟机上直接运行SQL Server,包括EC2实例,你就需要为VM包括的所有vCPU购买授权,不论SQL Server到底使用了多少vCPU资源。然而,如果你是在VM之上的容器里运行SQL Server,你只需要为容器访问到的vCPU数量购买授权。你可以仅仅为能访问到的核数量购买授权,这样你最小的情况可以只够买4核的授权,或者6核,8核这样,视情况而定。
如果你的SQL Server实例存在突发峰值的使用情况,你可以在高密度环境的容器内运行它们。这种情况下,你可以选择每物理机授权的模式。只要所有的物理核资源得到了正确的授权,就会允许你运行物理核资源之上的不限数量的容器,以及不限数量的vCPU。
在上面的图里,有12个vCPU核和20个容器。但因为这些容器都运行在一个6核的物理机器上,只需要为这6个物理机的核授权。这对那些已经在本地物理环境里过度部署了SQL Server虚拟机的情况非常有用。EC2实例有一个固定的hyperthreading比例:2vCPU对应一个物理主机核。这样迁移过度部署的负载(3:1,4:1,5:1或者更高)到EC2实例里会带来更高的成本问题。容器化解决成本问题,相应也会带来更好的收益。
Portworx支持高密度容器环境的授权模式。Kubernetes本身推荐一个节点最多不要超过100个pod(https://kubernetes.io/docs/setup/cluster-large/)。这样理论上,你可以在每个EC2实例里运行不超过100个SQL Server Pods,这样可以大量节省SQL Server授权。Portworx针对每个EC2实例只需要一个授权,不论运行多少容器,或者消耗多少存储。这样对于集群,你并不是简单的用一个授权来换另外一个,实际上,每个主机运行的SQL Server数量越多,你的平均授权成本越低。Portworx支持每个集群数千节点,以及支持每个节点数百个有状态容器(https://portworx.com/architects-corner-aurea-beyond-limits-amazon-ebs-run-200-kubernetes-stateful-pods-per-host/)。
在现有版本的功能上,并不是所有的SQL Server都能够被容器化。目前仅仅只有SQL Server2017支持容器。2017之前的版本都不能支持容器。但SQL Server本身是兼容SQL Server 2008之后的版本的,这意味着你可以导入从SQL Server 2008(或之后版本)中创建的数据库到SQL Server2017实例里(包括在容器里运行的SQL Server 2017里),用兼容模式来运行即可。
虽然SQL Server on Linux支持与Microsoft Active Directory的集成,SQL Server容器目前不支持Active Directory集成。
SQL Server一个经常使用的功能是horizontal read-scaling,它在Always on可用性组里。这个功能对容器目前只是Preview版本,不能用在生产环境。
另一个云带来的可能的好处是License Included services模式。对于许多商业来说,管理已购买的授权和实际软件授权使用是非常复杂的工作。经常会不一致,导致客户要么为未使用的软件授权多花钱,要么合规地软件授权不足。SQL Server容器支持Bring Your Own License (BYOL)模式,因此在决策前好好考虑下授权的问题。
也有其他一些功能目前还不能使用,比如Distributed Transaction Coordinator (DTC)和custom CLR user types。如果你的SQL Server负载是一个比较静态平稳的资源消耗模式,也许传统的部署模式更加适用。
在本篇文章中,我们讨论了为什么要考虑在容器中使用SQL Server和Portworx,并且讨论了需要考虑的各个方面。
这样的方式有下面的好处:
- 简单,而且会帮助你降低一些管理的复杂度。
- 可以通过释放闲置的资源给需要的负载,来增加应用的性能。
- 可以增加数据保护,以及部署的容灾恢复。
- 可以减少基础架构的成本。
- 可以减少SQL Server软件授权的成本。
这篇文章演示了在Amazon EKS上与Portworx一起部署SQL Server是比较简单的。你可以部署基础架构和EKS集群,并且通过使用一个简单的脚本来调用AWS API,从而来运行SQL Server容器。基于你的情况,你可以使用两种存储方案:
- 使用单独的EBS卷作为一个PVC,在一个单一的高可用区域里提供高可用性,最少的存储成本。
- 使用一个集群化的存储解决方案Portworx来跨多个可用性区域,提供支持可用性区域错误恢复级别的高可用。