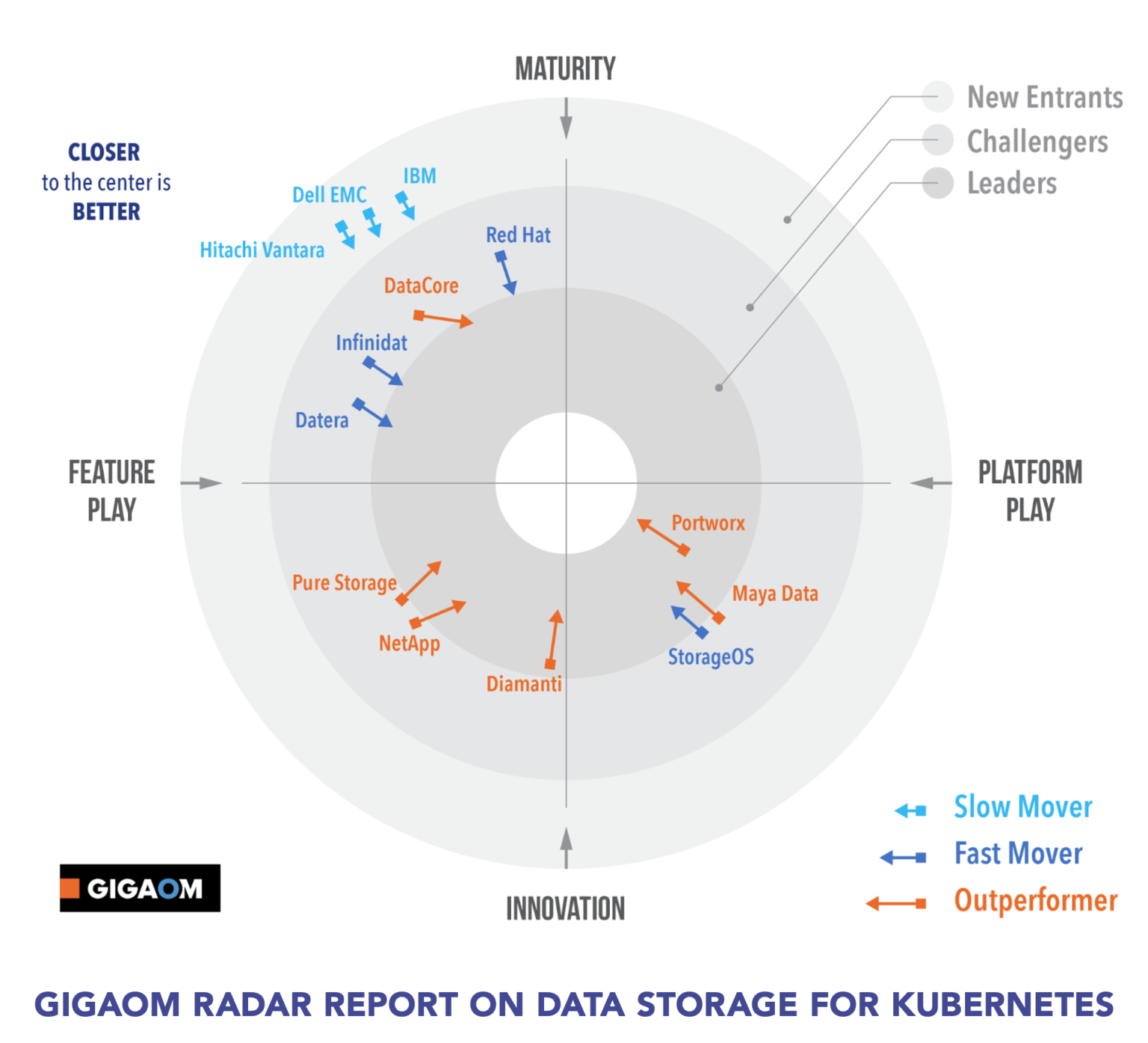
1、配置docker daemon
对于docker daemon,提供了两种配置方式:
- 使用daemon.json配置文件,这是首选的方式。
- 在使用dockerd启动时,通过flag设置。
当不能同时使用这两种方式进行相同选项的设置,否则会导致docker daemon无法启动。如果宿主机是linux,配置文件daemon.json的目录是/etc/docker/;

如果是宿主机是windows,配置文件daemon.json文件所在的目录是C:\ProgramData\docker\config\。

下面是配置文件的示例:
{
“debug”: true,
“hosts”: [“tcp://192.168.59.3:2376”]
}
通过此配置,Docker守护程序将以调试模式运行,通过2376端口侦听路由来自于192.168.59.3的流量。也可以通过手动启动Docker守护程序,并使用flag对其进行配置。下面是通过手动启动Docker守护程序进行配置的示例:
dockerd –debug –host tcp://192.168.59.3:2376
2、Docker daemon目录
Docker守护程序将所有的数据保存在宿主机的一个目录中,这些数据包括:容器,镜像,卷,服务定义和机密等。默认情况下,此目录为:
- Windows操作系统:/var/lib/docker
- Linux操作系统:C:\ProgramData\docker
对于docker daemon目录,可以使用data-root配置选项设置为使用其他目录 。由于Docker守护程序的状态保留在此目录中,因此需要确保守护程序使用的是专用目录。如果两个守护程序共享同一目录(例如,NFS共享),则将遇到难以解决的错误。
3、Docker daemon配置选项
3.1 Linux操作系统
在Linux操作上,docker守护进程配置文件的默认位置是/etc/docker/daemon.json。可以通过–config-file标志指定非默认位置。下面是Linux操作系统上允许的配置选项完整示例:
{
“authorization-plugins”: [],
“data-root”: “”, # docker的根目录 (默认值: “/var/lib/docker”)
“dns”: [],
“dns-opts”: [],
“dns-search”: [],
“exec-opts”: [],
“exec-root”: “”,
“experimental”: false,
“features”: {},
“storage-driver“: “”, # docker的使用的存储驱动,默认为bridge
“storage-opts”: [],
“labels”: [],
“live-restore”: true,
“log-driver“: “json-file”, # docker的日志驱动,此处的值为json-file
“log-opts”: { # docker的日志设置
“max-size”: “10m”, # docker的日志大小为10m
“max-file”:”5″, # 最大保留5个日志文件
“labels”: “somelabel”,
“env”: “os,customer”
},
“mtu”: 0,
“pidfile”: “”,
“cluster-store”: “”,
“cluster-store-opts”: {},
“cluster-advertise”: “”,
“max-concurrent-downloads”: 3,
“max-concurrent-uploads”: 5,
“default-shm-size”: “64M”,
“shutdown-timeout”: 15,
“debug”: true,
“hosts”: [],
“log-level”: “”, # 设置日志层次 (“debug”|”info”|”warn”|”error”|”fatal”) (默认值为: “info”)
“tls”: true,
“tlsverify”: true,
“tlscacert”: “”,
“tlscert”: “”,
“tlskey”: “”,
“swarm-default-advertise-addr”: “”,
“api-cors-header”: “”,
“selinux-enabled”: false,
“userns-remap”: “”,
“group”: “”,
“cgroup-parent”: “”,
“default-ulimits”: {
“nofile”: {
“Name”: “nofile”,
“Hard”: 64000,
“Soft”: 64000
}
},
“init”: false,
“init-path”: “/usr/libexec/docker-init”,
“ipv6”: false, # 是否启用ipv6网络
“iptables”: false, # 是否启用iptables规则,默认值为true
“ip-forward”: false,
“ip-masq”: false,
“userland-proxy”: false,
“userland-proxy-path”: “/usr/libexec/docker-proxy”,
“ip”: “0.0.0.0”,
“bridge”: “”,
“bip”: “”,
“fixed-cidr”: “”,
“fixed-cidr-v6”: “”,
“default-gateway”: “”,
“default-gateway-v6”: “”,
“icc”: false,
“raw-logs”: false,
“allow-nondistributable-artifacts”: [],
“registry-mirrors”: [], # 镜像仓库的镜像地址
“seccomp-profile”: “”,
“insecure-registries”: [], # 安全镜像仓库列表
“no-new-privileges”: false,
“default-runtime”: “runc”, # docker的默认运行时环境
“oom-score-adjust”: -500,
“node-generic-resources”: [“NVIDIA-GPU=UUID1”, “NVIDIA-GPU=UUID2”],
“runtimes”: {
“cc-runtime”: {
“path”: “/usr/bin/cc-runtime”
},
“custom”: {
“path”: “/usr/local/bin/my-runc-replacement”,
“runtimeArgs”: [
“–debug”
]
}
},
“default-address-pools”:[
{“base”:”172.80.0.0/16″,”size”:24},
{“base”:”172.90.0.0/16″,”size”:24}
]
}
在编辑daemon.json后,需要通过执行下面的命令对docker进行重启。
$ systemctl reload-daemon
$ systemctl restart docker
3.2 Windows操作
Windows上docker守护进程配置文件的默认位置是%programdata%\docker\config\daemon.json。可以通过–config-file标志指定非默认位置。Windows上允许的配置选项完整示例:
{
“authorization-plugins”: [],
“data-root”: “”,
“dns”: [],
“dns-opts”: [],
“dns-search”: [],
“exec-opts”: [],
“experimental”: false,
“features”:{},
“storage-driver”: “”,
“storage-opts”: [],
“labels”: [],
“log-driver”: “”,
“mtu”: 0,
“pidfile”: “”,
“cluster-store”: “”,
“cluster-advertise”: “”,
“max-concurrent-downloads”: 3,
“max-concurrent-uploads”: 5,
“shutdown-timeout”: 15,
“debug”: true,
“hosts”: [],
“log-level”: “”,
“tlsverify”: true,
“tlscacert”: “”,
“tlscert”: “”,
“tlskey”: “”,
“swarm-default-advertise-addr”: “”,
“group”: “”,
“default-ulimits”: {},
“bridge”: “”,
“fixed-cidr”: “”,
“raw-logs”: false,
“allow-nondistributable-artifacts”: [],
“registry-mirrors”: [],
“insecure-registries”: []
}
在编辑daemon.json后,需要通过执行下面的命令对docker进行重启。
$Restart-Service docker
参考:
1)Windows 上的 Docker 引擎:https://docs.microsoft.com/zh-cn/virtualization/windowscontainers/manage-docker/configure-docker-daemon
2)dockerd:https://docs.docker.com/engine/reference/commandline/dockerd/
作者简介:
季向远,北京神舟航天软件技术有限公司。本文版权归原作者所有。微博:ik8s