

Portworx技术视频系列:通过PX-AutoPilot自动扩展存储池容量
https://v.qq.com/x/page/w3102db86te.html
欢迎来到Portworx技术系列视频,我是Ryan Wallner。今天我们来介绍一下存储容量管理。Portworx Autopilot,我们会专门介绍一下存储池扩充、容量管理,这样可以让用户基于一些提前设定的规则引擎,自动的添加磁盘。Portwortx Autopilot可以自动化的管理容量,自动化的运维,例如添加磁盘,扩充PVCs,或者在存储池里扩充磁盘。这些操作可以通过脚本自动执行,也可以手动方式,但都是以K8S云原生的方式来进行的,定义YAML文件,给予Portworx权限来做这些事情。
当你完成了Portworx的配置,为每个节点配置了每个100G的磁盘,假如是云中,我们使用EBS,这样我们就为PVCs设定了一个Portworx存储池,总共300G。应用会使用PVCs,后续可能有更多的应用,数据库,服务会运行在K8S上,当它们开始使用存储容量的时候,假设它们使用了150G的空间。这是所有存储容量的一半。我们如何来管理这些容量?如何触发动作呢?我们来看一下Autopilot是怎么做的。
当你安装了Portworx,开始使用Autopilot,你会需要Prometheus,Prometheus的作用,是收集K8S里应用运行情况的信息,Portworx自身也使用Prometheus,方式是Portworx提供API,含有Prometheus端点,这个端点,会向Prometheus提供运行情况的信息,Prometheus就可以看到比如卷的数量、总体容量、已经使用了多少,CPU、内存这些。
AutoPilot,我们用AP来表示,会接入Prometheus,并且获取状况信息,这样AutoPilot根据状况信息,和事先制定的规则,对Portworx的运行进行自动化管理,现在我们对管理控制的流程有了概要性的了解,以及Autopilot的工作原理,我们需要创建一些规则,用Prometheus能够理解的表达,同时Autopolit可以去执行,假设,已经使用的字节,和总共的字节数,表明了我们还有多少容量可以使用。我们设定一个规则:如果我们剩下的容量已经不到40%了,也就是我已经使用了60%的容量,就会触发动作,来扩充我们的集群。
扩充的方式是增加磁盘。我们可以制定一些规则增加额度的限制,例如,每次当使用到60%容量时,这种情况可能会经常发生,我们可以设定,触发增加50%容量的动作,就是总体容量增加50%。也可以增加一些限制,例如,每个存储池的上限不要超过2TB,这是考虑你有成本限制的情况。这就是通过Autopilot来设定一些自动化的规则,以及设定限制。
还有其他配置方式,主要的配置方式就是规则、动作、和方式,当存储池增长到了60%,Prometheus会探测到,Autopilot就会触发规则,来进行相应的动作,这里动作就是增加存储池容量,增加磁盘会增加存储池容量50%,达到450G。这样我们的容量使用率就不再是60%了,Portworx增加总容量后,它就会低于60%,这个规则仍然是有效的,因为后续可能会进一步需要存储容量。
这里我们演示了,Autopilot如何通过规则和动作,自动化的控制下层的存储,如AWS, Azure,Vmware Vsphere,部署磁盘,加到存储池里面,确保一切都可以自动化的有序进行。这里我们介绍了增加磁盘的类型,直观的可以看到通过Portworx增加了存储池的容量,为PVCs服务。后续我们还会介绍其他类型,比如当磁盘达到使用率的阈值的时候,增加单个磁盘的容量,而不是增加新磁盘,以及介绍PVCs。上面我们介绍了Autopilot,自动增加磁盘容量,以及存储池容量,希望对您有用,谢谢!








Golang开发者非常关心开发应用的安全性。随着Go Module应用越来越广泛,Golang开发者需要更多的方式来确保这些公共共享文件的安全。Golang1.13版本在创建Go Module时,通过增加go.sum文件来验证之后从GOPROXY再次访问到的该Module是否曾被篡改。这个机制有助于保证Module的完整性。但是,当初次创建并提交Go Module时,如果原始文件中被引入了恶意代码,这种安全漏洞还是不能被发现和预警的。
Go Module的安全漏洞影响了很多项目和Go开发者。随着CI/CD流程中“左移”实践的推广,对于Go开发者来说,尽早跟踪和报告Go Module之中的安全漏洞变得越来越重要。幸运的是,GoCenter(https://search.gocenter.io)作为Golang的中央仓库,为Go开发者提供大量公共共享Go Module的同时,也通过集成JFrog Xray安全扫描的能力,帮助Go开发者检测、跟踪并报告仓库中Go Module包含的安全漏洞。
任何应用系统,在其开发的生命周期中,都应该持续监视安全漏洞,任何人发现了安全漏洞都应及时报告,以便其修复措施能够被更多的组织和开发者分享与跟踪。已知安全漏洞通常利用CVE(Common Vulnerability and Exposures, 常见漏洞及披露)来分类和跟踪,这是一个用于公开披露安全漏洞信息的列表。每个CVE信息包含一个标准标识序号(CVE ID)、一个状态指示器、对该漏洞的简短描述,以及与漏洞报告及建议相关的索引。
CVE不是漏洞数据库。相反,CVE旨在允许漏洞数据库和其他工具链接在一起,并促进安全工具和服务之间的比较。美国国家漏洞数据库(NVD,National Vulnerability Database)是一个免费的、公开的漏洞数据库,它使用CVE列表的标识序号,并包含漏洞的修复程序、漏洞级别评分,以及其他和每个漏洞相关的信息。
每一个被检测到的安全漏洞都必须报告给CVE编号颁发机构(CNA,CVE Numbering
Authorities),并附上详细的文档解释该漏洞的影响,以及至少一个受影响的代码库,然后才能将其识别为已知漏洞并分配一个CVE ID。作为参考,CVE ID的格式通常为:CVE前缀 + 年 + 任意数字。以下是CVE ID的示例:

确保Go Mudule的安全可能是一项棘手的任务,特别是由于Go Module和Go Package之间的关系。一旦收到Go Module的安全数据,就很难将该数据与特定的Module版本相关联。这是因为安全漏洞存在于Package级别,但是却报告在Module级别上。这可能会给人留下整个Module都容易受到攻击的印象。但事实并非如此,除非您使用易受攻击的Package数据,否则Module将保持安全。
让我们以上图中的CVE-2020-10660 为例。以下是1.3.4版变更日志的摘录,详细介绍了此漏洞的影响:
gopkg.in/hashicorp/vault.v0和github.com/hashicorp/vault都受到了HashiCorp Vault和Vault Enterprise0.9.0到1.3.3版本中的CVE-2020-10660的影响。在使用这些Package时,在某些情况下,它们可能使实体的组成员无意间包含了该实体不再具有权限的组。Vault Enterprise中发现的另一个漏洞是,在某些情况下,现有的嵌套路径策略可能会提供对事后创建的命名空间的访问权限。幸运的是,在版本1.3.4中对这些漏洞进行了修复。

如上例所示,修复是在github.com/hashicorp/vault内进行的。Module
istio.io/istio在其go.mod文件里记录了对github.com/hashicorp/vault的依赖。通常,您会认为istio.io/istio的安全性也会受到威胁。但是它仅仅使用了package github.com/hasicorp/vault/api,因此其代码是不受此漏洞的影响的。请参考下面的源代码:

现在您已经了解了如何报告Go
Module安全漏洞的过程,以及有关安全数据复杂性的一些详细信息,让我们看看如何在将来的开发中减少这些威胁。
首先,让我们看一下GoCenter中的Go Module:github/hashicorp/vault。
根据CVE数据,JFrog Xray能够扫描一个go.mod文件里包含的所有在GoCenter中保存的依赖,并识别其中包含的每个安全漏洞。GoCenter在“依赖关系”选项卡上显示这些Xray数据,并提供依赖关系树上各个级别里易受攻击Module的详细信息。您会在每个易受攻击的Module旁边看到一个警示的三角形。然后,您可以单击这些易受攻击的Module并跳转到安全页面。在这里,查看“版本”选项卡可以查找该模块的安全版本,以便您可以在go.mod文件中对其进行升级。
一旦确定了所有组件和依赖项,它们的信息就会与其他漏洞源和数据库进行交叉引用,以提醒您任何潜在的威胁。GoCenter上提供了免费的针对Go Module的基本Xray漏洞扫描,如“安全性”选项卡所示:

GoCenter是公共GOPROXY和中央仓库,具有70万+的Go Module版本。将GoCenter用作GOPROXY时,可以确保下载的代码版本是来自正确源代码的正确版本。GoCenter作为您的GOPROXY可与Go命令无缝协作,并具有安全、快速、可用和存储高效的优势。
许多Golang开发者还可以使用VS Code的免费JFrog扩展,将GoCenter的漏洞信息直接引入其IDE中。
随着CI/CD流程中“左移”实践的推广与落地,GoCenter的安全功能可以帮助您确定要导⼊的公共Go Module版本中是否存在易受攻击的依赖项,进而帮助您保持开发应用的安全性。
更多技术分享可以关注我们在新课堂
关注微信公众号:JFrog杰蛙DevOps,获取课程通知
随着 Go 语言的深入使用,其依赖管理机制也一直是各位 Gopher 热衷于探讨的话题。Go 语言的源码依赖可通过 go get 命令来获取,但自动化程度不高,于是官方提供了 Dep 这样的自动化批量管理依赖的工具。虽然 Go 语言的依赖管理在很多方面还是不如人意,但整个体系正在日趋完善,本篇就将从最基本的依赖管理场景出发,一同探讨 Go 语言依赖管理的一些最佳实践。
在 Go 语言中,我们通过 go get 命令将 GitHub 或者 Google Code 上的代码下载到本地指定目录,然后在开发代码中通过 import 的形式引用本地的代码。
Go 语言可以通过直接分析代码中的 import 语句来查询依赖关系。go get 命令在执行时,就会自动解析 import 来安装所有的依赖。那么下载的依赖在本地是如何存储的呢?
这里就涉及到 Go 语言的 WORKSPACE 概念,简单来说就是通过 GOPATH 环境变量来设置 Go 代码的位置。一般来说,GOPATH 目录下会包含 pkg、src 和 bin 三个子目录,这三个目录各有用处。
bin 目录用来放置编译好的可执行文件,为了使得这里的可执行文件可以方便的运行,在 shell 中设置PATH变量。
src 目录用来放置代码源文件,在进行 import 时,是使用这个位置作为根目录的。自己编写的代码也应该放在这下面,不同的项目放在不同的目录下进行管理。
pkg 用来放置安装的包的链接对象(Object)的。这个概念有点类似于链接库,Go 会将编译出的可连接库放在这里,方便编译时链接。不同的系统和处理器架构的对象会在 pkg 存放在不同的文件夹中。
当项目在 src 目录下管理时,多个项目可能都会使用相同的依赖,如果每个项目都存一份依赖显然会带来大量的冗余,这里我们推荐一个设置 GOPATH 环境变量时的小技巧。
这样第三方包就会默认放置在第一个路径中,而你可以在第二个路径下编写自己的代码,多个项目共享一份依赖。
dep 是 Go 语言官方提供的依赖管理工具,跟其他依赖管理工具类似,都是通过一个文件描述依赖的坐标信息,然后批量管理(下载、升级等)依赖包(源码)。dep 是一个开源项目, 大家可以在 https://github.com/golang/dep 了解详细信息,其安装方式大家可以参考官方说明,这里我们主要介绍其使用。
通过 dep init 命令来初始化,会创建Gopkg.lock,Gopkg.toml文件和一个空的vendor目录。
我们在代码中通过 import 命令添加依赖后,通过 dep ensure 就可以下载依赖到本地 $GOPATH/src 目录下。
main.go
Gopkg.lock
通过 dep status 我们可以查看当前依赖引用的情况
另外有一个 dep check 命令来检查是否存在依赖被引用,但是代码中并没有使用的情况,Go 语言对于依赖的引用比较严格,不允许引用了但是没使用的情况。从软件安全的角度考虑,这是一个很好的实践,避免引入一些安全风险。
当然,这种时候我们就需要移除本地依赖,最好不要手动删除vendor中的内容,而是通过 dep ensure -update 命令来移除。
从 dep 的目录结构,我们可以分析出 dep 的基本工作思路:
这里面有两个关键的步骤:
解析依赖
从当前项目的 import 文件中解析出整个工程的依赖情况,并结合 Gopkg.toml 定义的规则,然后将依赖关系输出给 Gopkg.lock,注意这个 lock 文件最好不要手动修改。
获取依赖
通过 Gopkg.lock 了解整个依赖关系之后,将依赖的具体内容拉取下来放到 vendor 目录中,然后执行 Go build 时从本地的 vendor 读取依赖并完成构建。
这一些都是在 dep ensure 时完成的,其实在执行这个命令时还可以传参数,最主要的是 -no-vendor 和 -vendor-only 这两个参数。
-no-vendor 参数只会导致运行 resolve 函数,结果是创建一个新的Gopkg.lock 文件,不会更新 vendor;而 -vendor-only 参数将跳过 resolve 并仅运行 vendoring 函数,导致 vendor/ 从已存在的Gopkg.lock 重新更新。
关于 dep 更多深入内容,可以参考
https://golang.github.io/dep/docs/introduction.html
Go dep 目前是一款比较好用的依赖管理工具,很多比较大型的项目都在使用,从中可以学习到依赖管理的一些基本思路,对于理解其他语言,比如 NPM 的依赖管理模型也是比较有好处的。
更多精彩内容可以专注我们的在线课堂
微信搜索公众号:jfrogchina 获取课程通知

近日,中国通信标准化协会云计算标准和开源推进委员会(已下简称信通院)主办《OSCAR 开源先锋日——云原生专场》,由云原生开源产业联盟、CNCF基金会联合选出的2020年度云原生应用十大优秀案例重磅发布。谐云为中移在线服务有限公司(以下简称中移在线)搭建的容器云PaaS平台项目在众多头部企业实践案例的激烈角逐中脱颖而出,成功入选云原生十大优秀案例,并成为全球最大的客服专有云案例。
近几年,中国本土的云原生力量已得到长足发展,生态体系逐步完善,本土引领的云原生开源项目开始反哺国际社区。云原生应用范围也逐步由互联网向传统行业拓展,帮助传统企业构建“好用的架构”和“适用于云的应用”。云原生应用十大优秀案例的评选,旨在推广云原生应用在行业成功落地的实践经验,树立行业先锋典范。同时本次活动征集的十大优秀案例将入选首版中国云原生生态图景(landscape)。中移在线容器化PaaS项目以高资源弹性伸缩、高持续交付效率、大规模集群&容器实例、跨中心容器、技术/应用服务等创新等高效应用价值博得了评委的一致好评与认可。
入选理由
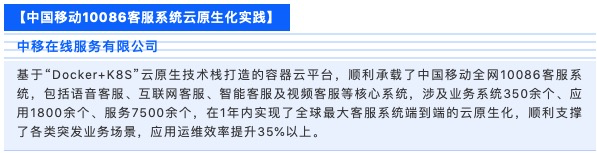
中移在线容器云PaaS 平台的创新价值主要体现在三个方面:
第一, 搭建了全球最大的客服专有云。实现了自主研发容器云在客服多场景中大规模应用,打造了开源自主、国产可控、技术领先的客服专有容器云,为其提供10亿级用户支撑能力。
第二, 降低IT 资源运行和集成成本,打造了高性能高效率高可靠环境。利用容器化带来的虚拟化能力替代原有虚拟机的资源隔离方式,节约大量的许可成本,实现资源层面的降本增效,并通过混合部署,结合业务负载自动弹性扩缩容,资源利用率提升至业内领先水平。
第三,建设容器化云服务环境,从整体提高开发、运维、管理的收益。利用容器云的标准化帮助开发效率提升70%,管理定责效率提升90%以上,同时通过建设高可靠高性能集群,为中间件容器化提供切实有效的运行基础,结合Operator组件,在中移在线生产环境实现了企业级的容器化中间件自助服务能力。
中移在线容器云PaaS 平台的落地,具有明显的示范意义。目前,谐云为中移在线容器云PaaS平台搭建已经到了第三期,实现了全量业务的容器化改造迁移和全面的技术升级。谐云作为中国数字基础设施建设云原生软件的领军企业,独自凭借着强大的底层核心技术实力和专业的服务交付能力,在大型企业中获得了广泛、成功的实践,为企业奠定了坚实的技术基石。
接下来,谐云也将一同继续参与信通院在云原生白皮书撰写等方面的工作,为云原生技术的应用落地和加速创新做出贡献!
Content
Garlic can prolong bleeding time and ideally should not be consumed within 7-10 days of a surgery. One of only 20% of healthcare centers in the world to earn CARF. Looking to help someone with their alcohol addiction, we have provided some more information for those seeking guidance. If you or a loved one is struggling with alcohol abuse, please call our helpline today. It was concluded that caffeine has the capacity to inhibit the metabolism of warfarin and enhance its plasma concentration and hence anticoagulant effects. Thus, patients should be advised to limit the frequent use of caffeine-rich products i.e. tea and coffee during warfarin therapy. The easiest way to lookup drug information, identify pills, check interactions and set up your own personal medication records.
If your brain starts to bleed and your blood has been thinned by too much alcohol, it may not be able to clot before you lose too much blood and hemorrhage. Moderate drinking may be able to lower the risk of clotting but it only does so for a short period of time. Because alcohol can thin your blood, you are discouraged from drinking it before medical surgery. Drinking alcohol within 24 hours of surgery can cause you to bleed more throughout the procedure. In other cases, blood can be difficult to manage, which can obscure what the surgeon is trying to do, leading to complications. Drinking alcohol allows it you enter your bloodstream through your digestive system. Once it enters your blood, it’s filtered by your liver before it’s able to enter your brain.
If you need surgery, it’s important to speak with both your surgical team and the clinician who prescribes your blood thinner before surgery. Many surgeries require patients to come off of their blood thinner before the surgery, so it’s important to discuss how to safely stop and restart your blood thinner.
Your healthcare provider also prescribes you the correct dosage for you depending on a number of factors. The effects of alcohol may be similar to blood thinners, but you should not replace your medication with alcohol.
The liver produces this protein, which plays an important role in controlling blood flow and promoting blood clotting. Okay, but can you switch medications to make it safer to imbibe? Blood thinner medications prevent blood from sticking together which increases the amount of time it …
How to Work with Your Doctor to Prevent Heart Disease.
Posted: Wed, 15 Feb 2023 17:01:13 GMT [source]
blood thinners and alcohol is mostly broken down in the liver, which serves to filter out toxins from the blood. Alcohol can stimulate the liver to then increase production of HDL (high-density lipoprotein cholesterol), which can then work to break down LDL (low-density lipoprotein cholesterol).
The platelets make your blood clot, so bleeding stops when you suffer an injury. The platelets in Lily’s body immediately get to work clotting the blood to stop the bleeding. After a couple of minutes, Lily’s hand still hurts, but at least the bleeding has stopped.
https://v.qq.com/x/page/q0976bknoii.html
欢迎回到Portworx系列讲解视频。我是Ryan Wallner。今天我们来介绍如何配置Portworx存储集群。这里我们概要性的对Kubernetes和Portworx的结构进行介绍,如何在Kubernetes上配置Portworx集群,以及正确安装Portworx需要哪些命令和参数。这里我们有一组已经配置好的高可用的Kubernetesmaster节点,一组worker节点,在这些节点上我们来安装Portworx。
Portworx需要一些资源的支撑。每一个worker节点都需要有CPU,不论是本地裸金属,还是云端,至少需要4个核以上的CPU。根据工作负载的不同,也许会需要更多核的CPU,例如运行一组数据库,4个核就不够了。最少的情况下我们需要4个核。内存建议至少4G。
跟CPU的核数一样,内存越大计算能力越强。可以根据自身的成本预算和负载的内存需求情况,来配置合适的资源供Kubernetes使用。但是运行Portworx,就需要满足4核CPU和4G内存的最小要求。因为Portworx是一个持久存储和数据管理系统,因此需要磁盘和驱动做支撑。
磁盘需要至少8G,我们推荐128G。4个节点的话,8G显得有点少。如果每个节点有128G,就能够有一个不错容量的存储池,来支撑存储系统。目前来看,还很少有为节点配置1TB以上。还要看运行的应用和需要的情况来定。网络方面,我们推荐10G的内部网络互联。
存在一个管理网络和一个数据网络。你可以把数据aka的复制、和应用的存储IO分配到不同的网络上。一个数据网络会存在,我们标记为D,还会存在一个管理网络,我们标记为M。因此管理网络和数据网络都可以通过网络进行连接。这些使你可以把I/O和数据流量进行分配。我们接下来介绍一下如何配置,需要确保数据网络至少是10G互联的。管理网络可以稍微低一些。Portworx的端口,需要9001到9021,这个范围可以配置的,这是默认的配置范围。除非有其他的端口冲突,就不要改变这些端口范围,它们是默认的Portworx通讯的端口。
对于Kernel版本,你至少需要3.10为Linux操作系统的版本,因为我们使用了很多更新的Linux Kernel集成、工作流和数据流等功能。键值存储数据库,etcd是最常见的,以及HashiCorp的Consul也可以选用。是的,Kubernetes集群在Master节点上运行etcd,注意键值数据库完全是分开的。
我在这里标记一下etcd,它通过网络会被附加到Portworx上,并且是独立的。它保存集群信息,元数据这些。对于一些有一定规模的集群,比如20或者25个节点的Portworx,我们推荐外部数据库,键值存储数据库,因为它会把I/O和CPU的资源放在外部系统上以及保持它们在独立的错误域里。
好的方法是保持一个独立的错误域,并且在配置过程中保持存有备份和快照,这样出现问题的时候可以恢复etcd数据库。对Kubernetes etcd数据库也可以这样操作。我们来介绍这两种方式。一种方式是有一个build-in的键值存储,这意味着Portworx可以自动工作,不需要人工干预,可以自动进行快照,也可以备份和恢复,但这是在20~25个Portworx节点的情况。现在对于Portworx所需资源有了一个整体了解,我们在介绍如何来配置它。我首先需要来介绍一下-C option,我来展示一个例子,来看在Kubernetes部署中是什么样的,或者Portworx运行中的DaemonSet。这样从命令行和EMO的角度我们就能更好的理解。
-C是我们的集群名称,你可以有其他的命名,但是不要有重复。因为如果用同样的名字,在应用分布和在etcd中配置的过程中,可能会出现冲突。所以确保集群名称是不重复的,这非常重要。我们接下来介绍存储,我们数据存储的选项。这里有一些,我们来看一下,你至少需要配置一项来定义你的存储磁盘或者后端存储,可以是本地的8G或者128G的磁盘驱动器,或者是云端存储驱动,例如SAN附加存储。不论是什么情况,-S都需要被使用,来指向一个特定的磁盘驱动:dev/sdb。你可以列出它们的名称,或者通过一个卷模板来使用。现在我来连接到卷模板,这是在云中来使用的,我想要使用gb2,有200G的卷,这会被认为是一个模板。Portworx会自动的与云的API进行沟通、部署、并且附加到Portworx worker节点上。
-Z是一个零存储节点。使用的情况是,如果你想要Portworx节点来加入到Portworx集群,也就是说着它需要附加\mount卷、并且允许应用具备I/O和使用卷。但是它不会给存储集群贡献更多的存储,也就是说它也不需要有磁盘。所以这就是-Z,零存储节点。-A,可以提供我们需要的所有功能。如果Portworx需要查询来看到底有多少没有被mount的未被使用的磁盘驱动。你可以增加-F,表示可以强制使用任何有文件系统的磁盘驱动。
这些是典型的操作中使用的参数。我们再来介绍一下数据网络和管理网络。配置时为数据网络使用-D,为管理网络使用-M。eth0,eth1这些。另外还有一个比较重要的就是 -X,这是你的调度器。“请告诉我的Kubernetes调度器来做更多的工作”。
我们介绍了STORK,有一个单独的视频介绍STORK,它是Kubernetes的存储调度器,与Kubernetes的调度器紧密集成。键值存储,会是IP和端口。通常运行在2379端口。也许是负载均衡器的IP地址,或者是etcd数据库的虚拟IP地址。如果你不想要使用外部数据库,你就不能使用 -b。-b表示使用内部的etcd数据库,或者是键值存储数据库。Portworx会自动的用高可用方式部署键值。高可用键值存储在至少3个节点上,并且配置压缩存储。如果低于20/25个节点,你可能就想使用-b,因为不论你是否想保持对etcd集群的感知,或者对集群本身的感知,可以留给Portworx来自动完成。
还有一些其他的部分,如果你想要使用-b,你需要配置一个元数据标志,表示这些是专门为键值存储数据库发送元数据I/O使用的驱动,所以它与数据I/O是分开的磁盘。还有就是缓存设备,它允许你在这些节点上选择最快的驱动。如果这些Portworx节点中的某一个使用GB2卷,在服务器上有一个NVMe或者一个io1类型的磁盘,就会比普通的驱动要快很多。
你可以使用它作为缓存设备,被Portworx作为缓存来使用。总结一下这些重要的标签。- C是集群名称。-A可用来获取磁盘。-Z代表零存储节点。S代表确定的存储,意味着磁盘模板或者存储设备本身。-D表示数据网络。-M表示管理网络。-X代表调度器或者Swarm,或者Kubernetes。-K代表外部键值存储。-b代表内部键值存储数据库、缓存设备、或者配置缓存设备/缓存元数据,供内部键值存储使用。
另外还有一些,我在这里就不再详细叙述,我们有spec生成器,你可以通过central.portworx.com来访问。你使用spec生成器的时候,它会用图形界面指导你来选择使用这些参数。以上我们介绍了在配置Portworx存储集群中需要考虑的一些方面,希望对您有帮助。谢谢!
Content

To make matters more confusing, my wife’s pension contribution hit the $58k limit for 2021 on this last paycheck in December. When that happened, the employer automatically stopped the contributions to that account and contributed the excess to a 415, which I had no idea existed. The IRS also said the amount of employee compensation that can be considered in calculating pension benefits and contributions to defined contribution plans will rise to $260,000 from $255,000.
While it feels like all of these are increases, they are really just keeping up with inflation (even though 2023’s increases are about twice as much as the increases from the previous year). On a real (after-inflation) basis, they’re basically the same as this year. Details on all the limits are available on the IRS web page by clicking here.
The additional catch-up contribution limit for individuals aged 50 and over is not subject to an annual cost-of-living adjustment and remains $1,000. In October, the Internal Revenue Service announced changes to various retirement plan benefits and employment tax limits for 2023. Not all limitations set forth by the IRS will be changed, as they are not subject to annual adjustments. However, those that will change are all tied to a cost of living index adjustment.
2023 TSP Contribution Limit Increasing Over 9%.
Posted: Sat, 22 Oct 2022 07:00:00 GMT [source]
The Roth IRA contribution limits for 2022 were $6,000 or your taxable income, whichever was lower. If you were 50 or older by the end of 2022, the contribution limit was $7,000. The annual contribution limit for a traditional IRA in 2022 were $6,000 or your taxable income, whichever was lower. If you were 50 or older by the end of 2022, you can contribute up to $7,000 total. The “catch-up” deferral limit for these plans also remains unchanged, at $5,500, so a person who is age 50 or older can defer a maximum of $23,000 in 2014.
The annual limit on the amount of a participant’s total compensation that can be taken into account under a qualified plan will increase from $255,000 to $260,000. The Code provides that the $1,000,000,000 threshold used to determine whether a multiemployer plan is a systemically important plan under Section 432 is adjusted using the cost-of-living adjustment provided under Section 432. After taking the applicable rounding rule into account, the threshold used to determine whether a multiemployer plan is a systemically important plan under Section 432 remains unchanged for 2017 at $1,012,000,000. For an IRA contributor who is not covered by a workplace retirement plan and is married to someone who is covered, the deduction is phased out if the couple’s income is between $186,000 and $196,000, up from $184,000 and $194,000.
I thought Irs Announces 2014 Retirement Plan Contribution Limits For 401 contributions went up from $5k to 6k fairly recently though. My understanding is the 415 limit of $58K for 2021 and presumably $61K for 2022 does NOT include the catch-up contribution. I will admit though that this has never been made very clear by the IRS or Congress as near as I can tell. I’d love to see a definitive resource on this question.
Also under the look-back rule, an individual will be treated as an HCE for 2014 if his or her compensation for 2013 exceeded $115,000. If the employer elects to apply the “top-20%” rule for determining HCEs, some individuals with compensation above these limits may not be considered HCEs. The annual compensation limit under Sections 401, 404, 408, and 408 increased from $260,000 to $265,000.
3Total contributions from all sources may not exceed 100% of a participant’s compensation. I’m hoping someone can help me out with an issue I think my wife may have in regards to the $58k limit on 401 and 403 accounts. A Roth IRA conversion results in taxation of any untaxed amounts in the traditional IRA and requires a five-year holding period before earnings can be withdrawn tax-free; subsequent conversions will require their own five-year holding period. In addition, earnings distributions prior to age 59½ are subject to an early-withdrawal penalty. ” You certainly can use your HSA funds while enrolled in Medicare. In fact, you can use them to pay Medicare premiums.
If you’ve exceeded contribution limits, the IRS charges a 6% tax each year on the excess contributions in your account, unless you fix the situation. If you realize your error before you file your tax return, you may withdraw the excess contributions—including earnings—ahead of the tax filing deadline to avoid the 6% tax. • Contribution limits don’t apply to rollover contributions. If you roll another retirement plan—such as a 401 from a previous employer— into your IRA, the rollover doesn’t count toward the annual contribution limit.
Contributing to an individual retirement account is a great way to boost your retirement savings and benefit from tax-sheltered investment growth. Depending on your income and other factors, you might even get a tax deduction. For assistance or questions related to applying the 2014 benefit plan limitations, or any other retirement plan issues, please contact your local CBIZ office. Simple IRAs.The contribution limit for a Simple IRA remains at $12,000 for 2014; the catch-up contribution for a person age 50 or older remains at $2,500, for a total of $14,500. The Social Security Administration also announced a 1.7% cost-of-living adjustment for 2015 regarding monthly Social Security and Supplemental Security Income benefits.
Individuals age 55 and older who are covered by an HDHP can make additional “catch-up” contributions each year until they enroll in Medicare. By statute, the catch-up contribution limit for individuals who will attain age 55 or older in the 2014 taxable year will remain at $1,000. The AGI phase-out range for taxpayers making contributions to a Roth IRA is $181,000 to $191,000 for married couples filing jointly, up from $178,000 to $188,000 in 2013. For singles and heads of household, the income phase-out range is $114,000 to $129,000, up from $112,000 to $127,000.
从Go 1.13开始,Go Module作为Golang中的标准包管理器,在安装时自动启用,并附带一个默认的GOPROXY。
但是对于其他的GOPROXY选项,比如JFrog
GoCenter,以及你自己的Go Module包,你需要在公众视野中保持安全,你应该选择什么样的配置? 你怎样才能不让你的公共和私人资源成为一个纠缠的结?
先让我们来看看GOPROXY是干什么的,以及如何为一个快速、可靠和安全的系统设置一个GOPROXY。
GOPROXY控制Go Module下载的来源,有助于确保构建的确定性和安全性。(传送门:大家可以在JFrog公众号里搜索 Go Module, 前文介绍里Go Module 带来的收益以及如快速转型Go Module)
GOPROXY时代之前,在Golang开发时,模块依赖关系直接从VCS系统中的源存储库下载,如GitHub、Bitbucket、Bazaar、Mercurial或SVN。来自第三方的依赖项通常从公共源repos下载。私有依赖项必须在存储它们以下载模块源文件的VCS系统中进行身份验证。
虽然上面的工作流得到了广泛的应用,但是它缺乏确定性和安全性构建,以及开发过程的两个基本需求:不变性和可用性。模块可以被作者删除,也可以编辑修改当前被发布的版本。虽然这些场景被认为是不好的实践,但它们确实经常发生,如下图:

为您的Golang开发或CI环境设置GOPROXY,将Go Module下载请求重定向到GOPROXY 指向的缓存库。
使用GOPROXY进行模块依赖关系的管理的有助于开发构建不变性需求。通过从GOPROXY的缓存中返回模块包,它能够为用户请求的某模块版本提供相同的返回(Go module模块代码),即使模块最近在VCS repo中被不正确地修改过,从而保证多次构建结果一致。
另外GOPROXY的缓存还有助于确保模块始终可用,即使VCS repo中的原始模块已被销毁。
使用GOPROXY有不同的方法,这取决于你想使用的go模块依赖的来源,通常有公共的GOPROXY,私有Go Module,以及私有的GOPROXY
公共GOPROXY是一个集中式的存储库,全球各地的Golang开发者都可以使用它。它缓存了大量开源的Go模块,这些模块可以从第三方公开访问的VCS项目存储库中获得。大多数此类GOPROXY,比如JFrog GoCenter,Goproxy.cn都是免费提供给Golang开发者社区的。此类GOPROXY 的架构拓扑如下图,提供了Go Module 的一致性以及可用性能力:

要使用公共GOPROXY,将Golang环境变量设置为其URL:
$ export GOPROXY=https://gocenter.io
以上设置将所有模块下载请求重定向到GoCenter。从公共GOPROXY下载要比直接从VCS下载快得多。
除了完成下载之外,一个公共的GOPROXY还可以为GoLang开发者提供关于它所拥有的模块的更详细的信息。JFrog GoCenter提供了丰富的UI,支持搜索和访问模块的安全信息(如cve)、非安全元数据(如Star数量,下载统计数据以及License信息)和gosumdb支持。这些元数据有助于用户在选择开源Go模块时做出更好的决策。

通常,GoLang项目会同时使用开源和私有模块。一些用户使用GOPRIVATE环境变量来指定一个必须绕过GOPROXY和GOSUMDB的路径列表,并直接从VCS repos下载私有模块。例如,您可能希望使用GoCenter检索所有开源模块,但只从公司的服务器请求私有模块。如下图:

要使用GoCenter公共GOPROXY和私有模块,请设置Golang环境变量:
$ export GOPROXY=https://gocenter.io,direct
$ export GOPRIVATE=*.internal.mycompany.com
这种对GOPRIVATE的使用也确保了你对这些私有模块的使用不会因为请求到一个开放网络上的公共GOPROXY &
checksum数据库服务器而“泄露”。另一种替代方法是使用GONOSUMDB变量,该变量包含对私有go模块的引用。虽然这种配置使Go客户端能够同时解析公共模块和私有模块依赖,但它并不强制私有模块的不可变性或可用性要求。
私有GOPROXY是一种在您自己的基础设施上存储公共和私有Go模块的工具。
公共模块通过在二进制存储库管理器(如JFrog
Artifactory)中代理一个公共GOPROXY缓存到企业内部网络。
私有模块也可以从VCS repos缓存到改存储库中。通过这种方式,可以保证公共和私有Go模块的不变性和可用性。
在Artifactory中,您可以通过设置GoCenter的远程存储库(remote reposiroty),以及指向私有GitHub 仓库(用于私有模块)的远程Go模块存储库,以及本地Go模块存储库,将上述三个仓库组合到一个虚拟存储库中,作为用户统一单元进行访问,如下图:

在Artifactory中设置名为“go”的虚拟存储库的GOPROXY:
$ export GOPROXY=”https://:@my.artifactory.server/artifactory/api/go/go
$ export GONOSUMDB=”github.com/mycompany/*,github.com/mypersonal/*”
因为您的私有VCS repos中的模块在sum.golang.org的公共校验和数据库中没有条目,所以它们必须被排除在go客户端的检查之外。将GONOSUMDB设置为您的私有VCS repos可以实现这一点,并将防止这些私有模块的go get命令由于校验和不匹配而失败。
在这个配置中,您可以确保对私有模块的引用不会“泄漏”,同时还确保了公共模块和私有模块的不可变性和可用性。
正如您所看到的,使用私有GOPROXY提供了最确定、最可靠和最安全的功能。
您还可以通过您的私有GOPROXY到您的构建工具的网络接近度来加速模块依赖关系的解析。JFrog Artifactory可以安装在您最需要它的地方:本地数据中心部署或云中,或公共云提供商的SaaS版本。
这些好处不仅仅局限于Golang开发。大多数技术公司使用不止一种语言和多个包管理器。例如,如果代码是用Golang编写的,那么npm可能用于UI,
Docker可能用于分发交付,Helm可能用于在k8上部署应用程序。
通过支持超过27种包类型,Artifactory可以为所有应用程序提供确定性、稳定和安全的软件开发过程。
更多精彩内容可以专注我们的在线课堂
微信搜索公众号:jfrogchina 获取课程通知
本文中的Redis高可用方案采用Sentinel(哨兵)模式(一个master:M1、两个slave:R2、R3,每个redis节点都有一个Sentinel:S1、S2、S3),Sentinel自身也是一个集群。在reids集群出现故障的时候,会自动进行故障转移,从而保证集群的可用性。
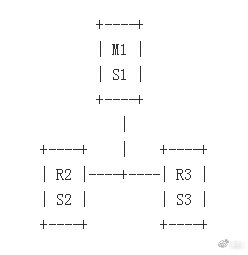
Redis 集群
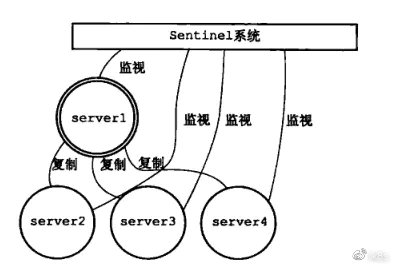
Sentiel的在redis集群中功能如下所示:
Sentinel本身是一套分布式系统,它被设计成能够进行多个进程间协同工作的模式,这样的好处如下:
Sentinel 将对redis集群中的所有redis节点进行监控,并在被监视的redis master(这里为server1)处于下线状态时,自动将某个redis slave升级为新的master。同上,会将其它redis slave设置为新的master节点的slave。
在Server1 掉线后:
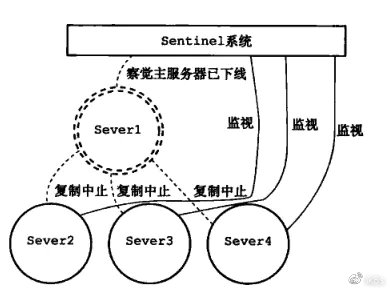
升级Server2 为新的主服务器:

通过执行下面的命令,添加helm stable仓库:
helm repo add bitnami https://charts.bitnami.com/bitnami
通过执行下面的命令,在Kubernetes中部署redis高可用方案:
helm install bitnami-redis –set master.service.type=NodePort –set cluster.enabled=true –set sentinel.enabled=true –set metrics.enabled=true –set password=redis bitnami/redis –namespace=kube-public
其中:
这里go语言客户端对redis进行验证访问,通过执行下面的命令获取go-redis/redis客户端。
—
go get -u github.com/go-redis/redis
—
通过执行cd $GOPATH/src,进入go工作目录中,在此目录目录下创建connect_redis.go文件,此文件内容如下所示。
—
package main
import (
“fmt”
“github.com/go-redis/redis”
)
func main() {
// 构建连接客户端
client := redis.NewClient(&redis.Options{
Addr: “10.0.33.203:31426”,
Password: “redis”, //no password set
DB: 0, // use default DB
})
ping, err := client.Ping().Result()
fmt.Println(ping, err)
// 创建数据 age=18
err = client.Set(“age”, “18”, 0).Err()
if err != nil {
panic(err)
}
// 获取age键的值
val, err := client.Get(“age”).Result()
if err != nil {
panic(err)
}
fmt.Println(“age”, val)
}
—
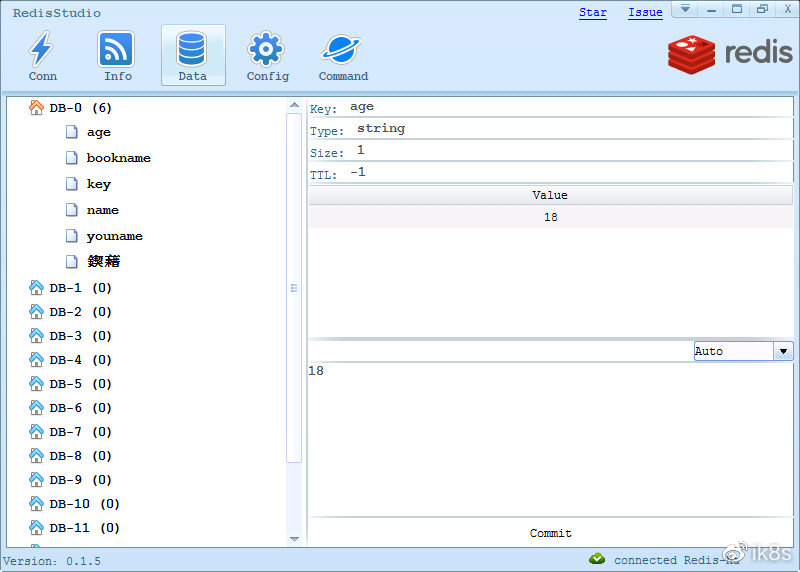
通过执行go run connect_redis.go,客户端会连接redis服务,并创建age=18的键值对数据。
在这里通过RedisStudio可视化工具查看redis中的数据,此工具可以通过:https://github.com/cinience/RedisStudio/releases 进行下载。
在部署是设置了metrics.enabled为true,在k8s中对应部署了metrics容器,通过此容器用于获取redis的指标信息,并提供给Prometheus。

在Prometheus的配置文件(/etc/prometheus/prometheus.yml)的最后面增加下面的内容。
– job_name: ‘redis-ha-exporter’
static_configs:
– targets: [‘bitnami-redis-metrics.redis-ha:9121’]
并在k8s中重新部署Prometheus。
在Grafana中导入Redis Dashboard for Prometheus Redis Exporter,通过此DashBoard就能监控redis运行的相关指标。

1)Redis Sentinel:https://www.jianshu.com/p/231afa35d937
2)Redis Sentinel Documentation:https://github.com/antirez/redis-doc/blob/master/topics/sentinel.md
3)Redis:https://hub.helm.sh/charts/bitnami/redis
作者简介:季向远,本文版权归原作者所有。微博:ik8s

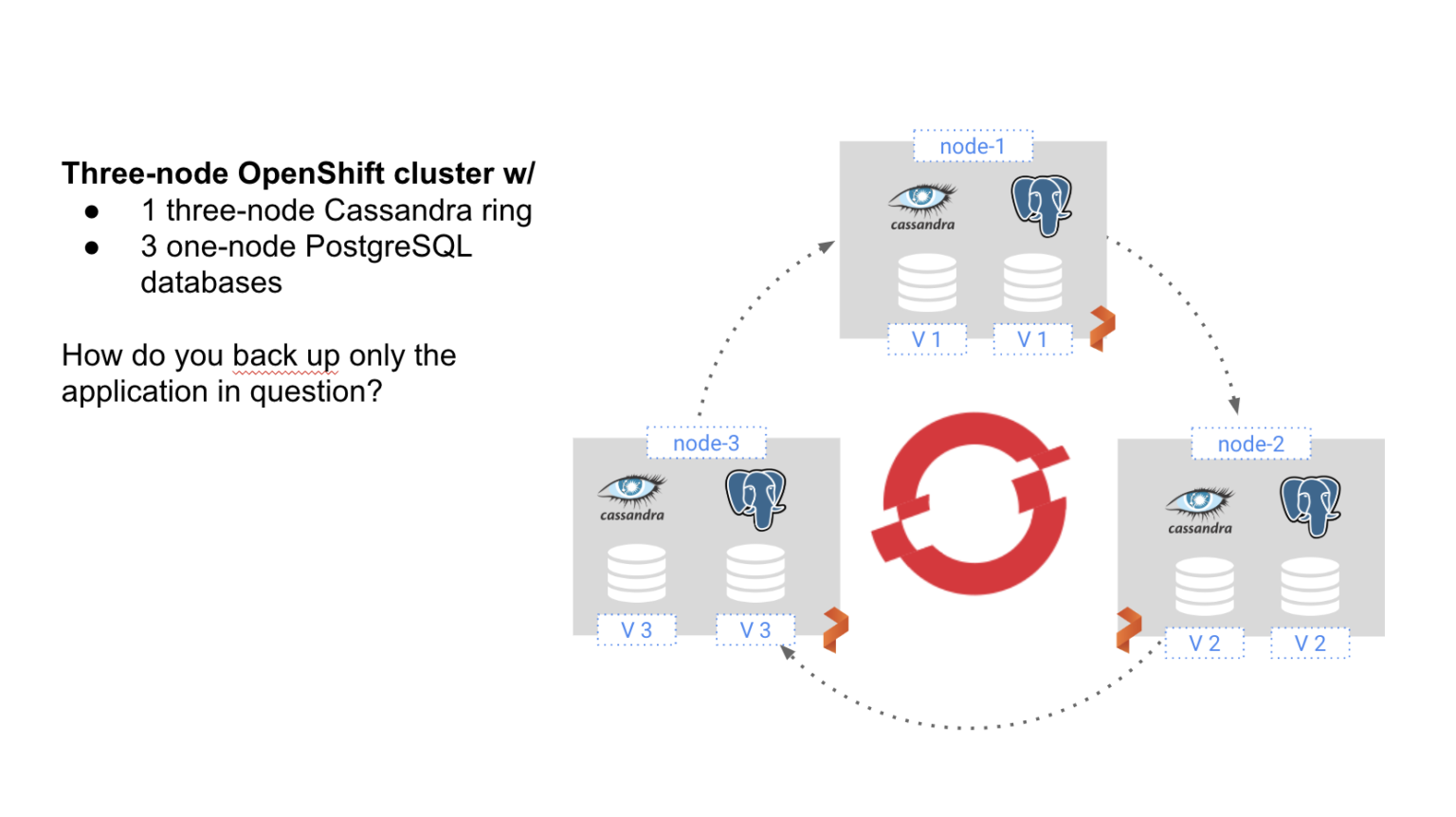
为了解决这个问题,Openshift上的容灾需要的解决方案应是:
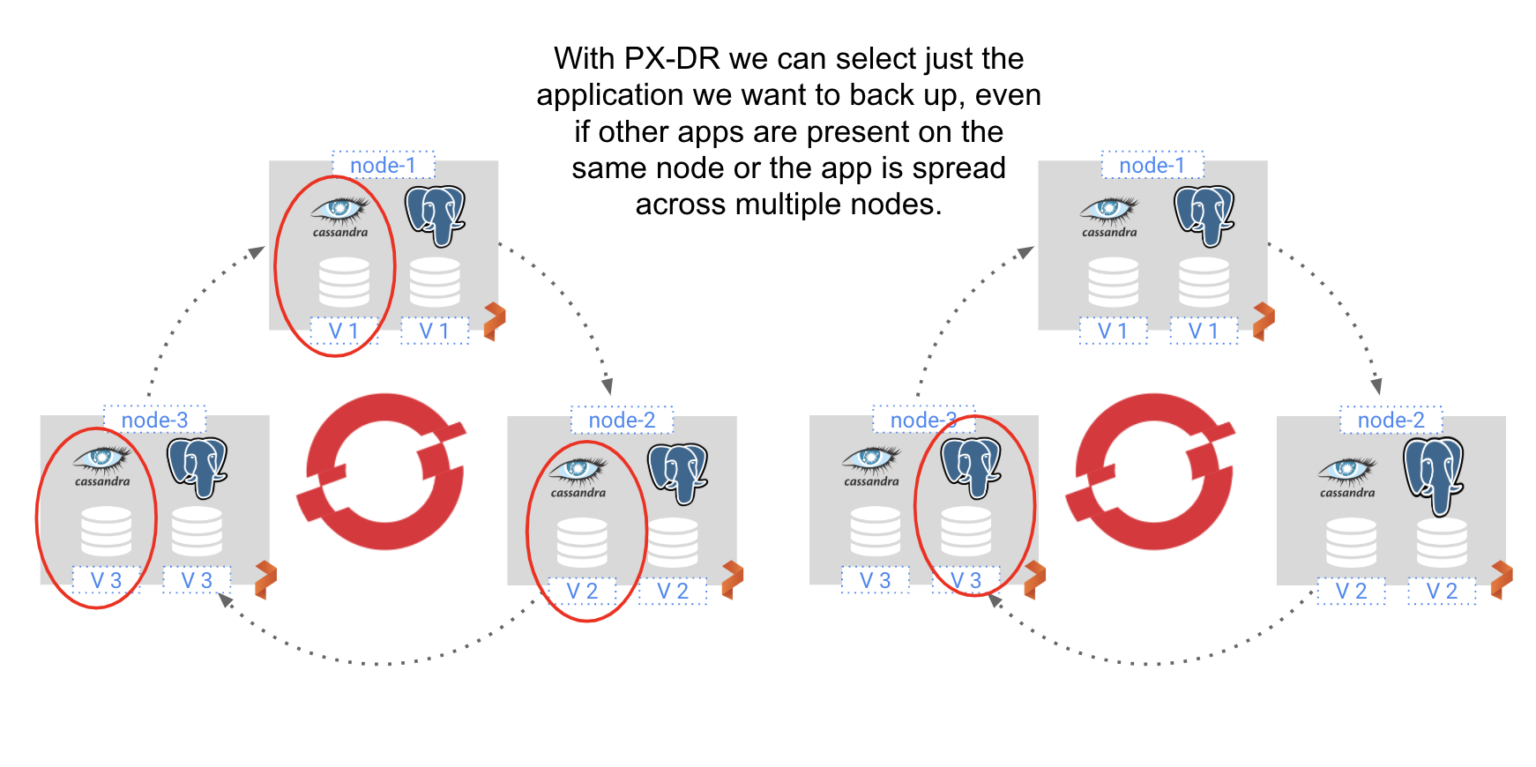
Portworx企业版数据平台的PX-DR就是按照以上的原则设计的。
apiVersion: stork.libopenstorage.org/v1alpha1
kind: Rule
metadata:
name: cassandra-presnap-rule
spec:
– podSelector:
app: cassandra
actions:
– type: command
value: nodetool flush
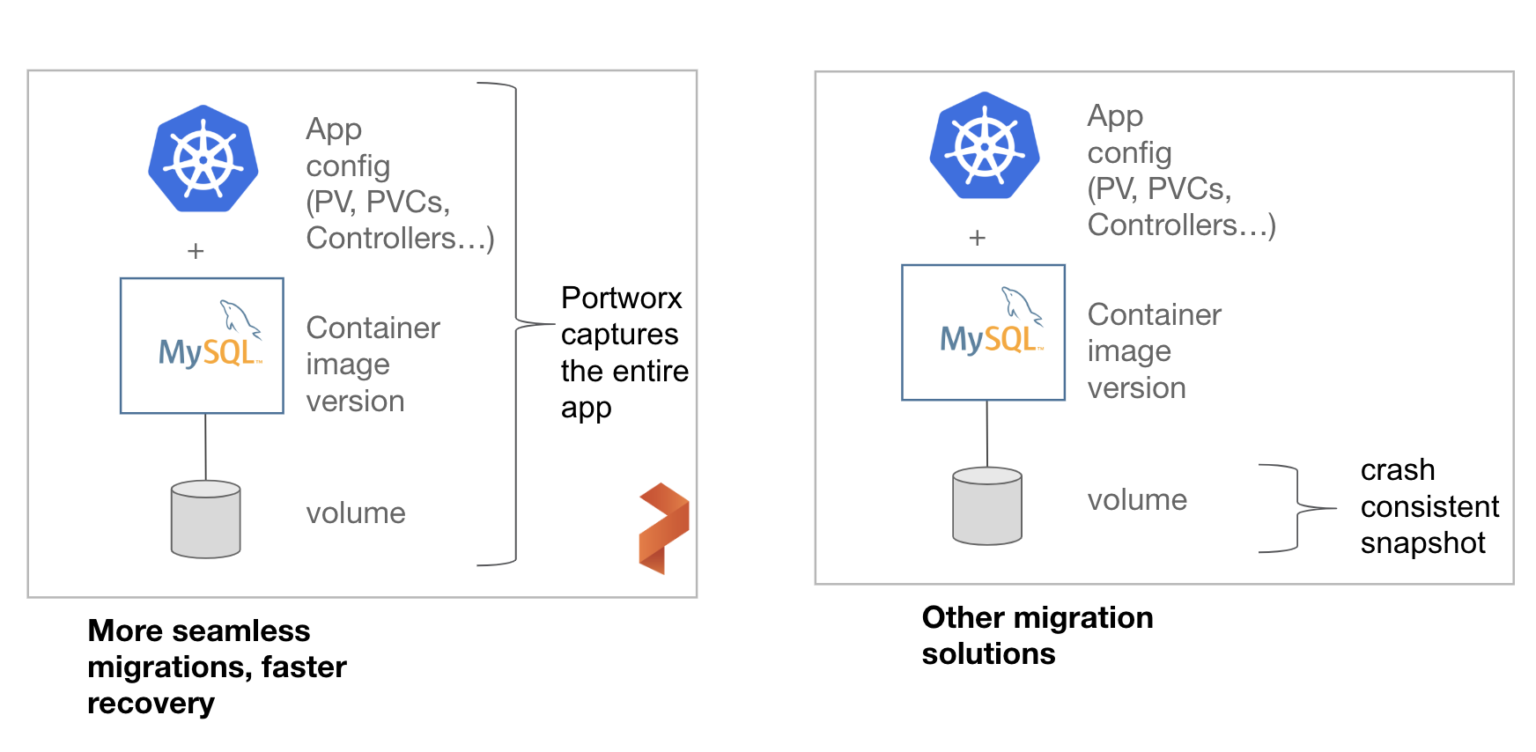
例如,一个银行有本地部署的数据中心,并且通过专线连接到了一个AWS数据中心,可能会需要为一个重要商业应用选择零RPO的DR策略,同时要求RTO<1分钟。在这种情况下,我们倾向于推荐同步备份的PX-DR,由于两个环境的延时极低,因此可以提供零数据损失的恢复。
另一个例子,如果一个制造业的公司在较远的两地有两个数据中心,应用要求较低的RTO,但按每小时的备份频率对于RPO的目标来说已经足够了,在这种情况下,异步备份的PX-DR,使用连续增量式的备份就已经足够。

下面是不同情况下OpenShift DR策略的选择
较远网络的OpenShift容灾策略(两个站点之间的往返延迟 >10毫秒的情况)
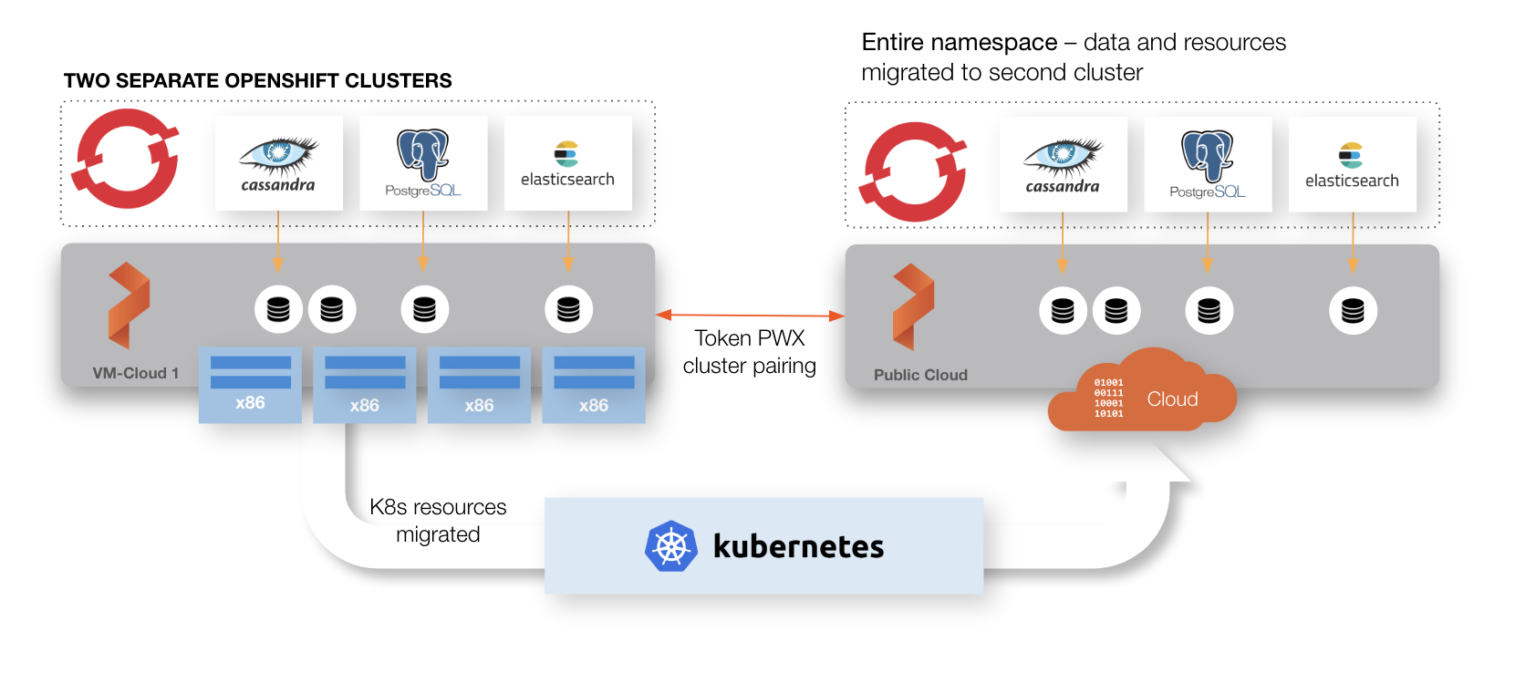

通过集群域,Portworx数据管理层来区分主站点和容灾站点。集群域在Portworx集群被安装的时候就会配置完成。在每一个OpenShift集群上(主集群或DR集群)配置Portworx来包括同一个Key-value的存储端点和集群名称,但使用不同的集群域来区分主站点和DR站点,看下面的例子。
Primary DR Site args: [“-k”, “etcd:http://etcd:2379”, “-c”, “px-cluster-synchronous”, “-s”, “type=gp2,size=250”, “-secret_type”, “k8s”, “-cluster_domain”, “primary” “-x”, “kubernetes”] “` args: [“-k”, “etcd:http://etcd:2379”, “-c”, “px-cluster-synchronous”, “-s”, “type=gp2,size=250”, “-secret_type”, “k8s”, “-cluster_domain”, “dr-site” “-x”, “kubernetes”]
低延时要求
$ ping ip-10-0-131-167 PING (10.0.131.167) 56(84) bytes of data. 64 bytes from (10.0.131.167): icmp_seq=1 ttl=255 time=0.019 ms 64 bytes from (10.0.131.167): icmp_seq=2 ttl=255 time=0.028 ms 64 bytes from (10.0.131.167): icmp_seq=3 ttl=255 time=0.035 ms 64 bytes from (10.0.131.167): icmp_seq=4 ttl=255 time=0.029 ms 64 bytes from (10.0.131.167): icmp_seq=5 ttl=255 time=0.028 ms ^C — ip-10-0-131-167.us-west-2.compute.internal ping statistics — 5 packets transmitted, 5 received, 0% packet loss, time 4080ms rtt min/avg/max/mdev = 0.019/0.027/0.035/0.008 ms
Setup Openshift集群配对
一旦完成两个站点都在运行Portworx,在正确的集群域设定基础上,它们就可以正常的来Sync了。我们可以通过Portworx命令 “` $ pxctl cluster domains show “` 来进行验证。验证完成后,并且两个集群域都是正常的情况下,就可以创建集群配对对象。这样两个站点就可以共享一个OpenShift应用YAML文件。这些YAML文件代表了应用的配置,对于在出问题时保证低RTO有着重要的作用。首先为目标命名空间产生集群配对,然后把YAML文件应用到主站点上。
$ storkctl generate clusterpair -n appns dr-site > dr-site.yaml
$ oc create -f dr-site.yaml
可以通过下面的命令来验证集群配对。
$ storkctl get clusterdomainsstatus
创建一个调度和迁移
取决于你的组织的RTO要求,你可以选择应用的sync频率。通过创建一个策略来定义调度,然后把调度和应用的迁移关联起来。
首先,创建一个调度,下面的例子中在每一分钟迁移应用配置。把它保存成一个Yaml文件,然后使用`oc create -f` 来创建策略。
apiVersion: stork.libopenstorage.org/v1alpha1
kind: SchedulePolicy
metadata:
name: sched-policy
namespace: appns
policy:
interval:
intervalMinutes: 1
daily:
time: “10:14PM”
weekly:
day: “Thursday”
time: “10:13PM”
monthly:
date: 14
time: “8:05PM”
接下来,创建一个迁移:针对 “appns”命名空间、“dr-site”集群配对、和使用这个调度。注意文件最下方的“schedulePolicyName”。存成一个yaml文件,然后通过` oc create -f` 来应用它。
apiVersion: stork.libopenstorage.org/v1alpha1
kind: MigrationSchedule
metadata:
name: migrationschedule
namespace: appns
spec:
template:
spec:
clusterPair: dr-site
includeResources: true
startApplications: false
includeVolumes: false
namespaces:
– demo
schedulePolicyName: sched-policy
注意以上仅仅设定includeResources是true,而设定其他的都是false,因为同步DR集群已经在两个集群上都配置了数据,因此我们不再需要include卷,并且直到有系统错误发生前,我们也不想启动这个应用。如果我们使用异步PX-DR方式,我们需要把`includeVolumes` 改为true。
你可以通过运行下面的命令来验证迁移是否已经完成。
$ storkctl get migration
通过OpenShift DR站点来恢复
现在OpenShift集群都已经sync完成,应用也sync完成。我们准备好来恢复应用了。当一个主站点的灾难发生后,下面的步骤即可在DR站点上恢复,并且是零RPO。
首先,关闭主站点,等待域变成 (NotInSync)
$ storkctl deactivate clusterdomain ocs-primary
$ storkctl get clusterdomainsstatus
接下来,如果你有权限访问主站点,把复制集变成0。如果你没有权限访问主站点,直接走到下一步,在容灾站点上恢复应用。
$ oc scale deploy -n demo –replicas=0 –all
通过向迁移调度增加 `suspend:true` ,并且更新spec,可以暂停迁移
apiVersion: stork.libopenstorage.org/v1alpha1
kind: MigrationSchedule
metadata:
name: migrationschedule
namespace: appns
spec:
template:
spec:
clusterPair: dr-site
includeResources: true
startApplications: false
includeVolumes: false
namespaces:
– demo
schedulePolicyName: sched-policy
suspend: true
$oc apply -f migration-schedule.yaml
最后,在DR站点上,启动迁移,打开DR站点上的Pods。
$ storkctl activate migration -n appns
你的“appns”命名空间里的应用现在已经在OpenShift DR站点上重启了,并且是0数据损失。
PX-DR包括一个API可以自动化的实现上面的步骤,另外,当主站点又重新启动后,应用的配置和数据会重新被sync,这样就可以重新在主站点上启动应用。