导读:云原生操作系统进化,详解阿里云 ACK Pro、ASM、ACR EE、ACK@Edge 等四款企业级容器新品。
KubeCon 2020 中国站,阿里云容器服务负责人易立会在《云原生,数字经济技术创新基石》的演讲中,分享阿里云原生如何助力数字技术抗‘疫’,阐述阿里云对云原生操作系统的思考,同时详解阿里云 ACK Pro、ASM、ACR EE、ACK@Edge 四款企业级容器新品。
容器服务 ACK Pro,为企业级大规模生产环境提供增强的可靠性安全性,以及与可赔付标准 SLA,现已开启公测。同时还有三款产品商业化:服务网格 ASM,统一精准管控容器化微服务应用流量;容器镜像服务企业版 ACR EE,公共云首个独享实例形态的容器镜像仓库产品,是支撑阿里巴巴经济体的双十一同款利器,具备如下能力:多维度安全保障、全球镜像分发加速、DevSecOps 交付提效特点,保障企业客户云原生制品的安全托管及高效分发;边缘容器 ACK@Edge 采用非侵入方式增强,提供边缘自治、边缘单元、边缘流量管理、原生运维 API 支持等能力,以原生方式支持边缘计算场景下的应用统一生命周期管理和统一资源调度。

疫情期间,争分夺秒的云原生
云计算是数字时代新基建,而 2020 疫情也为数字化生活按下了快进键。“上班用钉钉,上学云课堂,出门健康码,订菜送到家”成为了日常生活一部分,这背后是一系列云计算、云原生技术支撑的业务创新。
2 小时内支撑了钉钉业务 1 万台云主机的扩容需求,基于阿里云服务器和容器化的应用部署方案,钉钉应用发布扩容效率大大提升,顺利扛住有史以来最大的流量洪峰,为全国用户提供线上工作的流畅体验。
停课不停学,希沃课堂整体业务性能提升 30%、运维成本降低 50%,洋葱学院系统资源利用率提升 60%。
健康码基于云原生大数据平台具备弹性、韧性和安全的特点,平稳支撑每日亿次调用。
盒马通过阿里云边缘容器服务 ACK@Edge,快速构建人、货、场数字化全链路融合,云、边、端一体化协同的天眼 AI 系统。结合了云原生技术体系良好的资源调度和应用管理能力,与边缘计算就近访问,实时处理的优势,轻松实现全方位的『降本提效』,门店计算资源成本节省 50%,新店开服效率提升 70%。
云原生操作系统的诞生与进化
容器技术的发展揭开了云原生计算的序幕,在易立看来, Kubernetes 为基础的云原生计算也已经成为新的操作系统,云原生操作系统的雏形被越来越多的行业和企业采纳并因此受益:容器应用化、容器编排系统和 Istio 服务网格等技术依次解耦了应用与运行环境、资源编排调度与底层基础设施、服务实现与服务治理等传统架构的依赖关系。

阿里云为用户提供了怎样的云原生操作系统?这个云原生操作系统又有哪些突出特点呢?
首先基础设施层是强大的 IaaS 资源,基于第三代神龙架构的计算资源可以更弹性的扩展,以更加优化的成本提供更高的性能;云原生的分布式文件系统,为容器持久化数据而生;云原生网络加速应用交付能力,提供应用型负载均衡与容器网络基础设施。

其次在容器编排层,阿里云容器服务自 2015 年上线来,伴随数千家企业客户,共同实践过各行各业大量生产级场景。越来越多的客户以云原生的方式架构其大部分甚至全量应用,随着业务深入发展,为了满足大中型企业对可靠性、安全性的强烈需求,阿里云推出新品可供赔付 SLA 的容器服务企业版 ACK Pro。
容器服务企业版 ACK Pro 横空出世:全面安全、高性能,支持新一代神龙架构,SLA 可赔付
容器服务企业版 ACK Pro,是在原容器服务 ACK 托管版集群的基础上发展而来,其继承了原托管版集群的所有优势,例如 Master 节点托管和高可用等。同时,相比原托管版进一步提升了集群的可靠性、安全性和调度性能,并且支持赔付标准的 SLA,高达 99.95%,单集群可支持 5000 节点。ACK Pro 非常适合生产环境下有着大规模业务、对稳定性和安全性有高要求的企业客户。
ACK Pro 支持神龙架构,凭借软硬一体的优化设计,可为企业应用提供卓越的性能;支持无损 Terway 容器网络,相比路由网络延迟下降 30%;为企业提供全面安全防护,支持阿里云安全沙箱容器,满足企业客户对应用的安全、隔离需求,性能相比开源提升 30%。此外,ACK Pro 提供了对异构算力和工作负载优化的高效调度,支持智能 CPU 调度优化,在保障 SLA 和密度的前提下,Web 应用 QPS 提升 30%;支持 GPU 算力共享, AI 模型预测成本节省 50% 以上。
阿里云视频云已在全球十多个区域使用容器服务作为服务基础,有效管理全球万级节点的资源,其中 ACK Pro 切实保障基础设施层大规模计算资源的运维效率和高稳定性,使视频云团队可以将更多时间精力聚焦在视频领域从而为客户提供更多价值。
近日, 阿里云容器服务并成为国内首批通过可信云容器安全先进性认证的企业级容器平台,以 49 个满分项目荣获最高级别先进级认证,特别是在最小化攻击面,二进制镜像验签名,密文的 BYOK 加密等能力上国内领先,达到国际先进水平。
容器服务 ACK Pro 现已正式开启公测,非常适用于互联网、大数据计算、金融政府及跨海业务企业等,欢迎各位感兴趣的客户在官网上申请试用。
业内首个全托管 Istio 兼容服务网格 ASM,多种异构应用服务统一治理
在服务网格技术诞生前,应用服务治理的逻辑实现通常都是以代码库的方式嵌入在应用程序中,随着应用复杂度的增长和团队规模的扩大,代码库变更和维护会变地越来越复杂。服务网格通过 Sidecar 代理功能,将服务治理能力与应用程序本身解耦,将服务治理能力标准化、统一化,且更好地支持多种编程语言和技术框架的应用服务。
作为业内首个全托管 Istio 兼容的服务网格产品 ASM,已经正式商业化发布,用户可以在多个地域部署使用。阿里云一开始从架构上就保持了与社区、业界趋势的领先性,控制平面的组件托管在阿里云侧,与数据面侧的用户集群独立。ASM 在托管的控制面侧提供了用于支撑精细化的流量管理和安全管理的组件能力。通过托管模式,解耦了 Istio 组件与所管理的 K8s 集群的生命周期管理,使得架构更加灵活,提升了系统的可伸缩性。
商米科技使用服务网格 ASM 之后,充分享受了 Service Mesh 带来的好处,解决了 GRPC-HTTP2.0 多路复用引起的负载不均衡的问题,得以分离控制平面和数据平面,受益于 ASM 的可视化方式对控制平面进行管理,对规则配置一目了然。同时还无缝结合链路监控(Tracing Analysis)解决服务化体系下调用链排查追踪问题。
作为多种类型计算服务统一管理的基础设施, ASM 提供了统一的流量管理能力、统一的服务安全能力、统一的服务可观测性能力、以及统一的数据面可扩展能力, 并提出了相应的实践之成熟度模型。针对用户不同的场景, 逐步采用, 分别为一键启用、可观测提升、安全加固、多种基础设施的支持以及多集群混合管理。
全球镜像同步加速,ACR EE 保障云原生制品的安全托管及高效分发
容器镜像服务企业版 ACR EE 面向安全及性能需求高,业务多地域大规模部署的企业级客户,提供了公共云首个独享实例模式的企业版服务。
在制品托管部分,ACR EE 除了支持多架构容器镜像,还支持多版本 Helm Chart 等符合 OCI 规范制品托管。在分发及安全治理部分,ACR EE 加强了全球多地域分发和大规模分发支持,提供网络访问控制、安全扫描、安全加签、安全审计等多维度安全保障,助力企业从 DevOps 到 DevSecOps 的升级。目前已有数百家企业线上环境大规模使用,保障企业客户云原生应用制品的安全托管及高效分发。
某国际零售巨头是全球多地域业务形态,存在多地研发协作及多地域部署的场景。采用 ACR EE 之后,客户只需配置实例同步规则,在业务迭代更新容器镜像后,可实现分钟级自动同步至全球指定地域,自动触发 ACK 集群业务部署。完美应对跨海网络链路不稳定、分发不安全的问题,极大提高业务研发迭代效率和部署稳定性,保障企业业务的全球化部署。
除了业务镜像全球自动化部署,也有很多企业通过 ACR EE 的云原生应用交付链功能,通过全链路可追踪、可观测、可自主配置等实践容器化 DevSecOps。
业界首创“云边一体化”理念 ,边缘容器服务 ACK@Edge 正式商业化
与此同时,阿里云深度挖掘了“边缘计算+云原生落地实施”诉求,在去年 KubeCon 上,重磅发布了边缘容器(ACK@Edge),时隔一年,宣布 ACK@Edge 正式商用。此外,ACK@Edge 也将其核心能力开源,并向社区贡献完整的云原生边缘计算项目——OpenYurt。
在过去短短一年的时间里,该款产品已经应用于音视频直播、云游戏、工业互联网、交通物流、城市大脑等应用场景中,并服务于盒马、优酷、阿里视频云和众多互联网、新零售企业。
YY 使用 ACK@Edge 之后,可以 API 统一管理、统一运维边缘容器集群和中心容器集群,边缘算力快速接入并实现边缘节点自治,同时也可以无缝接入 Prometheus 服务实现监控数据上报,总体上运维效率和资源使用率都得到显著改善。
ACK@Edge 适用于丰富的应用场景, 包括边缘智能、智慧楼宇、智慧工厂、音视频直播、在线教育、CDN。
云原生技术不但可以最大化云的弹性,帮助企业实现降本提效;而且还意味着更多创新的想象空间, 云原生将和 AI, 边缘计算,机密计算等新技术相结合,为数字经济构建智能、互联、信任的创新基础设施。
“新基石、新算力、新生态是容器产品发展策略 ” ,易立称,“云原生技术正成为释放云价值的最短路径,团队会帮助企业更好支撑混合云、云边一体的分布式云架构和全球化应用交付。基于云原生的软硬一体化技术创新,如神龙架构,含光芯片,GPU 共享调度等,阿里云将加速业务智能化升级。同时我们还会通过开放技术生态和全球合作伙伴计划,让更多企业分享云时代技术红利。”
“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”













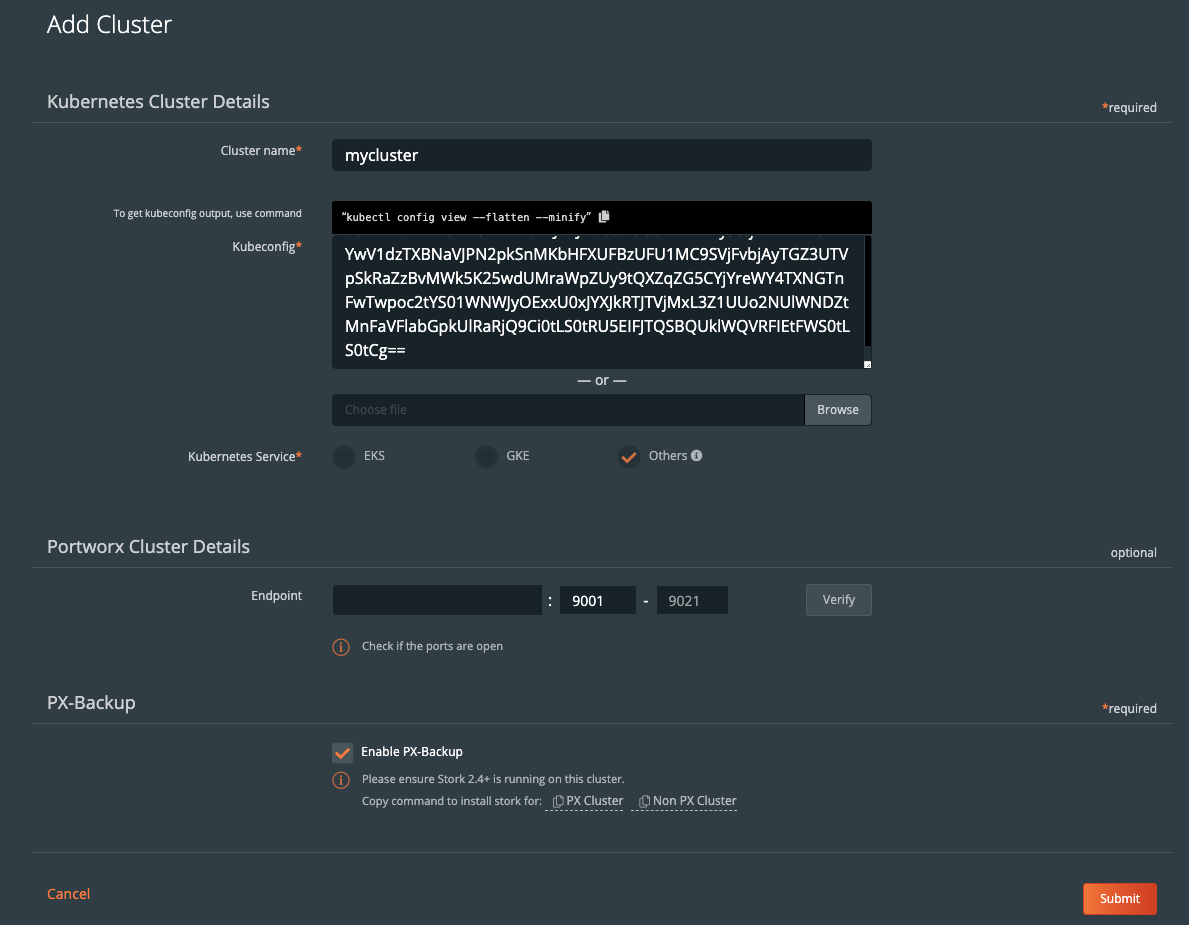

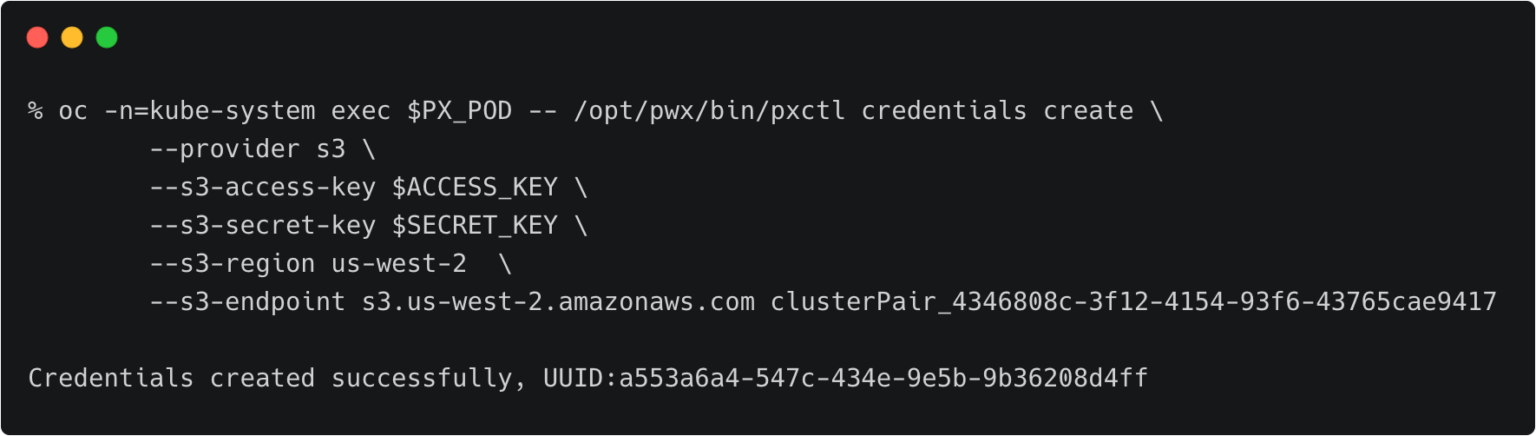
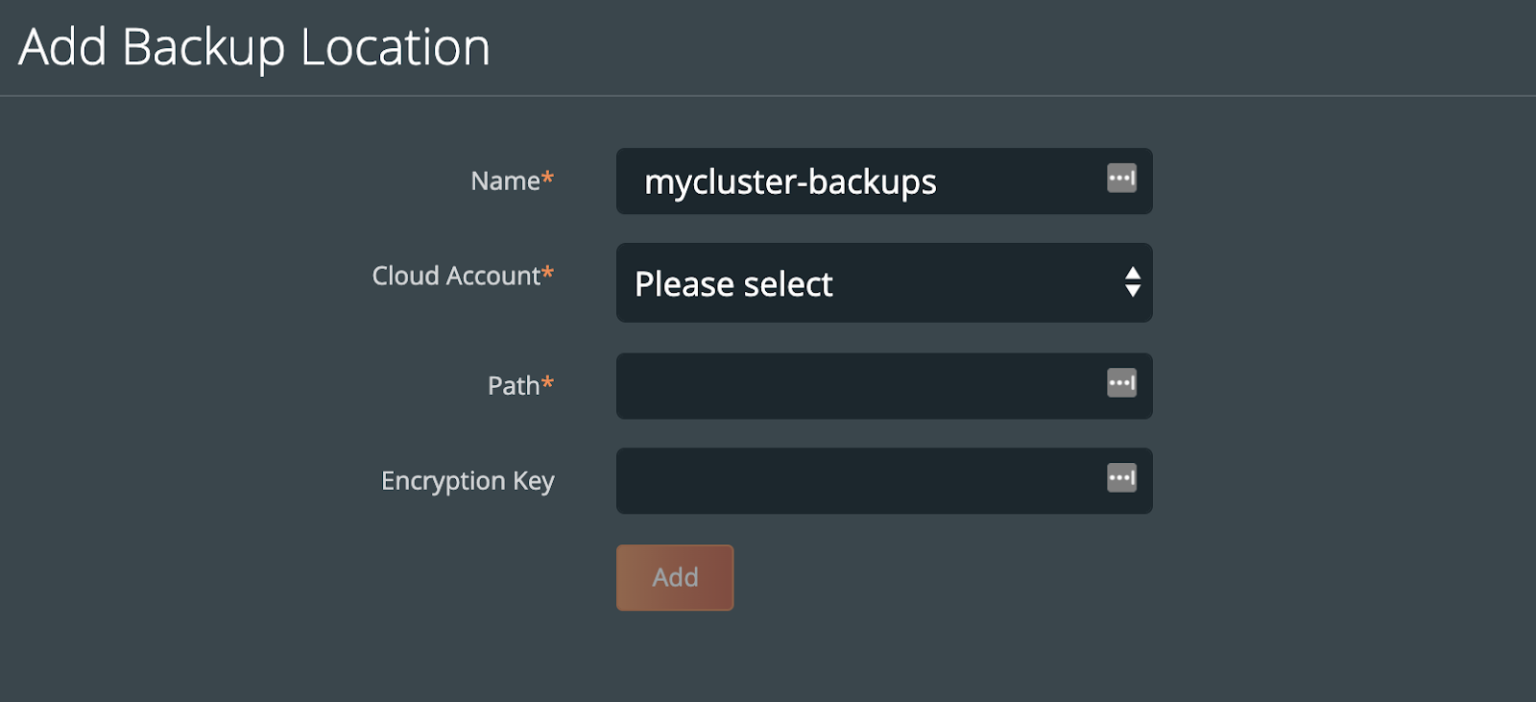
 关于不同的备份目标位置,这里有详细的文档(https://backup.docs.portworx.com/use-px-backup/credentials/)。一般来说,至少需要创建一个云账户(如AWS,Azure,Google),以及创建一个备份位置(如云对象存储的位置)。
关于不同的备份目标位置,这里有详细的文档(https://backup.docs.portworx.com/use-px-backup/credentials/)。一般来说,至少需要创建一个云账户(如AWS,Azure,Google),以及创建一个备份位置(如云对象存储的位置)。


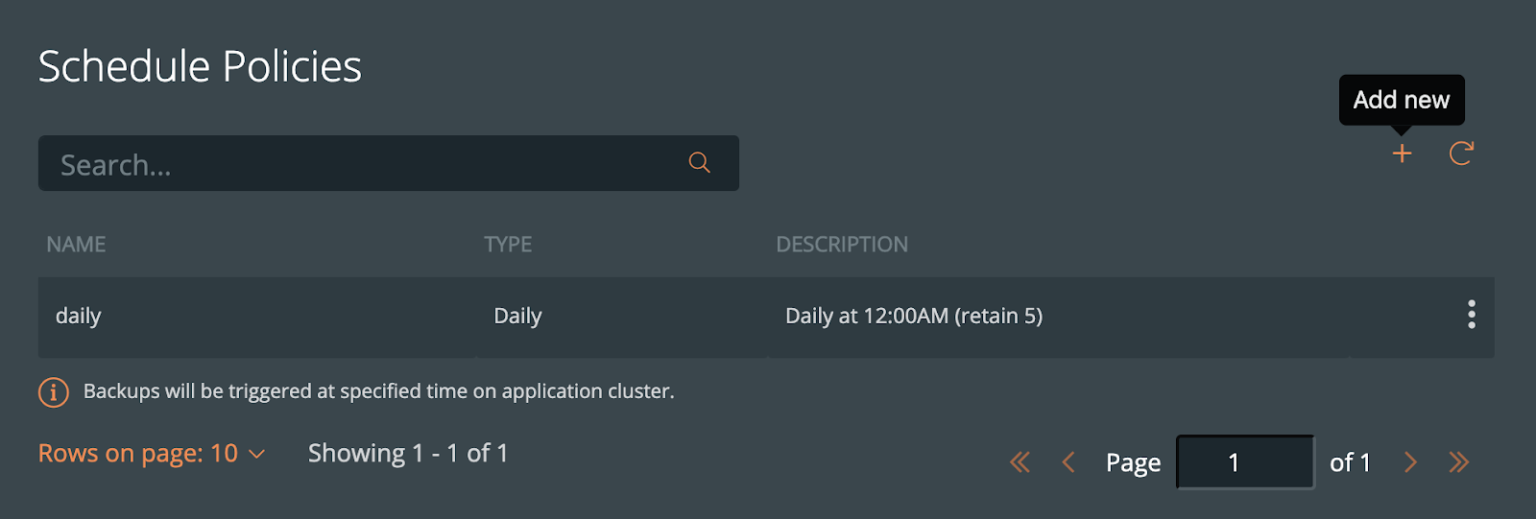
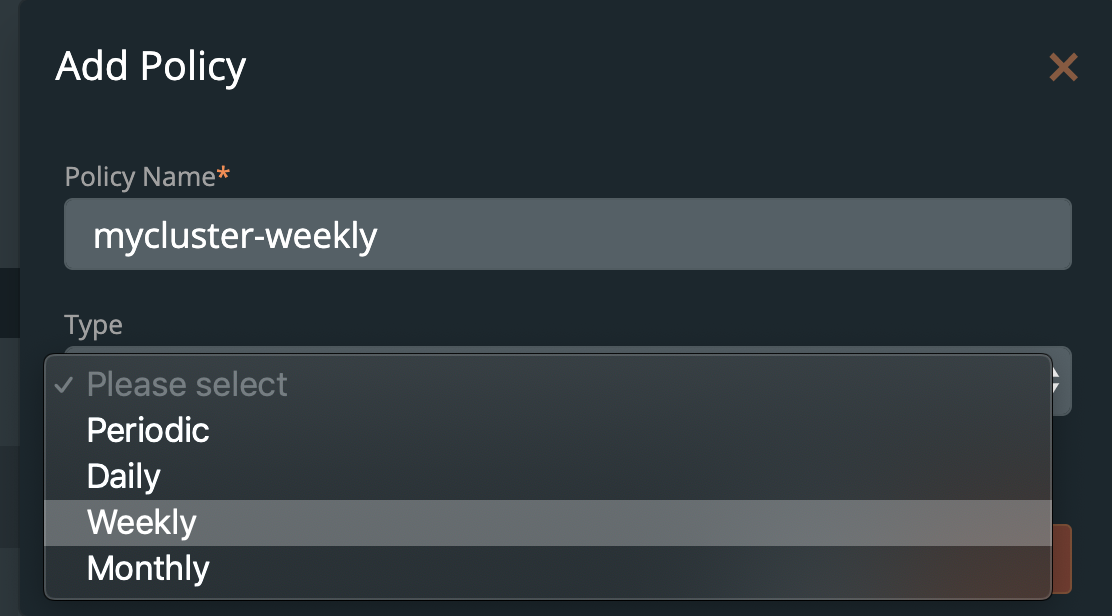
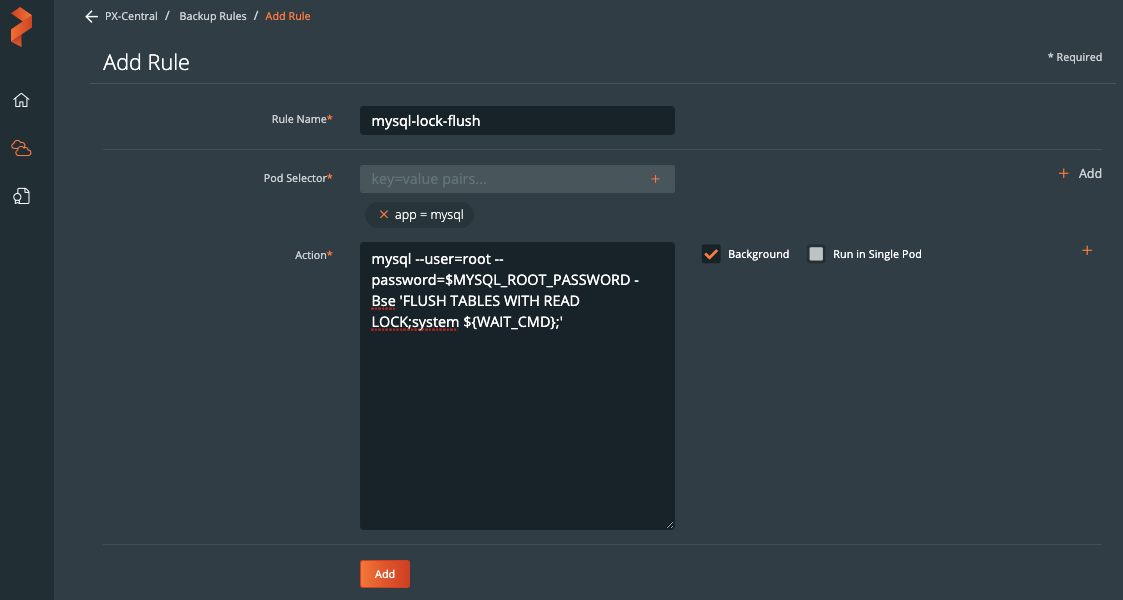
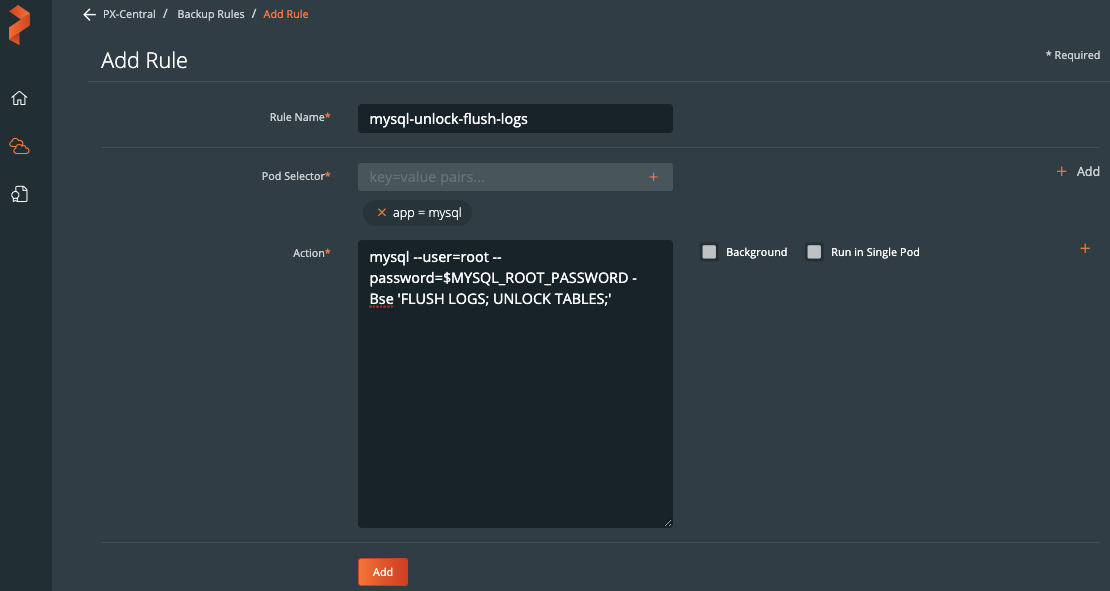
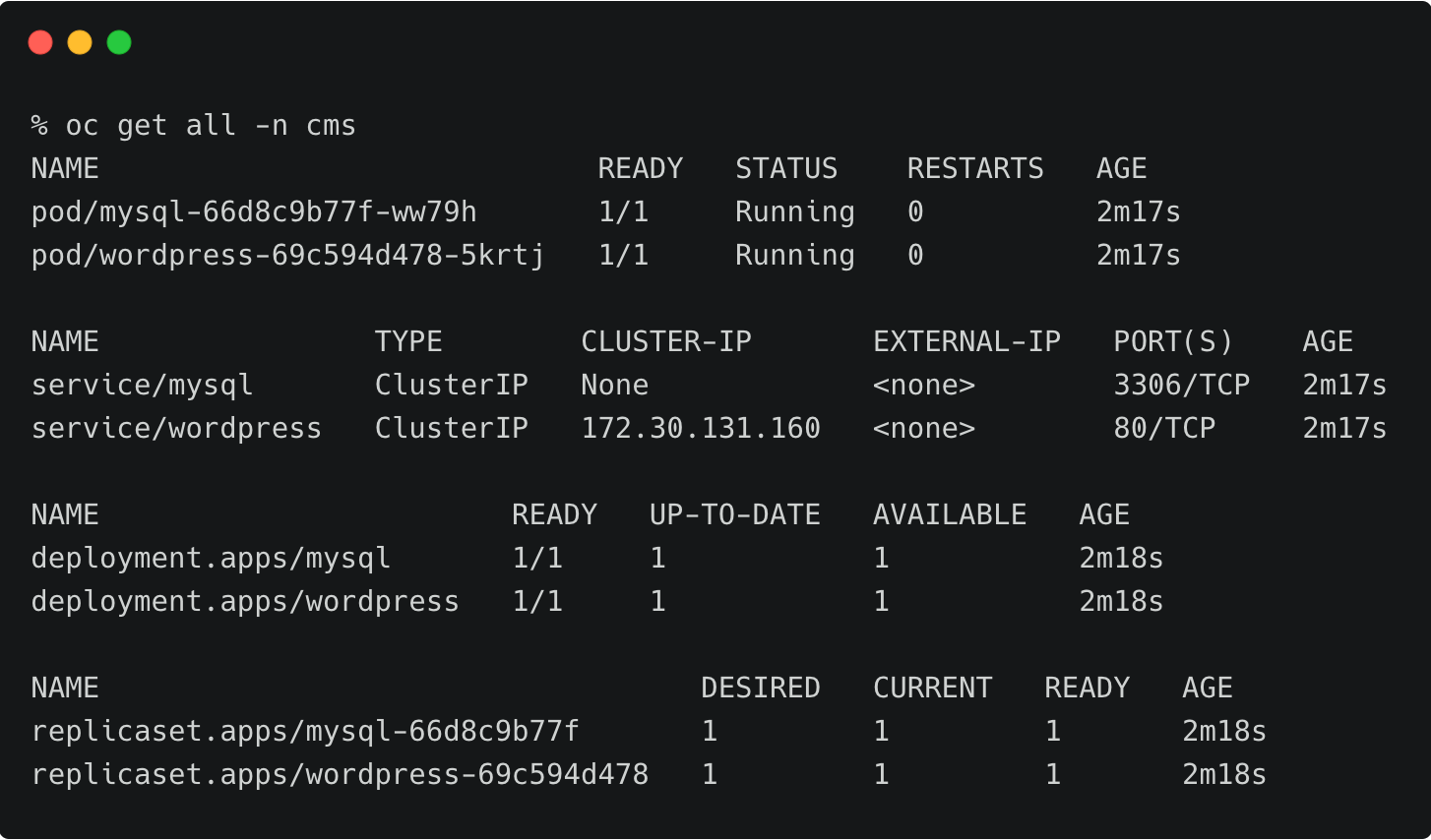
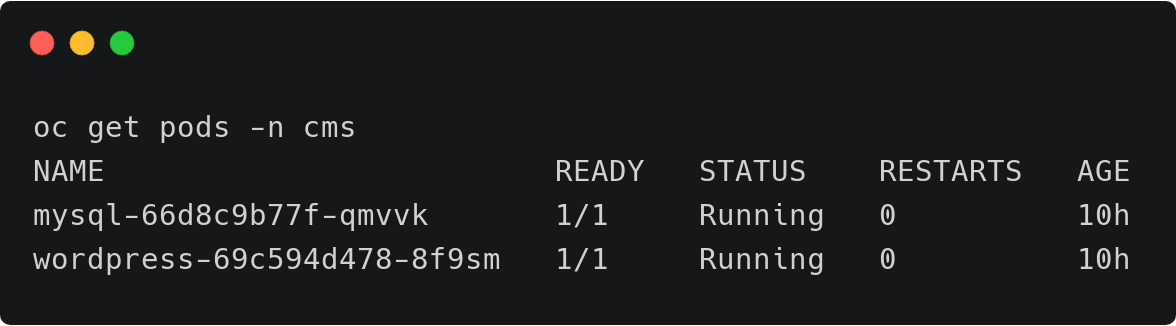
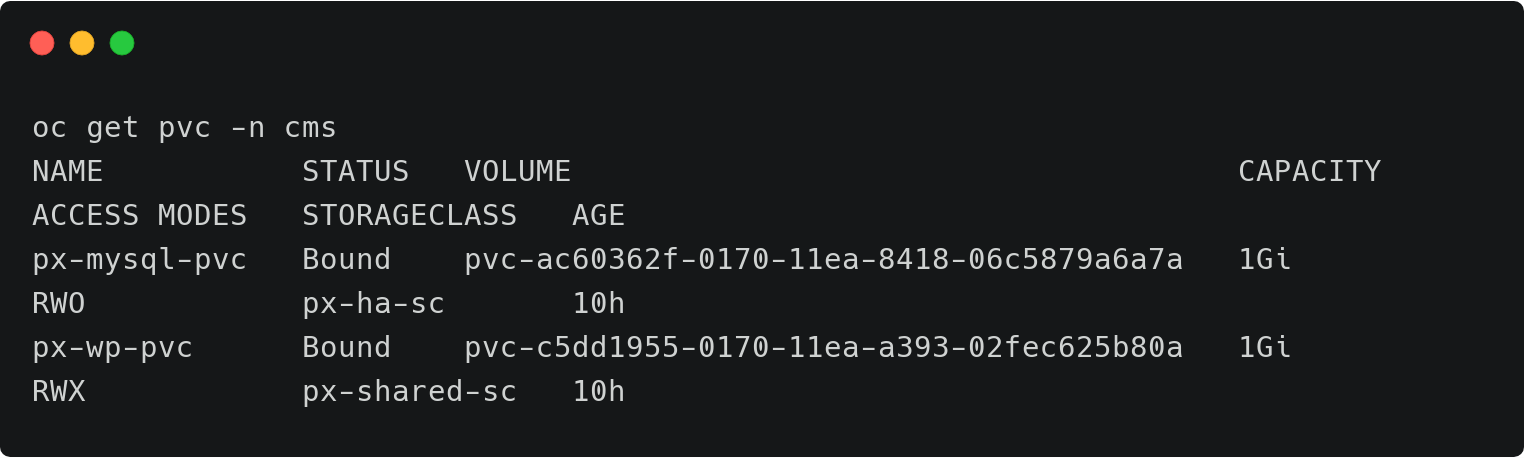
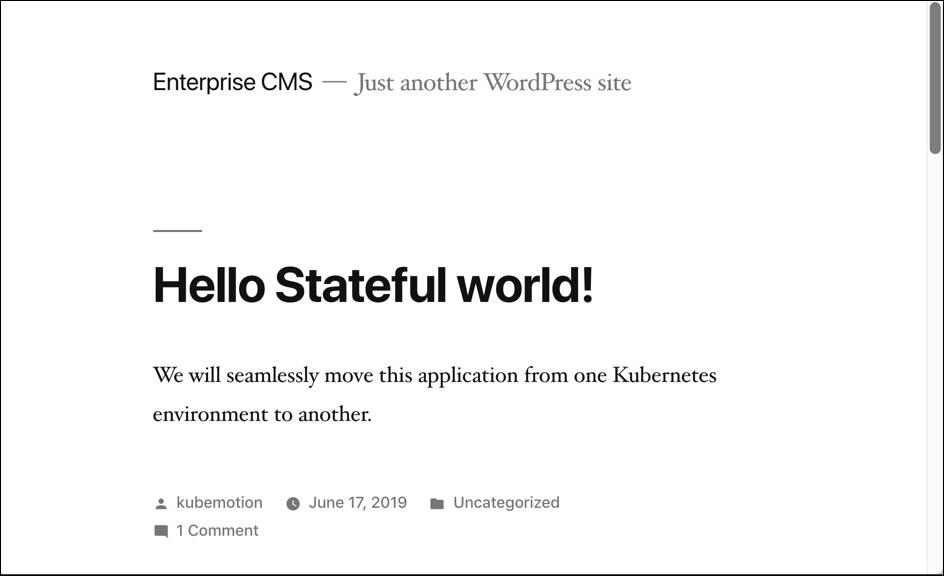
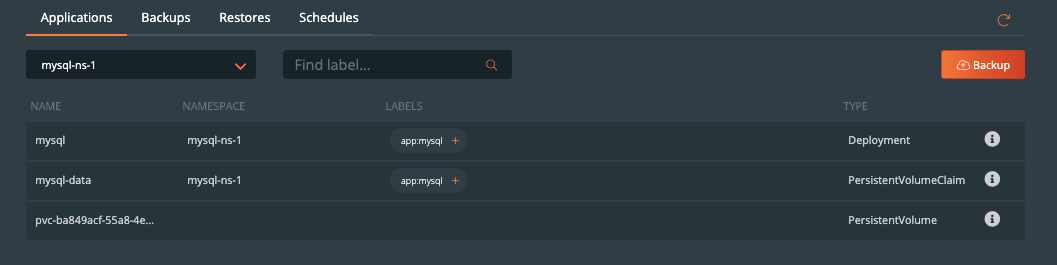 在命名空间内,我们可以选择MySQL相关的标签,可以仅备份具备标签的特定的对象。或者在命名空间备份界面中,通过点击右上角的Backup按钮备份整个命名空间。
在命名空间内,我们可以选择MySQL相关的标签,可以仅备份具备标签的特定的对象。或者在命名空间备份界面中,通过点击右上角的Backup按钮备份整个命名空间。
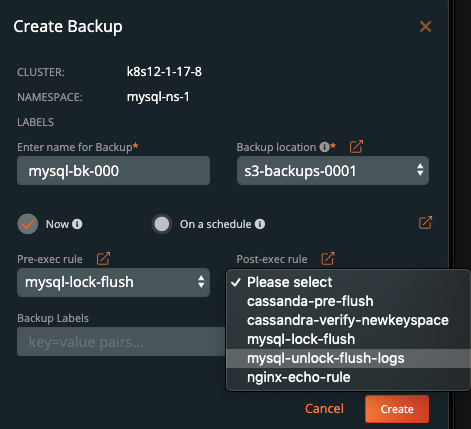
 一旦创建完成,备份会进入Pending状态,然后进入In Progress状态。这时的备份图标是下面的样子。
一旦创建完成,备份会进入Pending状态,然后进入In Progress状态。这时的备份图标是下面的样子。


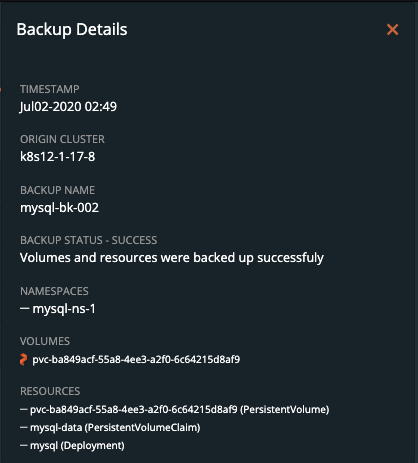


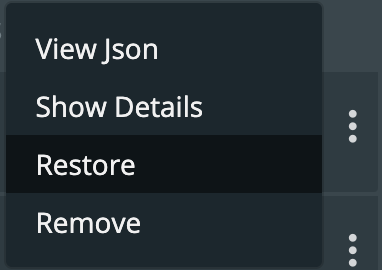
 找到你需要恢复的备份,选择菜单栏里的Restore。
找到你需要恢复的备份,选择菜单栏里的Restore。
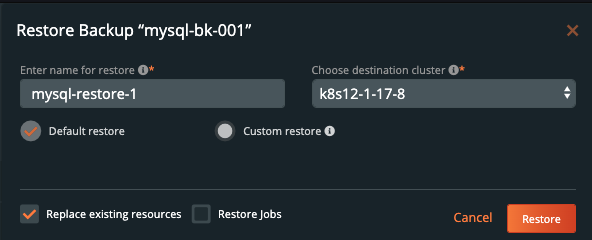
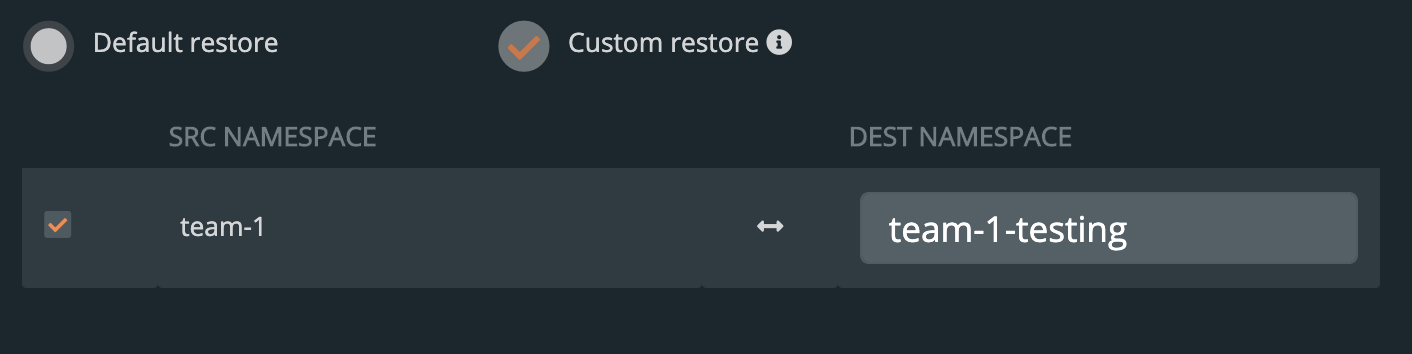































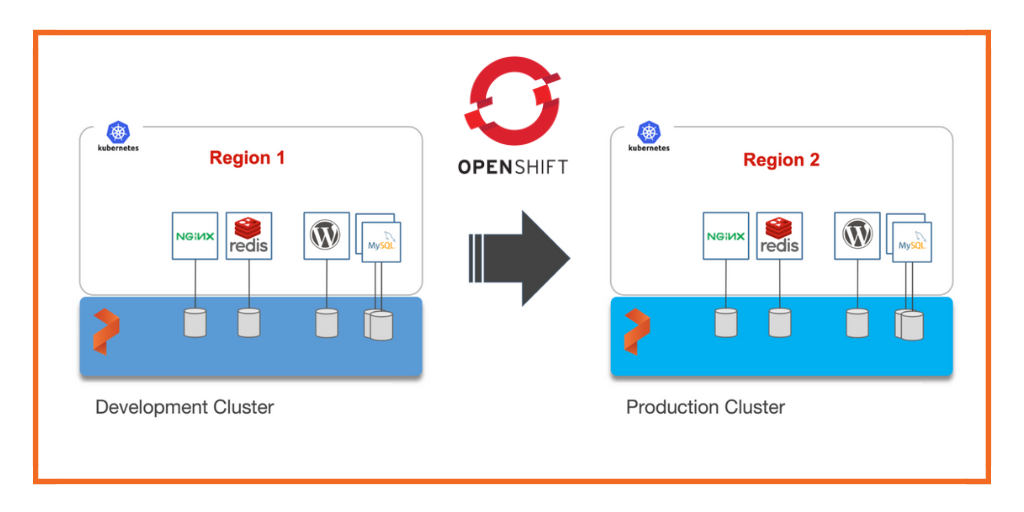
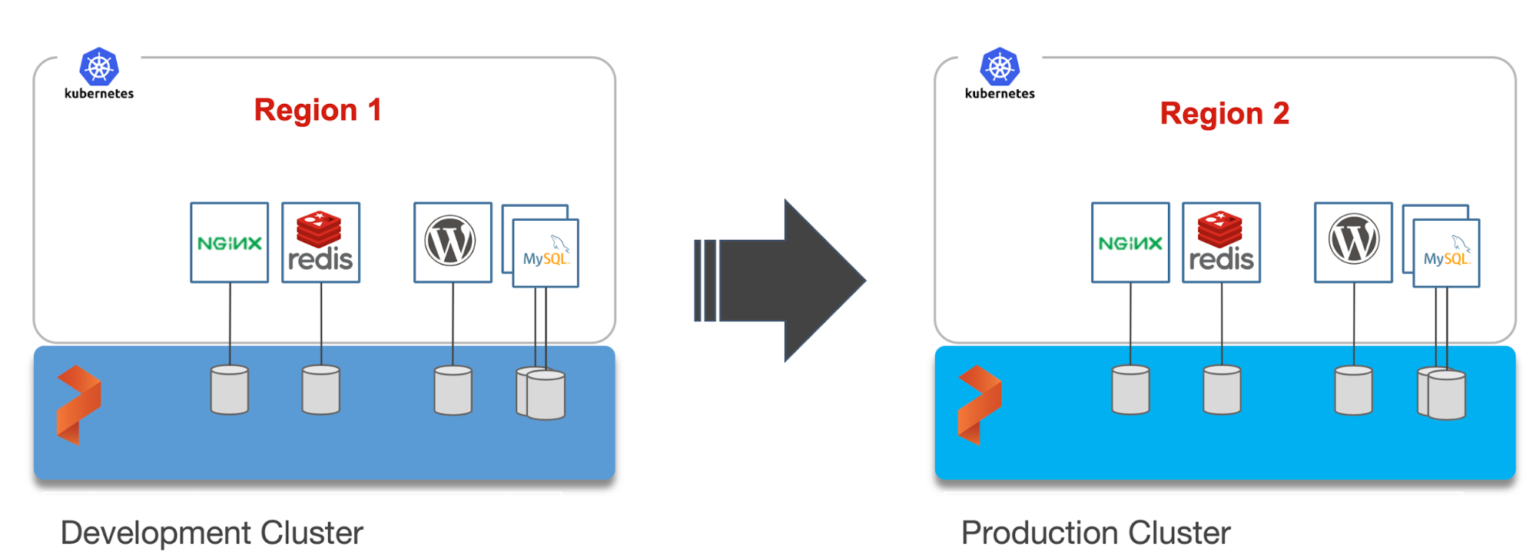
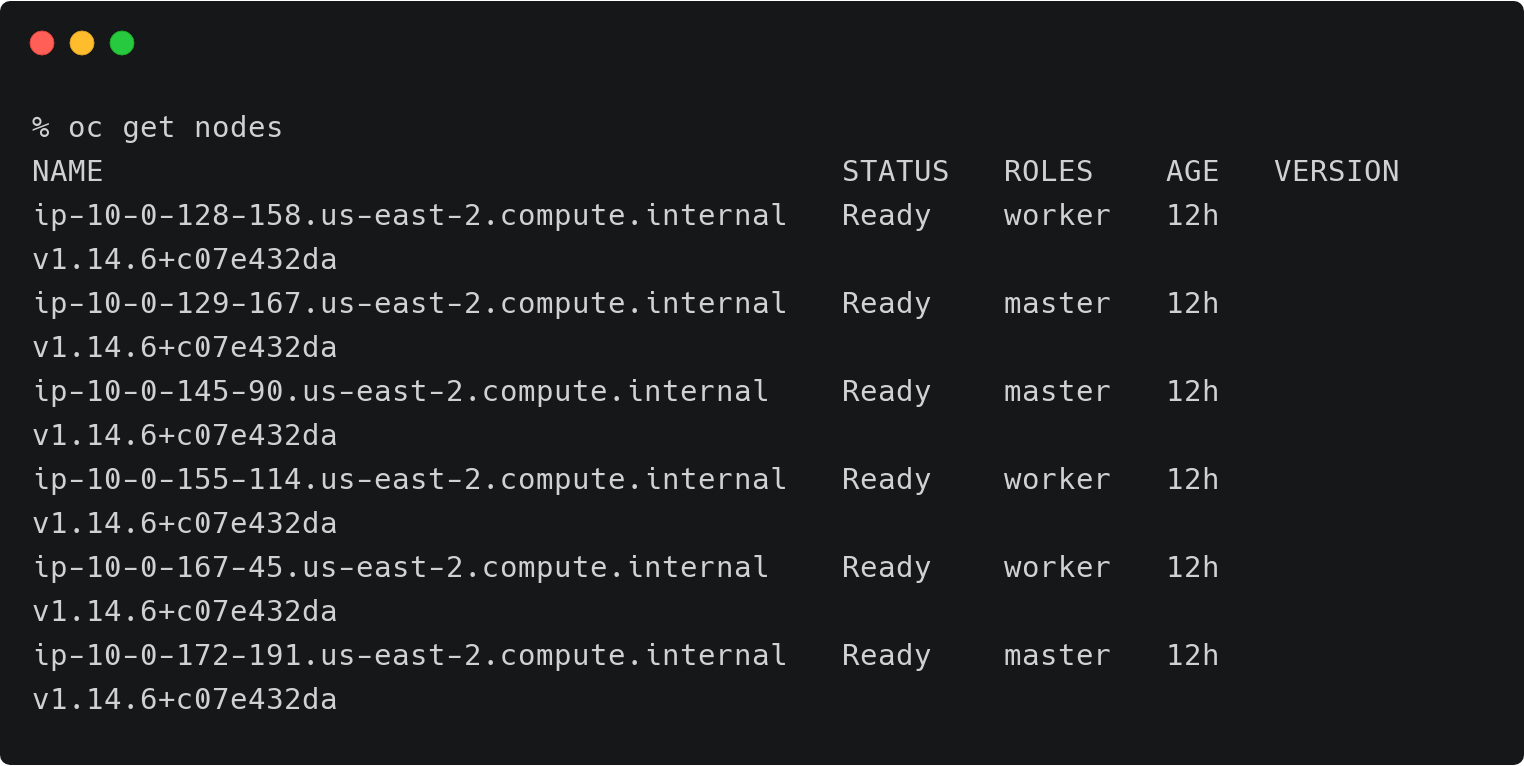
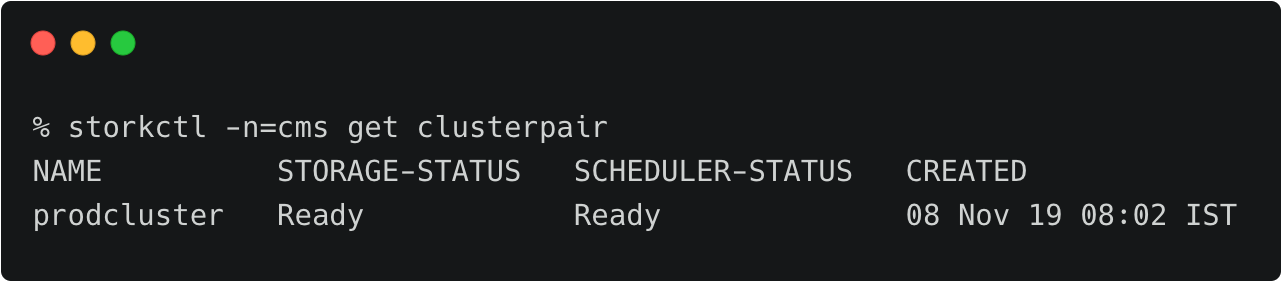
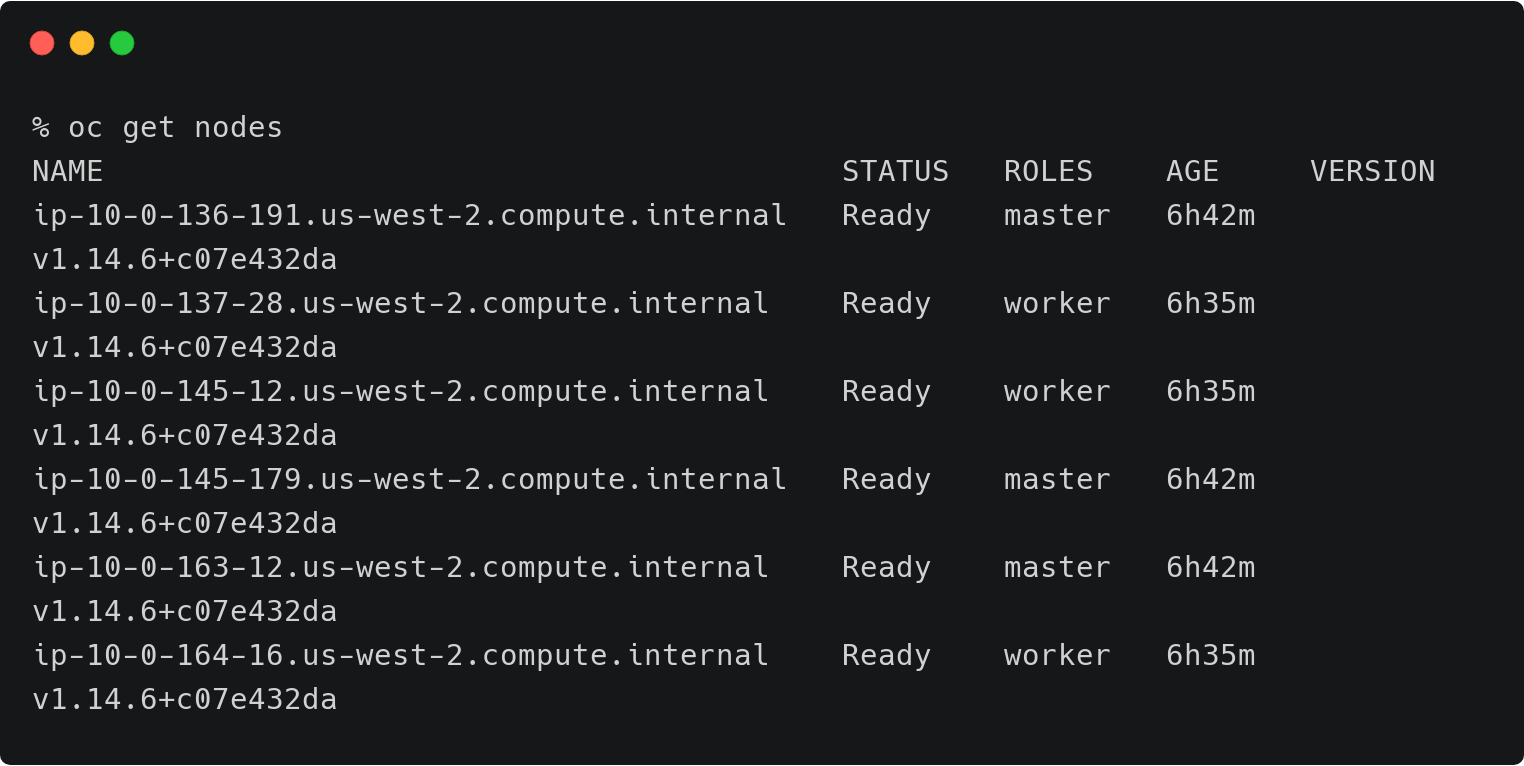
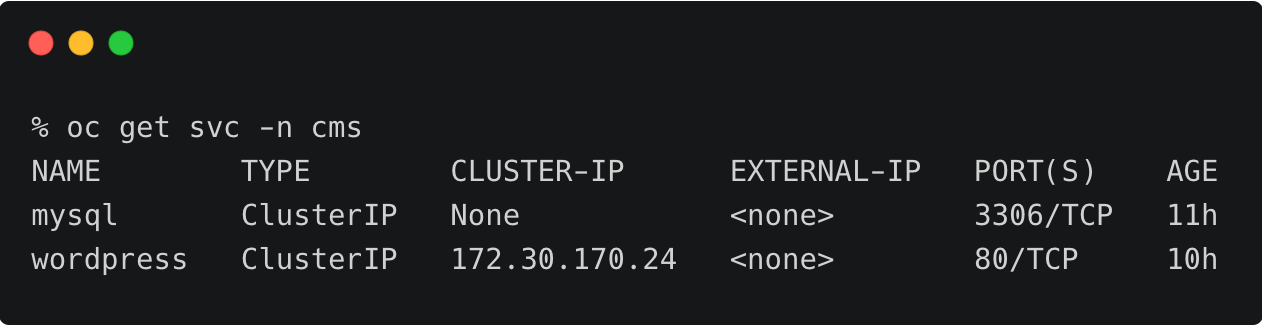
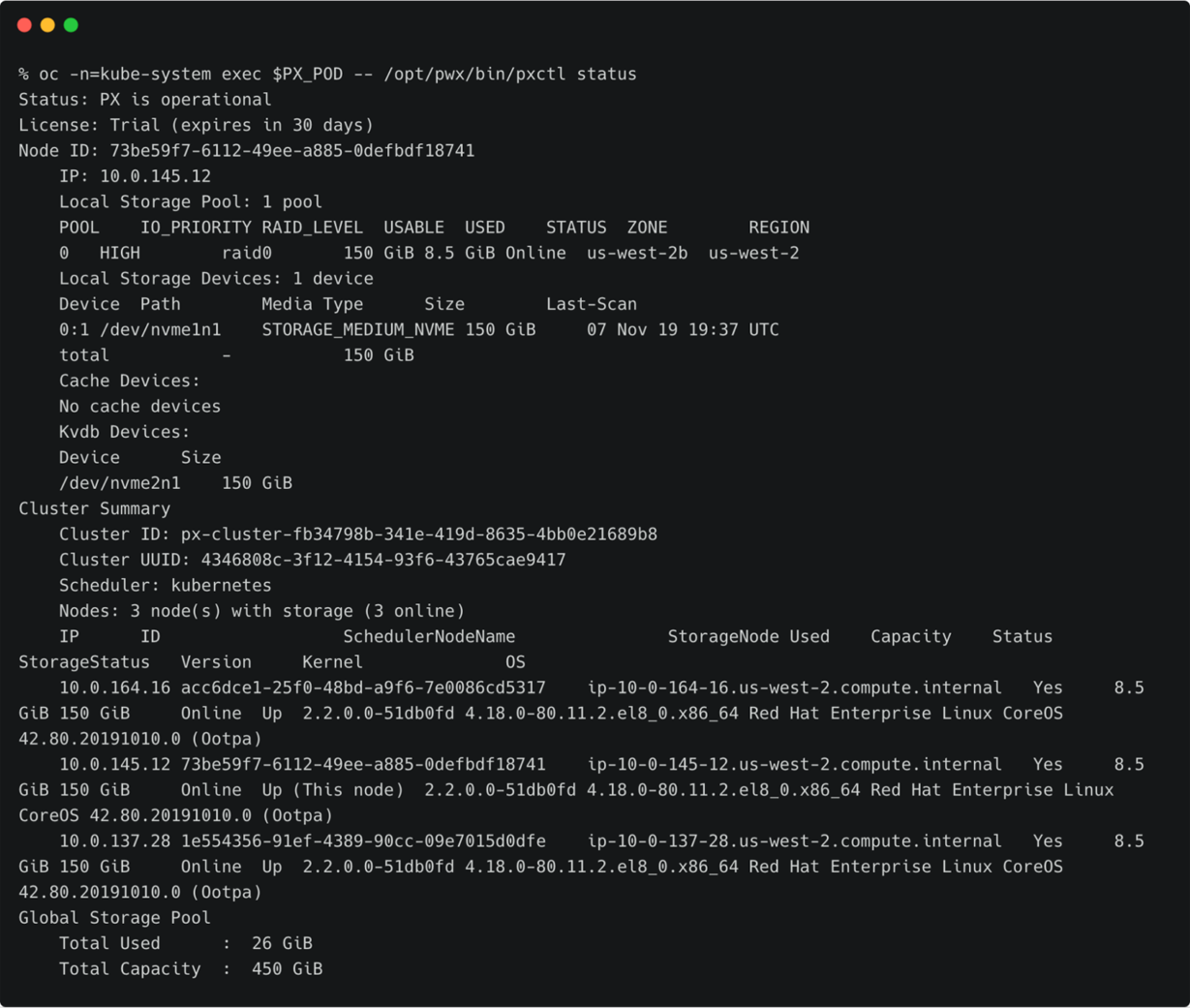
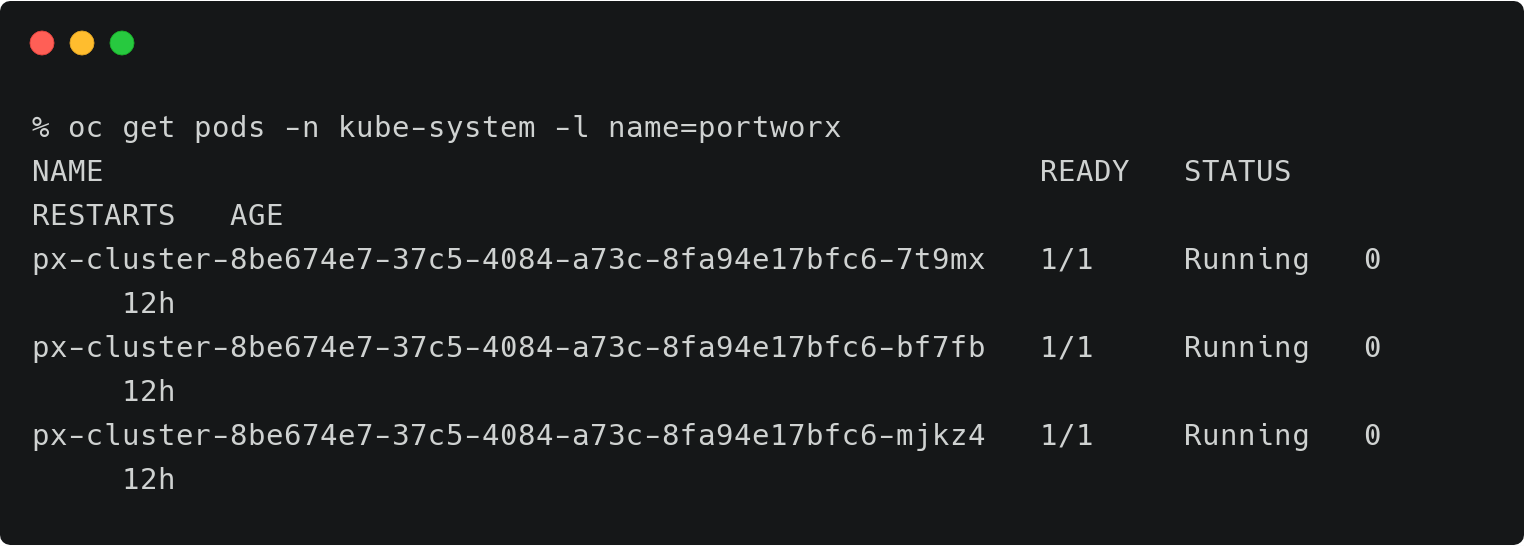 上面的OpenShift集群代表了运行在AWS东部区域(俄亥俄)的研发测试环境。
上面的OpenShift集群代表了运行在AWS东部区域(俄亥俄)的研发测试环境。

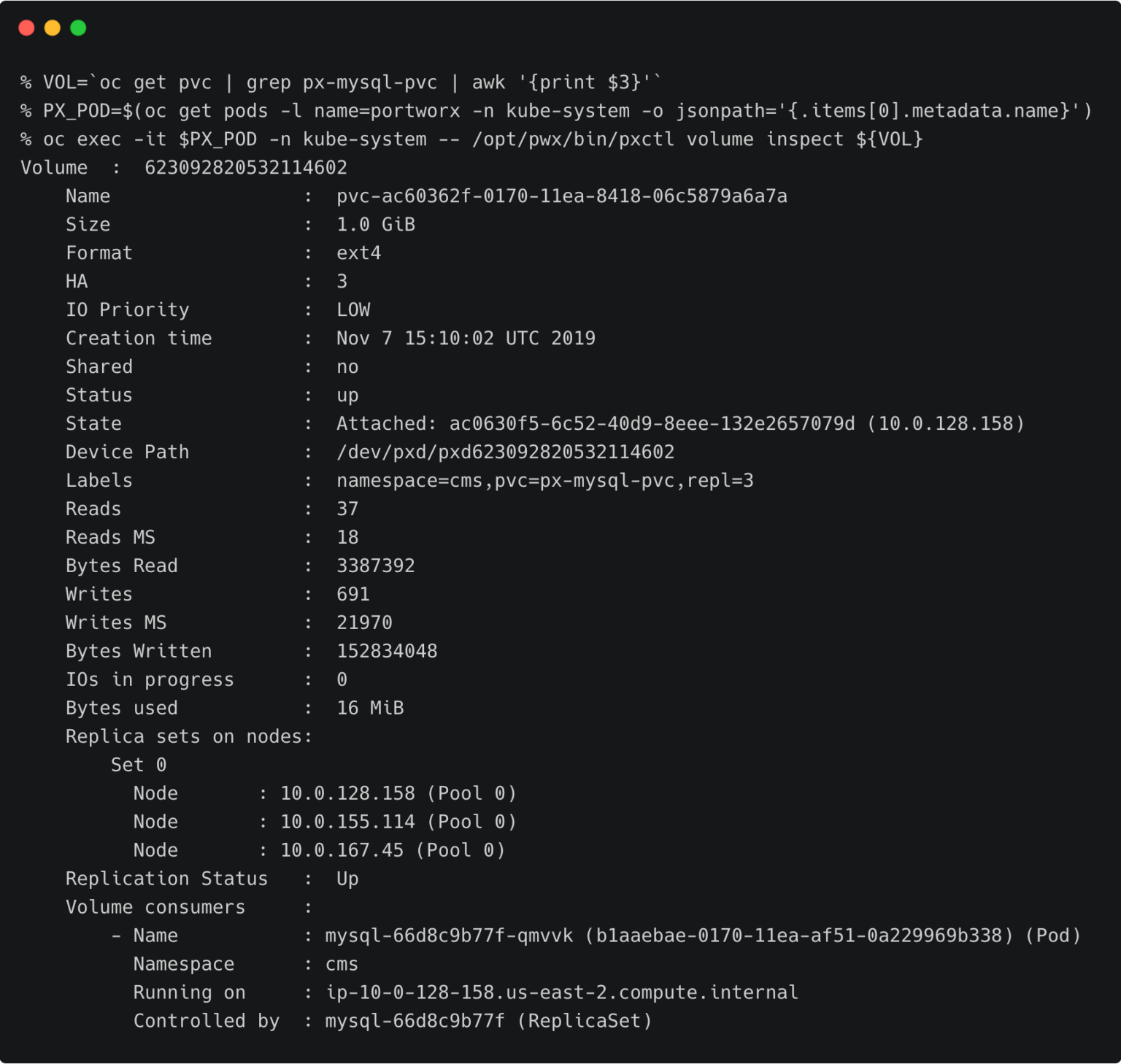

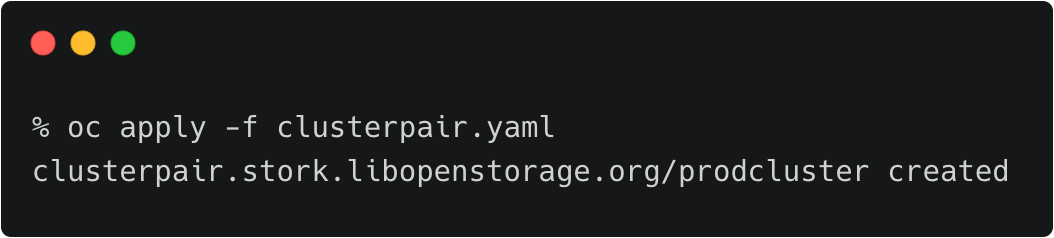
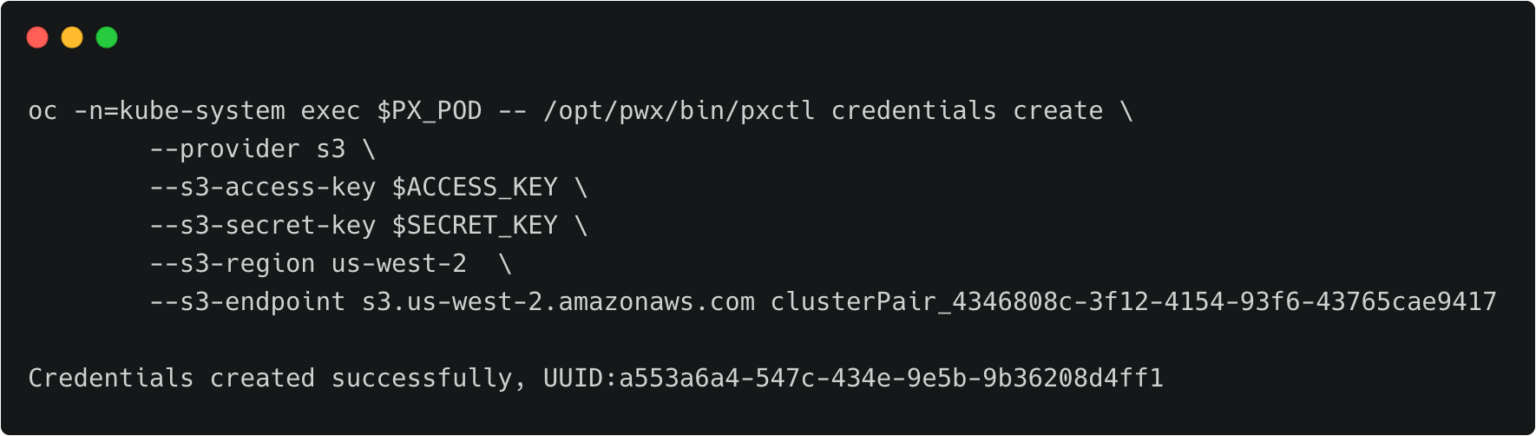 回到研发测试集群,重复操作来创建身份验证信息。
回到研发测试集群,重复操作来创建身份验证信息。