
一、环境准备
首先环境还是三台虚拟机,虚拟机地址如下
| IP 地址 | 节点 |
|---|---|
| 192.168.1.167 | master |
| 192.168.1.189 | node1 |
| 192.168.1.176 | node2 |
然后每台机器安装好 docker,至于 rpm 安装包版本下面介绍
二、说点正经事
2.1、安装包从哪来
官方的文档页面更新并不及时,同时他的 yum 源更新也很慢,再者…那他妈可是 Google 的服务器,能特么连上吗?以前总是在国外服务器使用 yumdownloader 下载,然后 scp 到本地,虽然能解决问题,但是蛋碎一地…最后找到了源头,如下
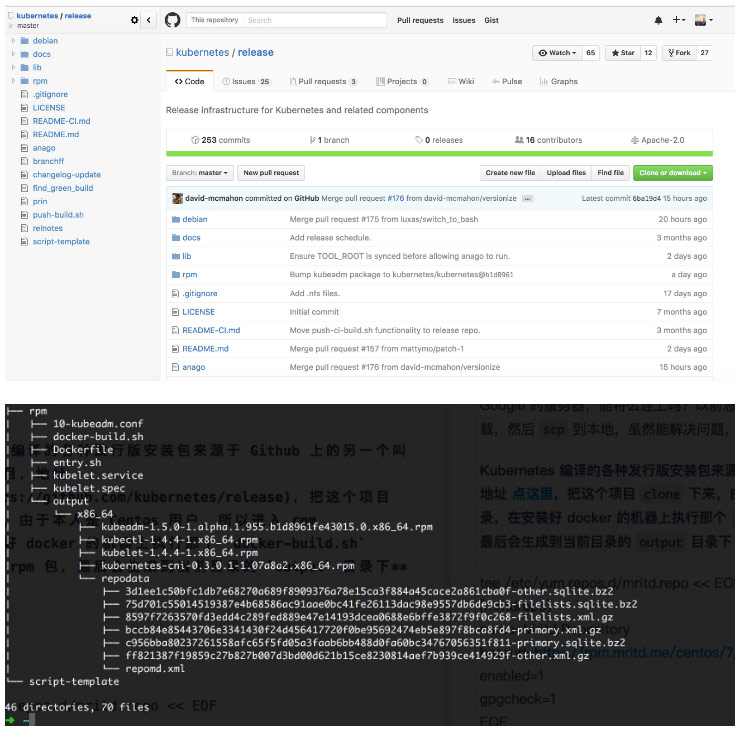
Kubernetes 编译的各种发行版安装包来源于 Github 上的另一个叫 release 的项目,地址 点这里,把这个项目 clone 下来,由于本人是 Centos 用户,所以进入 rpm 目录,在安装好 docker 的机器上执行那个 docker-build.sh 脚本即可编译 rpm 包,最后会生成到当前目录的 output 目录下,截图如下
2.2、镜像从哪来
对的,没错,gcr.io 就是 Google 的域名,服务器更不用提,所以在进行 kubeadm init 操作时如果不先把这些镜像 load 进去绝对会卡死不动,以下列出了所需镜像,但是版本号根据 rpm 版本不同可能略有不同,具体怎么看下面介绍
| 镜像名称 | 版本号 |
|---|---|
| gcr.io/google_containers/kube-discovery-amd64 | 1.0 |
| gcr.io/google_containers/kubedns-amd64 | 1.7 |
| gcr.io/google_containers/kube-proxy-amd64 | v1.4.1 |
| gcr.io/google_containers/kube-scheduler-amd64 | v1.4.1 |
| gcr.io/google_containers/kube-controller-manager-amd64 | v1.4.1 |
| gcr.io/google_containers/kube-apiserver-amd64 | v1.4.1 |
| gcr.io/google_containers/etcd-amd64 | 2.2.5 |
| gcr.io/google_containers/kube-dnsmasq-amd64 | 1.3 |
| gcr.io/google_containers/exechealthz-amd64 | 1.1 |
| gcr.io/google_containers/pause-amd64 | 3.0 |
这些镜像有两种办法可以获取,第一种是利用一台国外的服务器,在上面 pull 下来,然后再 save 成 tar 文件,最后 scp 到本地 load 进去;相对于第一种方式比较坑的是取决于服务器速度,每次搞起来也很蛋疼,第二种方式就是利用 docker hub 做中转,简单的说就是利用 docker hub 的自动构建功能,在 Github 中创建一个 Dockerfile,里面只需要 FROM xxxx 这些 gcr.io 的镜像即可,最后 pull 到本地,然后再 tag 一下
首先创建一个 github 项目,可以直接 fork 我的即可
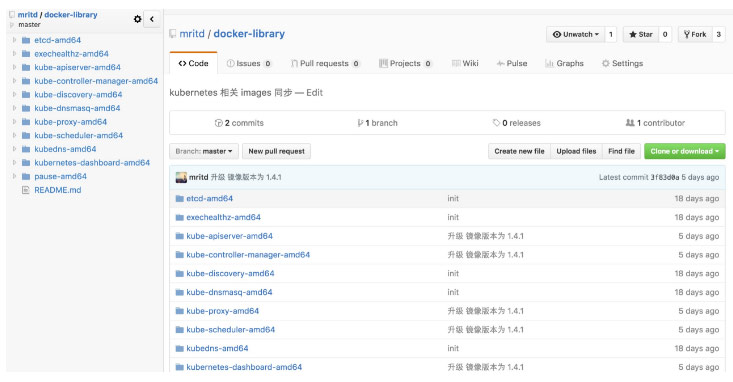
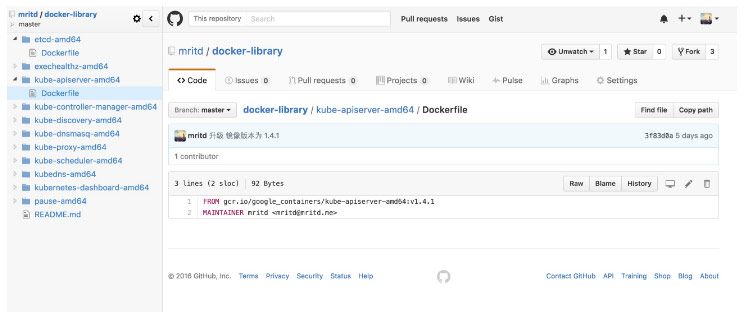
其中每个 Dockerfile 只需要 FROM 一下即可
最后在 Docker Hub 上创建自动构建项目
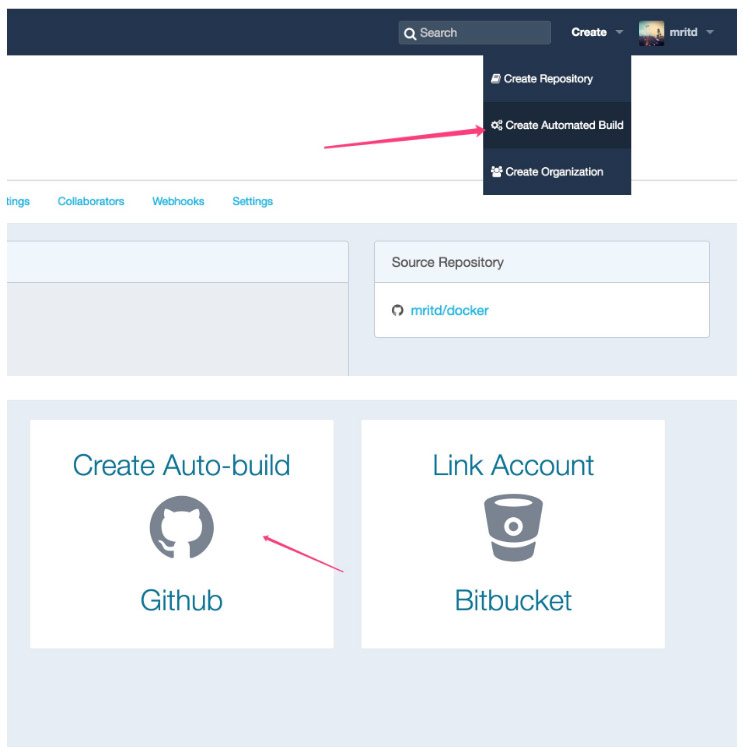
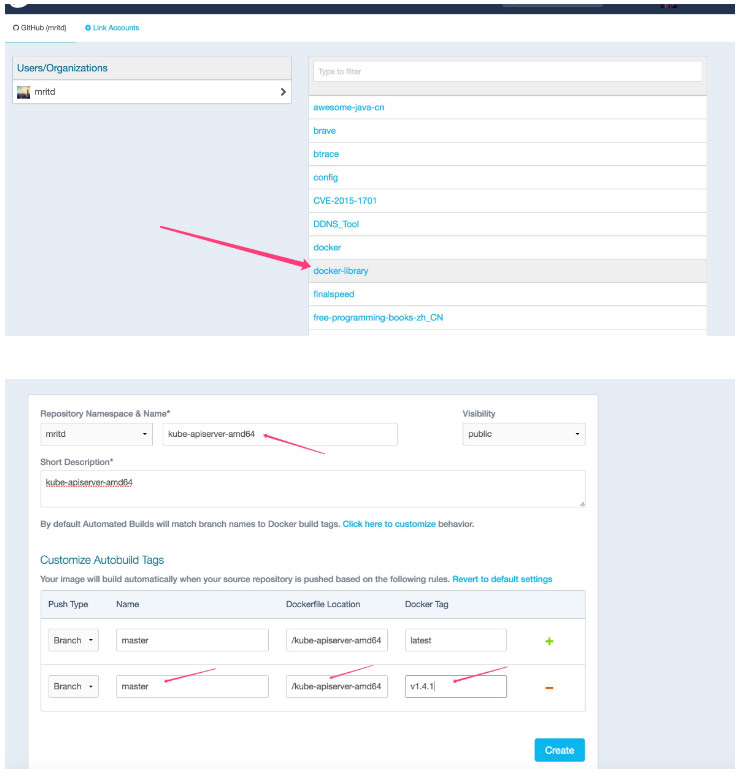
最后要手动触发一下,然后 Docker Hub 才会开始给你编译
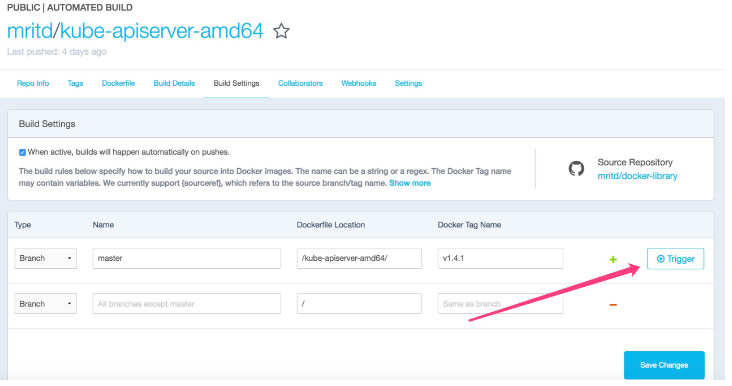
等待完成即可直接 pull 了
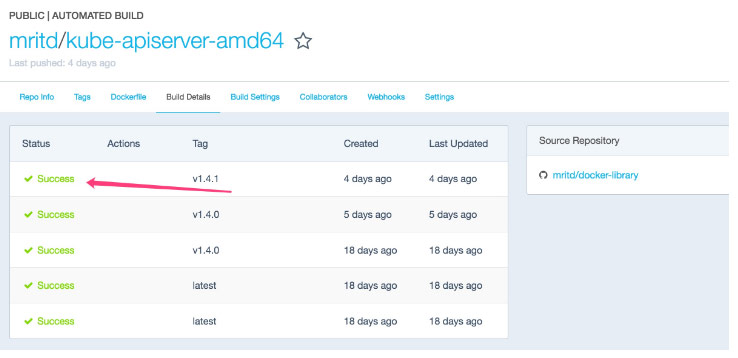
2.3、镜像版本怎么整
上面已经解决了镜像获取问题,但是一大心病就是 “我特么怎么知道是哪个版本的”,为了发扬 “刨根问底” 的精神,先进行一遍 kubeadm init,这时候绝对卡死,此时进入 /etc/kubernetes/manifests 可以看到许多 json 文件,这些文件中定义了需要哪些基础镜像

从上图中基本可以看到 kubeadm init 的时候会拉取哪些基础镜像了,但是还有一些镜像,仍然无法找到,比如kubedns、pause 等,至于其他的镜像版本,可以从源码中找到,源码位置是kubernetes/cmd/kubeadm/app/images/images.go 这个文件中,如下所示:
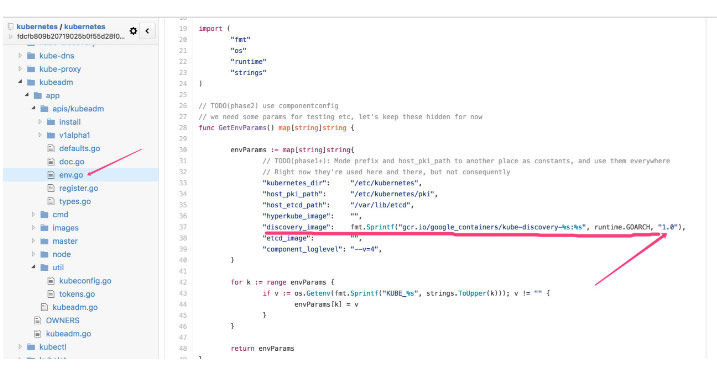
剩余的一些镜像,比如 kube-proxy-amd64、kube-discovery-amd64 两个镜像,其中 kube-discovery-amd64 现在一直是 1.0 版本,源码如下所示
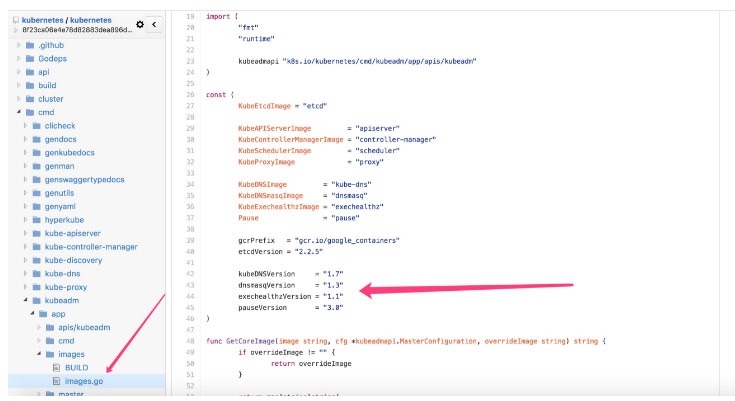
kube-proxy-amd64 则是一直跟随基础组件的主版本,也就是说如果从 manifests 中看到 controller 等版本是 v.1.4.4,那么 kube-proxy-amd64 也是这个版本,源码如下
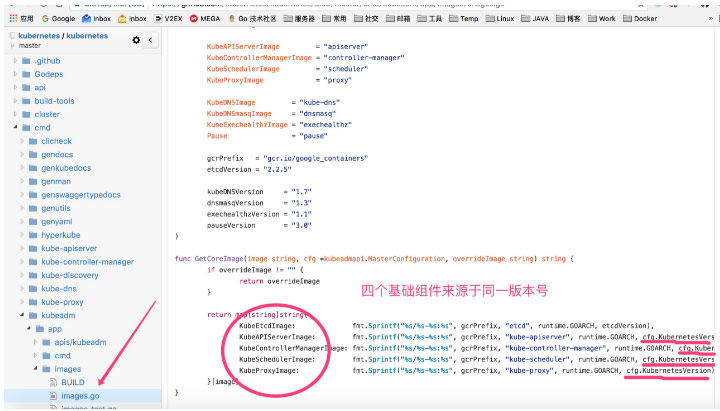
最后根据这些版本去 github 上准备相应的 Dockerfile,在利用 Docker Hub 的自动构建 build 一下,再 pull 下来 tag 成对应的镜像名称即可
三、搭建集群
3.1、主机名处理
经过亲测,节点主机名最好为 xxx.xxx 这种域名格式,否则在某些情况下,POD 中跑的程序使用域名解析时可能出现问题,所以先要处理一下主机名
# 写入 hostname(node 节点后缀改成 .node)
echo "192-168-1-167.master" > /etc/hostname
# 加入 hosts
echo "127.0.0.1 192-168-1-167.master" >> /etc/hosts
# 不重启情况下使内核生效
sysctl kernel.hostname=192-168-1-167.master
# 验证是否修改成功
➜ ~ hostname
192-168-1-167.master
3.2、load 镜像
由于本人已经在 Docker Hub 上处理好了相关镜像,所以直接 pull 下来 tag 一下即可,
images=(kube-proxy-amd64:v1.4.4 kube-discovery-amd64:1.0 kubedns-amd64:1.7 kube-scheduler-amd64:v1.4.4 kube-controller-manager-amd64:v1.4.4 kube-apiserver-amd64:v1.4.4 etcd-amd64:2.2.5 kube-dnsmasq-amd64:1.3 exechealthz-amd64:1.1 pause-amd64:3.0 kubernetes-dashboard-amd64:v1.4.1)
for imageName in ${images[@]} ; do
docker pull mritd/$imageName
docker tag mritd/$imageName gcr.io/google_containers/$imageName
docker rmi mritd/$imageName
done
3.3、安装 rpm
rpm 获取办法上文已经提到,可以自己编译,这里我已经编译好并维护了一个 yum 源,直接yum install 即可(懒)
# 添加 yum 源
tee /etc/yum.repos.d/mritd.repo << EOF
[mritdrepo]
name=Mritd Repository
baseurl=https://rpm.mritd.me/centos/7/x86_64
enabled=1
gpgcheck=1
gpgkey=https://cdn.mritd.me/keys/rpm.public.key
EOF
# 刷新cache
yum makecache
# 安装
yum install -y kubelet kubectl kubernetes-cni kubeadm
3.4、初始化 master
等会有个坑,kubeadm 等相关 rpm 安装后会生成 /etc/kubernetes 目录,而 kubeadm init 时候又会检测这些目录是否存在,如果存在则停止初始化,所以要先清理一下,以下清理脚本来源于 官方文档 Tear down 部分,该脚本同样适用于初始化失败进行重置
systemctl stop kubelet;
# 注意: 下面这条命令会干掉所有正在运行的 docker 容器,
# 如果要进行重置操作,最好先确定当前运行的所有容器都能干掉(干掉不影响业务),
# 否则的话最好手动删除 kubeadm 创建的相关容器(gcr.io 相关的)
docker rm -f -v $(docker ps -q);
find /var/lib/kubelet | xargs -n 1 findmnt -n -t tmpfs -o TARGET -T | uniq | xargs -r umount -v;
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd;
还有个坑,初始化以前记得一定要启动 kubelet,虽然你 systemctl status kubelet 看着他是启动失败,但是也得启动,否则绝壁卡死
systemctl enable kubelet
systemctl start kubelet
等会等会,还有坑,新版本直接 init 会提示 ebtables not found in system path 错误,所以还得先安装一下这个包在初始化
# 安装 ebtables
yum install -y ebtables
最后见证奇迹的时刻
# 初始化并指定 apiserver 监听地址
kubeadm init --api-advertise-addresses 192.168.1.167
完美截图如下
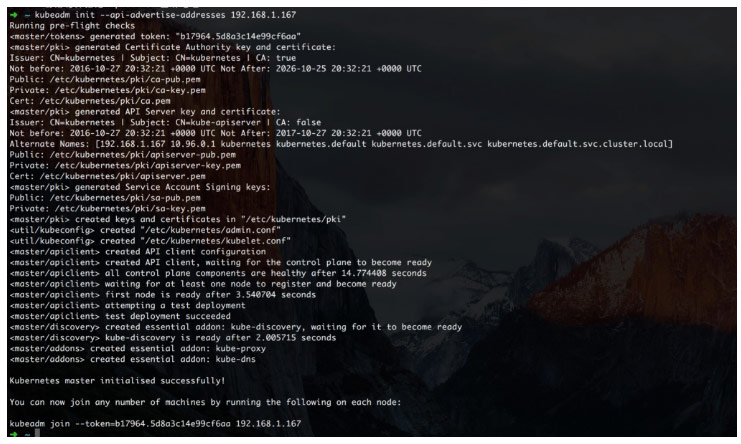
这里再爆料一个坑,底下的 kubeadm join --token=b17964.5d8a3c14e99cf6aa 192.168.1.167 这条命令一定保存好,因为后期没法重现的,你们老大再让你添加机器的时候如果没这个你会哭的
3.5、加入 node
上面所有坑大约说的差不多了,直接上命令了
# 处理主机名
echo "192-168-1-189.node" > /etc/hostname
echo "127.0.0.1 192-168-1-189.node" >> /etc/hosts
sysctl kernel.hostname=192-168-1-189.node
# 拉取镜像
images=(kube-proxy-amd64:v1.4.4 kube-discovery-amd64:1.0 kubedns-amd64:1.7 kube-scheduler-amd64:v1.4.4 kube-controller-manager-amd64:v1.4.4 kube-apiserver-amd64:v1.4.4 etcd-amd64:2.2.5 kube-dnsmasq-amd64:1.3 exechealthz-amd64:1.1 pause-amd64:3.0 kubernetes-dashboard-amd64:v1.4.1)
for imageName in ${images[@]} ; do
docker pull mritd/$imageName
docker tag mritd/$imageName gcr.io/google_containers/$imageName
docker rmi mritd/$imageName
done
# 装 rpm
tee /etc/yum.repos.d/mritd.repo << EOF
[mritdrepo]
name=Mritd Repository
baseurl=https://rpm.mritd.me/centos/7/x86_64
enabled=1
gpgcheck=1
gpgkey=https://cdn.mritd.me/keys/rpm.public.key
EOF
yum makecache
yum install -y kubelet kubectl kubernetes-cni kubeadm ebtables
# 清理目录(没初始化过只需要删目录)
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd;
# 启动 kubelet
systemctl enable kubelet
systemctl start kubelet
# 初始化加入集群
kubeadm join --token=b17964.5d8a3c14e99cf6aa 192.168.1.167
同样完美截图
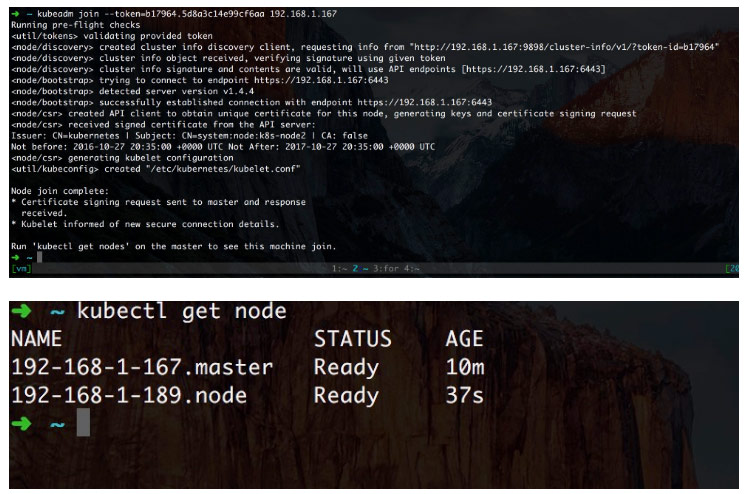
3.6、部署 weave 网络
再没部署 weave 时,dns 是启动不了的,如下
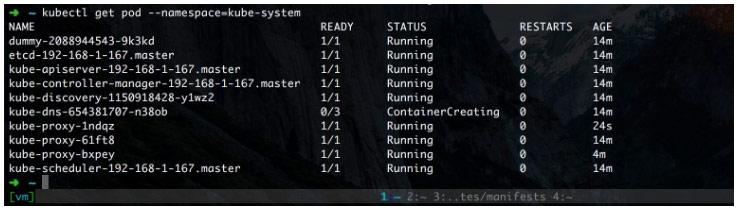
官方给出的命令是这样的
kubectl create -f https://git.io/weave-kube
本着 “刨根问底挖祖坟” 的精神,先把这个 yaml 搞下来
wget https://git.io/weave-kube -O weave-kube.yaml
然后同样的套路,打开看一下镜像,利用 Docker Hub 做中转,搞下来再 load 进去,然后 create -f就行了
docker pull mritd/weave-kube:1.7.2
docker tag mritd/weave-kube:1.7.2 weaveworks/weave-kube:1.7.2
docker rmi mritd/weave-kube:1.7.2
kubectl create -f weave-kube.yaml
完美截图
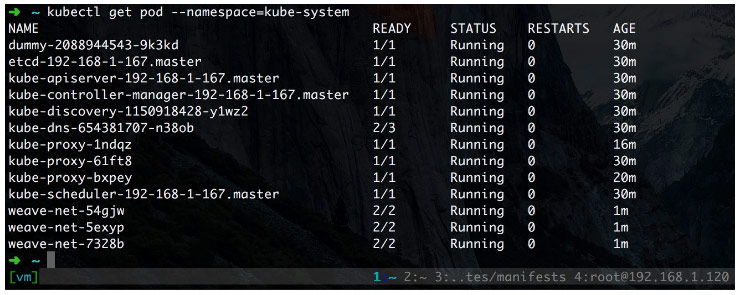
3.7、部署 dashboard
dashboard 的命令也跟 weave 的一样,不过有个大坑,默认的 yaml 文件中对于 image 拉取策略的定义是 无论何时都会去拉取镜像,导致即使你 load 进去也无卵用,所以还得先把 yaml 搞下来然后改一下镜像拉取策略,最后再 create -f 即可
wget https://rawgit.com/kubernetes/dashboard/master/src/deploy/kubernetes-dashboard.yaml -O kubernetes-dashboard.yaml
编辑 yaml 改一下 imagePullPolicy,把 Always 改成 IfNotPresent(本地没有再去拉取) 或者Never(从不去拉取) 即可
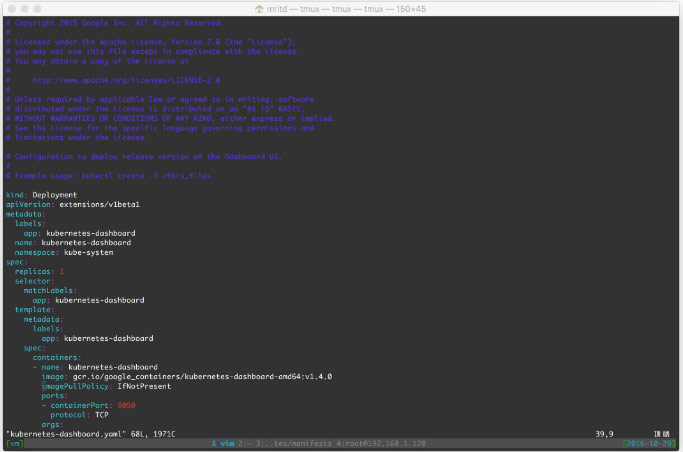
最后再利用 Dokcer Hub 中转,然后创建(实际上 dashboard 已经有了 v1.4.1,我这里已经改了)
kubectl create -f kubernetes-dashboard.yaml
截图如下
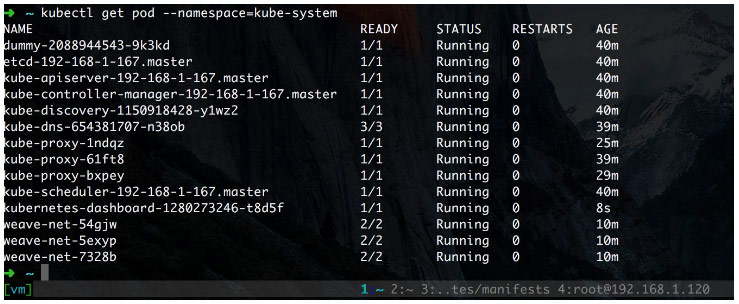
通过 describe 命令我们可以查看其暴露出的 NodePoint,然后便可访问
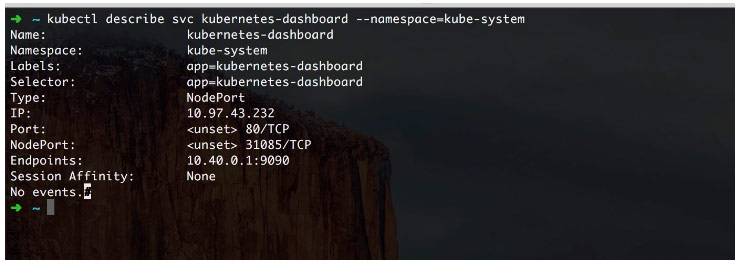

四、其他的一些坑
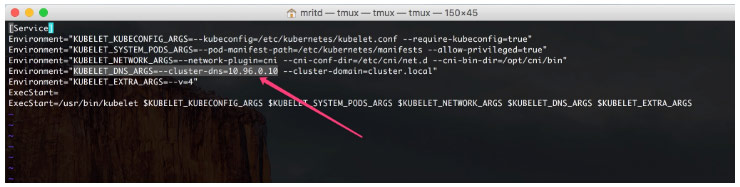
还有一些其他的坑等着大家去摸索,其中有一个是 DNS 解析错误,表现形式为 POD 内的程序通过域名访问解析不了,cat 一下容器的 /etc/resolv.conf发现指向的 dns 服务器与 kubectl get svc --namespace=kube-system 中的 kube-dsn 地址不符;解决办法就是 编辑节点的/etc/systemd/system/kubelet.service.d/10-kubeadm.conf 文件,更改 KUBELET_DNS_ARGS 地址为 get svc 中的 kube-dns 地址,然后重启 kubelet 服务,重新杀掉 POD 让 kubernetes 重建即可

那个我再问一句 能给我留个名吗?尊重一下版权好么?
非常抱歉,刚在后台去添加时发现之前是有您名字及来源,可能因为前些天网站调整删除了部分字段引起。
非常抱歉,刚在后台去添加时发现之前是有您名字及来源,可能因为前些天网站调整删除了部分字段引起。
妈蛋 确实kubeadm卡死了