
今天我跟大家讲的是 Kubernetes 在网易的一些实践,目的是抛砖引玉,看看大家在这个方向有没有更好的实践方法。简单介绍一下网易云。网易云是从最早 Kubernetes 1.0 开始做起,后面 1.3 版本一直用了很长的时间。最近,对内部业务提供了 1.9 的版本。
容器云平台架构
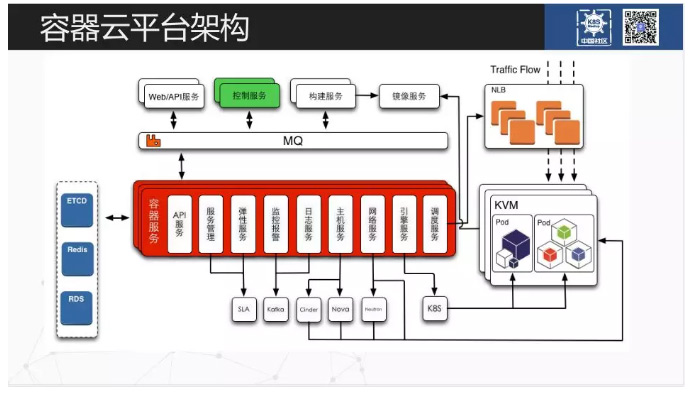
这是网易公有云的一个容器平台架构,可以简单的分为几个部分。最底下的是基础设施层。这个是由 laaS 来负责,在 laaS 以上,是容器和 Kubernetes 的调度层。因为 laaS 会去做其它的公共系统(比如认证、计费)。NCE(Netease Container Engine,容器引擎)这层服务,是容器和 Kubernetes 调度上面的一个抽象层,它上面是为用户提供前端的 Web 和 API 服务。
我们也是 Kubernetes 用户,在为用户提供 Kubernetes 服务的同时,也在解决我们的问题。在容器服务上,2016 年就已有几十个业界知名的服务微服务的工具,一个是 Spring Cloud,一个是 Kubernetes。在我们开发团队中,也会去想用什么样的技术更适合我们。Spring Cloud 和 Kubernetes 都是一个利器。它们面向的用户和解决思路是不一样的。Spring Cloud 更多的是面向开发者们,尤其是 Java 开发者,他们是从代码级别去考虑微服务是怎么去设计的。开发者们需要去处理,比如注册、环境配置怎么拿到?对于他们来说,除了做业务开发,他还要关心一些业务之外的东西。
Kubernetes 更多是面向 DevOps,它是希望通过提供一个平台,一个通用性的方案把微服务中间需要处理的细节放在平台上解决。不用去关注服务发现和 DNS 这些东西,就比如说在 Spring Cloud 里面的服务发现。你需要代码去拿这些信息。
但是在 Kubernetes 里,你只需要去创建一个服务,然后访问这个 Kubernetes 服务,你不用去关心后台策略是怎么做、服务是怎么发现、请求是怎么传到后面的 Pod。所以它是从不同的层面去解决这个问题的。因为 Spring Cloud 和 Kubernetes,不是一个完全对应的产品。作为微服务的一些基础要点,它们是有自己不同的解决方案。这里是做了一个相对的比较。你会发现无论是 Spring Cloud,还是 Kubernetes,其实都有他自己的方式去解决问题。
Spring Cloud or Kubernetes?

我们开发团队做了一些调研,Kubernetes 加 Docker,我们可以比较好的解决部分问题。有一些问题 Kubernetes 自己可以解决,但用起来不是很方便。还有一些只能用第三方工具,或者自己的方式来解决。比如说像监控,我们就是用第三方工具。比如说 ELK 是用 Grafana 去做监控。分步式追踪,我们做了一个 APM 分布步式追踪。

比较来看,如果做微服务,并不是说我只选 Kubernetes,或是 Spring Cloud,而是把它们结合起来用,更能发挥他们各自的优势。再比如服务发现、负载均衡、高可用、调度、部署这部分,我们是用 Kubernetes。比如故障隔离,我们用 Hystrix 去做进程内隔离,但是做进程间隔离,是通过 Kubernetes 的资源配额去做。比如像配置问题,Docker 能解决应用和运行环境等问题。
一般情况,我们会分为开发环境、测试环境、预发布和线上环境。不同的环境,它的配置是不一样的。如果是用 Kubernetes ConfigMap,它不能实时生效,所以我们用的 Disconf 配置中心。要把微服务做好,你要根据自己的实际情况,去选择适合的产品和技术,还要做一些基于第三方的开源工具和开发。
除了微服务这块,在我们自己的生产测试环境中,我们也用到了亲和性和反亲和性的特性,比如说一个很常见的需求,当我有些关键的应用模块需要去做储备部署,我需要去测试。当主模块坏掉后,我们通过它的亲和性去做,比如我们用 Node 和 Pod 的亲和性和反亲和性去做,中间会给你一些表达式去匹配规则。
这里面有两种模式,一种是 Hard 模式,一种是 Soft 模式。Hard 模式是你必须满足我的要求,它还有一个特性,在调度期间,我必须要满足它的要求。如果我已经调度成功了,后面的标签我没有改动,还是要让 Pod 正常运行。Soft 模式,我如果满足你表达式匹配的资源,那我就优先满足你。如果没有,那你按照调度器的分配继续进行下去。
在我们的环境里,对 Node 打标签。比如说有两台,一台是 ci1,一台是 ci2,在文件中进行配置。比如一个节点,它可以是 ci1 或者 ci2,它把 Pod 调度到 Node 上,但是这两个应用跟储备又不能在一起,它们必须要分开。我们在应用名字设置了一个 Pod 反亲和性。如果发现这个 Pod 已经在一台上,那它只能被调动到另一台上。我们可以用同样的一个配置去部署这样一个应用,不需要去分两个配置。而且我们不需要去管底层的 Node 资源是怎么样的,或者说我们要靠其它的一些灵活方式去做反亲和性配置。
网易云有一个现存的监控系统。它对于数据的要求,有一些规范。我们专门做了一个 Agent。这个 Agent,就是为了它从 cAdvisor 上挖数据,上报给监控系统。一方面,社区对模块是有更新的,我们不想对它有新动作。如果你做了自己的逻辑在里面,而社区更新了,在此之后就很难处理这件事。我们想把社区和我们制定一些东西,或者说我们跟内部其它系统去做的相关适配,可以去解耦。
通过 cAdvisor,做一个 DaemonSet。我们在每一个节点上,都会部署一个 Agent,它会去拉 cAdvisor 的数据。如果 Agent 在后面社区版本里进行了数据更新。我们只需要做一些相对应的适配,重新更新与部署。对我们来说,维护会非常简单。另外一个,我们的外部客户可能会有些非社区原生的需求。
比如说他要在界面上做保存镜像的操作。这些非原生的需求,我们会在 Node 端有一个容器服务的 Agent,它去监控这些命令。如果是这些非原生的需求,是由 Agent 来处理。我们就可以看到,DaemonSet 可以简化一些部署的难度。在特定的场景下,它可以在我的集群里,对所有的 Node,或是部分的 Node 部署一个 Agent。
如果你更新且把镜像重新做好,重新拉一个镜像就可以。所以说非常适合这种类似于获取日志,长期在 Node 上做工作的事情。而且,它可以把一些定制化需求和社区原生需求解耦,这样既能跟上社区更新,又可以根据自己的系统和业务产品,去做一些特别的适配。
因为网易云本身提供有关 Node/PV 的服务,所以在这一块又和私有云有点不一样。因为像社区原生的 Kubernetes,它更多的是面向私有云市场。像很多公有云厂商,提供的 Kubernetes 服务,也是用户申请后,它给你一套完整的 Kubernetes 集群。这个集群是由用户自己来维护的。
但是网易云目前所提供的 Kubernetes 服务,有点像 AWS 的 Fargate 的模式,所有租户都在这整个公有云中,都是在同一个 Kubernetes 集群下管理。租户是对 Kubernetes 没有访问权限的,他只能访问平台暴露出来的,比如 Deployment、Service、Ingress、Statefulset、Endpoint 等对象,用户只能使用这些资源。
K8S 公有云实践

公有云和私有云的场景存在不同。私有云没有足够的概念。在企业内部,只是不同部门或者不同项目,但是资源可能是全局可见的。但在公有云上就不一样。因为公有云是有租户的,我匹配的这些资源不是全局共享的,因为你不用关心这种安全性问题。但是在公有云上,用户很多,租户很多,租户之间不需要去做隔离。
我们的容器平台和底层的 laaS 层是做耦合。它不是原生的 Kubernetes 形态,像主机,我们是由 laaS 提供一个虚拟型或尾机给容器做一个 Node。硬盘,我们是由 laaS 层存储一个后端硬盘,网络是通过 VPC 网络,所以说租户与租户之间是隔离的。

我们以前的版本是一对一的,到了新的版本后每个租户可以去创建多个 Namespace。像认证、授权、也是在租户这边安排。还有一个像 Kubernetes ,它的 Node 资源,是预分配的,你在创建集群时,就要提前把这些 Node 资源准备好,它才可以调度。但是这个场景在公有云就不合适。因为你无法预估用户需要多少资源,没办法根据这个去部署。
如果你部署多了会浪费。你部署少了,资源可能就不够。我们想的一种办法就是用类似于半实时的预备资源方式。它不完全是你申请时才给你创建的一个 Node。如果是这样,对用户来说,体验会不好。所以我们的办法就是提前准备一个资源池,把临时的 Node 创建出来后不给它联网。它在临时资源池里,我们会维持一个水平。
此时如果一个用户,他申请了资源,我们就把创建好的 Node 做初始化,放在这个租户的 VPC 网络里。把信息给到他,他就可以去做第二步。一方面,我们不需要去预备更强大的资源;另一方面,我们在用户申请时,时间响应会少一些。
当用户把资源池里的 Node 请求消费了一部分,我们会根据消耗水平在后台补一些新的资源,它一般会维持这么一个规模。在一般情况下,没有特别多的高并发,或者说在很多大规模部署情况下,我们是能减少用户的等待时间又不会占用太多的底层资源,这是我们对这块的一个处理方式。
为什么要做系统优化呢?有这几个方面的原因。最核心的是为了省钱,网易云需要支撑很多内部业务,每个业务都会有自己的一套资源群,而做高可用功能会占用很多资源。所以我们希望有能够管理所有租户的资源。面向用户的产品,也需要这样的需求。所以说我们面向多个团体,必须要保证当客户有具体的资源申请时,性能可以满足用户需求。
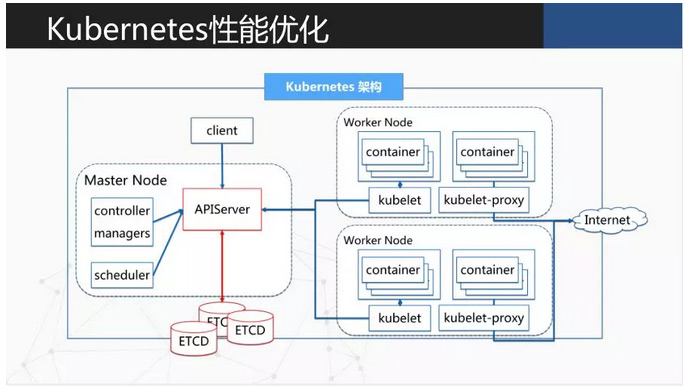
社区从 1.0 的 100 个 Node 到 1.6 的 5000 个 Node。虽然数量已经增加了很多但可能还不够。我们是希望一个集群能做到 3 万个 Node,所以我们在这里做了很多东西。但在 Kubernetes 的架构里,它所有的请求都是通过 API Server,然后去做一些查询、访问,再到 etcd 做产品。etcd 就是一个瓶颈,而且 etcd 本身比较缺少水平扩展能力,所以需要做一些优化。
当你规模加大后,在你做一些规则时就会碰到一些基本问题。我们是在 Controller 端,做一个自己的 Controller。它是和我们刚才说的 laaS 服务做一些交互,申请一个 Node,把网络打造在 Node 上,去创建 Pod。我们在前面又放了一层 HAProxy,做一些负载均衡。
K8S 性能优化
举个例子,如果你是社区原生方式,比如说你有 1 万个 Node,就可以创建 1 万个 Service,因为它是全局的可以互访,当你创建的规则是一万乘一万时,每个节点都会有这么多的规则。可想而知,你的性能就会很差。
对于公有云来说,因为我们是做租户隔离,所以说它不需要把所有的规则在每个 Node 上都去设一遍。因为我的租户是一个 VPC,需要在这个 VPC 上设用户自己的规则。我不用去设置别的租户 Node 上的规则。在每个租户里,他的 Node 规则很少。即使你再次设置规则也没有关系。
在后端存储,我们也是对 etcd 集群,就像 MySQL 一样,做类似分库的部署。我们会根据不同的对象、Node、RS、Pod,不同对象去分不同的多个 etcd 集群,减轻单个 etcd 集群的压力。其它做了一些调优,比如底层,我们用了 SSD,去做一些快照。在之前我们也考虑过是否有其它更好的 KV 存储方式,后来从 etcd 2 到 3 后,在性能上解决了不少问题,尤其是 etcd 3,它批量的消息推送效率比以前 2 版本要高了很多。
比如说底层的网络,我们的 laaS 层网络是基于 OVS+vxlan 做的,而没有用 Calico 等业界的一些方案,网络上,我们要提供 VPC 的安全隔离;性能上,我们测试下来的网络优化,也比一些开源的方式好一些。所以我们把这部分放到云底层去做。我们的容器平台,不需要关心底层是什么样,它只需要对接这些网络层,相当于接口。它需要申请资源,申请下来就可以了。
结语
以上这些是当前网易云对 Kubernetes 的一些实践和体会,随着用户越来越多的了解 Kubernetes 和容器技术所带来的好处,以及这些技术和生态的更新和演进,未来 Kubernetes 和容器也会有越来越多的潜力被开发出来。

文章来源:K8sMeetup中国社区

登录后评论
立即登录 注册