
简介
整体概括
本文章主要介绍如何全面监控k8s
- 使用metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等
- 使用prometheus-operator部署prometheus,存储监控数据
- 使用kube-state-metrics收集k8s集群内资源对象数据
- 使用node_exporter收集集群中各节点的数据
- 使用prometheus收集apiserver,scheduler,controller-manager,kubelet组件数据
- 使用alertmanager实现监控报警
- 使用grafana实现数据可视化
prometheus-operator简介
prometheus-operator是一个整合prometheus和operator的项目,prometheus是一个集数据收集存储,数据查询,数据图表显示于一身的开源监控组件。operator是由coreos开源一套在k8s上管理应用的软件,通过operator可以方便的实现部署,扩容,删除应用等功能。
prometheus-operator利用k8s的CustomResourceDefinitions功能实现了只需要像写原生kubectl支持的yaml文件一样,轻松收集应用数据,配置报警规则等,包含如下CRDs :
- Prometheus 用于部署Prometheus 实例
- ServiceMonitor 用于配置数据收集,创建之后会根据DNS自动发现并收集数据
- PrometheusRule 用于配置Prometheus 规则,处理规整数据和配置报警规则
- Alertmanager 用于部署报警实例
安装
环境说明
收集kube-controller-manager,kube-scheduler数据,需要配置组件监听0.0.0.0地址
二进制安装启动时添加如下参数 –address=0.0.0.0
如果使用kubeadm启动的集群,初始化时加入如下参数
controllerManagerExtraArgs: address: 0.0.0.0 schedulerExtraArgs: address: 0.0.0.0
如果是已经启动之后的集群,可以使用如下命令修改
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-controller-manager.yaml sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-scheduler.yaml
收集kubelet相关数据时需要配置kubelet使用如下认证方式。使用kubeadm默认情况下已经开启
--authentication-token-webhook=true --authorization-mode=Webhook
部署metric-server
# 下载 mkdir k8s-monitor && cd k8s-monitor git clone https://github.com/kubernetes-incubator/metrics-server.git # 修改配置(当前版本有bug) sed -ri 's@gcr.io/google_containers/metrics-server-amd64:(.*)@mirrorgooglecontainers/metrics-server-amd64:\1@g' metrics-server/deploy/1.8+/metrics-server-deployment.yaml sed -ri 's@--source=kubernetes.summary_api:.*@--source=kubernetes.summary_api:https://kubernetes.default?kubeletHttps=true\&kubeletPort=10250\&insecure=true@' metrics-server/deploy/1.8+/metrics-server-deployment.yaml # 部署 kubectl create -f metrics-server/deploy/1.8+/ # 查看状态 kubectl get pods -n kube-system # 测试获取数据 # 由于采集数据间隔为1分钟 # 等待数分钟后查看数据 NODE=$(kubectl get nodes | grep 'Ready' | head -1 | awk '{print $1}') METRIC_SERVER_POD=$(kubectl get pods -n kube-system | grep 'metrics-server' | awk '{print $1}') kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes kubectl get --raw /apis/metrics.k8s.io/v1beta1/pods kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/$NODE kubectl top node $NODE kubectl top pod $METRIC_SERVER_POD -n kube-system
下载相关部署文件
git clone https://github.com/mgxian/k8s-monitor.git cd k8s-monitor
部署prometheus-operator
# 创建 namespace kubectl apply -f monitoring-namespace.yaml # 部署 kubectl apply -f prometheus-operator.yaml # 查看 kubectl get pods -n monitoring kubectl get svc -n monitoring kubectl get crd
部署k8s组件服务
# 部署 kubectl apply -f node_exporter.yaml # 查看 kubectl get pods -n monitoring kubectl get svc -n monitoring
部署kube-state-metrics
# 部署 kubectl apply -f kube-state-metrics.yaml # 查看 kubectl get pods -n monitoring kubectl get svc -n monitoring
部署prometheus
# 部署 kubectl apply -f prometheus.yaml # 查看 kubectl get pods -n monitoring kubectl get svc -n monitoring
配置数据收集
# 部署 kubectl apply -f kube-servicemonitor.yaml # 查看 kubectl get servicemonitors -n monitoring
查看prometheus中的数据
# 查看 nodeport kubectl get svc -n monitoring | grep prometheus-k8s # 获取访问链接 # 11.11.11.111 为其中一个node ip NODE_IP='11.11.11.112' PROMETHEUS_NODEPORT=$(kubectl get svc -n monitoring | grep prometheus-k8s | awk '{print $(NF-1)}' | cut -d ':' -f 2 | cut -d '/' -f 1) echo "http://$NODE_IP:$PROMETHEUS_NODEPORT/"
prometheus主页
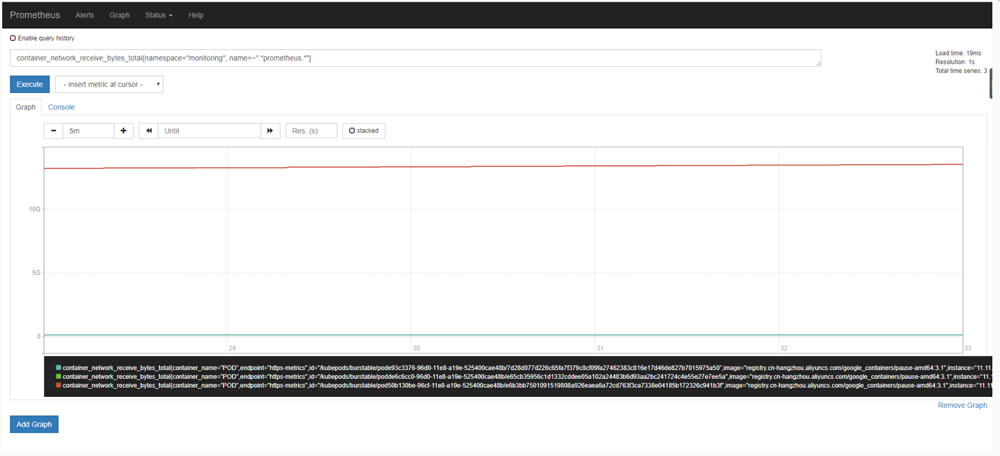
生成图表
container_network_receive_bytes_total{namespace=”monitoring”, name=~”.prometheus.“}
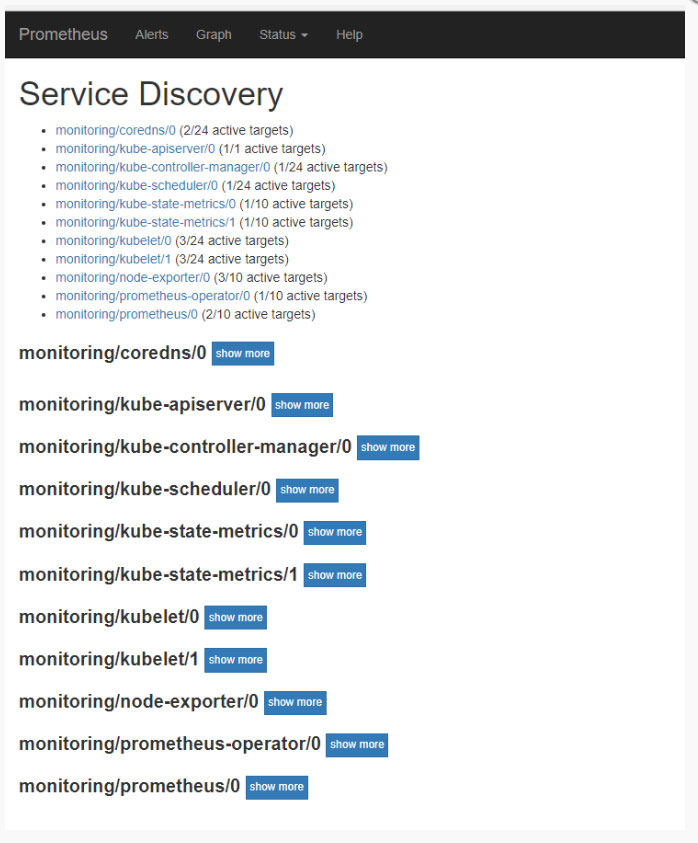
查看收集数据的端点

查看数据收集服务发现
部署grafana
# 部署 kubectl apply -f grafana.yaml # 查看 kubectl get pods -n monitoring kubectl get svc -n monitoring # 查看 nodeport kubectl get svc -n monitoring | grep grafana # 获取访问链接 # 11.11.11.111 为其中一个node ip NODE_IP='11.11.11.112' GRAFANA_NODEPORT=$(kubectl get svc -n monitoring | grep grafana | awk '{print $(NF-1)}' | cut -d ':' -f 2 | cut -d '/' -f 1) echo "http://$NODE_IP:$GRAFANA_NODEPORT/"
部署alertmanager
# 部署 kubectl apply -f alertmanager.yaml # 查看 kubectl get pods -n monitoring kubectl get svc -n monitoring # 查看 nodeport kubectl get svc -n monitoring | grep alertmanager-main # 获取访问链接 # 11.11.11.111 为其中一个node ip NODE_IP='11.11.11.112' ALERTMANAGER_MAIN_NODEPORT=$(kubectl get svc -n monitoring | grep alertmanager-main | awk '{print $(NF-1)}' | cut -d ':' -f 2 | cut -d '/' -f 1) echo "http://$NODE_IP:$ALERTMANAGER_MAIN_NODEPORT/"
查看图表
集群状态
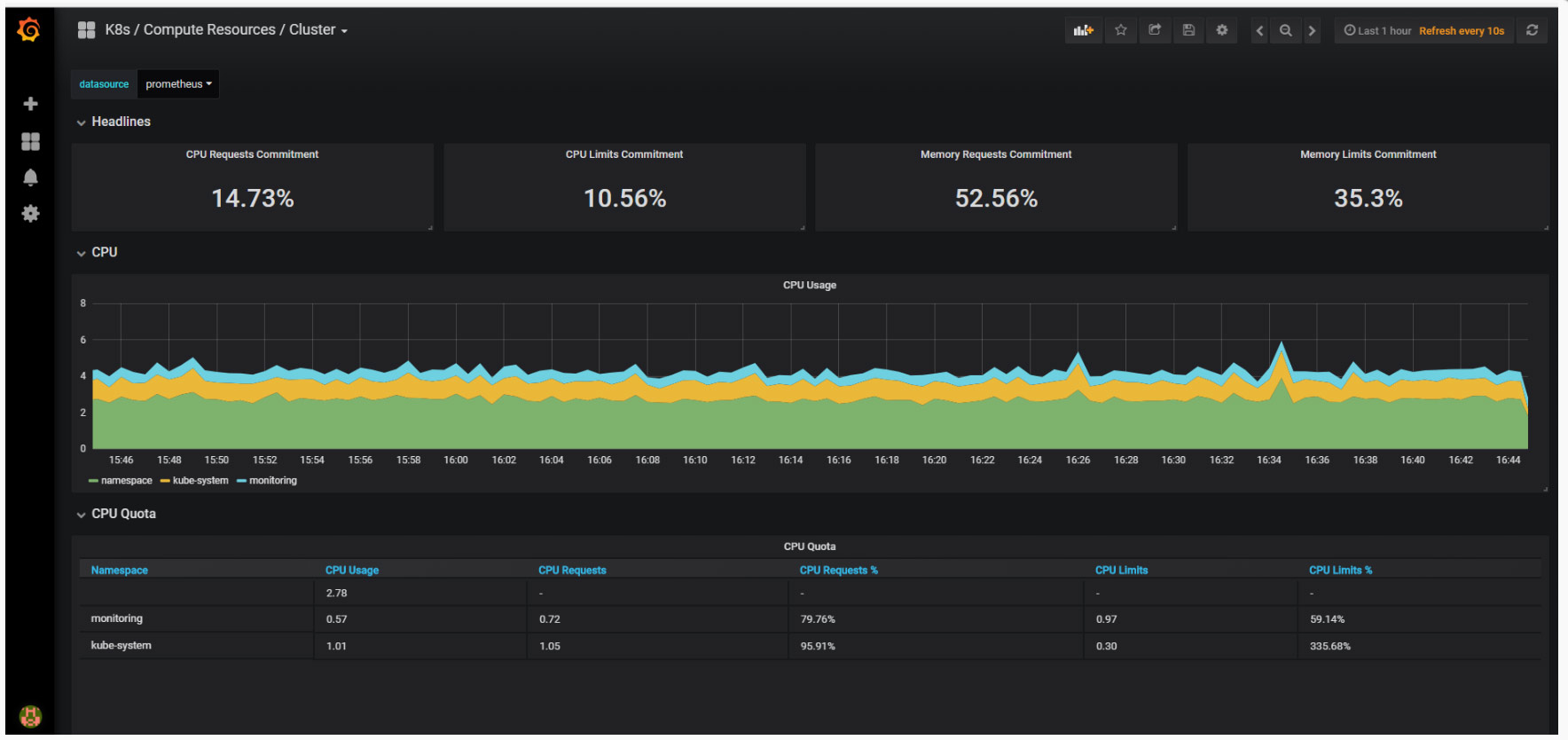
集群状态以命名空间视角

POD状态
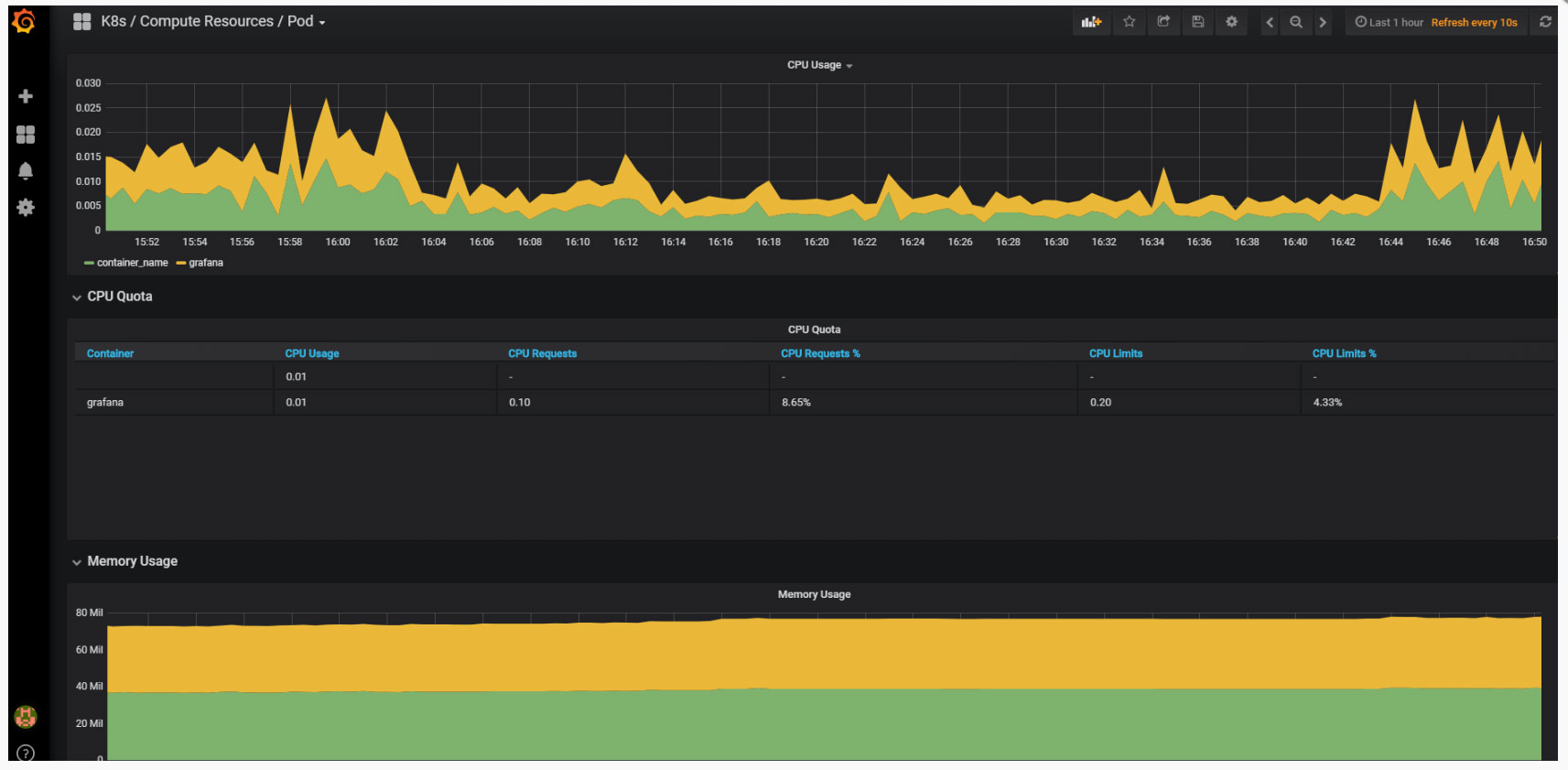
参考文档
- https://github.com/coreos/prometheus-operator
- https://github.com/coreos/prometheus-operator/blob/master/Documentation/user-guides/cluster-monitoring.md
- https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus
作者:毛广献
原文:http://www.maogx.win/posts/42/

请教博主一个问题,文章最开始描述了“使用metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等”。kubernetes现在hpa的数据来源是 metric-server 嘛? metric-server是一个k8s内部组件嘛?类似 heapster、cadvisor这种嘛?