
状态: Draft
作者 :bsalamat
译者:王国梁(云计算系统工程师/专业的业余摄影师)
贡献者 :misterikkit
原文地址:https://docs.google.com/document/d/1vITsfsbNBJTUklxrxU6D_gp8E4FHVDKLGYVvex8lrWg/edit#
译文地址:https://docs.google.com/document/d/1cfzff7bnrF9xNhlbi9pJBo9lNIVM73edgzHhM8NAu-M/edit#
大家都知道目前Kubernetes的调度器在可扩展性和性能上面还存在很多不足,在业界,不管是国内外大企业还是创业的新型云服务公司在面临调度的一系列本地化需求时都会自己定制或者使用webhook机制来兼容,但仍然要面临定制后不好和官方同步改动和webhook性能太差不够灵活的问题。所以,我们对更高可扩展性的调度器需求愈来愈强烈。下面是新更新的官方第二版调度器的设计草案,因为有些设计和我们内部的调度器不谋而合(例如预过滤,预留机制,拒绝(回调)等等),觉得很有意思。最快大家将可在2019年第一季度可以尝试使用Scheduler V2,一起期待吧。
摘要
本文档描述了 Kubernetes调度框架(Kubernetes Scheduling Framework)。该调度框架仅实现基本的功能,但它为插件扩展其功能提供了许多扩展点。 计划这个框架(及其插件)最终将取代当前的Kubernetes调度器。
目标
- 使调度程序更具可扩展性
- 通过将它的一些功能移植到插件来使调度程序的核心变得更简单。
- 调度程序很容易扩展,同时具备很高的性能
- 允许调度程序轻松扩展。
- 提出框架的扩展点
- 提出注册插件的机制
- 提出一种机制来过滤应该发送给每个插件的Pod
- 建议一种机制来接收插件的结果,并根据收到的结果决定继续或中止。
- 提出一种机制来处理错误并通过它与插件进行通信。
术语
Scheduler v1, 当前的调度程序,指代Kubernetes已经存在的调度器
Scheduler v2, 调度框架,指代在本文提出的新的调度器
背景
许多功能都被添加到了Kubernetes默认调度程序中,他们不断地让代码越来越多,逻辑更复杂。复杂到调度程序难以维护,它的错误也难以发现和修复,而运行自定义的调度程序的用户很难赶上并整合新的更改。
目前的Kubernetes调度器提供 webhooks 来扩展其功能。但是,这些在几个方面是有限制的:
- 扩展点的数量是有限的:在默认predicate函数之后调用“Filter”扩展器。在默认predicate函数之后调用“Prioritize”扩展器。运行默认preemption机制后调用“Preempt”扩展器。扩展器的“Bind”操作用于绑定Pod。只有其中的一个扩展器可以是一个绑定中的扩展器,并且该扩展器执行绑定而不是调度器来执行。扩展器不能在其他位置调用,例如,在运行predicate函数之前不能调用扩展器。
- 每次调用扩展器都需要编码和解码json文件。调用webhook(HTTP请求)也比调用本地函数慢。
- 很难通知扩展器调度器已经中止Pod的调度。例如,如果扩展器提供集群资源,并且调度程序联系扩展器并要求其为调度的Pod提供资源实例,然后当调度器面临调度Pod的错误并决定中止调度,则很难将该错误通知扩展器,并要求它撤销资源的供应。
- 由于当前扩展程序作为单独的进程运行,因此它们不能使用调度程序的缓存。他们必须从apiserver那里来构建自己的缓存,或者只处理从默认调度程序收到的信息。
上述限制妨碍了构建高性能和多功能的调度程序扩展。理想情况下,我们希望有一个足够快的扩展机制,以允许在调度程序核心中保留最少的逻辑,并将默认调度程序的许多现有功能(例如认predicate和predicate功能以及抢占功能都转换为插件)转换。这些插件将与调度程序一起编译。我们还想提供一个不需要重新编译调度程序的扩展机制。这些插件的预期性能低于进程内插件。在快速调用插件不是约束的情况下,应该使用这种进程外插件。
概述
调度程序v2 允许内置和外置扩展。这种新的架构是一个调度框架,公开了几个在调度周期的扩展点。调度程序插件可以注册在一个或多个扩展点。
非目标
- 我们将保持Kubernetes API向后兼容性,但保持scheduler v1向后兼容性是非目标。 特别是,调度策略配置和v1扩展器在这个新框架中不起作用。
- 解决所有调度程序v1的限制,尽管我们希望确保新的框架允许我们在未来解决已知的限制。
- 提供插件和回调函数的实现细节,例如它们的所有参数和返回值。
详细设计
调度的流程
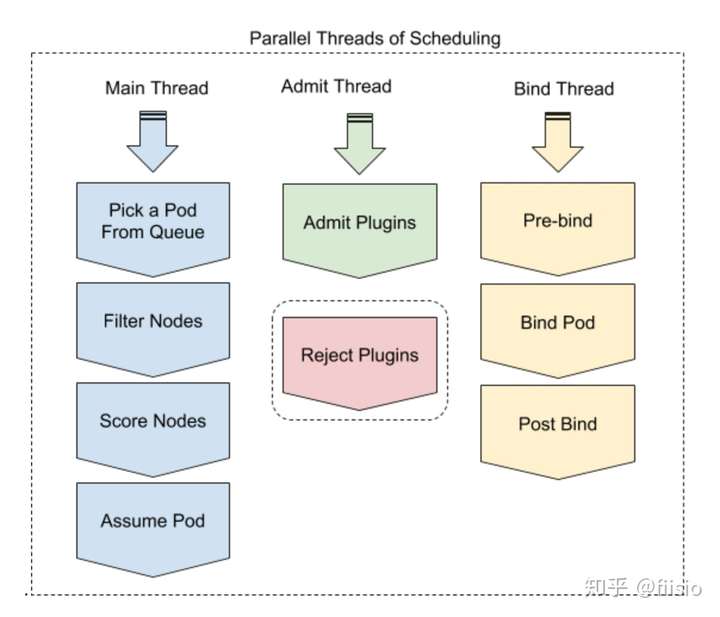
未分配给给任何节点的Pod被移到调度队列,并按插件指定的顺序排序(介绍 此处)。调度框架选择队列的头部并启动 调度周期 来调度该Pod。在周期结束时,调度程序确定该Pod是否可调度。如果该Pod不可调度,则其状态会被更新并返回到调度队列。如果Pod是可调度的(找到一个或多个可运行Pod的Node节点),则开始评分过程。评分过程找到运行Pod的最佳节点。一个执行绑定操作的goroutine开始绑定该吊舱。
上述过程与Kubernetes调度程序v1所做的相同。调度程序v1的一些基本特性,如领导者选举,也将被转移到调度框架中。
在本节的其余部分中,我们将介绍如何使用各种插件来丰富此基本工作流程。在本节中,我们将重点放在进程内插件上。进程外插件将在稍后的文档中讨论。
插件的通信和状态
调度框架提供了一个库插件可以通过它将信息传递给其他插件。 该库保存为一个字符串类型的键到类型为interface {}的不透明指针的map。 写操作需要一个键和一个指针,并使用给定的键将不透明指针存储在映射中。其他插件可以提供键获取并接收不透明指针。多个插件可以共享状态信息或通过此机制进行通信。
保存的状态仅在单个调度周期中保留。在计划周期结束时,该map被破坏。所以,插件无法在多个调度周期内保持共享状态。但是,它们可以通过缓存提供的接口来更新调度程序的缓存。缓存接口允许跨多个调度周期的有限的状态保存。
值得注意的是插件都被认为是 可信的。调度程序不会阻止一个插件访问或修改另一个插件的状态。
插件注册
插件注册是通过提供一个扩展点和一个应该在该扩展点上调用的函数来完成的。这一步将是这样的:
register(“pre-filter”, plugin.foo)
函数签名的细节将在稍后提供。
扩展点
下图显示了Pod的调度周期以及调度框架公开的扩展点。在此图片中,“Filter”相当于调度程序v1中的“Predicate”,“Scoring”相当于“Priority function”。 插件是go函数。他们被注册为这些扩展点之一。 框架会按照它们为每个扩展点注册的顺序调用它们。
在下面的章节中,我们按照它们在调度周期中被调用的相同顺序来描述每个扩展点。
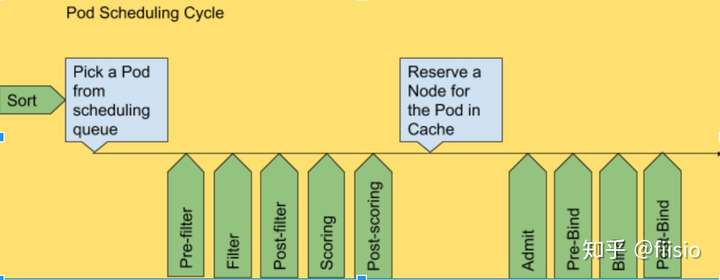
调度队列排序
这些插件表示应该如何在调度队列中对Pod进行排序。此时注册的插件只返回更大,更小或等于表示两个Pod之间的顺序。换句话说,这个扩展点上的插件返回“less(pod1,pod2)”的答案。此时可能会注册多个插件。在这一点上注册的插件按顺序调用,只要插件返回“相等”,调用就会继续。一旦插件返回“更大”或“更小”,这些插件的调用就会停止。
预过滤
这些插件通常用于检查集群或Pod必须满足的某些条件。这些对于在Pod上执行预处理并存储一些关于可以被其他插件使用的Pod的信息也很有用。
pod指针作为参数传递给这些插件。如果这些插件中的任何一个返回错误,则调度周期将中止。
这些插件以已注册的相同的顺序连续被调用。
过滤
过滤器插件过滤掉无法运行Pod的节点。调度程序按照它们注册的顺序为每个节点运行这些插件,但调度程序可以并行地为多个节点运行这些过滤器函数。所以,这些插件在修改状态时必须使用同步。
一旦这些过滤器中的一个过滤器失败,调度程序就会停止运行节点的剩余过滤器函数。
Post过滤器
已经通过过滤Pod的Pod和一组节点被传递给这些Post插件。它们被称为Pod是否可调度(不管节点集是空的还是非空的)。
如果这些插件中的任何一个返回错误,或者Pod确定为不可调度,则调度周期将中止。
这些插件被称为 Serially。
评分
这些插件与调度程序v1中的priority函数类似。它们被用来对已经通过过滤阶段的节点进行排序。与过滤器插件类似, 每个节点按照已注册的顺序依次调用它们,但调度程序可以并行地为多个节点运行它们。
这些函数中的每一个都会为给定节点返回一个分数。得分乘以函数的权重并与其他得分函数的结果汇总以得出节点的总得分。
这些函数永远不会阻止调度。在发生错误的情况下,它们应该为被排名的节点返回零分。
Post评分/预先假设
调用完所有评分插件并确定节点的分数后,框架将选出评分最高的最佳节点,然后调用Post评分插件。 Pod和选定的节点被传递给这些Post评分插件。这些插件还有一次机会检查任何有关将Pod分配给此节点的条件,并在需要时拒绝该节点。
预留
这不是一个插件点。 此时,调度程序通过为Pod更新Node缓存来“预留”资源(部分或全部)来。在调度程序v1中,这个阶段被称为“假设”。此时,只有调度程序缓存被更新以反映节点(部分地)被保留给Pod。节点到Pod的实际分配发生在“绑定”阶段。这是当apiserver使用节点信息更新Pod对象时。
承认
Admit 插件在单独的goroutine中运行(并行)。每个插件可以返回三个可能值之一:1)“承认”,2)“拒绝”,或3)“等待”。如果在此扩展点上注册的所有插件都返回“允许”,则将该容器发送到下一步进行绑定。如果任何一个插件返回“拒绝”,则会拒绝该容器并将其发送回调度队列。如果任何一个插件返回“等待”, 则Pod将保持保留状态,直到明确批准进行绑定为止。返回“等待”的插件也必须返回“超时”。如果超时到期,则该Pod被拒绝并返回到调度队列。
批准Pod绑定
虽然任何插件都可以从缓存中接收保留Pod的列表并批准它们,但我们只希望“Admit”插件批准绑定处于“等待”状态的保留Pod。一旦Pod被批准,它就会被发送到绑定阶段。
拒绝
被称为“Admit”的插件可能会执行一些操作,如果Pod假定失败,则应该撤消这些操作。 “拒绝”扩展点允许进行这种清理操作。如果Pod的假设被取消,则调用此时注册的插件。 如果任何“Admit”插件返回“拒绝”或处于“等待”状态的Pod假设超时,则预留被取消。
预先绑定
当Pod被批准绑定时,它会到达这个阶段。这些插件在Pod到节点的实际绑定发生之前运行。只有当所有这些插件都返回true时,绑定才会启动。如果有任何返回false,则Pod被拒绝并被发送回调度队列。这些插件运行在一个单独的去程序中。当所有这些插件返回true时,相同的例程运行“绑定”这些插件。
绑定
一旦所有预绑定插件返回true,绑定插件就会被执行。 这个扩展点可能会注册多个插件。每个插件可能会返回true或false(或错误)。如果插件返回false,则会调用下一个插件,直到插件返回true。一旦返回true ,剩余的插件就会被跳过。如果任何插件返回错误或者所有插件都返回false,那么Pod将被拒绝并返回到调度队列。
后期绑定
后期绑定插件对预定后的内务管理非常有用。这些插件不会返回任何值,也不会影响在调度周期中做出的调度决策。
USE-CASES
在本节中,我们提供了一些关于如何使用调度框架来解决常见调度场景的示例。
集群级资源的动态绑定
集群级资源是不在调度Pod时的立即确定可用的节点的资源。调度程序需要确保此类集群级资源绑定到选定的节点,然后才能调度需要此类资源的节点的节点。在调度Pod作为动态资源绑定时,我们将这种类型的资源绑定到节点。
事实证明,动态资源绑定在Scheduler v1中是一个挑战,因为Scheduler v1不够灵活,无法在不同的调度阶段支持各种类型的插件。因此,存储卷的绑定被集成到调度程序代码中,并且对调度程序扩展程序进行了一些不重要的更改以支持网络GPU的动态绑定。
调度框架以更清晰的方式允许这种动态绑定。调度框架的主线程处理待处理的Pod,它请求网络资源并为Pod找到节点并保留Pod。 在“预绑定”阶段安装动态资源联编程序插件(在单独的线程中)。它分析Pod,当检测到Pod需要动态绑定资源时,插件会尝试将集群资源附加到所选节点,然后返回true,以便可以绑定Pod。 如果资源附件失败,则返回false并重试Pod。
当有多个这样的网络资源时,它们中的每一个都安装一个“预先绑定”插件。每个插件都查看Pod,如果Pod没有请求他们感兴趣的资源,他们只需返回“真正”的pod。
Gang调度
Gang调度允许同时安排一定数量的Pod。如果该团伙的所有成员不能同时调度,他们都不应该调度。 Gang调度也可能具有其他各种功能,但在此情况下,我们对Pod的同时调度感兴趣。
调度框架中的Gang调度可以使用“Admit”插件完成。 主调度线程逐个处理pod并为它们预留节点。每个吊舱都会调用准入阶段的帮派调度插件。当它发现吊舱属于一个帮派时,它会检查帮派的属性。如果没有足够的成员定期或处于“等待”状态,该插件返回“等待”。当数字达到期望值时,处于等待状态的所有Pod均被批准并发送进行绑定。
进程外插件(OUT OF PROCESS PLUGINS)
进程外插件(OOPP通过HTTP接口通过JSON调用)。换句话说,调度器将支持最多(也许是全部)扩展点的webhook。发送到OOPP的数据必须编码为JSON,并且收到的数据必须解码。所以,调用一个OOPP比在进程中的插件要慢很多。
我们不打算在第一版的调度框架中构建OOPP。所以,关于它们的更多细节将被确定。
配置调度框架
兼容性 使用SCHEDULER v1
我们将为调度程序v2构建一组新的插件,以确保调度程序v1在将节点放置在节点上时的现有行为得以保留。这包括 构建复制缺省谓词和优先级插件 scheduler v1的函数及其绑定机制的,但为scheduler v1构建的调度程序扩展器将不兼容调度程序v2。此外,在调度程序v2中不保证缺省情况下未启用的谓词和优先级功能(如服务关联)。
开发计划
我们将开发调度框架作为SIG-scheduling中的孵化器项目。它将在独立于调度程序v1的独立代码库中构建,但我们 可能会使用来自调度程序v1的很多代码。
测试计划
我们将在构建调度框架的功能时添加单元测试。调度框架最终应该能够通过调度程序v1的集成和e2e测试,排除那些涉及调度程序扩展的测试。 e2e和集成测试可能需要稍微修改,因为调度框架的初始化和配置将与调度程序v1不同。
工作评估
我们期望在两个发布周期(2018年底)看到一个早期版本的调度框架。如果事情顺利,我们将在2019年第一季度末开始提供它作为调度程序v1的替代品,并启动调度程序v1的弃用。我们将在2019年第二季度将其作为Kubernetes的默认调度程序,但我们将保留使用调度程序v1至少两个更多发布周期的选项。

登录后评论
立即登录 注册