
背景
公司的容器云平台需要新增应用的自动扩缩容的功能,以便能够更加智能化的对应用进行管理。
Kubernetes官方提供了HPA(Horizontal Pod Autoscaling)资源对象。要让我们部署的应用做到自动的水平的(水平指的是增减Pod副本数量)进行扩缩容,我们只需要在Kubernetes集群中创建HPA资源对象,然后让该资源对象关联某一需要进行自动扩缩容的应用即可。
HPA默认的是以Pod平均CPU利用率作为度量指标,也就是说,当应用Pod的平均CPU利用率高于设定的阈值时,应用就会增加Pod的数量。CPU利用率的计算公式是:Pod当前CPU的使用量除以它的Pod Request(这个值是在部署deployment时自己设定的)值。而平均CPU利用率指的就是所有Pod的CPU利用率的算术平均值。
Pod平均CPU利用率的计算需要知道每个Pod的CPU使用量,目前是通过查询Heapster扩展组件来得到这个值,所以需要安装部署Heapster。
接下来我就将我们在Kubernetes集群中部署Heapster的过程记录下来,也会描述我们在部署过程中遇到的问题以及解决的方法,希望能够帮助到也准备在Kubernetes集群中部署Heapster的朋友。
Heapster成功部署之后,我们使用了性能测试工具对http应用做了压力测试,以观察HPA进行自动扩缩容时的实际效果。
部署过程
1
首先,我们在github中搜索Heapster,会找到Kubernetes中的Heapster库:
将这个库clone到集群的master节点中。
在Heapster目录下运行命令kubectl create -f deploy/kube-config/standalone/Heapster-controller.yaml
理论上创建完成后会启动三个资源对象,deployment、service、serviceaccount,此时Heapster应该就能够为HPA提供CPU的使用量了。
此时为验证Heapster是否可用,在集群中部署一个HPA资源对象,关联某个应用,并设定阈值为90:


查看这个HPA时我们可以看到,CURRENT的CPU利用率为,也就是说,HPA没能从Heapster中取得CPU的使用量。
于是,我们用kubectl get pod –namespace=kube-system命令查看Heapster的pod的运行情况,发现是拉取镜像失败的缘故。
打开部署Heapster的yaml文件如下:
apiVersion: v1 kind: ServiceAccount metadata: name: Heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: Heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: Heapster spec: serviceAccountName: Heapster containers: - name: Heapster image: gcr.io/google_containers/Heapster-amd64:v1.4.0 imagePullPolicy: IfNotPresent command: - /Heapster - --source=kubernetes:https://kubernetes.default --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: Heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: Heapster
可以看到23行,镜像是要从谷歌的gcr.io镜像仓库中拉取的,由于我们的集群服务器不能连通外网,所以镜像当然就拉取失败了。
2
此时,我们使用之前使用过的自己仓库中的Heapster镜像来替代此yaml文件中使用的镜像。
清除刚才部署失败的资源对象后再次在Heapster目录下使用命令:kubectl create -f deploy/kube-config/standalone/Heapster-controller.yaml
这个时候发现对应的资源对象都创建成功了,而且pod也成功运行了。
此时看HPA的情况如下:

此时问题没有得到解决,虽然Heapster的pod运行起来了,但是HPA还是没能取到CPU使用量的值。
现在的情况来看,此时还不能确定问题是在于Heapster安装没成功还是HPA没能从Heapster中取得值。
所以,接下来就是要确定一下Heapster是否安装成功了。
这个时候,我们想到去Heapster中的docs目录下看看有没有什么debug的方法,也就是进入Heapster目录下的docs中的debugging。
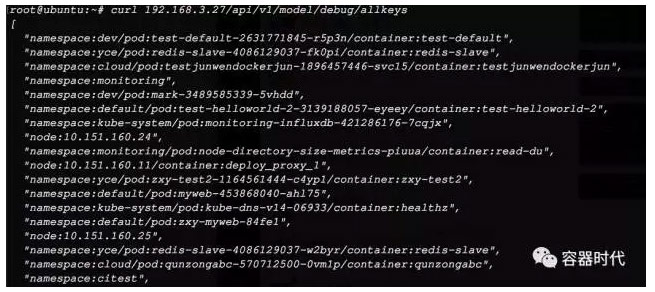
用curl命令对URL/api/v1/model/debug/allkeys 做取值,得到的结果如下:
然后再用kubectl describe hpa yce –namespace=yce命令来查看HPA资源对象的详情

Message中显示,从Heapster获取指标失败。
此时结论就得出了,Heapster已经成功安装,不过集群无法从Heapster中获取到监控数据。
好了,接下来我们决定再给Heapster换一个镜像试试,有可能是我们的镜像版本问题导致与Kubernetes集群不能协同工作。
在docker hub中搜索到了版本为v1.2.0的Heapster镜像,替换为此镜像后再次创建资源对象。
3
创建成功后,惊喜出现了

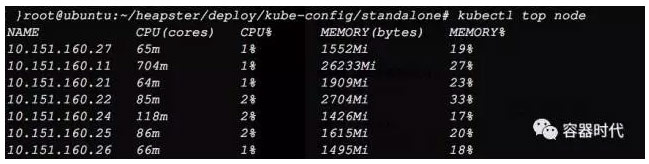
可以看到,HPA已经可以从Heapster中取到值了。然后用kubectl top node命令查看节点的指标,发现也可以取到值了。
对HPA关联的应用做压力测试
理论上Heapster已经安装成功。为了验证HPA是否可用,我们写了一个简单的http程序,名为helloworldhey。该程序就是做了一个自增整型变量1000次的循环。
将该程序打包成镜像,部署对应的deployment和service资源对象,然后在集群外部通过暴露的节点端口用性能测试工具ab对其进行压力测试。可以看到结果如下:

可以看到,我这里设置的阈值为50%,也就是说,在平均CPU使用率超过50%时,HPA会对pod进行自动的扩容,也即是增加pod的数量,使增加后的pod总数量可以让平均CPU使用率低于50%。可以看到此时的CPU使用率已经为110%,所以,理论上HPA应该自动的拉起2个pod来分担CPU的使用量。看看pod的目前情况,结果如下:
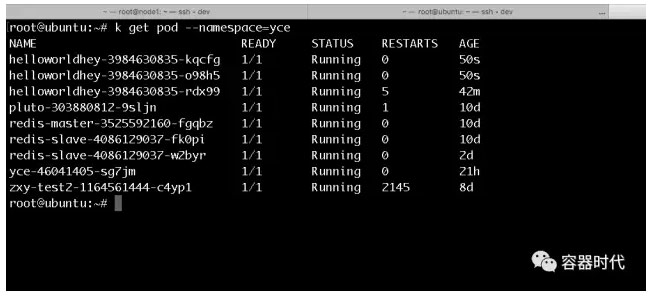
可以看到此时共有三个pod,与预期的结果相同。
不过,可能有人会有疑问,为什么最初创建的pod会重启多次?原因就在于Kubernetes在部署deployment时,每个pod都设置有requests与limits值,当该pod的CPU(或内存)使用量超过该limits值时,kubelet就会重启这个pod,由于在压力测试的开始时刻只有此一个pod,所以CPU使用量肯定是超过了这个limit值于是pod就被重启了。
至此,heapter就被部署成功且可以正常使用了。

欢迎关注译者微信公众号

登录后评论
立即登录 注册