
随着容器越来越流行,k8s也成为很多公司标配,Kubernetes 让当前主流的基础架构有一套易用的 API 。利用好 Kubernetes ,我们可以实现更高的、更通用的基础架构自动化管理。基于此, CoreOS 实现了一套能“自动驾驶”的 Kubernetes 。在本次演讲中,来自 CoreOS 的邓洪超将通过自身参与的经验,讲解其中的技术细节。并以主要负责的 etcd operator 为例,讲解在 Kubernetes 搭建 Operator 的通用模式。
邓洪超:今天非常荣幸来到这里。首先介绍一下 Operator ,它是用来自动化应用的运维的。这里的应用指的是你的 code+config、程序、逻辑层和部署层。
一个例子
开始之前我们先讲一个故事,这个故事一般朋友圈比较多,我们是从朋友圈开始的,大家知道pingCAP不仅数据库做得好,周边也做得很好。

图1
卖周边就得做一个网站,那黄东旭是GO的大牛,GO这个语言可以让我们非常快速的做一个网站出来。Golang 可以让我们非常快速地做一个网站出来。于是我们很快的就有了一个原形,给大家欣赏一下底层程序员的设计。
图2
可以说GO是一门非常好的语言,它可以让我们非常简单和方便的实现从想法到程序的转变。然后我们写程序是本地层面的,需要部署到一个服务器层面里面。首先我们要对这个程序进行打包,并且把我们的服务包发布出去。这就需要在服务器集群里面配置储存等资源,把程序部署出去,让它跑起来去服务这些用户请求。
部署无状态的应用
接下来会告诉大家怎么打包这个程序。如图4所示,首先这是一个打包的命令,这是一个容器镜像。我们会把这个进向发布出去,发布出去的时候我们已经有了一个集群,是在跑的。我们现在把这个应用跑起来。首先在本地的这个关口我们是访问不了的,我们会在本地30080端口,相当于我们找到了另外一个方法找这个服务。我们看到这时候的服务已经部署起来,我们可以访问了。
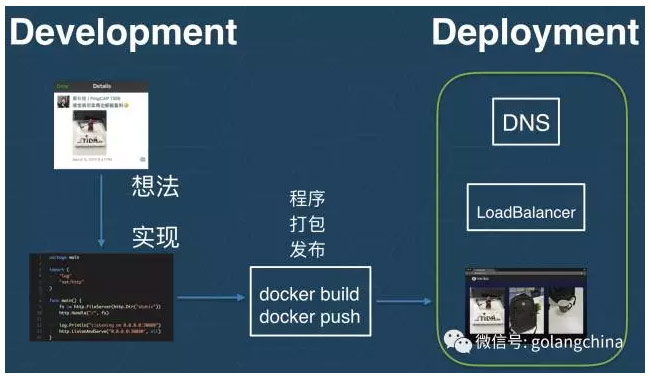
图3
有了容器技术,让我们非常方便——哪怕我从来不写应用的,我也能非常简单的部署一个应用。而我们刚才在这个过程中使用了容器的两个工具,

图4
这个对应了容器发展的两个阶段,在第一个阶段我们对如何打包应用进行的标准化,这样的话你服务包在网络传输里面的格式是一致的,只要你用这种标准的格式打包了你的应用,无论跑在哪一个平台上,无论服务提供商是谁——谷歌,或者腾讯云,阿里云,你的服务包在任何地方都可以被跑起来,是兼容的。然后刚才这个过程是本地,是一个个体层面的。我们在部署的时候是要部署到一个服务器集群里面去,这往往要求我们对这个集群的资源进行配置、管理和调度。所以第二个阶段我们需要一些工具去管理这个集群。

图5
有状态的应用
容器技术发展到现在,可以说部署这一类的无状态的外表应用是非常简单的。而且据我所知,现在大部分
的这些企业的应用都是无状态的应用,哪怕包括谷歌自身。这也是容器技术的出发点。然而对于部署一些有状态的应用还是非常困难的,现阶段大家都没有很好的解决方面。那什么是有状态的应用呢?我这里给大家举一些例子。
比如说数据库,你一些中间件,像Kafka,heron,还有做大数据的spark,等等这些都是状态的服务。可以说部署这些有状态服务是非常困难的,比这些无状态的外表应用要复杂的多。一方面他们要求的这些配置更为复杂,而现在也很多,首先很多公司他们会有专门的团队去管理,他们不会这么简单的管理,而是有专门的团队去管理一个个集群。甚至很多公司通过帮助管理这些有状态的应用集群来盈利。
prometheus
我们首先通过几个例子,首先是prometheus,它是一个开源工具,当我们在跑这个prometheus的时候,一方面它需要知道选定服务的端口,它会对这些端口进行扫描,并且抓取它们的Matrix,最后把Matrix整合到一个接口里面。另外一方面他要抓取这些规则,然后根据这个Matrix和规则,所以你在避暑prometheus的时候,会遇到一些非常复杂的关系型依赖。你在部署的时候不仅需要知道这个prometheus自身的部署规则,另一方面你还要根本环境的不同,而做一些重复性的运维操作。

图6
Etcd
Etcd,是一款强一直的高可用的服务发现存储仓库。由于架构,它在启动的时候会给所有成员的信息,这样所有人会去投票,从而产生一个leader,然后我们需要配置这些ID,配置这个运营,配置这个端口,然后我们还得对每一个都重复做同样的操作,这些还只是静态的。如果是动态的时候,我们还需要做一些有顺序的操作。

图7
Self-updating Kubernetes
大家都知道 OS 是会自动更新的,因为它有一套自动更新服务器。那么在它的另一个产品里面,它就利用这一套更新服务器,去给它做自动更新的服务。当一个更新发出来的时候,它的策略会长得像如图8所示,他会说我需要把 APIServer 升级到 1.6 ,我把 etcd 升到 3.1.4 。当我们要升 etcd 的时候,我们在更新的时候,我们先会对集群的数据做一遍备份,然后我们还要检查这些更新路径。比如我从3.0升到3.2,它会先从3.0升到3.1,然后从3.1升到3.2。然后集群做滚动升级。确保每个都升级成功。最后当整个升级不成功的时候,他还会做回滚。
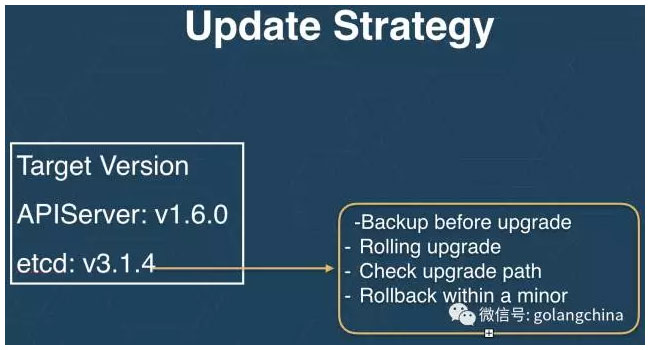
图8
从我们看的这几个例子,我们发现为什么部署这些有状态的应用和部署管理它们会比无状态的复杂呢?是因为它们有这些复杂的运维和逻辑在里面。它需要你去配置像ID,像网络资源,像储存等等这些操作。并且这些会根据环境的不同而做一些重复性的工作。
operator
那么正是为了解决这个问题,推出了一个叫operator的概念,那么从软件上我们会模拟一个运维人员,去不断的更新,去做一些配置,来保证你的集群、你的服务正常运行。那么operator的工作原理如图9所示。
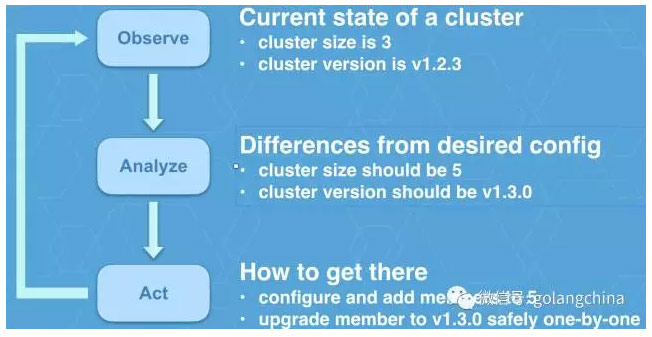
图9
它主要有三个步骤,首先它会去观察当前的状态,比如说当前的集群节点数量是三个,当前的集群的版本等等,它会比较跟期望的有什么不同。比如它发现我期望的集群节点数量应该是5个,我期望的版本应该是1.3.0。最后它会做出行为去纠正。可能它会想办法添加这些成员,把它从三个变成五个;也可能它会去更新这些一个个的成员,把它们从 1.2.3 升级到 3 。而在一轮做完之后又回到原点,去重新观察,不断的重复做这样的工作,就像一个24小时在上班的运维人员一样的,来保证这个集群或者服务的正常健康的运行。
那么正是基于这样一个想法,我们写了一个etcd operator来管理和部署ectd集群。如图10。

图10
首先 ectd operator 能帮助大家在日常运维中的工作,比如说这个扩容,你要从三个节点扩容到五个结点,或者从五个节点缩减到三个节点。然后备份,因为 etcd 毕竟是存数据的,所以我们要对这个集群进行自动备份。还有故障切换,当你有一个成员它死掉的时候,etcd operator 会自动换一个新的成员上去,来保证这个集群健康运行。而对于更高级的用户我们甚至提供更高级的功能,像恢复、TLS等等。
那么 etcd operator 如果实现了上面这个功能,可以说它就是一个 RDS ,但是我个人觉得,etcd operator比 RDS 要高级的多。因为它这个etcd operator有一套陈述式的 API ,如图11所示。什么是陈述式的 API 呢,就是你只需要告诉说,我最后希望变成什么样?我不需要说究竟要怎么一步步做成那样。

图11
我这里举个例子,比如我要创建一个 etcd 集群,我告诉节点数量它是 3 个,然后集群版本是3.1.5,我每隔300秒做一次备份,也就是每隔5分钟做一次备份,我最多的这个备份数量是5个,那我们甚至还可以配置说我需要去存在这个PV里边还是S3里面等等。这就是一个陈述式的API。就是陈述式的API可以让里面的线路是兼容,是互通的。就像我们刚才定的API是一个更结构性的。但是我们一样可以转换成和其他的线路沟通。它一样可以转化成GO的API。

图12

图13
总结
容器发展我们经历了两个阶段,第一个是格式的标准化,第二个是对容器更方便的配置这些资源,管理和调度这些资源。那慢慢的随着这个应用的多元化,和应用的专门话以后未来在容器上会有越来越多的针对专门应用的自动化出现。这个也是我们推 operator 的原因,图14是未来operator的发展方向,会以应用以服务为中心的一些自动化。

图14
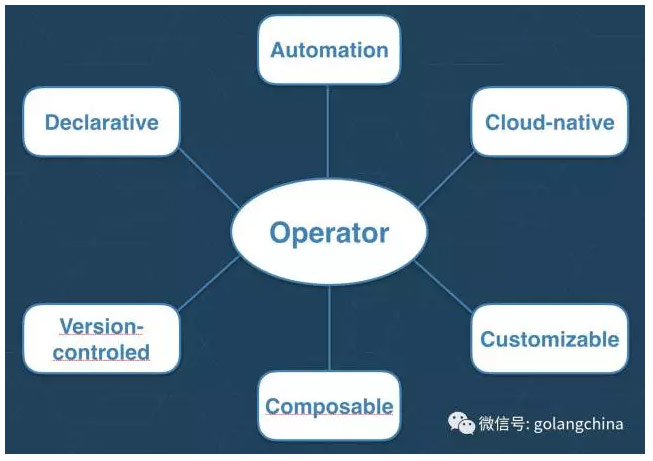
最后我们来定义operator究竟是什么东西,以及prometheus未来会做什么东西。operator的核心在于自动化,我们也看到operator的API是陈述式的,然后operator的API也是Cloud-native,operator也是customizable的,你可以自定义prometheus来跑在不同的环境里面。

登录后评论
立即登录 注册