
本文从一个服务的不同访问方式入手,分析了Kubernetes集群中的网络组成,也给出了一个简单可行的网络性能评估方案。
本文适合对虚拟网桥、iptables以及Kubernetes的相关概念有了解的读者。
另外Service-Pod流量转发时提到”iptables转发”,严格说措辞不准确,因为iptables仅负责用数据库维护了Kernel中Netfilter的hook,这样表述是为了便于理解。
另外,本文也希望为以下几个问题找出明确的答案:
- Service-Pod之间转发流量时,kube-proxy是否承担流量转发?kube-proxy的转发机制是怎么样的?
- Service-Pod之间(Service对应多个Pod时)的负载均衡的实现原理是怎么样的?是用kube-proxy来做负载均衡吗?
Kubernetes网络组成分析
从不同访问方式的数据流上看,一个Kubernetes集群的网络可以划分为2部分:
- Kubernetes网络模型实现:如Overlay Network(第三方实现中有Flannel,Contiv等)
- 集群IP(Cluster IP),用以集群内服务发现,DNS解析等
本节中的试验集群使用Flannel搭建Overlay Network,其他的解决方案没有本质区别。
为了说明Kubernetes集群网络,下面来部署一个Nginx服务,同时部署了2个Pod:
$ kubectl create -f https://raw.githubusercontent.com/yangyuqian/k8s-the-hard-way/master/assets/nginx.yaml deployment "nginx-deployment" created service "nginx-service" created
可以直接在主机上用Pod的IP来访问对应的Pod:
$ kubectl get pod --selector="app=nginx" -o jsonpath='{ .items[*].status.podIP }'
172.30.40.3 172.30.98.4
$ curl 172.30.40.3:80
...
$ curl 172.30.98.4:80
...
注意:下面“在集群内”的命令都需要attach到一个Pod里面才可以执行。
也可以在集群内,使用Cluster IP来访问服务:
$ kubectl get services NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes 10.254.0.1 <none> 443/TCP 1d nginx-service 10.254.126.60 <none> 8000/TCP 9m $ kubectl run --rm -it curl --image="docker.io/appropriate/curl" sh $ curl 10.254.126.60:8000 ...
如果部署了DNS服务,那么还可以通过集群内的域名来访问对应的服务:
$ curl nginx-service:8000 ...
图1 上面例子的网络图解(采用Flannel来搭建Overlay Network)
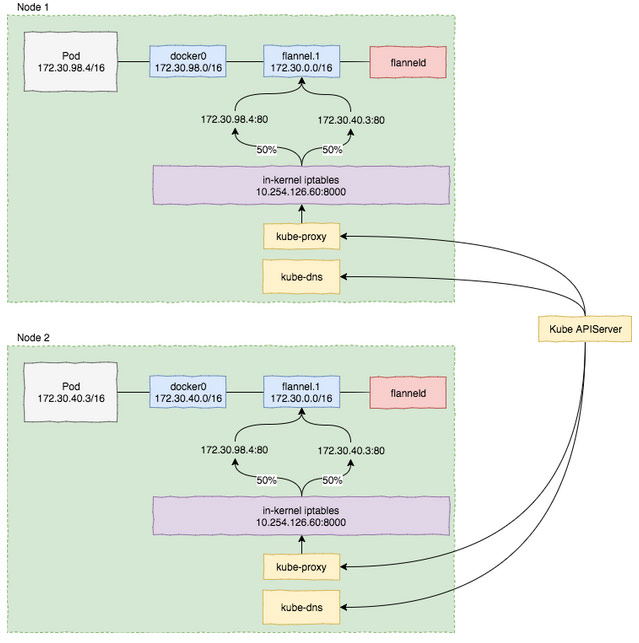
总结
Service到Pod的流量完全在本机网络中完成,简单而不失高效。
kube-proxy并不承担实际的流量转发工作,实际上,它会从kube-apiserver动态拉取最新的应用与服务状态信息,并更新本机上的iptable规则. 即使把kube-proxy停掉,已经生成的规则还是可用的。
Service对多个Pod进行流量转发时,采用iptable规则来进行负载均衡,上面的例子中,iptable会在两个Pod中进行分别50%概率的流量转发。
性能评估
集群拓扑结构:
测试集群采用Digital Ocean上2台VPS,用Flannel搭建Overlay Network,使用vxlan backend, 默认mtu配置。
这里旨在提供一种网络性能的评估方案,评估结果只能说明当前实验环境下的Flannel网络性能。
分别对下面3种网络访问方式,使用qperf做TCP和UDP的带宽和延迟测试:
- 节点之间
- Pod-Pod之间
- Pod-Service-Pod
实验 1 节点之间
Node 1上启动qperf server:
$ qperf
Node 2上测试直接访问性能:
$ qperf -v ${node1_ip} tcp_bw tcp_lat udp_bw udp_lat conf
tcp_bw:
bw = 331 MB/sec
msg_rate = 5.05 K/sec
send_cost = 451 ms/GB
recv_cost = 2.05 sec/GB
send_cpus_used = 15 % cpus
recv_cpus_used = 68 % cpus
tcp_lat:
latency = 125 us
msg_rate = 7.99 K/sec
loc_cpus_used = 14 % cpus
rem_cpus_used = 14 % cpus
udp_bw:
send_bw = 2.43 GB/sec
recv_bw = 132 MB/sec
msg_rate = 4.03 K/sec
send_cost = 302 ms/GB
recv_cost = 4.05 sec/GB
send_cpus_used = 73.5 % cpus
recv_cpus_used = 53.5 % cpus
udp_lat:
latency = 113 us
msg_rate = 8.84 K/sec
loc_cpus_used = 11 % cpus
rem_cpus_used = 9 % cpus
conf:
loc_node = kube-minion-2
loc_cpu = Intel Xeon E5-2650L v3 @ 1.80GHz
loc_os = Linux 3.10.0-514.6.1.el7.x86_64
loc_qperf = 0.4.9
rem_node = kube-minion-1
rem_cpu = Intel Xeon E5-2650L v3 @ 1.80GHz
rem_os = Linux 3.10.0-514.6.1.el7.x86_64
rem_qperf = 0.4.9
实验 2 Pod-Pod之间
部署qperf-server:
$ kubectl create -f https://raw.githubusercontent.com/yangyuqian/k8s-the-hard-way/master/assets/qperf-server.yaml
测试Pod-Pod之间网络:
$ podip=`kubectl get pod --selector="k8s-app=qperf-server" -o jsonpath='{ .items[0].status.podIP }'`
$ kubectl run qperf-client -it --rm --image="arjanschaaf/centos-qperf" -- -v $podip -lp 4000 -ip 4001 tcp_bw tcp_lat udp_bw udp_lat conf
bw = 170 MB/sec
msg_rate = 2.59 K/sec
port = 4,001
send_cost = 3.07 sec/GB
recv_cost = 3.27 sec/GB
send_cpus_used = 52 % cpus
recv_cpus_used = 55.5 % cpus
tcp_lat:
latency = 154 us
msg_rate = 6.5 K/sec
port = 4,001
loc_cpus_used = 16 % cpus
rem_cpus_used = 17 % cpus
udp_bw:
send_bw = 2.93 GB/sec
recv_bw = 42.9 MB/sec
msg_rate = 1.31 K/sec
port = 4,001
send_cost = 341 ms/GB
recv_cost = 17.1 sec/GB
send_cpus_used = 100 % cpus
recv_cpus_used = 73.5 % cpus
udp_lat:
latency = 170 us
msg_rate = 5.87 K/sec
port = 4,001
loc_cpus_used = 17 % cpus
rem_cpus_used = 22.5 % cpus
conf:
loc_node = qperf-client-2392635233-sbwff
loc_cpu = Intel Xeon E5-2650L v3 @ 1.80GHz
loc_os = Linux 3.10.0-514.6.1.el7.x86_64
loc_qperf = 0.4.9
rem_node = qperf-server-rmjd8
rem_cpu = Intel Xeon E5-2650L v3 @ 1.80GHz
rem_os = Linux 3.10.0-514.6.1.el7.x86_64
rem_qperf = 0.4.9
实验 3 Service-Pod之间
部署qperf-server:
$ kubectl create -f https://raw.githubusercontent.com/yangyuqian/k8s-the-hard-way/master/assets/qperf-server.yaml
测试Pod – Service – Pod网络:
$ kubectl run qperf-client -it --rm --image="arjanschaaf/centos-qperf" -- -v qperf-server -lp 4000 -ip 4001 tcp_bw tcp_lat udp_bw udp_lat conf tcp_bw: bw = 217 MB/sec msg_rate = 3.31 K/sec port = 4,001 send_cost = 1.38 sec/GB recv_cost = 3.11 sec/GB send_cpus_used = 30 % cpus recv_cpus_used = 67.5 % cpus tcp_lat: latency = 157 us msg_rate = 6.38 K/sec port = 4,001 loc_cpus_used = 15 % cpus rem_cpus_used = 14.5 % cpus udp_bw: send_bw = 1.28 GB/sec recv_bw = 7.83 MB/sec msg_rate = 239 /sec port = 4,001 send_cost = 693 ms/GB recv_cost = 69.6 sec/GB send_cpus_used = 89 % cpus recv_cpus_used = 54.5 % cpus udp_lat: latency = 140 us msg_rate = 7.12 K/sec port = 4,001 loc_cpus_used = 17.5 % cpus rem_cpus_used = 11 % cpus conf: loc_node = qperf-client-3660233240-w0nq9 loc_cpu = Intel Xeon E5-2650L v3 @ 1.80GHz loc_os = Linux 3.10.0-514.6.1.el7.x86_64 loc_qperf = 0.4.9 rem_node = qperf-server-rmjd8 rem_cpu = Intel Xeon E5-2650L v3 @ 1.80GHz rem_os = Linux 3.10.0-514.6.1.el7.x86_64 rem_qperf = 0.4.9
评估结论
使用Flannel vxlan backend前提下,采用默认mtu配置,Overlay Network的转发延迟在微妙量级,带宽有一定影响(减半)。

登录后评论
立即登录 注册