
编者注:本文由来自百度深度学习团队和CoreOS的Etcd团队共同编写

PaddlePaddle是什么
PaddlePaddle是一款由百度原生打造的易用、高效、灵活、可扩展的深度学习平台,从2014年开始应用在百度各个涉及深度学习的产品上。
PaddlePaddle支持了百度搜索引擎、在线广告、问答(Q&A)以及系统安全等15个产品,创造了超过50项革新。
2016年9月,百度开源了PaddlePaddle,它很快就吸引了百度以外的很多贡献者。
为什么选择K8s
PaddlePaddle的设计思路是独立于计算基础设施的平台。用户可以在Hadoop、Spark、Mesos、Kubernetes等各个基础设施上运行它。其中灵活、高效、且拥有丰富特性的Kubernetes深深地吸引了我们。
当我们在百度各个产品上应用PaddlePaddle时,我们注意到两种使用场景——科研和产品。科研数据不常改变,聚焦在快速地进行实验以达到期望的科学计量。产品数据则会频繁变动,它通常是来自Web服务的日志消息。
一个成功的深度学习项目包含了科研和数据处理管道(data processing pipeline),并且有许多需要调整的参数。很多工程师同时在这个项目的各个部分上工作。
为了保证这个项目易于管理,并且有效地利用了硬件资源,我们希望它的每个部分都运行在同一个基础设施平台上。
这个平台应该提供:
- 容错。它应该把管道的每个阶段都抽象为服务,这需要冗余的大量进程提供高吞吐和健壮性。
- 自动扩容。在白天有许多活跃的用户,平台应该扩展在线服务,而到了晚上,平台拥有更多资源,正好进行深度学习实验。
- 任务打包和隔离。它可以分配PaddlePaddle训练进程所需的GPU、一个需要大量内存的Web后端以及为了提高硬件资源利用率,需要对同一个节点进行磁盘IO的CephFS进程。
我们需要的是一个可以运行深度学习系统、Web服务器(例如: nginx)、日志采集器(例如: fluentd)的平台、分布式队列服务(例如: Kafka)、日志聚合以及其他在同个集群上利用Storm、Spark、Hadoop、MapReduce等数据处理器的平台。我们想把所有的任务(job)——在线的和离线的,生产的和实验的———运行在同一个集群上。所以当不同的任务需要不同的硬件资源时,我们会最大化利用整个集群资源。
由于虚拟机(VMs)带来的负载跟我们的效率和资源目标背道而驰,所以我们选择基于容器的解决方案。
在对不同容器解决方案的研究基础上,Kubernetes是最符合预期的方案。
K8s上的分布式训练
PaddlePaddle支持分布式本地训练。在PaddlePaddle集群里有两种角色:Parameter Server和Trainer。每个paramenter server进程拥有全局模型的一个分片(shard)。每个trainer拥有该模型的本地拷贝,并且使用本地数据来更新这个模型。在训练过程中,trainers会把模型的更新发送至parameter server,然后由parameter server对这些更新进行聚合,由此实现trainers本地拷贝和全局模型的同步。
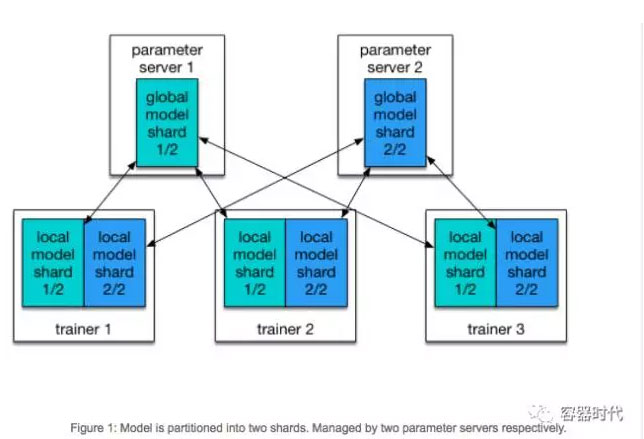
另外一些方法使用一组parameter server在多个节点上占用大量的CPU和内存来维持大型模型。但实践中,我们通常没有这么大的模型,因为鉴于GPU内存的限制,处理特大型模型是非常低效的。在我们的配置里,多个parameter server是主要是为了快速地通信。假定只有一个parameter server在处理所有的trainer,parameter server会聚合所有trainer的数据并到达瓶颈。在我们的实验里,一个实验性的有效配置包含了相同数量的trainer和parameter server。并且我们通常在同一个节点上运行一对trainer和parameter server。按照下列的Kubernetes任务配置,我们启动了N个Pods的任务,每个Pod里都有一对parameter server和trainer进程。
name: PaddlePaddle-cluster-job spec: parallelism: 3 completions: 3 template: metadata: name: PaddlePaddle-cluster-job spec: volumes: - name: jobpath hostPath: path: /home/admin/efs containers: - name: trainer image: your_repo/paddle:mypaddle command: ["bin/bash", "-c", "/root/start.sh"] env: - name: JOB_NAME value: paddle-cluster-job - name: JOB_PATH value: /home/jobpath - name: JOB_NAMESPACE value: default volumeMounts: - name: jobpath mountPath: /home/jobpath restartPolicy: Never
我们可以看到配置里parallelism和completions都设置为3。那么这个任务将会同时启动3个PaddlePaddle Pods,这个任务随着这3个Pods结束而结束。
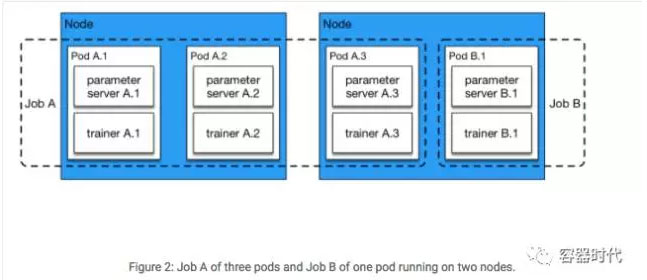
每个Pod的入口(entrypoint)是start.sh。它会从存储服务上下载数据,所以trainer可以快速地从Pod本地磁盘空间读到数据。当下载完成后,它运行一个Python脚本,start_paddle.py,这会启动parameter server,直到所有Pod的parameter server都可以进行服务时,再启动每个Pod里的trainer进程。
这个等待是很有必要的,因为每个trainer都需要与parameter server进行通信,如图1所示。Kubernetes API使得每个trainer都可以检查Pod的状态,所有Python脚本可以一直等待,直到所有的parameter server状态变为”Running”,再触发训练过程。
现在,从数据分片到pods/trainers的映射还是静态的。如果我们运行了N个trainer,我们需要将数据分为N片,并且静态地把每个分片分配给trainer。我们再一次依赖于Kubernetes API来得到任务里的Pod列表,这样我们就可以从1到N实现对pods/trainers的索引了,第i个trainer会读取第i个数据分片。
训练数据存放在分布式文件系统上。在实践中我们采用了CephFS作为我们集群上的文件系统,在AWS上我们使用的是Amazon Elastic File System。如果你对使用Kubernetes集群运行分布式PaddlePaddle训练任务感兴趣的话,请参考这个教程。
接下来
我们正致力于让PaddlePaddle可以在Kubernetes上更平滑地运行。
正如你可能注意到的,当前的trainer调度完全依赖于Kubernetes的静态划分映射(static partition map)。这个方法非常简单,但可能会造成一些效率问题。
首先,过慢的或者死亡的trainer会阻塞整个任务。在初始部署之后没有相应的控制原语或重调度策略。第二,静态的资源分配。如果Kubernetes拥有比我们使用的还多的资源,我们需要手动改变资源需求。这是一项枯燥的工作,并且跟我们关于效率和利用率的目标也不够契合。
为了解决上面提到的这些问题,我们添加了一个了解Kubernetes API的PaddlePaddle主(master),它可以动态地添加/移除资源容量,并且以一种更加动态的方式向各个trainer分发数据分片。PaddlePaddle使用Etcd作为数据分片和trainer动态映射的容错存储。这样,即使master挂掉了,这个映射也不会丢失。Kubernetes会重启这个master并且继续执行任务。
另外一个潜在的提升是更好的PaddlePaddle任务配置。我们的体验是拥有相同数量的trainer和parameter server这个配置主要来自于特定目的的集群。这个策略在仅运行PaddlePaddle任务的集群上高效。然而,这个策略可能在运行多个任务的通用集群上并不是最优的。
PaddlePaddle trainers可以利用多个GPU来加速计算。GPU在Kubernetes里目前还不是一级资源(first-class resource)。我们需要半手动地管理GPU。我们乐意与Kubernetes社区一同工作来提高对GPU的支持,让PaddlePaddle在Kubernetes表现最优。
原文链接
原文作者: Yi Wang, Baidu Research and Xiang Li, CoreOS
原文链接: http://blog.kubernetes.io/2017/02/run-deep-learning-with-paddlepaddle-on-kubernetes.html

登录后评论
立即登录 注册